Analysis of application performance as a separate area in IT
Good afternoon, my name is Daniel, and for more than five years I have been working in the global technical support service for IT infrastructure of a large international company. The idea to separate the analysis of application performance into a separate area arose about two years ago and now I am at a stage where it is already possible to summarize the first results of work. The main reason that motivates me to write this article is the desire to receive constructive feedback from outside (including from respected visitors to this resource) in order to use them in the future to adjust the course of development of this area.
The topic of application performance management [1] (more general regarding its analysis) is quite popular in our time. Many large companies are aware or close to awareness of the importance of developing this area. However, the issue of practical implementation and evaluation of the effectiveness of the efforts is far from simple. Even the wording that there is “optimal performance” for each particular application or service is not an easy task with fuzzy conditions and conclusions. Also, today there is not a single reliable way to measure the financial efficiency of investments in this area. The only thing that you can rely on in the development of this area is the common sense used in each case.
Let's look at a typical example. The organization has some important application. The business has strict requirements for the availability of this application, since every hour of downtime leads to quite noticeable losses. The relevant SLA is signed. The IT department establishes continuous automatic monitoring of availability when a special device regularly polls its user interface, sending a simple request and waiting for a typical response. If there is no answer, an automatic incident is created, which is eliminated by the corresponding support teams. Can we say that the IT department carries out its work and provides support for the interests of the business in full? Not sure.
One day, users discover that the application starts up pretty quickly, but its key operations are extremely slow. Automatic monitoring is "silent" and we are very lucky if there is at least one of the users who picks up the phone and calls the technical support service before this problem leads to significant losses. My practice shows that, as a rule, users do not report such problems. There are many reasons, from the banal unwillingness to call and explain difficult and subjective symptoms to the distrust of the local support service. It happens that such problems last for years, causing hidden damage to the business, spoiling people's nerves and significantly undermining the reputation of the IT department. Sometimes they still find out about the problem, if the losses from poor system performance become too obvious and fall into the focus of business management. Then begins a rather fascinating story. Senior IT executives require their subordinates to immediately fix the problem. A round table is being assembled of representatives of individual teams, each of them checks part of the infrastructure entrusted to him, and everyone comes to a wonderful conclusion - “everything is fine with us!” The servers are in order - neither the CPU nor the memory is overloaded. The network is in order - there are no packet losses, communication lines are not overloaded. The client part should also be in order - the rest of the applications are working fine. The trouble is that when it all merges into one system - it works terribly, but where to look for the root cause? The manufacturer of the program also does not help much, citing the fact that other customers do not complain and points to "some kind of infrastructure problems." Then usually one of the three occurs (sometimes in combination):
IT department can save face only in the latter case, but what happens this way, alas, there are no guarantees. In addition, it is completely unclear how to motivate people to work beyond their direct responsibility and maintain transparency and manageability in the industry.
The management of the company supported my initiative to separate the analysis of application performance into a separate area. This gave me the opportunity on an official basis to develop it in accordance with the needs of our organization and to do what I do best - to conduct a cross-technological analysis of the various systems operating in our enterprise. Now let's figure out what this area is in our understanding.
For the area of application performance analysis (hereinafter - APA or Application Performance Analysis), we have assigned the following functions (in accordance with the available tools and skills):
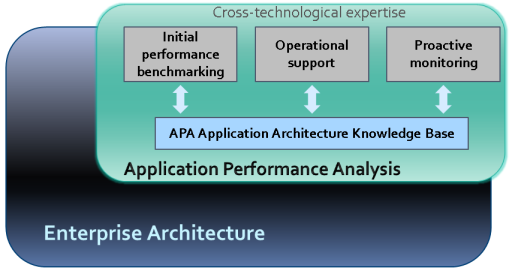
Figure 1
One of the main APA tools is a knowledge base that reflects the functional purpose, architecture, and related incidents of all applications that have ever been in the focus of APA attention. It helps not to do the same job twice (especially if several specialists work in a team). We can say that this base is related to the APA area with a more general area of Enterprise Architecture [3], namely, its technical branch. In order not to create excessive expectations, we immediately define the clear boundaries of the area of responsibility:
The essence of the APA area is reflected in its logo (see. Fig. 2). The lighthouse only helps determine the right course, but the choice of route always remains on the captain’s conscience.

Figure 2
The main APA niche among other services can be defined as follows:
In ITIL terms, we can say that we take the Performance Management area beyond the traditional concept of the Capacity Management area, to which it formally refers [4].
