Scaling is easy
B2C portals are primarily expected to scale. Unfortunately, scaling is too often declared a question of Technology - just select a fashionable technology and all problems are resolved. The fact that this is not so can occur, most recently, already in production mode (on the working system).
Instead of waving a technological mace, I’ll talk about how to develop a highly accessible, scalable portal using a well-thought-out architecture and consciously abandoning a data model. The first part will describe general concepts, and possible scenarios and their solutions will follow.
Once upon a time, in the dark times of the beginning of the Internet, that is, somewhere at the end of the past - the beginning of this millennium, the question of choosing the right architecture often came down to choosing the right database. When the director of a startup asked the developers to build a new portal, the team mostly debated about whether to buy Oracle Enterprise Edition or whether a standard license could be dispensed with. Advanced companions experimented with Рёt , Versant or other object-oriented databases. After that, data models were created, which in most cases were database models, and all this before asking the question: what, in fact, should the system do, and how?
Today, 10 years and a bunch of interesting developments in the field of software later, everything happens very similar, except that instead of choosing Oracle or Informix they argue about whether to take Mongo , Hadoop or ElasticSearch . Without a doubt, these are good and very useful technologies. However, the choice of technology should not precede the choice of architecture! In other words: technology, no matter how advanced it is, should serve the architecture, performing certain tasks within its framework. These tasks should be determined by the architecture and system requirements. Technology First
Approach, which can often be found in software development trenches, is very attractive for a technically poorly-guided guide: “If startup X uses Mongo, Bootstrap, ElasticSearch and / or Ruby, then this cocktail will help me, and if not, I will always give up by investors: they say that he used all the most fashionable technologies and that means he’s not to blame ! ”Unfortunately (for the fate of a startup and fortunately for everyone else), this approach rarely leads to the correct solution of a specific problem .
I advocate the opposite approach: Architecture First . This means that the problem is solved primarily architecturally, and technology is only a way to implement the architecture. Accordingly, technology is only part of the solution.and only when it brings concrete benefits in the context of this decision.
Here is an example.
For many years, people tried to solve all the problems of portal building with the help of relational DBMS, and for many years all attempts to scale these portals were crowned with dust as soon as Schema (DB Scheme) became quite complicated. As a result of this disaster, a generation of RDBMS heirs appeared - NoSQL DBMS (whether NoSQL databases are something fundamentally new or just reanimation of old ideas, in this context it does not matter). Another thing is interesting: the success of NoSQL DBMS is based on the fact that they recognized the main problem of SQL DBMS, namely Joins , and they simply do not support them. But if you build the architecture so that you can do without Joins, that isconsciously refuse them , then the good old SQL databases are scaled without any problems.
Before talking about how to find the right architecture that will support such standard requirements as flexibility (scalability) , scalability (scalability) and manageability (controllability), you need to decide: what, in fact, is architecture? Opinions differ here. Some consider architecture as a very abstract form of descriptions of system requirements, a kind of requirement analysis; others are like class distributing packages. A wide selection of diverse definitions of software architecture can be found on this page .
I consider the most successful as follows:
In other words, architecture deals with the components of the system and the communication between them. This definition is based on the concept of components , but what is a component?
Components are the components of our architectural thought, which we determine by various criteria: in particular, I - by responsibility for any business process or data.
A separate component is a set of entities (for example, classes / objects) that perform a common task. For example, MessagingService is a component responsible for sending messages and consisting of several classes (including the MessagingService interface itself).
The size of the component should be as small as possible, but sufficient to solve the problem (for Messaging - sending and receiving messages).
Returning to B2C portals, we note their common, from the point of view of architecture, properties:
One of the most popular architectures for building such portals is service-oriented (SOA). In the recent past, its reputation has been affected by the popularity of WebServices , an architecture that has little in common with SOA, but is often confused with it. SOA, being an architecture much older and more mature than WebServices, when used correctly offers a solution to many scaling problems.
From an architectural point of view, components in SOA are services and clients, and each component can be both at the same time. The externally visible properties of a component are the interfaces that it publishes. As for the relations between the components, there are two types of them:
Direct communication is similar to a phone call to a taxi or pizza ordering service; indirect communication is comparable to a ticker on a stock board that appears regardless of whether someone reads it or not. Interviewed methods, like listening data, are interfaces from the point of view of architecture, that is, means of communication with the component.
