GraphQL future of microservices?
- Transfer
- Tutorial
GraphQL is often presented as a revolutionary way for web API design compared to REST. However, if you take a closer look at these technologies, you will see that there are so many differences between them. GraphQL is a relatively new solution, the source code of which was opened to the Facebook community in 2015. Today, REST is still the most popular paradigm used to provide API and interoperability between microservices. Can GraphQL overtake REST in the future? Let's take a look at how microservice interaction occurs through the GraphQL API using the Spring Boot and the GQL library .
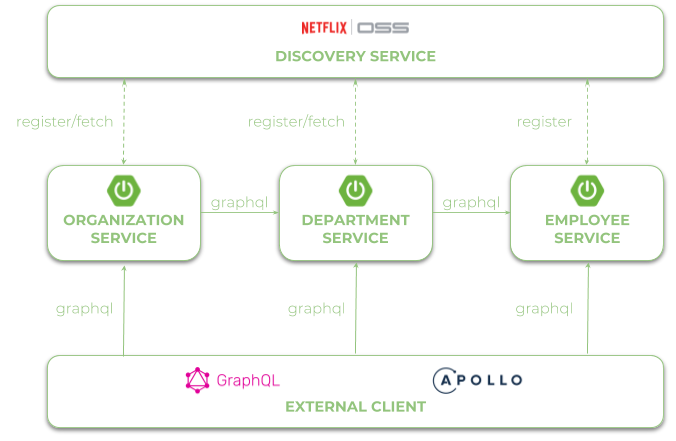
Let's start with the architecture of our system example. Suppose that we have three microservices that communicate with each other through the URL obtained from the Spring Cloud Eureka application.
We can easily enable support for GraphQL on the server side of the Spring Boot application using starters. After adding the graphql-spring-boot-starter, the GraphQL servlet will be automatically accessible via the path / graphql. We can override this default path by specifying the graphql.servlet.mapping property in the application.yml file. We also include the GraphiQL browser-based IDE for writing, testing, and testing GraphQL queries and the GraphQL Java Tools library, which contains useful components for creating queries and mutations. Thanks to this library, all files in the classpath with the .graphqls extension will be used to create the schema definition.
Each schema description contains a type declaration, relationships between them, and a variety of operations involving queries to find objects and mutations to create, update, or delete data. Usually we begin with a type definition that is responsible for the domain of the object being described. You can specify whether the field is required using the
The next part of the schema definition contains the declaration of requests and mutations. Most queries return a list of objects that are labeled as [Employee] in the schema. Inside the EmployeeQueries type, we declare all the search methods, while in the EmployeeMutations type we add, update, and delete employees. If you pass an entire object to a method, you must declare it as an input type.
Thanks to GraphQL Java Tools autoconfiguration and Spring Boot GraphQL, we don’t need to make a lot of effort to implement queries and mutations in our application. The EmployeesQuery bean must implement the GraphQLQueryResolver interface. Based on this, Spring will be able to automatically find and call the right method as an answer to one of the GraphQL queries that were declared inside the schema. Here is the class containing the implementation of responses to requests:
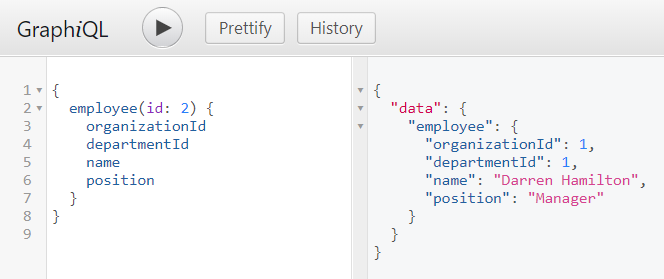
If you want to call, for example, the employee (Long id) method, write the following query. To test it in your application, use GraphiQL, which is available at / graphiql.
The bin responsible for the implementation of mutation methods needs to implement the GraphQLMutationResolver interface. Despite the name EmployeeInput, we continue to use the same domain object Employee that is returned by the query.