It can be seen from the above that APA plays an important role in the application performance management process, but does not completely replace it. This is a kind of centralization and unification of its most complex components - monitoring and analysis, however, the issues of direct application management remain with the relevant teams. Here they are more effective: it is easier for them to establish individual contact with the software manufacturer, they are most interested in the success of their service or application. APA is just a tool covering the most complex area, everything else is solved by standard procedures.
An APA specialist analyzes network traffic to identify the causes of performance problems. The network is a universal environment that combines various architectural components of applications and in the vast majority of cases, the analysis of network transactions provides the necessary and sufficient information to find a bad element. However, this method has its limitations. For example, we can see that this server introduces the greatest delay in the execution of user operations, and we can even highlight the most problematic call, for example, a GET or POST request when loading a web page and the corresponding long SQL query to the database. But what happens inside the server at this time remains off-screen. Moreover, if for some reason the database server is combined with the application server within the same host, then it is practically impossible to separate their influence on the total time of the operation execution by this method. Fortunately, in most cases the use of this method brings good results. From my practice, I can say that about 99% of calls to me are resolved successfully. Moreover, the information received by the APA service is key.
There are many software and hardware products on the market today that help manage application performance. We use two main tools: one for a detailed study of pre-recorded transactions, the other for continuous monitoring of application performance by decoding and analyzing their network traffic.
Now let's take a closer look at the methods for implementing individual areas of APA.
The key to success in operational support for application performance is the clear formalization of each incident. The user, as a rule, describes the problem subjectively and often very emotionally. At the first stage, it is very important to separate the emotional component (too strong coffee, bad mood or hostility to any application) from the direct definition of the problem. To do this, I created a special list of questions that the user must answer during the creation of the incident. It is important to note that APA does not imply direct work with users, all the necessary answers are received by universal specialists of the first and second level of support. Sometimes part of the necessary information can be obtained using the automatic monitoring of application performance.
Further, the team responsible for this application provides me with a fairly complete description of its architecture (which host is responsible for what, and what network transactions between them are expected during the execution of problem operations). Incomplete information is sometimes given, which is not an insurmountable obstacle to an investigation. Also, I can ask them to install the necessary agents on the client and server side of the application. Agents are used to collect statistical information from network interfaces. They are placed in strict accordance with the instructions and in 99% of cases their installation does not cause any difficulties.
Then, we will agree on a procedure for directly testing problematic operations: I either reproduce the problem myself according to the instructions or ask the user to do this at my command. At the same time, I activate the recording process on my agents. The resulting material is a set of trace files simultaneously recorded during the execution of a problem operation at several observation points. They contain a complete history of network operations on selected hosts. The key advantage of the tool that I use for analysis is the ability to combine these files into one, time-aligned (that is, 0 seconds of the trace file taken from the client exactly correspond to 0 seconds on server trace files). This gives me the opportunity to track in time the entire course of the operation - how much time the client request went through the network to the application server, how much it spent on processing before sending the necessary request to the database, how long the database processed this request, and so on. Let's take a concrete example.
Here is a fragment of the architecture of the application we are interested in (see Fig. 3).
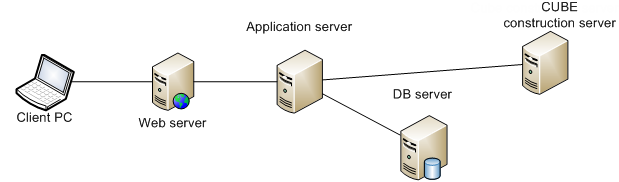
Figure 3
After recording and processing, the problematic operation looks as shown in Figure 4:

Figure 4
Next, you can determine the effect of each element on the total execution time of the operation (see Figure 5)
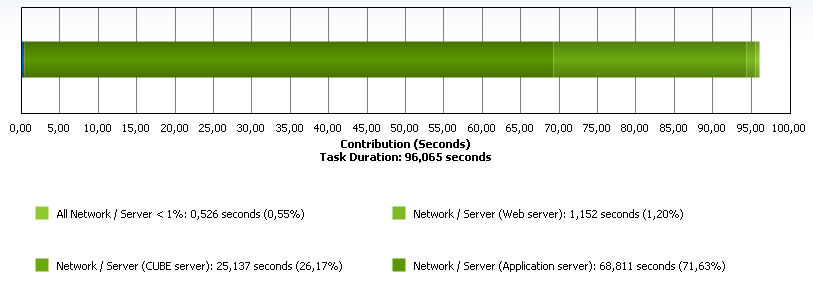
Figure 5
It can be seen that the problem is related to the application server and CUBE server, but You can understand a little deeper. For example, highlight the most problematic challenges (see Fig. 6).

