How did the Cossacks retro contest decide
In the spring of this year, a landmark Retro Contest from OpenAI was held, which was devoted to learning with reinforcements, meta learning and, of course, Sonic. Our team took the 4th place from 900+ teams. The field of study with reinforcement is slightly different from standard machine learning, and this contest was different from the typical RL competition. For details, I ask under the cat.

TL; DR
Properly zayucheny baseline does not need additional tricks ... practically.
Intro in training with reinforcements

Reinforced learning is an area that combines optimal control theory, game theory, psychology, and neuroscience. In practice, reinforcement learning is applied to solving decision-making problems and finding optimal behavior strategies, or policies that are too complex for “direct” programming. In this case, the agent is trained on the history of interactions with the environment. The environment, in turn, evaluating the agent's actions, provides him with a reward (scalar) - the better the agent's behavior, the greater the reward. As a result, the best policy is learned from the agent who learned to maximize the total reward for all the time of interaction with the environment.
As a very simple example, you can play BreakOut. In this good old Atari series, the person / agent needs to control the lower horizontal platform, hit the ball and gradually break all the upper blocks. The more knocked down - the greater the reward. Accordingly, what the person / agent sees is the image from the screen and it is required to decide in which direction to move the lower platform.

If you are interested in the topic of training with reinforcements, I recommend the steep introductory course from HSE , as well as its more detailed open source counterpart . If you want something that you can read, but with examples - a book inspired by these two courses. All these courses I reviewed / passed / helped in the creation, and therefore I know from my own experience that they provide an excellent basis.
About the task
The main purpose of this competition was to get an agent who could play well in a series of SEGA games - Sonic The Hedgehog. At that time, OpenAI was just starting to import games from SEGA to its platform for training RL agents, and thus decided to promote this moment a little. Even an article was published with a device of everything and a detailed description of the basic methods.
All 3 Sonic games were supported, each with 9 levels, on which, having brushed away a tear, you could even play, recalling childhood (having previously bought them on Steam).
The image from the simulator - RGB picture acted as the state of the environment (what the agent saw), and the agent was asked to select which button on the virtual joystick to press - jump / left / right and so on. The agent received the award points in the same way as in the original game, i.e. for collecting rings, as well as for the speed of passing the level. In fact, we had an original sonic in front of us, only we had to go through it with the help of our agent.
The competition was held from April 5 to June 5, i.e. only 2 months, which seems pretty small. Our team was able to get together and enter the competition only in May, which made us learn a lot on the go.
Baselines
As a baseline, full Rainbow (DQN approach) and PPO (Policy Gradient approach) training guides were given at one of the possible levels in Sonic and the resulting agent was released.
The Rainbow version was based on the little-known project anyrl , but PPO used the good old baselines from OpenAI and it seemed much more preferable to us.
From the approaches described in the article, the published baselines were distinguished by greater simplicity and smaller sets of “hacks” to accelerate learning. Thus, the organizers and ideas were thrown and the direction was set, but the decision on the use and implementation of these ideas remained with the competitor.
Regarding ideas, I want to thank OpenAI for openness, and in particular, John Schulman for the advice, ideas and suggestions he voiced at the very beginning of this competition. We, like many participants (and even more so for newcomers in the RL world), have allowed us to better focus on the main goal of the competition - meta learning and improved agent generalization, which we will now discuss.
Features of decision evaluation
The most interesting thing started at the moment of evaluating the agents. In typical RL competitions / benchmarks, algorithms are tested in the same environment where they were trained, which contributes to algorithms that are good at remembering and have many hyperparameters. In the same competition, the testing of the algorithm was carried out at the new Sonic levels (which were never shown to anyone) developed by the OpenAI team specifically for this competition. Cherry on the cake was the fact that in the process of testing the agent was also given a reward during the passage of the level, which made it possible to learn directly in the process of testing. However, in this case it was worth remembering that testing was limited both in time - 24 hours, and in game ticks - 1 million. At the same time, OpenAI strongly supported the creation of such agents who could quickly train for new levels. As already mentioned, the receipt and study of such solutions was the main task of OpenAI in the course of this competition.
In an academic environment, the direction of learning policies that can quickly adapt to new conditions is called meta learning, and has been actively developed in recent years.
Additionally, in contrast to the usual kaggle competitions, where the entire submission comes down to sending your response file, in this competition (and indeed in RL competitions) the team was required to wrap its solution in a docker container with the specified API, build it and send docker image. This increased the entry threshold for the competition, but made the decision process much more honest - resources and time for the docker image were limited, respectively, too heavy and / or slow algorithms simply did not pass the selection. It seems to me that such an approach to assessing is much more preferable, as it allows researchers without the “home cluster of DGX and AWS” to compete on a par with lovers of 100,500 models. I hope to see more of this kind of competition in the future.