One of the basic and most useful principles of SOA: isolating components from each other. Among other things, this means that each component is the absolute owner of its data. No one has the right to change them without informing the owner at least, or better, asking him to make the modification himself.
Service-oriented architecture has a lot of geeks, but its main advantage is the lack of a global data model. The interfaces of each specific component is all that is known about it “outside”. His inner life remains a purely personal matter, not known to anyone. This principle has not only supporters - it is so convenient to conduct a complex investigation using one (three-story) SQL query! Yes, it’s true, the connection between the data of different services at the DBMS level could be of some benefit in the investigation, statistical analysis and data mining ( data mining, in-depth, or data mining). But where is it said that these relationships must exist in the work environment? If someone needs data for analysis, no one bothers to regularly transfer them from the working system to the analytical one, and at the same time create as many and any kind of connections as you want, as well as turn the data sideways, upside down or whatever else you like. But the working system itself should not be contaminated with these "offal" - ballast, which makes a brisk, slow "Passat" out of a nimble, fast "Ferrari".
The voluntary abandonment of the global data model in terms of system architecture means the following:
In order to fully enjoy the benefits of SOA, services must be correctly “chopped”. Large, monstrous services often turn into an "application in an application", and are themselves prone to the problems that we were going to overcome. Too finely chopped services lead to overhead communication, which kills all scaling at the root. How to find the right service size?
The easiest way to do this is to adhere to the following two software development paradigms: Design by Responsibility and Layer Isolation . With the help of the latter, it is possible to determine the fundamental boundaries of the responsibility of services - what is a service (like business logic) and what is not (for example, presentation logic). Design by Responsibilityhelps to cut services vertically, breaking them down by subject or functional specialization (messaging, search, etc.).
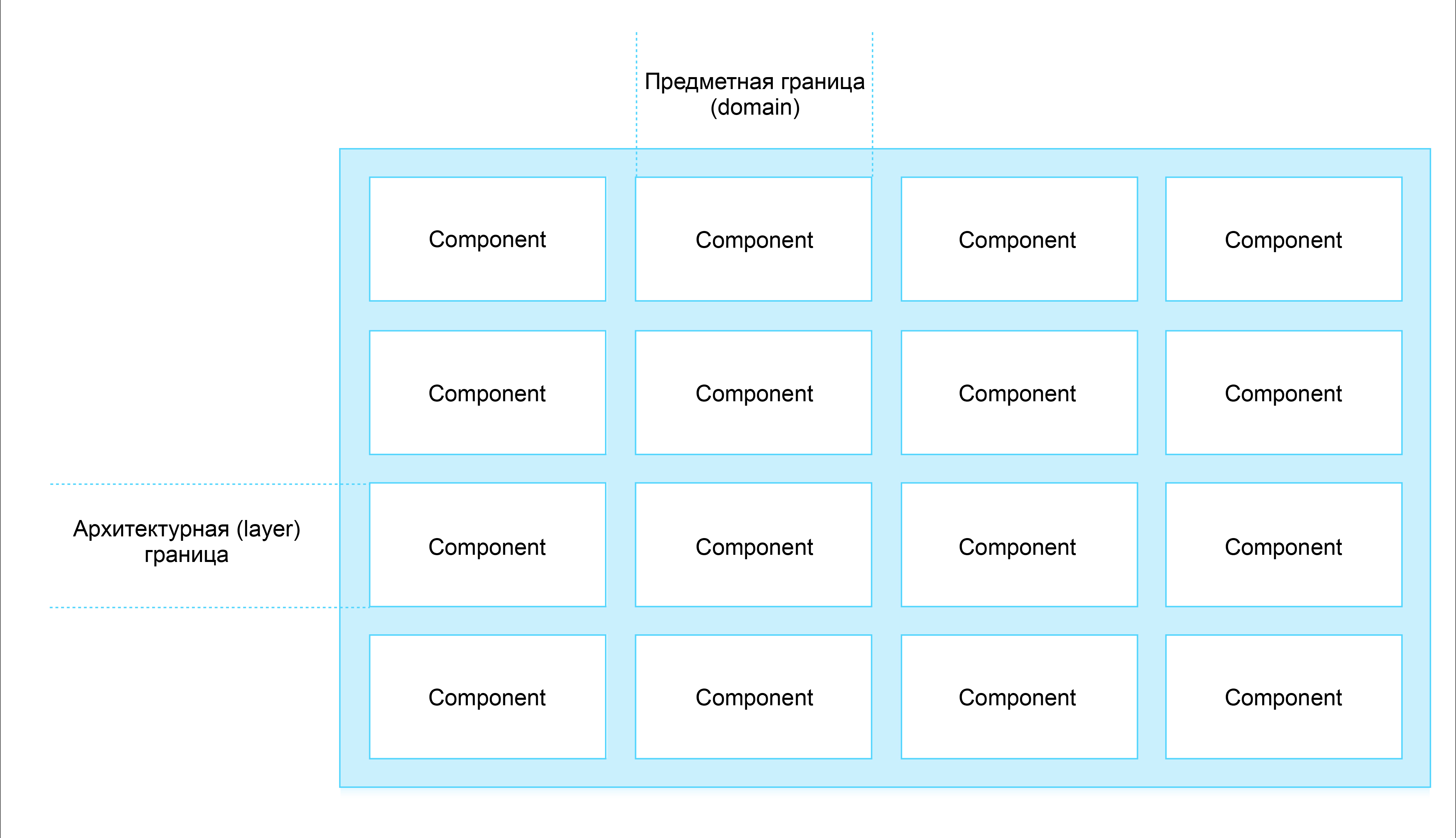
Scheme 1: Correct cutting of services