Figure 6
There is a topic for a reasoned conversation with the manufacturer of this software.
It is also important to note that this method is no less effective in investigating non-performance functional problems in which support teams are at a standstill.
This type of activity is entirely based on the methods used in operational support. In addition to them, we are also able to mathematically predict what the performance of the user interface in different regions for centralized applications will be.
As mentioned above, it can be very difficult to get an objective assessment of application performance from the user. Just because of the subjectivity of the question itself. On the other hand, technical support in its work cannot operate on subjective metrics. This contradiction often leads to the fact that we are trying to fix non-existent or non-essential breakdowns, while the truly important problems are ignored. The main conclusion is that to effectively manage the performance of applications installed in the enterprise, you need to have an independent system for automatic performance monitoring. Relying on users in this matter is pointless.
To resolve this issue, I use tools for continuous monitoring of application performance by decoding and analyzing their network traffic. Here, the source of information is the SPAN ports configured on the switches we are interested in. That is, we practically do not interfere in the work of the systems of interest to us, no agents on the servers are needed. The received information is collected and filtered on special probe servers and transmitted to a central server. This server is responsible for analyzing and storing received data, providing a reporting interface and automatic notification of application performance problems.
This solution not only helps to quickly find out about existing problems, but often gives a hint where to look for the root cause of their occurrence. Not as detailed and accurate as this can be done using operational support, but still enough to significantly speed up the investigation process. In addition, we can see long-term trends in application performance changes, as well as evaluate the effect of changes made in the infrastructure.
Let me give you a couple of examples of reports that we use.
General assessment of the load and performance of the web user interface of the application over the past 8 hours (see Fig. 7)

Figure 7
Here: Operations (left scale) - the total number of operations per measurement interval is divided by"Slow operations" and "fast operations" . An operation is considered slow if its execution time exceeds a certain threshold value defined for this interface. Average operation time (right scale) - average time of execution of operations for each measurement interval.
The performance and load of the database server of the same application for the same time is shown in Figure 8.

Figure 8
If you want, you can determine which SQL queries caused the “Average operation time” jump between 8 30 and 9 00, but there is no special need, since this did not affect the user interface.
There are companies on the market that provide analysis of application performance as a service. As far as I could figure it out, they do it by about the same methods as I do, but various variations and additions are possible. If you are faced with the task of developing this area in your enterprise, the first question that remains to be decided is to use external services or develop a service within the company. When I went through this stage, I identified several key factors that helped us make the final decision. I hope they will be interesting and useful to you too.
One of the first factors to think about is the price. In the case of external services, the initial cost of installation can be significantly lower than what the internal installation will require. Moreover, an increase in fixed assets can be practically avoided (we buy the service). If you install everything inside, you need to be prepared for some costs - servers, licenses, personnel with his hiring and training, annual maintenance, resources to install and debug all this. And the time required for the efforts and costs to begin to be beneficial can be significantly longer if you do everything yourself. These arguments are very significant when considering the short term, but over time the balance may change. A service provider is primarily a commercial organization. He, too, needs to cover his expenses for the maintenance of specialists and service products and do it for the benefit of himself. It may well happen that in the long run with more or less dense loading, this service will require high costs if you use the services of third-party companies. I spent a lot of time trying to compare the cost of ownership for each option. I had to make some assumptions based on existing experience: how many investigations a year need to be carried out, how much time it takes on average, and how much, in the end, it can cost. if you use the services of third-party companies. I spent a lot of time trying to compare the cost of ownership for each option. I had to make some assumptions based on existing experience: how many investigations a year need to be carried out, how much time it takes on average, and how much, in the end, it can cost. if you use the services of third-party companies. I spent a lot of time trying to compare the cost of ownership for each option. I had to make some assumptions based on existing experience: how many investigations a year need to be carried out, how much time it takes on average, and how much, in the end, it can cost.
An equally important issue is what we get for the money (quality, volume, and speed of investigation of critical incidents).