Team
Kolesnikov Sergey ( scitator )
RL enthusiast. At the time of the competition, an FIFT student at the Moscow Institute of Physics and Technology, wrote and defended a diploma from last year’s NIPS: Learning to Run competition (an article about which we should write too).
Senior Data Scientist @ Dbrain - we bring production-ready contests with docker and limited resources to the real world.
Mikhail Pavlov ( fgvbrt )
Senior Research & Development Deephack Lab . Repeatedly participated and held prizes in hackathons and training contests with reinforcement.
Ilya Sergeev ( sergeevii123 )
RL enthusiast. Got on one of the hackathons on RL from Deephack and everything started to happen. Data Scientist @ Avito.ru - computer vision for various internal projects.
Sorokin Ivan ( 1ytic )
Engaged in speech recognition in speechpro.ru .
Approaches and solutions
After a quick test of the proposed baselines, our choice fell on the approach from OpenAI - PPO, as a more formed and interesting option for the development of our solution. In addition, judging by their article for this competition, the PPO agent did a little better job. From the same article, the first improvements were born that we used in our solution, but first things first:
PPO co-education at all available levels
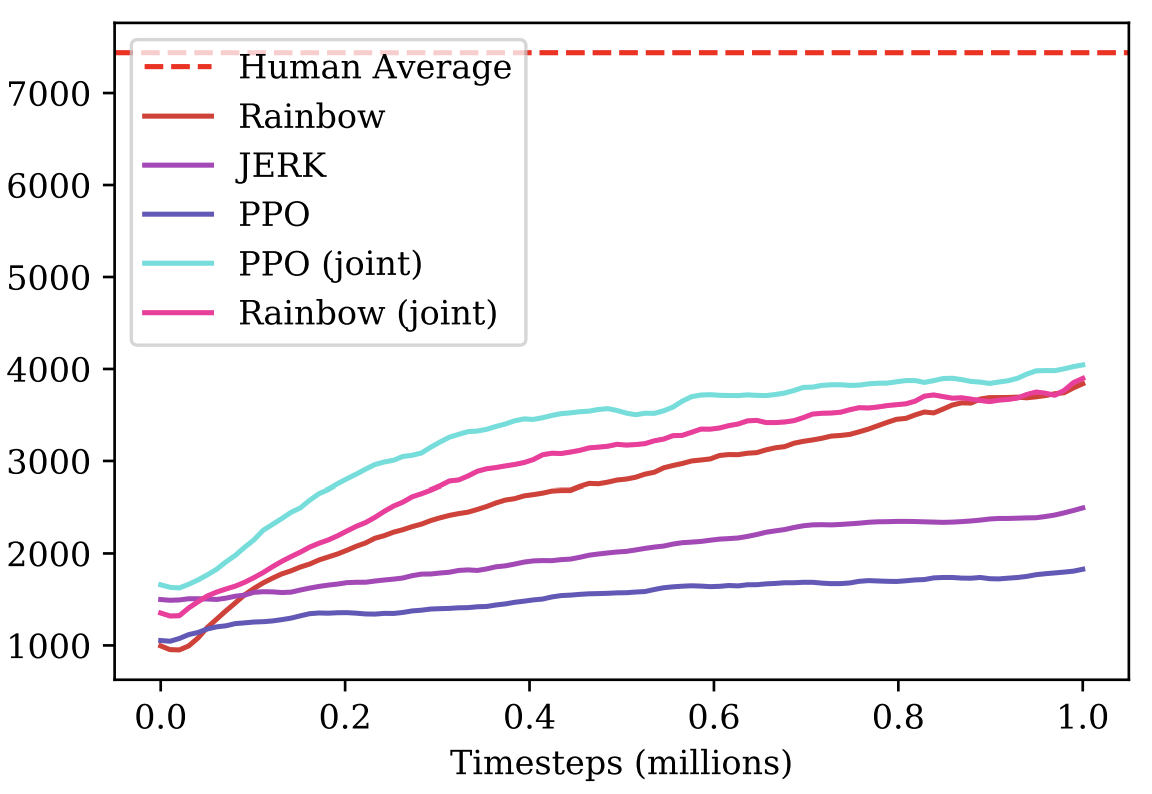
Laid out baseline was trained only on one of the available 27 levels of Sonic. However, with the help of small modifications, it was possible to parallelize training on all 27 levels at once. Due to the greater diversity in training, the resulting agent had much greater generalization and a better understanding of the structure of the Sonic world, and therefore coped much better.