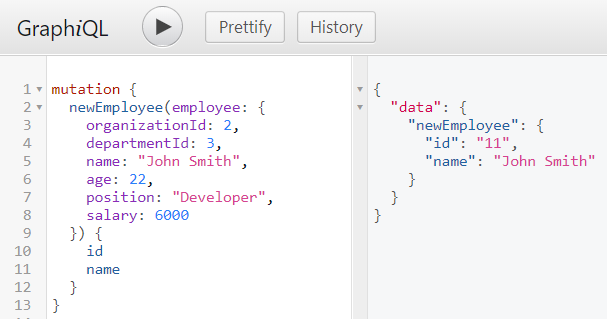
And here we use GraphiQL to test mutations. Here is a team that adds a new employee and accepts the answer with the employee id and name.
With this, I suspend the translation of this article and write my “lyrical digression”, and in fact I substitute the description of the part of the microservice interaction through the Apollo Client, for interaction through the GQL library and Unirest - the library for performing HTTP requests.
To create GraphQL queries in department-servive microservice, I will use Query builders :
This construction in GQL DSL creates a query of the form:
And, further, I will execute HTTP request on the address transferred to a method.
How the address of the request is formed will be found later.
After receiving the answer, we perform its conversion from JSONObject to the form of the list Employee.
Consider the implementation of microservice employees. In this example, I used Eureka client directly. eurekaClient gets all running instances of services registered as employee-service. Then he randomly selects one of the registered copies (2). Next, it takes its port number and forms the request address (3) and sends it to the EmployeeGQL object, which is a GraphQL client on Groovy and, which is described in the previous paragraph.
Further, I “hand over” the word to the author again, or rather continue the translation of his article.
Finally, EmployeeClient is implemented in a class that responds to DepartmentQueries requests and is used inside departmentsByOrganizationWithEmployees.
Before executing the necessary requests, we follow a look at the scheme created for the department-service. Each Department object may contain a list of assigned employees, and we also defined the type of Employee referred to by the Department type.
Now we can call our test query with a list of the required fields using GraphiQL. The department-service application is available by default on port 8091, that is, we can see it at http: // localhost: 8091 / graphiql
Perhaps GraphQL may be an interesting alternative to the standard REST API. However, we should not consider it as a replacement for REST. There are several cases where GraphQL may be the best choice, but those where REST is the best choice. If your clients do not need to have all the fields returned by the server side, and moreover, you have many clients with different requirements for one entry point, then GraphQL is a good choice. If you look at what is in the microservice community, you can see that now there is no Java-based solution that allows you to use GraphQL with service discovery, balancer, or API gateway out of the box. In this article, I showed an example of using GQL and Unirest to create a GraphQL client with Spring Cloud Eureka for microservice communication.github.com/piomin/sample-graphql-microservices.git .
My example when with the GQL library : github.com/lynx-r/sample-graphql-microservices
Let's start with the architecture of our system example. Suppose that we have three microservices that communicate with each other through the URL obtained from the Spring Cloud Eureka application.
Enable GraphQL Support in Spring Boot
We can easily enable support for GraphQL on the server side of the Spring Boot application using starters. After adding the graphql-spring-boot-starter, the GraphQL servlet will be automatically accessible via the path / graphql. We can override this default path by specifying the graphql.servlet.mapping property in the application.yml file. We also include the GraphiQL browser-based IDE for writing, testing, and testing GraphQL queries and the GraphQL Java Tools library, which contains useful components for creating queries and mutations. Thanks to this library, all files in the classpath with the .graphqls extension will be used to create the schema definition.
compile('com.graphql-java:graphql-spring-boot-starter:5.0.2')
compile('com.graphql-java:graphiql-spring-boot-starter:5.0.2')
compile('com.graphql-java:graphql-java-tools:5.2.3')
Description GrpahQL schema
Each schema description contains a type declaration, relationships between them, and a variety of operations involving queries to find objects and mutations to create, update, or delete data. Usually we begin with a type definition that is responsible for the domain of the object being described. You can specify whether the field is required using the
!symbol or if it is an array - […]. The description must contain a declared type or reference to other types available in the specification.typeEmployee {
id: ID!
organizationId: Int!
departmentId: Int!
name: String!
age: Int!
position: String!
salary: Int!