An important feature of outsource services is that the provider always works as part of its contract. Unlike internal service, he is absolutely not interested in the success of our business. From here follows the inflexibility of the supplier in borderline situations. Everything that is not spelled out in the contract, as a rule, is either impossible or very expensive. For example, a complex critical incident occurred that was not related to performance. Very often in such cases, the same tools and methods that are used to analyze performance problems help out. An internal APA team will definitely help, but what a third-party provider says is unknown. Formally, for him this is far beyond the scope of the contract and the usual work. And not the fact that it will be easy to convince the manager on the other hand to help,
An APA investigation may result in a recommendation to substantially modify existing infrastructure. This is done in order to not only resolve the current incident, but also to prevent a similar problem in other applications. It is completely unprofitable for an external supplier to resolve problems that have not yet occurred. This is their income. In addition, the level of responsibility for the recommendations provided is quite high, since they often affect the overall strategy for the development of information technologies in the enterprise. It is not always wise to leave these issues to the discretion of an external company.
No less complicated issue with the speed of investigation of critical incidents. In general, investigating performance issues is a complex area. You can never say in advance how much time it will take to analyze - there are too many unknown factors. In any case, this is not something that can be reflected in the contract. But what then, if you need to urgently understand? One way or another, the internal division depends on the success of our business, but the external company does not.
In addition, working with an external provider involves a certain formalization of requests and the results obtained. And now the question is: are all internal units ready to clearly formulate their requests and can understand what exactly they were answered? People often come to me and ask me not at all about what they really need. It turns out that inside we still need someone who will act as a translator who knows the right people inside the company and understands how to communicate with an external supplier in his language. At the same time, this role implies the presence of a good technical expertise, almost the same as that needed to independently conduct investigations.
Consideration of the above arguments led us to the decision to leave APA as an internal service. Of course, in each case, the optimal solution may vary. Any arguments are a priori controversial due to the nature of the issue. I just share my experience.
All of the above is a version of the practical implementation of the process of analyzing and managing application performance in a large enterprise. In our case, it gives a good result. Over the past year, the APA has been involved in the investigation of many critical issues and in the vast majority of cases has played a key role in determining the root cause. Moreover, in many cases it was difficult to imagine how the errors found could be identified without involving APA methods. Our work is appreciated by management.
[1] en.wikipedia.org/wiki/Application_Performance_Management .
[2] “Retail IT Service Operation: Calculating the Impacts of Poor Application Performance Across a Business Ecosystem”. Enterprise Management Associates. 2011
[3] en.wikipedia.org/wiki/Enterprise_architecture_framework
[4] en.wikipedia.org/wiki/Information_Technology_Infrastructure_Library .
Application Performance Management
The topic of application performance management [1] (more general regarding its analysis) is quite popular in our time. Many large companies are aware or close to awareness of the importance of developing this area. However, the issue of practical implementation and evaluation of the effectiveness of the efforts is far from simple. Even the wording that there is “optimal performance” for each particular application or service is not an easy task with fuzzy conditions and conclusions. Also, today there is not a single reliable way to measure the financial efficiency of investments in this area. The only thing that you can rely on in the development of this area is the common sense used in each case.
Let's look at a typical example. The organization has some important application. The business has strict requirements for the availability of this application, since every hour of downtime leads to quite noticeable losses. The relevant SLA is signed. The IT department establishes continuous automatic monitoring of availability when a special device regularly polls its user interface, sending a simple request and waiting for a typical response. If there is no answer, an automatic incident is created, which is eliminated by the corresponding support teams. Can we say that the IT department carries out its work and provides support for the interests of the business in full? Not sure.
One day, users discover that the application starts up pretty quickly, but its key operations are extremely slow. Automatic monitoring is "silent" and we are very lucky if there is at least one of the users who picks up the phone and calls the technical support service before this problem leads to significant losses. My practice shows that, as a rule, users do not report such problems. There are many reasons, from the banal unwillingness to call and explain difficult and subjective symptoms to the distrust of the local support service. It happens that such problems last for years, causing hidden damage to the business, spoiling people's nerves and significantly undermining the reputation of the IT department. Sometimes they still find out about the problem, if the losses from poor system performance become too obvious and fall into the focus of business management. Then begins a rather fascinating story. Senior IT executives require their subordinates to immediately fix the problem. A round table is being assembled of representatives of individual teams, each of them checks part of the infrastructure entrusted to him, and everyone comes to a wonderful conclusion - “everything is fine with us!” The servers are in order - neither the CPU nor the memory is overloaded. The network is in order - there are no packet losses, communication lines are not overloaded. The client part should also be in order - the rest of the applications are working fine. The trouble is that when it all merges into one system - it works terribly, but where to look for the root cause? The manufacturer of the program also does not help much, citing the fact that other customers do not complain and points to "some kind of infrastructure problems." Then usually one of the three occurs (sometimes in combination):
- After a long study, they can forget about the problem (the business has come to terms with the fact that it is working now and will not be faster), although in the process we spent a lot of money on the chaotic improvement of individual infrastructure elements. Alas, it did not help, but we tried!
