Nvidia. Revealing the secrets of the next generation GPU Turing architecture: double Ray Tracing, GDDR6, and more
- Transfer
At the presentation of NVIDIA SIGGRAPH 2018, CEO Jensen Juan officially presented the long-awaited (and caused numerous rumors and speculation) Turing GPU architecture. The next generation of NVIDIA GPUs, Turing, will include a number of new features, and will see the world later this year. Although the focus of today's announcements has been professional visualization (ProViz), we expect that the new architecture will be used in other upcoming NVIDIA products. Today's review is not just a listing of all the features of Turing.

So what is so special and new about Turing? The marquee feature, at least for the NVIDIA ProViz community, is designed for hybrid rendering, which combines ray tracing with traditional rasterization.

Major change: NVIDIA has included even more ray-tracing equipment in Turing to offer the most rapid hardware acceleration of ray tracing. New to the Turing architecture is the specialized computational unit RT Core, as NVIDIA calls it, at present there is not enough information about it, only that its function is support for ray tracing. These processor units speed up both checking the intersection of the rays and triangles, as well as manipulating the BVH (hierarchy of bounding volumes).
NVIDIA claims that the fastest Turing components can calculate 10 billion (Giga) rays per second, which is a 25-fold improvement in ray tracing performance compared to non-accelerated Pascal.
Turing architecture includes Volta tensor kernels that have been enhanced. Tensor cores are an important aspect of several NVIDIA initiatives. Along with the acceleration of ray tracing, an important tool in NVIDIA's “magic bag with tricks” is to reduce the number of rays required in the scene using AI noise reduction to clear the image, here tensor cores do the best. Of course, this is not the only area where they are good - all the NVIDIA neural networks and AI empires are built on them.
Turing is characterized by supporting a wider range of accuracy, and therefore, the possibility of significant acceleration in workloads that do not have high accuracy requirements. In addition to Volta FP16 precision mode, Turing tensor kernels support INT8 and even INT4. This is 2 and 4 times faster than FP16, respectively. Although at the presentation, NVIDIA did not wish to go into details, I would assume that they implemented something similar to data packaging, which is used for low-current operations on CUDA cores. Despite the reduced accuracy of the neural network (the return is reduced - by INT4 we get only 16 (!) Values) - there are certain models that really have this low level of accuracy. As a result, reduced accuracy modes will show good throughput, especially in output tasks,
Returning to the hybrid rendering as a whole, it is interesting that, despite these large individual accelerations, NVIDIA's overall promises for performance gains are somewhat more modest. Although the company promises to increase productivity by 6 times compared with Pascal, is it not time to ask which parts are accelerated and compared to which. Time will tell.
Meanwhile, in order to better use tensor cores beyond ray tracing tasks and narrowly focused deep learning tasks, NVIDIA will deploy SDK, NVIDIA NGX, which will allow integrating neural networks into image processing. NVIDIA suggests using neural networks and tensor cores for additional image and video processing, including such methods as the upcoming Deep-Anti-Aliasing (DLAA).
Along with RT and tensor cores, the Turing Streaming Multiprocessor (SM) architecture also presents new tricks. In particular, one of the recent changes in Volta is inherited, as a result of which Integer cores are allocated to their own blocks, and are not part of the floating-point CUDA cores. The advantage is accelerated address generation and Fused Multiply Add (FMA) performance.
As for ALU (I'm still waiting for confirmation for Turing) - support for faster operations with low accuracy (for example, fast FP16). In Volta, this is implemented as FP16 operations at double frequency relative to FP32, and INT8 operations at 4x speed. Tensor cores already support this concept, so it would be logical to transfer it to the CUDA cores.
Fast FP16, Rapid Packed Math technology, and other ways of packing multiple small operations into one major operation are all key components of improving GPU performance at a time when Moore's law slows down.
Using large (accurate) data types only as needed, they can be packaged together to do more work in the same time period. It is, first of all, important for the output of neural networks, as well as for the development of games. The fact is that not all shader programs need FP32 accuracy, and reducing accuracy can improve performance and reduce useful memory bandwidth and use of the registry file.
