Understand RBAC in Kubernetes
- Transfer
Note trans. : The article was written by Javier Salmeron, an engineer from Bitnami, a company well-known in the Kubernetes community, and was published on the CNCF blog in early August. The author talks about the very basics of the RBAC (role-based access control) mechanism that appeared in Kubernetes a year and a half ago. The material will be especially useful for those who are familiar with the device of the key components of the K8s (see links to other similar articles at the end).
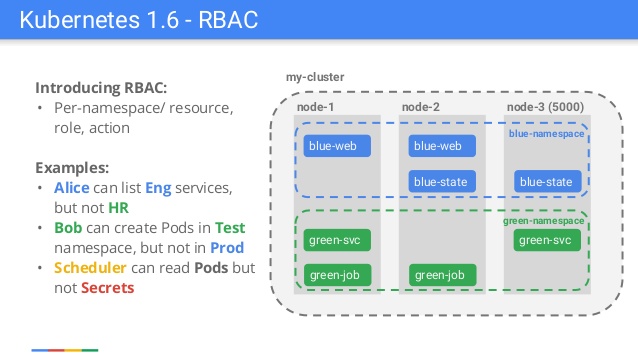
Slide from a presentation made by a Google employee on the occasion of the release of Kubernetes 1.6
Many experienced users of Kubernetes may recall the release of Kubernetes 1.6 when authorization based on Role-Based Access Control (RBAC) received beta status. This is how an alternative authentication mechanism appeared, which complemented the existing, but difficult to manage and understand, Attribute-Based Access Control (ABAC). Everyone enthusiastically welcomed the new feature, but at the same time countless users were disappointed. StackOverflow and GitHub were full of messages about RBAC restrictions, because most of the documentation and examples did not take into account RBAC (but now everything is in order). The reference example was Helm: simple start
Leaving these unsuccessful first attempts aside, one cannot deny the enormous contribution that RBAC has made to turning Kubernetes into a production-ready platform. Many of us managed to play with Kubernetes with full administrator privileges, and we are well aware that in a real environment it is necessary:
And in this respect, RBAC is a key element providing much-needed opportunities. In the article we will quickly go through the basics (for details, see this video ; follow the link for 1-hour webinar from Bitnami in English - approx. Transl. ) And dive a little into the most confusing moments.
To fully understand the idea of RBAC, you need to understand that three elements are involved in it:

If you keep these three elements in mind, the key idea of RBAC is:
- We want to connect actors, API resources, and operations. In other words, we want to specify for a given user what operations can be performed on a variety of resources .
In the combination of these three types of entities, RBAC objects that are available in the Kubernetes API become clear:
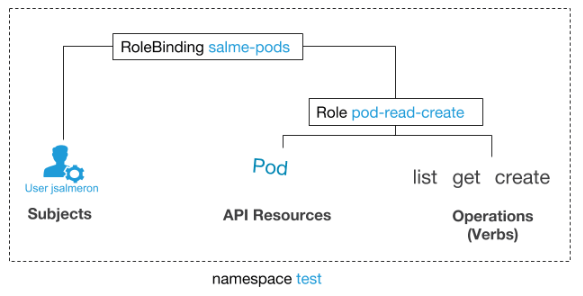
In the example below, we give the user jsalmeron the right to read, retrieve a list, and create pods in the test namespace . This means that jsalmeron will be able to execute such commands:
... but not like this:
Examples of YAML files:
Another interesting point in the following: now that the user can create scams, can we limit how much? This will require other objects that are not directly related to the RBAC specification and allow you to set limits on the number of resources:
One of the difficulties that many Kubernetes users face in the context of subjects is the difference between ordinary users and
The similarity of both types is the need to authenticate with the API to perform certain operations on a variety of resources, and their subject areas look very specific. They can also belong to groups, so they
... but this one is already gone:
This situation has a serious consequence: if the cluster will not store information about users, the administrator will have to manage accounts outside the cluster. There are various ways to solve the problem: TLS-certificates, tokens, OAuth2, etc.
In addition, you will need to create contexts
We have seen an example in which the specified user is granted permissions for operations in the cluster. But what about Deployments that require access to the Kubernetes API? Consider a specific scenario to get a better look.
Take for example the popular infrastructure application - RabbitMQ. We will use the Helm chart for RabbitMQ from Bitnami (from the official helm / charts repository), which uses the bitnami / rabbitmq container . The container contains a plugin for Kubernetes, which is responsible for detecting other members of the RabbitMQ cluster. Because of this, the process inside the container requires access to the Kubernetes API, and we will need to configure it
When it comes to
- Customize ServiceAccounts for each Deployment with a minimum set of privileges .