After correctly identifying services, you need to think about how they should "communicate" with each other.
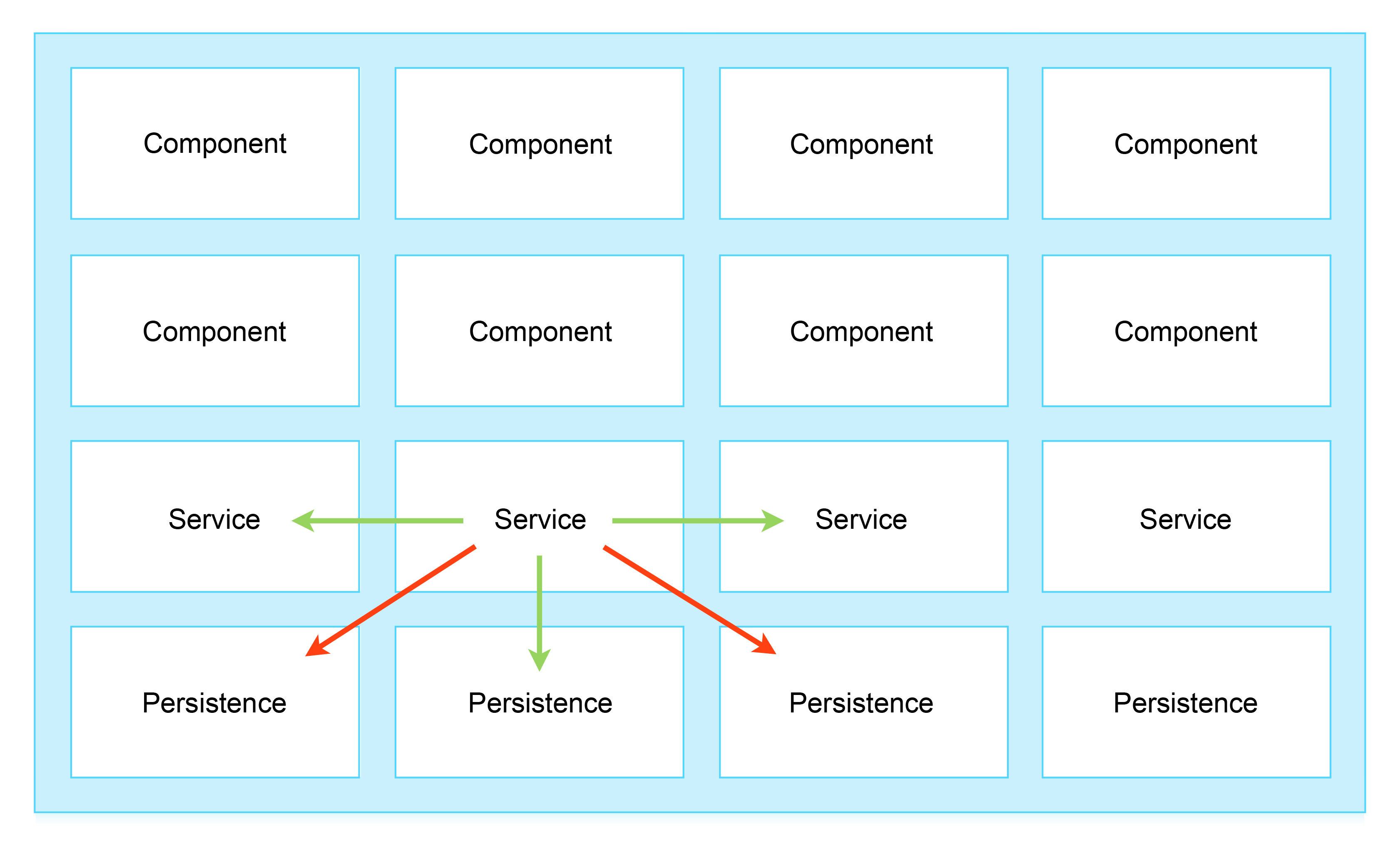
Figure 2: Allowed (green) and forbidden (red) communication paths
The generally accepted model of layers is vertical. At the top is the presentation layer, at the bottom - persistent. Therefore, developers usually start with persistence and create a global data model. In fact, in SOA you need to start from the middle :
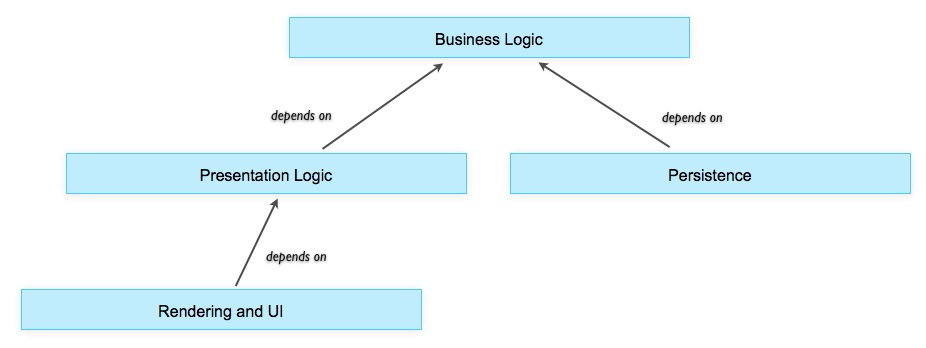
Scheme 3: Dependencies between layers
Thus, we can create a real service model in which each specific persistence meets the needs of its service, and only it. This leads to the strict isolation required for scaling:
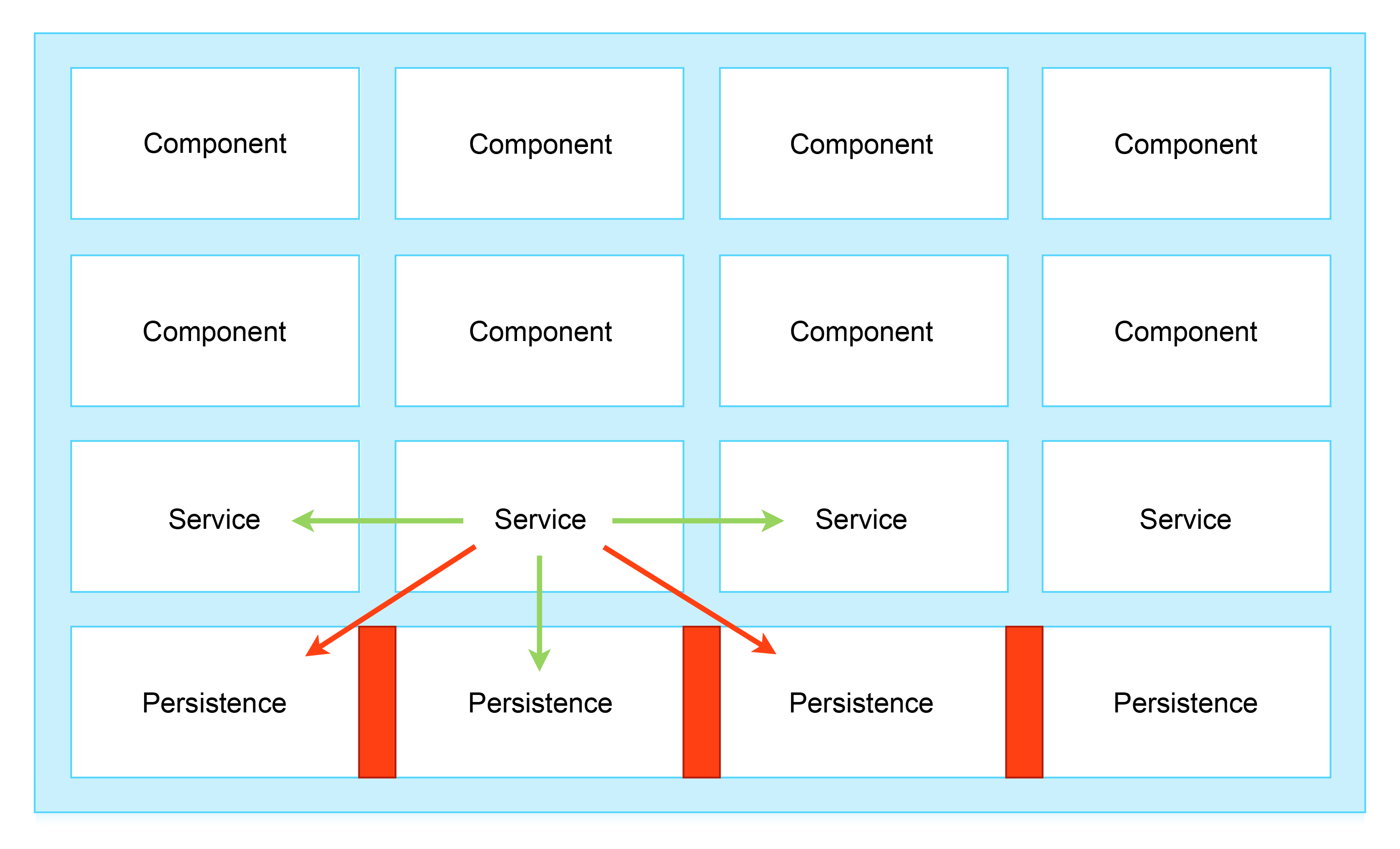
Figure 4: Isolation of persistences
Another paradigm that is absolutely necessary to follow is KISS (Keep it Simple, Stupid). Regarding software architecture, KISS means that only absolutely necessary components should be part of our architecture. Anything that is not directly beneficial, and fashionable technology may be relevant, should be ruled out. In other words, only those technologies that justify the costs of their support deserve the right to enter the final solution.
But now, finally, the time has come when the services are designed and written, and it's time to throw breasts at the embrasure - that is, under the real load of real users. Before launch, we often do not know what load a particular component will withstand. Of course, it is good to have a realistic stress test. The problem is that to write a good test we need to know the real behavior of users, and to find out the real behavior of users, we need to ... start up.
Nevertheless, it is not at all scary to engage in tuning after starting up in the operating mode, because we all remember well what premature optimization is. It is important to monitor (Hi MoSKito !) Each component in order to recognize bottlenecks in time and respond tofull overload of this component. Knowing such a bottleneck, we have different response capabilities. We will talk about two of them, Caches and Routing, in the following parts .
Instead of waving a technological mace, I’ll talk about how to develop a highly accessible, scalable portal using a well-thought-out architecture and consciously abandoning a data model. The first part will describe general concepts, and possible scenarios and their solutions will follow.
Part one. Theory.
