How we migrated millions of countries in a working day
 Badoo — крупнейшая в мире социальная сеть для знакомств с новыми людьми, насчитывающая 190 миллионов пользователей.
Badoo — крупнейшая в мире социальная сеть для знакомств с новыми людьми, насчитывающая 190 миллионов пользователей. Все данные хранятся в двух дата-центрах — европейском и американском. Некоторое время назад мы исследовали качество интернет-соединения у наших пользователей из Азии и обнаружили, что для 7 миллионов пользователей наш сайт будет загружаться в 2 раза быстрее, если мы переместим их из европейского дата-центра в американский. Перед нами впервые встала задача крупномасштабной миграции данных пользователей между дата-центрами, с которой мы успешно справились: мы научились перемещать 1,5 миллиона пользователей за один рабочий день! Мы смогли перемещать целые страны! В первой части мы подробно расскажем о поставленной перед нами задаче и о том, какого результата мы достигли.
Архитектура Badoo
About architecture Badoo was much told at various conferences and on Habré, but nevertheless we will repeat the main points which are important for understanding our task. Badoo uses a standard technology stack to render web pages: Linux, nginx, PHP-FPM (developed by Badoo), memcached, MySQL.
Almost all user data is located on a couple of hundreds of MySQL servers and is distributed (“shared”) over them using a “self-written” service called authorizer. It stores a large correspondence table of the user id and the id of the server on which the user is located. We don’t use “remainders from dividing” and other similar methods for distributing users among servers, so we can easily transfer users between database servers: this was originally built into the Badoo architecture.

In addition to MySQL, we have many C / C ++ services that store various data: sessions, dates of the last visit to the site, user photos for voting, basic data of all users for searching.
We also have a service that serves the "Dating" section. It differs from others in that it exists in one copy for each country. It just consumes so much RAM that all its data cannot physically fit on one server, even if you put 384 GB there. Moreover, he “lives” only in “his” data center.
In addition, we have a number of “central” MySQL databases that store general information about all users, and separate billing databases that also store information for all Badoo users at once. In addition, we have separate repositories for uploaded photos and videos, which will be a separate article. This data must also be moved.
Formulation of the problem
The task is formulated very simply: to transfer user data from a whole country in one working day, and so that during the migration these users can use the site. The largest country that we “migrated” is Thailand, in which we have about 1.5 million registered users. If we divide this number into 8 working hours (plus lunch), we get the required migration rate, which is about 170 thousand users per hour.
The requirement to migrate the country in one working day is dictated by the fact that anything can happen at this time. For example, they can “lie down” or start to slow down some servers or services, and then it will be necessary to “live” edit the code in order to reduce the load created on them. There may also be errors in the migration code that will lead to problems for users, and then there should be the ability to quickly see this and pause (or even roll back) the process. In a word, when carrying out such a large-scale operation to transfer users, the presence of an “operator” is required, which will monitor what is happening and make the necessary adjustments during operation.
Technically, for each user, you need to make selections from all tables of all MySQL instances on which data about this user can be located, as well as transfer the data stored in C / C ++ services. Moreover, for one of the services you need to transfer the daemon itself, and not the data between the running daemon instances in both data centers.
The delay in transferring data between data centers is about 100 ms, so operations should be optimized so that the data is downloaded by the stream, and not by a large number of small requests. During migration, the site inaccessibility time for each user should be minimal, so the process should be carried out for each user individually, and not a large bundle. The time we focused on was no more than 5 minutes of site inaccessibility for a specific user (preferably 1-2 minutes).
Work plan
Based on the fact that we needed to migrate 170,000 users per hour, and the migration time of each user should be about 2-3 minutes, we calculated the number of threads executed in parallel that would be required to fulfill these conditions. Each thread can transfer an average of 25 users per hour, so the total number of threads is 6,800 (i.e. 170,000 / 25). In fact, we were able to limit ourselves to “only” 2,000 threads, because most of the time, the user simply “expects” the occurrence of various events (for example, MySQL replication between data centers). Thus, each thread took three users into processing at the same time and switched between them when one of them went into a waiting state for something.