- The business cannot reconcile with the poor performance of this system and, seeing the failure of the IT departments to resolve the problem, hires an external consultant. For a lot of money, he finds the root cause somewhere at the junction of individual infrastructure elements and technologies, but the reputation of the IT department is thoroughly undermined.
- Someone from internal experts guesses the reason, but acts far beyond the scope of their responsibility.
IT department can save face only in the latter case, but what happens this way, alas, there are no guarantees. In addition, it is completely unclear how to motivate people to work beyond their direct responsibility and maintain transparency and manageability in the industry.
Key Application Performance Analysis Features
The management of the company supported my initiative to separate the analysis of application performance into a separate area. This gave me the opportunity on an official basis to develop it in accordance with the needs of our organization and to do what I do best - to conduct a cross-technological analysis of the various systems operating in our enterprise. Now let's figure out what this area is in our understanding.
For the area of application performance analysis (hereinafter - APA or Application Performance Analysis), we have assigned the following functions (in accordance with the available tools and skills):
- Initial analysis of performance and architecture of new applications
- Helps Operations Support Teams Identify Causes of Application Performance Incidents
- Automated operations performance monitoring for key applications
Figure 1
One of the main APA tools is a knowledge base that reflects the functional purpose, architecture, and related incidents of all applications that have ever been in the focus of APA attention. It helps not to do the same job twice (especially if several specialists work in a team). We can say that this base is related to the APA area with a more general area of Enterprise Architecture [3], namely, its technical branch. In order not to create excessive expectations, we immediately define the clear boundaries of the area of responsibility:
- APA helps implementation teams conduct initial performance analysis for new applications, but is not responsible for evaluating this application comprehensively. Issues such as functionality, redundancy, fault tolerance, and many others remain outside the scope of the APA study.
- The APA helps support teams identify a problematic infrastructure or application item, but is not responsible for fixing it.
- For the needs of application performance monitoring, APA provides technical tools and fine-tuning them according to customer needs, but is not responsible for the success of resolving identified problems.
The essence of the APA area is reflected in its logo (see. Fig. 2). The lighthouse only helps determine the right course, but the choice of route always remains on the captain’s conscience.
Figure 2
The main APA niche among other services can be defined as follows:
- Analysis of problems and incidents in which other teams are at a standstill
- Cross-technology expertise
- Prevention of application performance degradation incidents
In ITIL terms, we can say that we take the Performance Management area beyond the traditional concept of the Capacity Management area, to which it formally refers [4].
It can be seen from the above that APA plays an important role in the application performance management process, but does not completely replace it. This is a kind of centralization and unification of its most complex components - monitoring and analysis, however, the issues of direct application management remain with the relevant teams. Here they are more effective: it is easier for them to establish individual contact with the software manufacturer, they are most interested in the success of their service or application. APA is just a tool covering the most complex area, everything else is solved by standard procedures.
Basic methods for analyzing application performance
An APA specialist analyzes network traffic to identify the causes of performance problems. The network is a universal environment that combines various architectural components of applications and in the vast majority of cases, the analysis of network transactions provides the necessary and sufficient information to find a bad element. However, this method has its limitations. For example, we can see that this server introduces the greatest delay in the execution of user operations, and we can even highlight the most problematic call, for example, a GET or POST request when loading a web page and the corresponding long SQL query to the database. But what happens inside the server at this time remains off-screen. Moreover, if for some reason the database server is combined with the application server within the same host, then it is practically impossible to separate their influence on the total time of the operation execution by this method. Fortunately, in most cases the use of this method brings good results. From my practice, I can say that about 99% of calls to me are resolved successfully. Moreover, the information received by the APA service is key.
There are many software and hardware products on the market today that help manage application performance. We use two main tools: one for a detailed study of pre-recorded transactions, the other for continuous monitoring of application performance by decoding and analyzing their network traffic.