Turing SM includes something that NVIDIA calls "unified cache architecture". Since I am still awaiting the official SM diagrams from NVIDIA, it is unclear whether this is the same unification that we saw in Volta — where the L1 cache was combined with shared memory — or NVIDIA took another step forward. In any case, NVIDIA states that it has now offered twice as much bandwidth relative to the “previous generation”, but it’s unclear whether it means “Pascal” or “Volta” (the latter is more likely).
Finally, deeply hidden in the Turing press release, a reference to variable rate shading support was found. This is a relatively young and developing technology of graphic rendering, about which there is little information (especially about how exactly it is implemented in NVIDIA). But at a very high level of abstraction, it sounds like “the technology of the new generation of NVIDIA, which allows to apply shading with different resolutions, which allows developers to display different areas of the screen at different effective resolutions for concentrating quality (and rendering time) in areas where it is most needed” .
Since the memory used by GPUs is developed by third-party companies, there are no secrets here. JEDEC and its major 3 players Samsung, SK Hynix and Micron develop GDDR6 memory as a successor to GDDR5 and GDDR5X. NVIDIA confirmed the fact that Turing will support it. Depending on the manufacturer, GDDR6 of the first generation is advertised as having a memory bandwidth of up to 16 Gbit / s per bus, which is twice as much as the latest generation of NVIDIA GDDR5 cards and 40% faster than the latest NVIDIA GDDR5X cards.
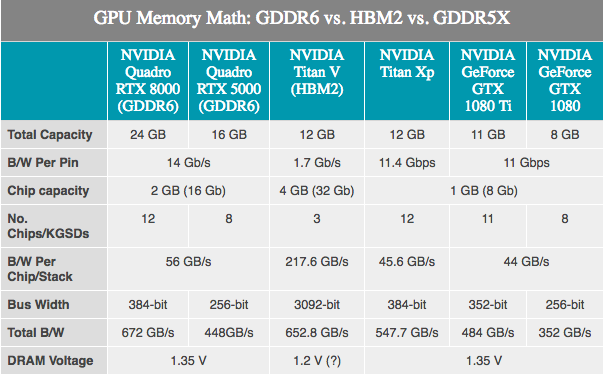
Compared to GDDR5X, GDDR6 does not look like a major breakthrough, since many of the GDDR6 innovations have already been applied in GDDR5X. The principal changes here include lower operating voltages (1.35v), and the internal memory is now divided: two memory channels per chip. For a standard 32-bit chip, two 16-bit memory channels, in total, we have 16 such channels on a 256-bit card. Although this, in turn, says that there are a very large number of channels, graphics processors will get the maximum benefit from innovation, because historically they are the most “parallel” devices.

NVIDIA, for its part, has confirmed that the first Turing Quadro cards will use GDDR6 at 14 Gb / s. At the same time, NVIDIA also confirmed the memory usage of Samsung, especially for its advanced 16 GB devices. This is important because it means that a typical NVIDIA 256-bit graphics processor can be equipped with 8 standard modules and get 16 GB of total memory capacity, or even 32 GB if they use clamshell mode (allows you to address 32 GB of memory on a standard 256-bit tire).
Already finishing review of architecture Turing, NVIDIA in passing confirmed support of some new functions of external input-output. NVLink support will be present in at least several Turing products. Recall that NVIDIA uses it in all three new Quadro cards. NVIDIA offers a two-way GPU configuration.
An important point (before the part of our game-oriented audience goes deeper into reading): the presence of NVLink in Turing hardware does not mean that it will be used in consumer video cards. Perhaps everything will be limited to Quadro and Tesla cards.
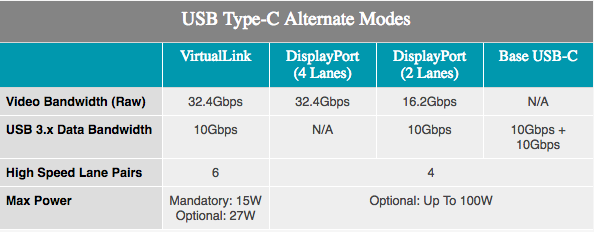
With the addition of VirtualLink support, players and users of ProViz will have what to expect from VR. The alternative USB Type-C mode was announced last month and supports 15 W + power, 10 Gbps data transfer thanks to USB 3.1 Gen 2, 4 DisplayPort HBR3 lanes on a single cable. In other words, this is a DisplayPort 1.4 connection with additional data and power. This allows the graphics card to directly control the VR headset. The standard is supported by NVIDIA, AMD, Oculus, Valve and Microsoft, so Turing products will be the first of a series of products that will support the new standard.