Each user’s migration consisted of many successive steps. The execution of each step began strictly after the end of the previous one and provided that the last one was completed successfully.
Also, each step should be repeatable, or, "speaking Russian," idempotent. Those. the execution of each step can be interrupted at any time for various reasons, and he must be able to determine what operations he needs to complete, and perform these operations correctly.
This is required in order not to lose user information in the event of a crash of migration and during temporary failures of internal services or database servers.
The structure and sequence of our actions
Preparatory steps
We mark the user as “migrating” at the moment and wait for the end of his processing by background scripts, if any. This step took us about a minute, during which you can migrate another user in the same stream.
Migration of billing data
During the migration of the country, we completely turned off billing in it, so no special actions and locks were required for this - the data was simply transferred from one central MySQL database to another. A MySQL connection was established from each thread to this database, so the total number of connections to the billing database was more than 2,000.
Photo migration
Here we “counted” a little, because we found a way to transfer photos in advance and separately relatively easily. Therefore, for most users, this step simply checked that they did not have new photos since the transfer.
Filling the user's main data
In this step, we generated an SQL dump of the data of each user and applied it on the remote side. At the same time, the old data was not deleted in this step.
Updating data in the authorizer service The authorizer
service stores the correspondence between the user id and server id, and until we update the data in this service, scripts will go to the old data for the user data.
Removing user data from an old location
Using DELETE FROM queries, we clear the user data on the source MySQL server.
Steps for transferring data from central databases
One of the central databases under the eloquent name Misc (miscellaneous - miscellaneous) contains a lot of different tables, and for each of them we did one SELECT and DELETE per user. We squeezed 40,000 SQL queries per second from the poor database and kept more than 2,000 connections open to it.
Steps to transfer data from services
As a rule, all the data is contained in the database, and the services only allow you to quickly access them. Therefore, for most services, we simply deleted data from one place and re-filled it with information from the database, which was already in a new place. However, we simply transferred one service as a whole, and not according to users, because the data in it was stored in a single copy.
Pending replication
Our databases are replicated between data centers, and until the replication is "reached", the user data is in an inconsistent state in different data centers. Therefore, we had to wait for the end of replication for each user, so that everything worked correctly and the data was consistent with each other. And in order not to lose time at this step (from 20 seconds to a minute), it was used to migrate other users at this moment.
Final steps
We mark the user as having completed the migration and allow him to log in on the site, already in the new data center.
MySQL Data Transfer

As mentioned earlier, we store user data on MySQL servers, which are about one and a half hundred for each data center. Each server has several databases, each of which has thousands of tables (on average, we try to have one table per 1000 users). The data is designed in such a way that either do not use auto-increment fields at all, or at least not refer to them in other tables. Instead, the combination of user_id and sequence_id is used as the primary key, where user_id is the user identifier, and sequence_id is the counter that automatically increments and is unique within the same server. Thus,
Data movement was done according to the same scheme for most MySQL servers (note that in case of any errors the entire step crashes and starts again after a short time interval):
- We go to the "receiver side" and check if there is already user data there. If there is, then the data upload was successful, but the step was not completed correctly.
- If there is no data on the remote side, make SELECT from all the necessary tables with filtering by user and create an SQL dump containing BEGIN at the beginning and COMMIT at the end.
- Fill the dump via SSH to the “proxy” on the remote side and use it using the mysql console utility. It may happen that a COMMIT request passes, but we won’t be able to get an answer, for example, due to network problems. To do this, we first check if the dump was flooded in a previous attempt. Moreover, in some databases, the lack of data for the user is a normal situation, and in order to be able to check whether the data transfer was performed, in such cases we added INSERT to a special table, according to which we checked if necessary.
- We delete the original data using DELETE FROM with the same WHERE as in the SELECT queries. As a rule, WHERE conditions contained user_id, and for some tables this field was not part of the primary key for various reasons. Where possible, an index was added. Where this turned out to be difficult or impractical, when deleting data, the user_id was first selected, and then the primary key was deleted, which avoided reading locks and significantly accelerated the process.