Pre-training in the testing process
Returning to the basic idea of competition, meta learning, it was required to find an approach that would have maximum generalization and could easily adapt to new environments. And for adaptation, it was necessary to train the existing agent under the test environment, which, in fact, was done (at each test level, the agent took 1 million steps, which was enough to tune to a specific level). At the end of each test game, the agent evaluated the award received and optimized his policy using the history he had just received. Here it is important to note that with this approach it is important not to forget all of your previous experience and not to degrade under specific conditions, which, in essence, is the main interest of meta learning, since such an agent immediately loses all the existing ability to generalize.Exploration bonuses Going deeper
into the conditions of remuneration for the level - the agent was given a reward for moving forward along the x - coordinates, respectively, he could get stuck on some levels, when you first had to go forward and then back. It was decided to make for the agent an additive to the award, the so-called count based explorationwhen the agent was given a small reward if he was in a state in which he had not yet been. Two types of exploitation bonus were implemented: based on the image and based on the x-coordinates of the agent. The reward based on the picture was calculated as follows: for each pixel location in the picture, it was counted how many times each value occurred per episode, the reward was inversely proportional to the product across all pixel locations, and how many times the values met in these locations per episode. The award based on the x-coordinate was considered similarly: for each x-coordinate (with a certain accuracy), the number of times the agent was in this coordinate per episode, the reward is inversely proportional to this number for the current x-coordinate.Experiments with mixup
Recently, a simple, but effective, augmentation method of data, so-called, began to be used in “learning with the teacher”. mixup. The idea is very simple: the addition of two arbitrary input images is done and a weighted sum of corresponding labels is assigned to this new image (for example, 0.7 dog + 0.3cat). In such tasks as the classification of images and speech recognition, mixup shows good results. Therefore, it was interesting to test this method for RL. The augmentation was done in each large batche consisting of several episodes. The input images were mixed in pixels, but with tags, it was not so simple. The values returns, values and neglogpacs were mixed by a weighted sum, but the action (actions) was chosen from the example with the maximum coefficient. Such a decision did not show a tangible increase directly (although it would seem that there should have been an increase in generalization), but it did not worsen the baseline. The graphs below compare the PPO algorithm with mixup (red) and without mixup (blue): at the top is the reward during training, at the bottom is the length of the episode.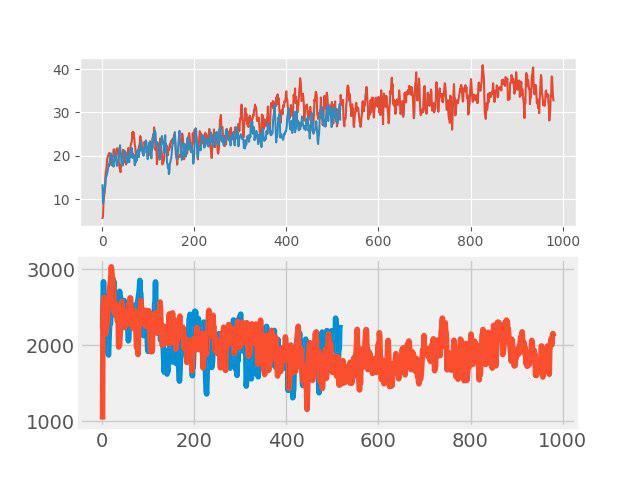
Selection of the best initial policy
This improvement was one of the last and made a very significant contribution to the final result. At the training level, several different policies with different hyperparameters were trained. At the test level, the first few episodes were tested for each of them and the policy that gave the maximum test reward for their episode was chosen for further study.
Bloopers
And now on the question of what was tried, but “did not fly”. In the end, this is not a new SOTA article to hide something.
- Changing network architecture: SELU activation , self-attention, SE blocks
- Neuroevolution
- Creating your own Sonic levels - everything was prepared, but there was not enough time
- Meta-learning through MAML and REPTILE
- Ensemble of several models and additional training in the process of testing each of the models using importance sampling
Results
After 3 weeks from the end of the competition OpenAI posted the results . On another 11 additionally created levels, our team received an honorable 4th place, jumping from the 8th on a public test, and overtaking the banned baselines from OpenAI.
