TiKV - distributed key-value database for cloud native

On August 28, CNCF (Cloud Native Computing Foundation), behind Kubernetes, Prometheus and other open source projects for modern cloud applications, announced the adoption of a new product in its sandbox - TiKV .
This distributed, key-value transactional database was born as an addition to TiDB — a distributed DBMS that offers OLTP and OLAP capabilities and ensures compatibility with the MySQL protocol ... But let's get everything in order.
TiDB as a parent
Let's start with the "parent" project TiDB, created by the Chinese company PingCAP Inc.

The first major public release of this DBMS, 1.0, took place less than a year ago. Its main features are “hybridity”, combining transactional and analytical data processing (Hybrid Transactional / Analytical Processing, HTAP), as well as the already mentioned compatibility with the MySQL protocol. A fuller picture of TiDB arises at the mention of others — already common for new DBMS features such as horizontal scalability, high availability, and strict ACID compliance.
The overall architecture of TiDB is as follows:
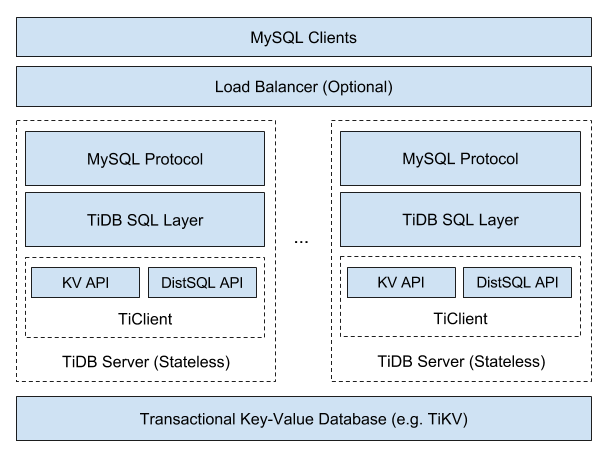
Since TiDB offers NoSQL scalability and ACID guarantees, it is categorized as NewSQL. The authors do not hide the fact that they created the product under inspiration from other representatives of NewSQL: Google Spanner and F1 . However, Chinese developers insisted on "their best practices and solutions when choosing technologies." In particular, they chose an algorithm for solving the consensus problems of Raft (instead of Paxos , which is used in Spanner), the RocksDB repository (instead of the distributed file system), and Go (and Rust) as the programming language.
Many details about the TiDB device can be found in the “ How we build TiDB ” report from the co-founder and CEO of PingCAP, Max Liu, and we will return to some of them closely related to TiKV. TiDB source codedistributed under the free Apache License v2. Among its major users are Lenovo, Meizu, Bank of Beijing, Industrial and Commercial Bank of China, etc.
What is TiKV and what role does it play in the world of TiDB (and not only)?
Architecture and features of TiKV
Let's return to the overall TiDB architecture, in a slightly different way:

You can see that TiDB itself provides SQL implementation and compatibility with MySQL *, and entrusts the rest of the work to the TiKV cluster. What is this “other work”? Here is a more detailed diagram:
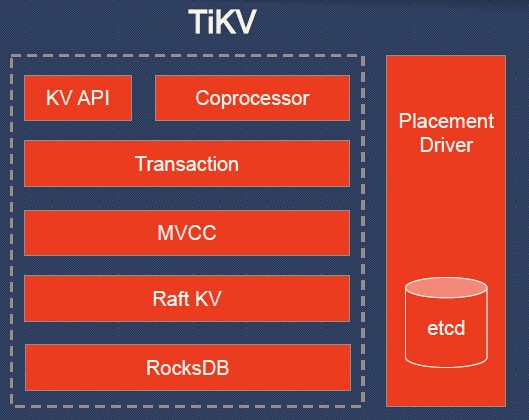
* In two pictures about the MySQL compatibility layer in TiDB.
The conversion of tables to key-value happens in such a way that from queries:
... it

turns out : Indexes in TiDB are ordinary pairs, the values of which indicate a data line:

INSERTINTOuserVALUES (1, "bob", "huang@pingcap.com");
INSERTINTOuserVALUES (2, "tom", "tom@pingcap.com");... it
turns out : Indexes in TiDB are ordinary pairs, the values of which indicate a data line:
Explanation of the scheme TiKV:
- KV API - a set of software interfaces for writing / reading data;
- Coprocessor - a coprocessor framework to support distributed computing (compares with that of HBase);
- Transaction is a transactional model similar to Google Percolator ( commits protocol in 2 phases; uses timestamp allocator; see also comparison with Spanner );
- MVCC (MultiVersion Concurrency Control) to provide reads without locks and ACID transactions (data is tagged by versions; any changes made in the current transaction are not visible to other transactions until the time of the commit);
- Raft KV - the already mentioned Raft algorithm used for horizontal scaling and data consistency; its implementation in the Rust language is ported from etcd (tested by extensive exploitation); by the way, the authors of TiKV declared “simple scalability up to 100+ TB of data”;
- RocksDB - local storage of key-value type, which has also already proven itself in large-scale projects in production (Facebook);
- Placement Driver is the “brain” of the cluster, created according to the concept from Google Spanner and responsible for storing the metadata about the regions, maintaining the necessary number of replicas, and evenly distributing the loads (using Raft).