Although NVIDIA barely touched the topic, we know that the NVENC video coder unit was updated in Turing. The latest iteration of NVENC adds special HEKC 8K encoding support. Meanwhile, NVIDIA was able to improve the quality of its encoder, allowing it to achieve the same quality as before, with a 25% lower video bit rate.
Along with the announced specifications of the equipment, NVIDIA shows several figures of Turing hardware performance. It should be noted that here we know very, very little. The components appear to be based on a fully and partially enabled Turing SKU with 4608 CUDA cores and 576 tensor cores. Frequencies are not disclosed, however, since these numbers are profiled for Quadro hardware, we are likely to see lower clock frequencies than on any consumer equipment.

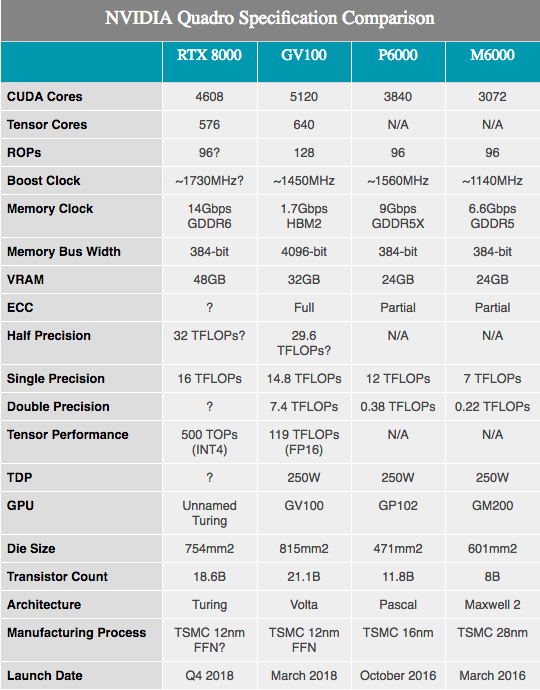
Along with the aforementioned 10GigaRays / sec index for RT cores, the performance of NVIDIA tensor cores is 500 trillion tensor operations per second (500T TOPs). For reference, NVIDIA often mentions the GV100 GPU as capable of delivering a maximum of 120T TOP, but this is not the same thing. In particular, while the GV100 is mentioned in the processing of FP16 operations, Turing's performance is cited with extremely low accuracy of INT4, which is just a quarter of the size of FP16 and, therefore, four times the throughput. If we normalize accuracy, then Turing tensor kernels do not seem to have better bandwidth per core, but rather offer more precision options than Volta. In any case, 576 tensor cores in this chip put it almost on par with the GV100, which has 640 such cores.
As for the CUDA cores, NVIDIA claims that the Turing graphics processor can offer 16 TFLOPS performance. This is a little ahead of 15 TFLOPS of performance with a single Tesla V100 accuracy, or even more advanced than 13.8 TFLOPS from Titan V. If you are looking for more customer-friendly information, this is about 32% more than Titan Xp. Having scribbled a few rough calculations on paper, we can assume the GPU clock frequency at about 1730 MHz, given that at the SM level there were no additional changes that would change the traditional ALU performance formulas.
Meanwhile, NVIDIA said that Quadro cards will ship with GDDR6 memory running at 14 Gb / s. And looking at the two best Quadro SKUs offering 48 GB and 24 GB GDDR6, respectively, we can almost see the 384-bit memory bus of this Turing graphics processor. Turning to numbers, this amounts to 672 GB / s of memory bandwidth for two top Quadro cards.
Otherwise, with a change in architecture, it is difficult to make many useful performance comparisons, especially comparing with Pascal. From what Volta saw, NVIDIA’s overall performance has improved, especially in well-designed computing loads. Thus, about a 33% improvement in paper productivity, compared to the Quadro P6000, may well be something much larger.
I will mention the crystal size of the new graphics processor. Located at 754 mm2, it’s not just big, it’s huge. Compared to other GPUs, it is second only to the NVIDIA GV100, which currently remains the flagship of NVIDIA. But given the 18.6 billion transistors, it is easy to see why the resulting chip should be so big. Apparently, NVIDIA has big plans for this GPU, which in the end will be able to justify the presence of two huge graphics processors in its product stack.