}The next part of the schema definition contains the declaration of requests and mutations. Most queries return a list of objects that are labeled as [Employee] in the schema. Inside the EmployeeQueries type, we declare all the search methods, while in the EmployeeMutations type we add, update, and delete employees. If you pass an entire object to a method, you must declare it as an input type.
schema {
query: EmployeeQueries
mutation: EmployeeMutations
}
typeEmployeeQueries {
employees: [Employee]
employee(id: ID!): Employee!
employeesByOrganization(organizationId: Int!): [Employee]
employeesByDepartment(departmentId: Int!): [Employee]
}typeEmployeeMutations {
newEmployee(employee: EmployeeInput!): EmployeedeleteEmployee(id: ID!) : BooleanupdateEmployee(id: ID!, employee: EmployeeInput!): Employee
}inputEmployeeInput {
organizationId: Int
departmentId: Int
name: String
age: Int
position: String
salary: Int
}
Implementation of requests and mutations
Thanks to GraphQL Java Tools autoconfiguration and Spring Boot GraphQL, we don’t need to make a lot of effort to implement queries and mutations in our application. The EmployeesQuery bean must implement the GraphQLQueryResolver interface. Based on this, Spring will be able to automatically find and call the right method as an answer to one of the GraphQL queries that were declared inside the schema. Here is the class containing the implementation of responses to requests:
@ComponentpublicclassEmployeeQueriesimplementsGraphQLQueryResolver{
privatestaticfinal Logger LOGGER = LoggerFactory.getLogger(EmployeeQueries.class);
@Autowired
EmployeeRepository repository;
public List employees(){
LOGGER.info("Employees find");
return repository.findAll();
}
public List employeesByOrganization(Long organizationId){
LOGGER.info("Employees find: organizationId={}", organizationId);
return repository.findByOrganization(organizationId);
}
public List employeesByDepartment(Long departmentId){
LOGGER.info("Employees find: departmentId={}", departmentId);
return repository.findByDepartment(departmentId);
}
public Employee employee(Long id){
LOGGER.info("Employee find: id={}", id);
return repository.findById(id);
}
}
If you want to call, for example, the employee (Long id) method, write the following query. To test it in your application, use GraphiQL, which is available at / graphiql.
The bin responsible for the implementation of mutation methods needs to implement the GraphQLMutationResolver interface. Despite the name EmployeeInput, we continue to use the same domain object Employee that is returned by the query.
@ComponentpublicclassEmployeeMutationsimplementsGraphQLMutationResolver{
privatestaticfinal Logger LOGGER = LoggerFactory.getLogger(EmployeeQueries.class);
@Autowired
EmployeeRepository repository;
public Employee newEmployee(Employee employee){
LOGGER.info("Employee add: employee={}", employee);
return repository.add(employee);
}
publicbooleandeleteEmployee(Long id){
LOGGER.info("Employee delete: id={}", id);
return repository.delete(id);
}
public Employee updateEmployee(Long id, Employee employee){
LOGGER.info("Employee update: id={}, employee={}", id, employee);
return repository.update(id, employee);
}
}
And here we use GraphiQL to test mutations. Here is a team that adds a new employee and accepts the answer with the employee id and name.
With this, I suspend the translation of this article and write my “lyrical digression”, and in fact I substitute the description of the part of the microservice interaction through the Apollo Client, for interaction through the GQL library and Unirest - the library for performing HTTP requests.
GraphQL client on Groovy.
To create GraphQL queries in department-servive microservice, I will use Query builders :
String queryString = DSL.buildQuery {
query('employeesByDepartment', [departmentId: departmentId]) {
returns {
id
name
position
salary
}
}
}
This construction in GQL DSL creates a query of the form:
{
employeesByDepartment (departmentId: 1) {
id
name
position
salary
}
}
And, further, I will execute HTTP request on the address transferred to a method.