Once upon a time, in the dark times of the beginning of the Internet, that is, somewhere at the end of the past - the beginning of this millennium, the question of choosing the right architecture often came down to choosing the right database. When the director of a startup asked the developers to build a new portal, the team mostly debated about whether to buy Oracle Enterprise Edition or whether a standard license could be dispensed with. Advanced companions experimented with Рёt , Versant or other object-oriented databases. After that, data models were created, which in most cases were database models, and all this before asking the question: what, in fact, should the system do, and how?
Today, 10 years and a bunch of interesting developments in the field of software later, everything happens very similar, except that instead of choosing Oracle or Informix they argue about whether to take Mongo , Hadoop or ElasticSearch . Without a doubt, these are good and very useful technologies. However, the choice of technology should not precede the choice of architecture! In other words: technology, no matter how advanced it is, should serve the architecture, performing certain tasks within its framework. These tasks should be determined by the architecture and system requirements. Technology First
Approach, which can often be found in software development trenches, is very attractive for a technically poorly-guided guide: “If startup X uses Mongo, Bootstrap, ElasticSearch and / or Ruby, then this cocktail will help me, and if not, I will always give up by investors: they say that he used all the most fashionable technologies and that means he’s not to blame ! ”Unfortunately (for the fate of a startup and fortunately for everyone else), this approach rarely leads to the correct solution of a specific problem .
I advocate the opposite approach: Architecture First . This means that the problem is solved primarily architecturally, and technology is only a way to implement the architecture. Accordingly, technology is only part of the solution.and only when it brings concrete benefits in the context of this decision.
Here is an example.
For many years, people tried to solve all the problems of portal building with the help of relational DBMS, and for many years all attempts to scale these portals were crowned with dust as soon as Schema (DB Scheme) became quite complicated. As a result of this disaster, a generation of RDBMS heirs appeared - NoSQL DBMS (whether NoSQL databases are something fundamentally new or just reanimation of old ideas, in this context it does not matter). Another thing is interesting: the success of NoSQL DBMS is based on the fact that they recognized the main problem of SQL DBMS, namely Joins , and they simply do not support them. But if you build the architecture so that you can do without Joins, that isconsciously refuse them , then the good old SQL databases are scaled without any problems.
Architecture - what is it?
Before talking about how to find the right architecture that will support such standard requirements as flexibility (scalability) , scalability (scalability) and manageability (controllability), you need to decide: what, in fact, is architecture? Opinions differ here. Some consider architecture as a very abstract form of descriptions of system requirements, a kind of requirement analysis; others are like class distributing packages. A wide selection of diverse definitions of software architecture can be found on this page .
I consider the most successful as follows:
Architecture (software) is the structure of the system, consisting of components, the visible properties of these components and the relationships between them.
In other words, architecture deals with the components of the system and the communication between them. This definition is based on the concept of components , but what is a component?
Components are the components of our architectural thought, which we determine by various criteria: in particular, I - by responsibility for any business process or data.
A separate component is a set of entities (for example, classes / objects) that perform a common task. For example, MessagingService is a component responsible for sending messages and consisting of several classes (including the MessagingService interface itself).
The size of the component should be as small as possible, but sufficient to solve the problem (for Messaging - sending and receiving messages).
Returning to B2C portals, we note their common, from the point of view of architecture, properties:
- high ratio between reading and writing operations: the number of readers can be 9-10 times higher than those who write;
- clearly distinguishable functionalities - for example, internal messaging or a profile;
- Portal traffic is subject to spikes that create the plural of normal load based on the time of day, week or year;
- portals are constantly and rapidly changing. This applies to code, and content, and data.
General architectural principles
One of the most popular architectures for building such portals is service-oriented (SOA). In the recent past, its reputation has been affected by the popularity of WebServices , an architecture that has little in common with SOA, but is often confused with it. SOA, being an architecture much older and more mature than WebServices, when used correctly offers a solution to many scaling problems.
From an architectural point of view, components in SOA are services and clients, and each component can be both at the same time. The externally visible properties of a component are the interfaces that it publishes. As for the relations between the components, there are two types of them:
- Direct or synchronous communication is a method call, that is, a client accesses a service.
- Indirect or asynchronous communication is an alert about a state change (event), which a component publishes “in secret to the whole world”, without worrying about whether it has specific listeners.