NVIDIA, for its part, did not indicate the specific model number of this GPU - whether it is a traditional class 102 or even 100th class graphics processor. I wonder if we will see a modification of this type of GPU for a consumer product in one form or another; it's so big that NVIDIA may want to save it for its more profitable Quadro and Tesla GPUs.
Finally, along with the announcement of the Turing architecture, NVIDIA announced that the first 4 Quadro cards based on Turing graphics processors - Quadro RTX 8000, RTX 6000 and RTX 5000 - will start shipping in the fourth quarter of this year. Since the very nature of this announcement is somewhat inverted - usually NVIDIA first announces consumer components - I would not apply the same timeline to consumer cards that do not have such stringent requirements for validation. We will see Turing equipment in the fourth quarter of this year, if not earlier. Those who want to buy Quadro can start saving money now: the best of the new Quadro RTX 8000 cards will cost you about $ 10,000.
Finally, as for consumers with Tesla from NVIDIA, the launch of Turing leaves the Volta in limbo. NVIDIA did not tell us whether Turing will eventually expand into Tesla’s high-end space — replacing the GV100 — or their best Volta processor will remain the master of their domain for centuries. However, since other Tesla cards were still based on Pascal, they are the first candidates for ousting by Turing in 2019.
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, a 30% discount for Habr's users for a unique analogue of the entry-level servers that we invented for you:The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
Hybrid rendering and neural networks: RT & Tensor Cores
So what is so special and new about Turing? The marquee feature, at least for the NVIDIA ProViz community, is designed for hybrid rendering, which combines ray tracing with traditional rasterization.
Major change: NVIDIA has included even more ray-tracing equipment in Turing to offer the most rapid hardware acceleration of ray tracing. New to the Turing architecture is the specialized computational unit RT Core, as NVIDIA calls it, at present there is not enough information about it, only that its function is support for ray tracing. These processor units speed up both checking the intersection of the rays and triangles, as well as manipulating the BVH (hierarchy of bounding volumes).
NVIDIA claims that the fastest Turing components can calculate 10 billion (Giga) rays per second, which is a 25-fold improvement in ray tracing performance compared to non-accelerated Pascal.
Turing architecture includes Volta tensor kernels that have been enhanced. Tensor cores are an important aspect of several NVIDIA initiatives. Along with the acceleration of ray tracing, an important tool in NVIDIA's “magic bag with tricks” is to reduce the number of rays required in the scene using AI noise reduction to clear the image, here tensor cores do the best. Of course, this is not the only area where they are good - all the NVIDIA neural networks and AI empires are built on them.
Turing is characterized by supporting a wider range of accuracy, and therefore, the possibility of significant acceleration in workloads that do not have high accuracy requirements. In addition to Volta FP16 precision mode, Turing tensor kernels support INT8 and even INT4. This is 2 and 4 times faster than FP16, respectively. Although at the presentation, NVIDIA did not wish to go into details, I would assume that they implemented something similar to data packaging, which is used for low-current operations on CUDA cores. Despite the reduced accuracy of the neural network (the return is reduced - by INT4 we get only 16 (!) Values) - there are certain models that really have this low level of accuracy. As a result, reduced accuracy modes will show good throughput, especially in output tasks,
Returning to the hybrid rendering as a whole, it is interesting that, despite these large individual accelerations, NVIDIA's overall promises for performance gains are somewhat more modest. Although the company promises to increase productivity by 6 times compared with Pascal, is it not time to ask which parts are accelerated and compared to which. Time will tell.
Meanwhile, in order to better use tensor cores beyond ray tracing tasks and narrowly focused deep learning tasks, NVIDIA will deploy SDK, NVIDIA NGX, which will allow integrating neural networks into image processing. NVIDIA suggests using neural networks and tensor cores for additional image and video processing, including such methods as the upcoming Deep-Anti-Aliasing (DLAA).
Turing SM: Dedicated INT Kernels, Single Cache, Variable Rate Shading
Along with RT and tensor cores, the Turing Streaming Multiprocessor (SM) architecture also presents new tricks. In particular, one of the recent changes in Volta is inherited, as a result of which Integer cores are allocated to their own blocks, and are not part of the floating-point CUDA cores. The advantage is accelerated address generation and Fused Multiply Add (FMA) performance.