How the address of the request is formed will be found later.
(Unirest.post(serverUrl)
.body(JsonOutput.toJson([query: queryString]))
.asJson()
.body.jsonObject['data']['employeesByDepartment'] as List)
.collect { JsonUtils.jsonToData(it.toString(), Employee.class) }
After receiving the answer, we perform its conversion from JSONObject to the form of the list Employee.
GrpahQL client for microservice employees
Consider the implementation of microservice employees. In this example, I used Eureka client directly. eurekaClient gets all running instances of services registered as employee-service. Then he randomly selects one of the registered copies (2). Next, it takes its port number and forms the request address (3) and sends it to the EmployeeGQL object, which is a GraphQL client on Groovy and, which is described in the previous paragraph.
@ComponentpublicclassEmployeeClient{
privatestaticfinal Logger LOGGER = LoggerFactory.getLogger(EmployeeClient.class);
privatestaticfinal String SERVICE_NAME = "EMPLOYEE-SERVICE";
privatestaticfinal String SERVER_URL = "http://localhost:%d/graphql";
Random r = new Random();
@Autowiredprivate EurekaClient discoveryClient; // (1)public List<Employee> findByDepartment(Long departmentId){
Application app = discoveryClient.getApplication(SERVICE_NAME);
InstanceInfo ii = app.getInstances().get(r.nextInt(app.size())); // (2)
String serverUrl = String.format(SERVER_URL, ii.getPort()); // (3)
EmployeeGQL clientGQL = new EmployeeGQL();
return clientGQL.getEmployeesByDepartmentQuery(serverUrl, departmentId.intValue()); // (4)
}
}
Further, I “hand over” the word to the author again, or rather continue the translation of his article.
Finally, EmployeeClient is implemented in a class that responds to DepartmentQueries requests and is used inside departmentsByOrganizationWithEmployees.
public List<Department> departmentsByOrganizationWithEmployees(Long organizationId){
LOGGER.info("Departments find: organizationId={}", organizationId);
List<Department> departments = repository.findByOrganization(organizationId);
for (int i = 0; i < departments.size(); i++) {
departments.get(i).setEmployees(employeeClient.findByDepartment(departments.get(i).getId()));
}
return departments;
}
Before executing the necessary requests, we follow a look at the scheme created for the department-service. Each Department object may contain a list of assigned employees, and we also defined the type of Employee referred to by the Department type.
schema {
query: DepartmentQueries
mutation: DepartmentMutations
}
typeDepartmentQueries {
departments: [Department]
department(id: ID!): Department!
departmentsByOrganization(organizationId: Int!): [Department]
departmentsByOrganizationWithEmployees(organizationId: Int!): [Department]
}typeDepartmentMutations {
newDepartment(department: DepartmentInput!): DepartmentdeleteDepartment(id: ID!) : BooleanupdateDepartment(id: ID!, department: DepartmentInput!): Department
}inputDepartmentInput {
organizationId: Int!
name: String!
}
typeDepartment {
id: ID!
organizationId: Int!
name: String!
employees: [Employee]
}typeEmployee {
id: ID!
name: String!
position: String!
salary: Int!
}Now we can call our test query with a list of the required fields using GraphiQL. The department-service application is available by default on port 8091, that is, we can see it at http: // localhost: 8091 / graphiql
Conclusion
Perhaps GraphQL may be an interesting alternative to the standard REST API. However, we should not consider it as a replacement for REST. There are several cases where GraphQL may be the best choice, but those where REST is the best choice. If your clients do not need to have all the fields returned by the server side, and moreover, you have many clients with different requirements for one entry point, then GraphQL is a good choice. If you look at what is in the microservice community, you can see that now there is no Java-based solution that allows you to use GraphQL with service discovery, balancer, or API gateway out of the box. In this article, I showed an example of using GQL and Unirest to create a GraphQL client with Spring Cloud Eureka for microservice communication.github.com/piomin/sample-graphql-microservices.git .
My example when with the GQL library : github.com/lynx-r/sample-graphql-microservices