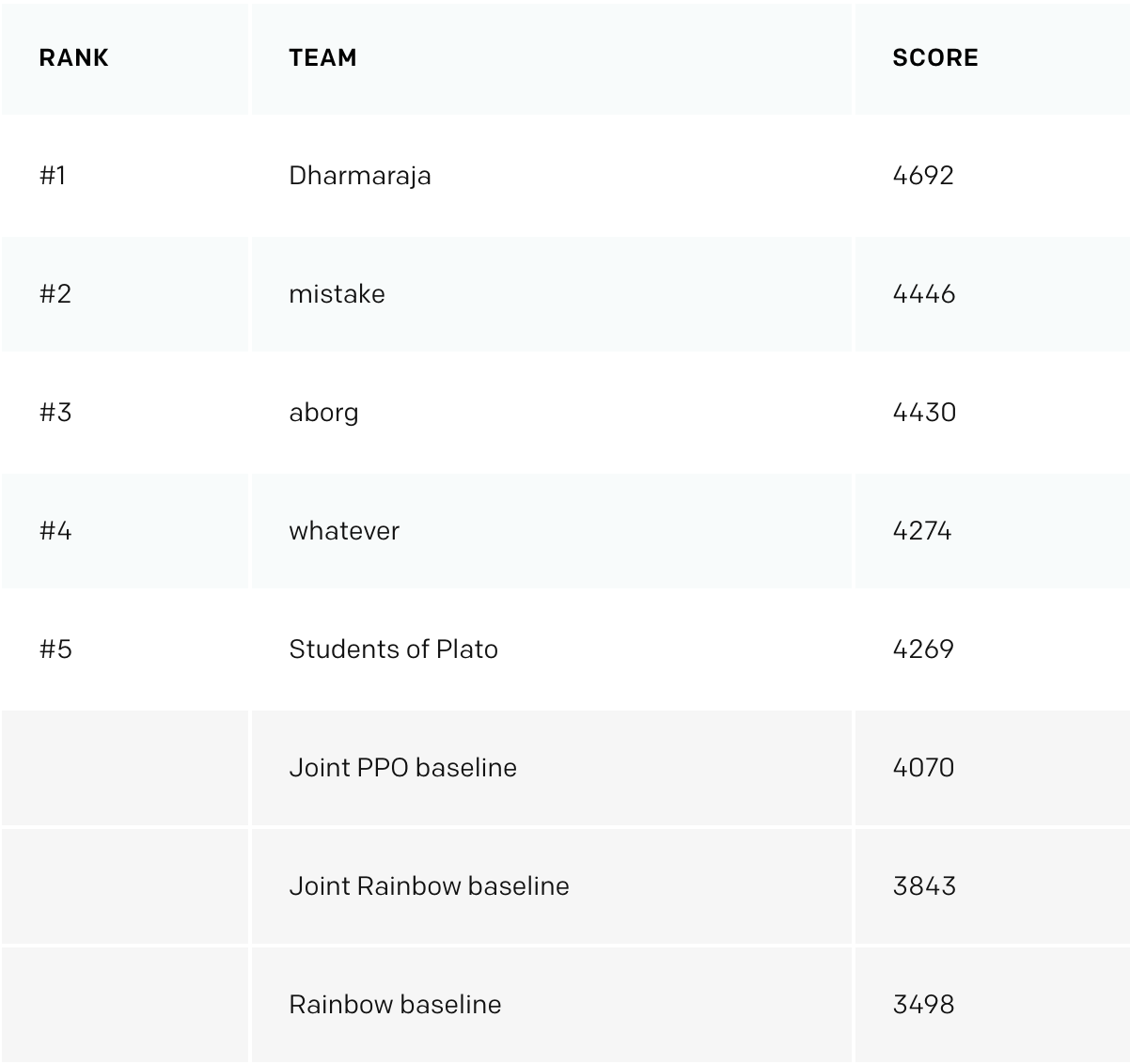
The main distinctive moments that “flew” in the first 3ki:
- Modified system of actions (they invented their buttons, removed unnecessary ones);
- Investigation of states through hash from the input image;
- More learning levels;
Additionally, we would like to note that in this competition, in addition to the victory, the promotion of a description of their decisions, as well as materials that helped other participants, was actively encouraged - for this there was also a separate nomination. Which, again, increased the bulbiness of the competition.
Afterword
Personally, I really enjoyed this competition, as well as the topic of meta learning. During the time of participation, I got acquainted with a large list of articles (I did not even forget some of them ) and learned a great number of different approaches that I hope to use in the future.
In the best tradition of participating in the competition, all code is available and uploaded to the githab .