As for ALU (I'm still waiting for confirmation for Turing) - support for faster operations with low accuracy (for example, fast FP16). In Volta, this is implemented as FP16 operations at double frequency relative to FP32, and INT8 operations at 4x speed. Tensor cores already support this concept, so it would be logical to transfer it to the CUDA cores.
Fast FP16, Rapid Packed Math technology, and other ways of packing multiple small operations into one major operation are all key components of improving GPU performance at a time when Moore's law slows down.
Using large (accurate) data types only as needed, they can be packaged together to do more work in the same time period. It is, first of all, important for the output of neural networks, as well as for the development of games. The fact is that not all shader programs need FP32 accuracy, and reducing accuracy can improve performance and reduce useful memory bandwidth and use of the registry file.
Turing SM includes something that NVIDIA calls "unified cache architecture". Since I am still awaiting the official SM diagrams from NVIDIA, it is unclear whether this is the same unification that we saw in Volta — where the L1 cache was combined with shared memory — or NVIDIA took another step forward. In any case, NVIDIA states that it has now offered twice as much bandwidth relative to the “previous generation”, but it’s unclear whether it means “Pascal” or “Volta” (the latter is more likely).
Finally, deeply hidden in the Turing press release, a reference to variable rate shading support was found. This is a relatively young and developing technology of graphic rendering, about which there is little information (especially about how exactly it is implemented in NVIDIA). But at a very high level of abstraction, it sounds like “the technology of the new generation of NVIDIA, which allows to apply shading with different resolutions, which allows developers to display different areas of the screen at different effective resolutions for concentrating quality (and rendering time) in areas where it is most needed” .
Feed the Beast: GDDR6 support
Since the memory used by GPUs is developed by third-party companies, there are no secrets here. JEDEC and its major 3 players Samsung, SK Hynix and Micron develop GDDR6 memory as a successor to GDDR5 and GDDR5X. NVIDIA confirmed the fact that Turing will support it. Depending on the manufacturer, GDDR6 of the first generation is advertised as having a memory bandwidth of up to 16 Gbit / s per bus, which is twice as much as the latest generation of NVIDIA GDDR5 cards and 40% faster than the latest NVIDIA GDDR5X cards.
Compared to GDDR5X, GDDR6 does not look like a major breakthrough, since many of the GDDR6 innovations have already been applied in GDDR5X. The principal changes here include lower operating voltages (1.35v), and the internal memory is now divided: two memory channels per chip. For a standard 32-bit chip, two 16-bit memory channels, in total, we have 16 such channels on a 256-bit card. Although this, in turn, says that there are a very large number of channels, graphics processors will get the maximum benefit from innovation, because historically they are the most “parallel” devices.
NVIDIA, for its part, has confirmed that the first Turing Quadro cards will use GDDR6 at 14 Gb / s. At the same time, NVIDIA also confirmed the memory usage of Samsung, especially for its advanced 16 GB devices. This is important because it means that a typical NVIDIA 256-bit graphics processor can be equipped with 8 standard modules and get 16 GB of total memory capacity, or even 32 GB if they use clamshell mode (allows you to address 32 GB of memory on a standard 256-bit tire).
Any details: NVLink, VirtualLink and 8K HEVC
Already finishing review of architecture Turing, NVIDIA in passing confirmed support of some new functions of external input-output. NVLink support will be present in at least several Turing products. Recall that NVIDIA uses it in all three new Quadro cards. NVIDIA offers a two-way GPU configuration.
An important point (before the part of our game-oriented audience goes deeper into reading): the presence of NVLink in Turing hardware does not mean that it will be used in consumer video cards. Perhaps everything will be limited to Quadro and Tesla cards.
With the addition of VirtualLink support, players and users of ProViz will have what to expect from VR. The alternative USB Type-C mode was announced last month and supports 15 W + power, 10 Gbps data transfer thanks to USB 3.1 Gen 2, 4 DisplayPort HBR3 lanes on a single cable. In other words, this is a DisplayPort 1.4 connection with additional data and power. This allows the graphics card to directly control the VR headset. The standard is supported by NVIDIA, AMD, Oculus, Valve and Microsoft, so Turing products will be the first of a series of products that will support the new standard.