In the case of applications that require access to the Kubernetes API, you may be tempted to create some kind of “privileged
In addition, different Deployments will have different needs in terms of accessing the API, so for each Deploymentit is reasonable to have different
Not forgetting this, let's see which RBAC configuration will be correct for the case of Deployment 's with RabbitMQ.
You can see in the plug- in's documentation and source code that it requests the Endpoints list from the Kubernetes API . This is how the remaining members of the RabbitMQ cluster are discovered. Therefore, the RabbitMQ chart from Bitnami creates:

The diagram shows that we have allowed processes running in RabbitMQ to perform get operations on Endpoint objects . This is the minimum set of operations that is required for everything to work. At the same time, we know that the expanded chart is safe and will not perform undesirable actions within the Kubernetes cluster.
To work with Kubernetes in production, RBAC policies are not optional. They should not be treated as a set of API objects that only administrators should know. They are actually needed by developers to deploy secure applications and take full advantage of the potential offered by the Kubernetes API for cloud (cloud native) applications. More information on RBAC is available at these links:
Read also in our blog:
Slide from a presentation made by a Google employee on the occasion of the release of Kubernetes 1.6
Many experienced users of Kubernetes may recall the release of Kubernetes 1.6 when authorization based on Role-Based Access Control (RBAC) received beta status. This is how an alternative authentication mechanism appeared, which complemented the existing, but difficult to manage and understand, Attribute-Based Access Control (ABAC). Everyone enthusiastically welcomed the new feature, but at the same time countless users were disappointed. StackOverflow and GitHub were full of messages about RBAC restrictions, because most of the documentation and examples did not take into account RBAC (but now everything is in order). The reference example was Helm: simple start
helm init+ helm installno longer worked. Suddenly we needed to add “weird” elements like ServiceAccountsorRoleBindingseven before deploying a chart with WordPress or Redis (for more details, see the instructions ).Leaving these unsuccessful first attempts aside, one cannot deny the enormous contribution that RBAC has made to turning Kubernetes into a production-ready platform. Many of us managed to play with Kubernetes with full administrator privileges, and we are well aware that in a real environment it is necessary:
- Have a lot of users with different properties that provide the necessary authentication mechanism.
- Have complete control over what operations can be performed by each user or group of users.
- Have complete control over what operations each process in the hearth can perform.
- Restrict the visibility of certain resources in namespaces.
And in this respect, RBAC is a key element providing much-needed opportunities. In the article we will quickly go through the basics (for details, see this video ; follow the link for 1-hour webinar from Bitnami in English - approx. Transl. ) And dive a little into the most confusing moments.
The key to understanding RBAC in Kubernetes
To fully understand the idea of RBAC, you need to understand that three elements are involved in it:
- Subjects (subjects) - a set of users and processes that want to have access to the Kubernetes API;
- Resources - a collection of Kubernetes API objects available in a cluster. Their examples (among others) are Pods , Deployments , Services , Nodes , PersistentVolumes ;
- Verbs (verbs) - a set of operations that can be performed on resources. There are various verbs (get, watch, create, delete, etc.), but all of them are ultimately CRUD (Create, Read, Update, Delete) operations.
If you keep these three elements in mind, the key idea of RBAC is:
- We want to connect actors, API resources, and operations. In other words, we want to specify for a given user what operations can be performed on a variety of resources .
Understanding RBAC objects in the API
In the combination of these three types of entities, RBAC objects that are available in the Kubernetes API become clear:
Rolesconnect resources and verbs. They can be reused for different subjects. They are attached to the same namespace (we cannot use patterns that represent more than one [namespace], but we can deploy the same role object into different namespaces). If you want to apply a role to the entire cluster, there is a similar objectClusterRoles.RoleBindingsconnect the remaining entity-subjects. Having specified the role that already links API objects with verbs, we now select subjects who can use them. Equivalent for the cluster level (i.e., without reference to namespaces) isClusterRoleBindings.
In the example below, we give the user jsalmeron the right to read, retrieve a list, and create pods in the test namespace . This means that jsalmeron will be able to execute such commands:
kubectl get pods --namespace test
kubectl describe pod --namespace test pod-name
kubectl create --namespace test -f pod.yaml # в этом файле описание пода... but not like this:
kubectl get pods --namespace kube-system # другое пространство имён
kubectl get pods --namespace test -w # требует также глагола watchExamples of YAML files:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: pod-read-create
namespace: test
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "create"]kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: salme-pods
namespace: test
subjects:
- kind: User
name: jsalmeron
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-read-create
apiGroup: rbac.authorization.k8s.ioAnother interesting point in the following: now that the user can create scams, can we limit how much? This will require other objects that are not directly related to the RBAC specification and allow you to set limits on the number of resources:
ResourceQuotaand LimitRanges. They are definitely worth exploring with the configuration of such an important component of the cluster [as the creation of pods].Subjects: users and ... ServiceAccounts?