Now let's take a closer look at the methods for implementing individual areas of APA.
Operational Support Methods
The key to success in operational support for application performance is the clear formalization of each incident. The user, as a rule, describes the problem subjectively and often very emotionally. At the first stage, it is very important to separate the emotional component (too strong coffee, bad mood or hostility to any application) from the direct definition of the problem. To do this, I created a special list of questions that the user must answer during the creation of the incident. It is important to note that APA does not imply direct work with users, all the necessary answers are received by universal specialists of the first and second level of support. Sometimes part of the necessary information can be obtained using the automatic monitoring of application performance.
Further, the team responsible for this application provides me with a fairly complete description of its architecture (which host is responsible for what, and what network transactions between them are expected during the execution of problem operations). Incomplete information is sometimes given, which is not an insurmountable obstacle to an investigation. Also, I can ask them to install the necessary agents on the client and server side of the application. Agents are used to collect statistical information from network interfaces. They are placed in strict accordance with the instructions and in 99% of cases their installation does not cause any difficulties.
Then, we will agree on a procedure for directly testing problematic operations: I either reproduce the problem myself according to the instructions or ask the user to do this at my command. At the same time, I activate the recording process on my agents. The resulting material is a set of trace files simultaneously recorded during the execution of a problem operation at several observation points. They contain a complete history of network operations on selected hosts. The key advantage of the tool that I use for analysis is the ability to combine these files into one, time-aligned (that is, 0 seconds of the trace file taken from the client exactly correspond to 0 seconds on server trace files). This gives me the opportunity to track in time the entire course of the operation - how much time the client request went through the network to the application server, how much it spent on processing before sending the necessary request to the database, how long the database processed this request, and so on. Let's take a concrete example.
Here is a fragment of the architecture of the application we are interested in (see Fig. 3).
Figure 3
After recording and processing, the problematic operation looks as shown in Figure 4:
Figure 4
Next, you can determine the effect of each element on the total execution time of the operation (see Figure 5)
Figure 5
It can be seen that the problem is related to the application server and CUBE server, but You can understand a little deeper. For example, highlight the most problematic challenges (see Fig. 6).
Figure 6
There is a topic for a reasoned conversation with the manufacturer of this software.
It is also important to note that this method is no less effective in investigating non-performance functional problems in which support teams are at a standstill.
Initial analysis of performance and architecture of new applications
This type of activity is entirely based on the methods used in operational support. In addition to them, we are also able to mathematically predict what the performance of the user interface in different regions for centralized applications will be.
Application Performance Monitoring
As mentioned above, it can be very difficult to get an objective assessment of application performance from the user. Just because of the subjectivity of the question itself. On the other hand, technical support in its work cannot operate on subjective metrics. This contradiction often leads to the fact that we are trying to fix non-existent or non-essential breakdowns, while the truly important problems are ignored. The main conclusion is that to effectively manage the performance of applications installed in the enterprise, you need to have an independent system for automatic performance monitoring. Relying on users in this matter is pointless.
To resolve this issue, I use tools for continuous monitoring of application performance by decoding and analyzing their network traffic. Here, the source of information is the SPAN ports configured on the switches we are interested in. That is, we practically do not interfere in the work of the systems of interest to us, no agents on the servers are needed. The received information is collected and filtered on special probe servers and transmitted to a central server. This server is responsible for analyzing and storing received data, providing a reporting interface and automatic notification of application performance problems.
This solution not only helps to quickly find out about existing problems, but often gives a hint where to look for the root cause of their occurrence. Not as detailed and accurate as this can be done using operational support, but still enough to significantly speed up the investigation process. In addition, we can see long-term trends in application performance changes, as well as evaluate the effect of changes made in the infrastructure.
Let me give you a couple of examples of reports that we use.
General assessment of the load and performance of the web user interface of the application over the past 8 hours (see Fig. 7)
Figure 7
Here: Operations (left scale) - the total number of operations per measurement interval is divided by"Slow operations" and "fast operations" . An operation is considered slow if its execution time exceeds a certain threshold value defined for this interface. Average operation time (right scale) - average time of execution of operations for each measurement interval.
The performance and load of the database server of the same application for the same time is shown in Figure 8.
Figure 8
If you want, you can determine which SQL queries caused the “Average operation time” jump between 8 30 and 9 00, but there is no special need, since this did not affect the user interface.