If you summarize the relationship of the main components, you get the following:
- Each node of the TiKV cluster has one or more repositories (RocksDB).
- Each repository has many regions .
- The region is the “base unit of movement of key-value data”, replicated (using Raft) to multiple nodes. Such replica sets form the Raft group .
- Finally, the Manager of this cluster Placement Driver, as you can see, is itself a cluster.
Install and Test TiKV
The TiKV codebase is written primarily in Rust, but it also has several third-party components in other languages (RocksDB in C ++ and gRPC on Go). It is distributed under the same free Apache License v2.
As mentioned at the beginning of the article, TiKV initially appeared as an important component of TiDB, but today it can be used both within the framework of this DBMS and separately. (But in any case, its work will require a Placement Driver , written on Go and distributed as a separate component).
The shortest instruction for running TiKV along with a TiDB database requires Git, Docker (17.03+), Docker Compose (1.6.0+), MySQL Client and comes down to the following:
git clone https://github.com/pingcap/tidb-docker-compose.git
cd tidb-docker-compose && docker-compose pull
docker-compose up -dThe result of these commands will be the deployment of a TiDB cluster, which by default consists of the following components:
- 1 copy of TiDB itself;
- 3 copies of TiKV;
- 3 copies of Placement Driver;
- Prometheus and Grafana (for monitoring and graphs) ;
- 2 instances (master + slave) TiSpark (an interlayer for running Apache Spark over TiDB / TiKV to perform complex OLAP queries) ;
- 1 copy of TiDB-Vision (for visualizing the work of Placement Driver) .
Further work with the deployed DBMS:
- connect via the MySQL-client:
mysql -h 127.0.0.1 -P 4000 -u root; - web interface Grafana to view the status of the cluster -
http://localhost:3000under admin / admin; - TiDB-Vision web interface for cluster load balancing and node migration data
http://localhost:8010; - Spark web interface -
http://localhost:8080(access to TiSpark - throughspark://127.0.0.1:7077).
If you want a not quite standard TiDB cluster (i.e., change its dimensions, use Docker images, ports, etc.), then after cloning the tidb-docker-compose repository you can edit the config for Docker Compose:
$ cd tidb-docker-compose
$ vi compose/values.yaml
$ helm template compose > generated-docker-compose.yaml
$ docker-compose -f generated-docker-compose.yaml pull
$ docker-compose -f generated-docker-compose.yaml up -dFor even more customization, see “ Customize TiDB Cluster ”, where the information is described, where the configs for TiDB, TiKV, Placement Driver and other specifics come from.
For a convenient deployment of TiDB to the Kubernetes cluster, the eponymous operator, TiDB Operator, has been prepared . It is in the Helm-charts, so the installation can be reduced to the following commands (slide from the presentation on TiDB DevConf 2018):

By the way, the same presentation talks about the views of the TiDB developers on monitoring this DBMS. The text description, unfortunately, is in Chinese, but a general idea can be obtained from these slides:

Returning to the topic directly TiKV - this project has published its launch guidelines for test purposes:
- together with TiDB ;
- separately:
And for TiKV deployments in production there are ready-made developments with Ansible - again, with and without TiDB .
Finally, as interfaces for working with TiKV are offered:
The developers' plans also include the creation of a client on Rust.
Results
Having originated as a component of a larger Open Source-project of a Chinese company, TiKV has already managed to gain fame in wide enough circles. GitHub statistics show not only about 3600+ stars, but almost 500 forks, and almost 100 contributors (although more than 10 commits have made only two dozen of them).
The joining of TiKV to the number of CNCF projects and the fact that this is the first project of this type also clearly indicates that the product is recognized by the cloud native community ... and should give impetus to the active development of its third-party code base (i.e., outside the founding company and its DBMS a) specialists.
PS
Read also in our blog:
- “ Familiarity with the CockroachDB DBMS and the creation of a fault-tolerant cluster with it on Ubuntu 16.04 ”;
- “ Rook -“ self-service ”data store for Kubernetes ”;
- “ Accelerate the bootstrap of large databases using Kubernetes ”;
- " CNCF Guide to Open Source Solutions (and more) for cloud native ";
- " Operators for Kubernetes: how to run stateful applications ."