Direct communication is similar to a phone call to a taxi or pizza ordering service; indirect communication is comparable to a ticker on a stock board that appears regardless of whether someone reads it or not. Interviewed methods, like listening data, are interfaces from the point of view of architecture, that is, means of communication with the component.
Isolation to the bone marrow (to the database)
One of the basic and most useful principles of SOA: isolating components from each other. Among other things, this means that each component is the absolute owner of its data. No one has the right to change them without informing the owner at least, or better, asking him to make the modification himself.
Service-oriented architecture has a lot of geeks, but its main advantage is the lack of a global data model. The interfaces of each specific component is all that is known about it “outside”. His inner life remains a purely personal matter, not known to anyone. This principle has not only supporters - it is so convenient to conduct a complex investigation using one (three-story) SQL query! Yes, it’s true, the connection between the data of different services at the DBMS level could be of some benefit in the investigation, statistical analysis and data mining ( data mining, in-depth, or data mining). But where is it said that these relationships must exist in the work environment? If someone needs data for analysis, no one bothers to regularly transfer them from the working system to the analytical one, and at the same time create as many and any kind of connections as you want, as well as turn the data sideways, upside down or whatever else you like. But the working system itself should not be contaminated with these "offal" - ballast, which makes a brisk, slow "Passat" out of a nimble, fast "Ferrari".
The voluntary abandonment of the global data model in terms of system architecture means the following:
- The data model is replaced by the service model. It could be called an Enterprise model if this word had not been used left and right, for which it would have to. A service model consists of the services in the system, the artifacts they manage, and the relationships between these artifacts.
- Each service and each component is completely free to choose their persistence. A service that manages well-structured data can write it to an SQL database; a blobs service , be it pictures or large texts, may use more appropriate persistence methods.
- The load on services varies within the system. In a 2-tier (two-tier) database-oriented system, load growth always falls on the entire system. In SOA, it’s easy to identify the service, the load on which has grown, which makes it possible to deal with it in this place, by optimization or scaling.
In order to fully enjoy the benefits of SOA, services must be correctly “chopped”. Large, monstrous services often turn into an "application in an application", and are themselves prone to the problems that we were going to overcome. Too finely chopped services lead to overhead communication, which kills all scaling at the root. How to find the right service size?
The easiest way to do this is to adhere to the following two software development paradigms: Design by Responsibility and Layer Isolation . With the help of the latter, it is possible to determine the fundamental boundaries of the responsibility of services - what is a service (like business logic) and what is not (for example, presentation logic). Design by Responsibilityhelps to cut services vertically, breaking them down by subject or functional specialization (messaging, search, etc.).
Scheme 1: Correct cutting of services
After correctly identifying services, you need to think about how they should "communicate" with each other.
Figure 2: Allowed (green) and forbidden (red) communication paths
How to avoid a global data model?
The generally accepted model of layers is vertical. At the top is the presentation layer, at the bottom - persistent. Therefore, developers usually start with persistence and create a global data model. In fact, in SOA you need to start from the middle :
Scheme 3: Dependencies between layers
Thus, we can create a real service model in which each specific persistence meets the needs of its service, and only it. This leads to the strict isolation required for scaling:
Figure 4: Isolation of persistences
Another paradigm that is absolutely necessary to follow is KISS (Keep it Simple, Stupid). Regarding software architecture, KISS means that only absolutely necessary components should be part of our architecture. Anything that is not directly beneficial, and fashionable technology may be relevant, should be ruled out. In other words, only those technologies that justify the costs of their support deserve the right to enter the final solution.
Good architecture has many cogs
But now, finally, the time has come when the services are designed and written, and it's time to throw breasts at the embrasure - that is, under the real load of real users. Before launch, we often do not know what load a particular component will withstand. Of course, it is good to have a realistic stress test. The problem is that to write a good test we need to know the real behavior of users, and to find out the real behavior of users, we need to ... start up.
Nevertheless, it is not at all scary to engage in tuning after starting up in the operating mode, because we all remember well what premature optimization is. It is important to monitor (Hi MoSKito !) Each component in order to recognize bottlenecks in time and respond tofull overload of this component. Knowing such a bottleneck, we have different response capabilities. We will talk about two of them, Caches and Routing, in the following parts .