Although NVIDIA barely touched the topic, we know that the NVENC video coder unit was updated in Turing. The latest iteration of NVENC adds special HEKC 8K encoding support. Meanwhile, NVIDIA was able to improve the quality of its encoder, allowing it to achieve the same quality as before, with a 25% lower video bit rate.
Performance indicators
Along with the announced specifications of the equipment, NVIDIA shows several figures of Turing hardware performance. It should be noted that here we know very, very little. The components appear to be based on a fully and partially enabled Turing SKU with 4608 CUDA cores and 576 tensor cores. Frequencies are not disclosed, however, since these numbers are profiled for Quadro hardware, we are likely to see lower clock frequencies than on any consumer equipment.
Along with the aforementioned 10GigaRays / sec index for RT cores, the performance of NVIDIA tensor cores is 500 trillion tensor operations per second (500T TOPs). For reference, NVIDIA often mentions the GV100 GPU as capable of delivering a maximum of 120T TOP, but this is not the same thing. In particular, while the GV100 is mentioned in the processing of FP16 operations, Turing's performance is cited with extremely low accuracy of INT4, which is just a quarter of the size of FP16 and, therefore, four times the throughput. If we normalize accuracy, then Turing tensor kernels do not seem to have better bandwidth per core, but rather offer more precision options than Volta. In any case, 576 tensor cores in this chip put it almost on par with the GV100, which has 640 such cores.
As for the CUDA cores, NVIDIA claims that the Turing graphics processor can offer 16 TFLOPS performance. This is a little ahead of 15 TFLOPS of performance with a single Tesla V100 accuracy, or even more advanced than 13.8 TFLOPS from Titan V. If you are looking for more customer-friendly information, this is about 32% more than Titan Xp. Having scribbled a few rough calculations on paper, we can assume the GPU clock frequency at about 1730 MHz, given that at the SM level there were no additional changes that would change the traditional ALU performance formulas.
Meanwhile, NVIDIA said that Quadro cards will ship with GDDR6 memory running at 14 Gb / s. And looking at the two best Quadro SKUs offering 48 GB and 24 GB GDDR6, respectively, we can almost see the 384-bit memory bus of this Turing graphics processor. Turning to numbers, this amounts to 672 GB / s of memory bandwidth for two top Quadro cards.
Otherwise, with a change in architecture, it is difficult to make many useful performance comparisons, especially comparing with Pascal. From what Volta saw, NVIDIA’s overall performance has improved, especially in well-designed computing loads. Thus, about a 33% improvement in paper productivity, compared to the Quadro P6000, may well be something much larger.
I will mention the crystal size of the new graphics processor. Located at 754 mm2, it’s not just big, it’s huge. Compared to other GPUs, it is second only to the NVIDIA GV100, which currently remains the flagship of NVIDIA. But given the 18.6 billion transistors, it is easy to see why the resulting chip should be so big. Apparently, NVIDIA has big plans for this GPU, which in the end will be able to justify the presence of two huge graphics processors in its product stack.
NVIDIA, for its part, did not indicate the specific model number of this GPU - whether it is a traditional class 102 or even 100th class graphics processor. I wonder if we will see a modification of this type of GPU for a consumer product in one form or another; it's so big that NVIDIA may want to save it for its more profitable Quadro and Tesla GPUs.
Will be released in the fourth quarter of 2018, if not earlier
Finally, along with the announcement of the Turing architecture, NVIDIA announced that the first 4 Quadro cards based on Turing graphics processors - Quadro RTX 8000, RTX 6000 and RTX 5000 - will start shipping in the fourth quarter of this year. Since the very nature of this announcement is somewhat inverted - usually NVIDIA first announces consumer components - I would not apply the same timeline to consumer cards that do not have such stringent requirements for validation. We will see Turing equipment in the fourth quarter of this year, if not earlier. Those who want to buy Quadro can start saving money now: the best of the new Quadro RTX 8000 cards will cost you about $ 10,000.
Finally, as for consumers with Tesla from NVIDIA, the launch of Turing leaves the Volta in limbo. NVIDIA did not tell us whether Turing will eventually expand into Tesla’s high-end space — replacing the GV100 — or their best Volta processor will remain the master of their domain for centuries. However, since other Tesla cards were still based on Pascal, they are the first candidates for ousting by Turing in 2019.
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, a 30% discount for Habr's users for a unique analogue of the entry-level servers that we invented for you:The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?