One of the difficulties that many Kubernetes users face in the context of subjects is the difference between ordinary users and
ServiceAccounts. In theory, everything is simple:Users- global users, intended for people or processes living outside the cluster;ServiceAccounts- limited to the namespace and intended for processes within the cluster running on the pods.
The similarity of both types is the need to authenticate with the API to perform certain operations on a variety of resources, and their subject areas look very specific. They can also belong to groups, so they
RoleBindingallow you to bind more than one subject (although ServiceAccountsonly one group is allowed for system:serviceaccounts). However, the main difference is the cause of the headache: users do not have corresponding objects in the Kubernetes API. It turns out that such an operation exists:kubectl create serviceaccount test-service-account # OK... but this one is already gone:
kubectl create user jsalmeron # Ошибка!This situation has a serious consequence: if the cluster will not store information about users, the administrator will have to manage accounts outside the cluster. There are various ways to solve the problem: TLS-certificates, tokens, OAuth2, etc.
In addition, you will need to create contexts
kubectlso that we can access the cluster through these new accounts. To create files with them, you can use commands kubectl config(which do not require access to the Kubernetes API, so they can be executed by any user). In the video above, there is an example of creating a user with TLS certificates.RBAC in Deployments: an example
We have seen an example in which the specified user is granted permissions for operations in the cluster. But what about Deployments that require access to the Kubernetes API? Consider a specific scenario to get a better look.
Take for example the popular infrastructure application - RabbitMQ. We will use the Helm chart for RabbitMQ from Bitnami (from the official helm / charts repository), which uses the bitnami / rabbitmq container . The container contains a plugin for Kubernetes, which is responsible for detecting other members of the RabbitMQ cluster. Because of this, the process inside the container requires access to the Kubernetes API, and we will need to configure it
ServiceAccountwith the correct RBAC privileges. When it comes to
ServiceAccounts, follow this good practice: - Customize ServiceAccounts for each Deployment with a minimum set of privileges .
In the case of applications that require access to the Kubernetes API, you may be tempted to create some kind of “privileged
ServiceAccount” that can do almost everything in the cluster. While this may seem like a simpler solution, in the end it can lead to security vulnerabilities allowing unwanted operations to be performed. (The video shows an example of Tiller [component Helm] and the consequences of having ServiceAccountsprivileges.) In addition, different Deployments will have different needs in terms of accessing the API, so for each Deploymentit is reasonable to have different
ServiceAccounts. Not forgetting this, let's see which RBAC configuration will be correct for the case of Deployment 's with RabbitMQ.
You can see in the plug- in's documentation and source code that it requests the Endpoints list from the Kubernetes API . This is how the remaining members of the RabbitMQ cluster are discovered. Therefore, the RabbitMQ chart from Bitnami creates:
- ServiceAccount for hearths with RabbitMQ:
{{- if .Values.rbacEnabled }} apiVersion: v1 kind: ServiceAccount metadata: name: {{ template "rabbitmq.fullname" . }} labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" {{- end }} - Role (we assume that the entire RabbitMQ cluster is deployed in a single namespace) resolving the get verbfor the Endpoint resource:
{{- if .Values.rbacEnabled }} kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: {{ template "rabbitmq.fullname" . }}-endpoint-reader labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] {{- end }} - RoleBinding connecting
ServiceAccountto a role:{{- if .Values.rbacEnabled }} kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: {{ template "rabbitmq.fullname" . }}-endpoint-reader labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" subjects: - kind: ServiceAccount name: {{ template "rabbitmq.fullname" . }} roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: {{ template "rabbitmq.fullname" . }}-endpoint-reader {{- end }}
The diagram shows that we have allowed processes running in RabbitMQ to perform get operations on Endpoint objects . This is the minimum set of operations that is required for everything to work. At the same time, we know that the expanded chart is safe and will not perform undesirable actions within the Kubernetes cluster.
Final thoughts
To work with Kubernetes in production, RBAC policies are not optional. They should not be treated as a set of API objects that only administrators should know. They are actually needed by developers to deploy secure applications and take full advantage of the potential offered by the Kubernetes API for cloud (cloud native) applications. More information on RBAC is available at these links:
- Bitnami Documentation: “ Configure RBAC in your Kubernetes Cluster ”;
- Kubernetes documentation: “ Using RBAC authorization ”.
PS from translator
Read also in our blog:
- “ 11 ways to (not) become a victim of hacking at Kubernetes ”;
- “ What happens in Kubernetes when starting the kubectl run? Part 1 ";
- “ How does the Kubernetes scheduler actually work? ";
- " Behind the scenes of the network in Kubernetes ";
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes) .