In-house or outsource
There are companies on the market that provide analysis of application performance as a service. As far as I could figure it out, they do it by about the same methods as I do, but various variations and additions are possible. If you are faced with the task of developing this area in your enterprise, the first question that remains to be decided is to use external services or develop a service within the company. When I went through this stage, I identified several key factors that helped us make the final decision. I hope they will be interesting and useful to you too.
One of the first factors to think about is the price. In the case of external services, the initial cost of installation can be significantly lower than what the internal installation will require. Moreover, an increase in fixed assets can be practically avoided (we buy the service). If you install everything inside, you need to be prepared for some costs - servers, licenses, personnel with his hiring and training, annual maintenance, resources to install and debug all this. And the time required for the efforts and costs to begin to be beneficial can be significantly longer if you do everything yourself. These arguments are very significant when considering the short term, but over time the balance may change. A service provider is primarily a commercial organization. He, too, needs to cover his expenses for the maintenance of specialists and service products and do it for the benefit of himself. It may well happen that in the long run with more or less dense loading, this service will require high costs if you use the services of third-party companies. I spent a lot of time trying to compare the cost of ownership for each option. I had to make some assumptions based on existing experience: how many investigations a year need to be carried out, how much time it takes on average, and how much, in the end, it can cost. if you use the services of third-party companies. I spent a lot of time trying to compare the cost of ownership for each option. I had to make some assumptions based on existing experience: how many investigations a year need to be carried out, how much time it takes on average, and how much, in the end, it can cost. if you use the services of third-party companies. I spent a lot of time trying to compare the cost of ownership for each option. I had to make some assumptions based on existing experience: how many investigations a year need to be carried out, how much time it takes on average, and how much, in the end, it can cost.
An equally important issue is what we get for the money (quality, volume, and speed of investigation of critical incidents).
An important feature of outsource services is that the provider always works as part of its contract. Unlike internal service, he is absolutely not interested in the success of our business. From here follows the inflexibility of the supplier in borderline situations. Everything that is not spelled out in the contract, as a rule, is either impossible or very expensive. For example, a complex critical incident occurred that was not related to performance. Very often in such cases, the same tools and methods that are used to analyze performance problems help out. An internal APA team will definitely help, but what a third-party provider says is unknown. Formally, for him this is far beyond the scope of the contract and the usual work. And not the fact that it will be easy to convince the manager on the other hand to help,
An APA investigation may result in a recommendation to substantially modify existing infrastructure. This is done in order to not only resolve the current incident, but also to prevent a similar problem in other applications. It is completely unprofitable for an external supplier to resolve problems that have not yet occurred. This is their income. In addition, the level of responsibility for the recommendations provided is quite high, since they often affect the overall strategy for the development of information technologies in the enterprise. It is not always wise to leave these issues to the discretion of an external company.
No less complicated issue with the speed of investigation of critical incidents. In general, investigating performance issues is a complex area. You can never say in advance how much time it will take to analyze - there are too many unknown factors. In any case, this is not something that can be reflected in the contract. But what then, if you need to urgently understand? One way or another, the internal division depends on the success of our business, but the external company does not.
In addition, working with an external provider involves a certain formalization of requests and the results obtained. And now the question is: are all internal units ready to clearly formulate their requests and can understand what exactly they were answered? People often come to me and ask me not at all about what they really need. It turns out that inside we still need someone who will act as a translator who knows the right people inside the company and understands how to communicate with an external supplier in his language. At the same time, this role implies the presence of a good technical expertise, almost the same as that needed to independently conduct investigations.
Consideration of the above arguments led us to the decision to leave APA as an internal service. Of course, in each case, the optimal solution may vary. Any arguments are a priori controversial due to the nature of the issue. I just share my experience.
Conclusion
All of the above is a version of the practical implementation of the process of analyzing and managing application performance in a large enterprise. In our case, it gives a good result. Over the past year, the APA has been involved in the investigation of many critical issues and in the vast majority of cases has played a key role in determining the root cause. Moreover, in many cases it was difficult to imagine how the errors found could be identified without involving APA methods. Our work is appreciated by management.
References
[1] en.wikipedia.org/wiki/Application_Performance_Management .
[2] “Retail IT Service Operation: Calculating the Impacts of Poor Application Performance Across a Business Ecosystem”. Enterprise Management Associates. 2011
[3] en.wikipedia.org/wiki/Enterprise_architecture_framework
[4] en.wikipedia.org/wiki/Information_Technology_Infrastructure_Library .