If we know for sure that we have never started the corresponding step before, then we skip checking the availability of data on the remote side. This allows us to win about a second for each server to which we transfer data (which is due to a delay of 100 ms for each packet sent).
During the migration, we encountered a number of problems that we want to talk about.
Auto-increment fields (auto_increment)
Auto-increment fields are actively used in the billing database, so for them I had to write complex logic of “mapping” old id to new ones.
The difficulty was that the data from tables where only the sequence_id described above can be entered in the primary key cannot be simply transferred, since sequence_id is unique only within the server. Replacing sequence_id with NULL, thereby causing the generation of a new auto-increment value, is also impossible, because, firstly, the generation of sequence_id is done by inserting data into one table, and the resulting value is used in another. And secondly, other tables refer to a table using sequence_id. That is, you need to get the right amount of auto-increment field values on the server where the data is transferred, replace the old sequence_id with new ones in the user data, and write the finished INSERTs to a file that will later be used by the mysql console utility.
To do this, we opened a transaction on the receiving server, made the required number of inserts, called mysql_insert_id (), which, if several rows were inserted in one transaction, returns the auto-increment value for the first row, and then rolled back the transaction. In this case, after the transaction is rolled back, the auto-increment will remain increased by the number of rows inserted by us, unless the database server reboots. Having received the auto-increment values we need, we formed the appropriate insertion requests, including in the table responsible for generating the auto-increment. But these requests already explicitly indicated auto-increment values in order to fill the holes formed in it after the transaction was rolled back.
Max_connections and MySQL load
Each thread created one MySQL connection to the server with which it had to deal. Therefore, we kept 2,000 connections on all central MySQL servers. With more connections, MySQL began to behave inappropriately, until the fall (we use versions 5.1 and 5.5).
Once during a migration, one of the central MySQL servers crashed (one of those that had a very heavy load). The migration was immediately aborted, and we began to find out the cause of the fall. It turned out that the RAID controller just “flew out” on it. And although the administrators said that this was not due to the load that we gave to this server, but the "sediment remained."
InnoDB, MVCC, and DELETE FROM: Pitfalls
Since we store all the data in InnoDB and all transferred data was deleted immediately, we started to slow down all the scripts that rake the queues located in tables on some servers. We were surprised to see how SELECT from an empty table took minutes. MySQL purge thread did not have time to clear deleted records, and despite the fact that the tables with queues were empty, there were a lot of deleted records that were not physically deleted yet and were simply skipped by MySQL when fetching. A quantitative description of the length of the queue for cleaning records can be obtained by typing SHOW ENGINE INNODB STATUS and looking at the line History list length. The greatest value that we have observed is several million records. We recommend that you very carefully remove many records from InnoDB tables using DELETE FROM. It is much better to avoid this and use, for example, TRUNCATE TABLE, if possible. Queries of the form TRUNCATE TABLE completely clear the table, and these operations are DDL, so deleted records do not add up to undo / redo log (InnoDB does not support transactions for DDL operations).
If after deleting all the data using DELETE FROM you need to make a selection from the table, then try to impose the BETWEEN condition on the primary key. For example, if you use auto_increment, select MIN (id) and MAX (id) from the table, and then select all the records between them - this is much faster than choosing records with some kind of limit or with only one of the conditions of the form id> N or id <N . Requests that receive MIN (id) and MAX (id) will take a very long time because InnoDB will skip deleted records. But on the other hand, queries on key ranges will be executed at the same speed as usual - deleted records will not fall into the selection during such queries.
We were also surprised to see many “hanging” queries of the form DELETE FROM WHERE user_id =, where all queries have the same query, and there is no user_id index in this table. As it turned out, MySQL version 5.1 (and to a lesser extent 5.5) has very poor scalability of such queries if FULL SCAN tables are made when deleting records and the isolation level is REPEATABLE READ (by default). There is a very high competition of locks for the same records, which leads to an avalanche-like increase in query processing time.
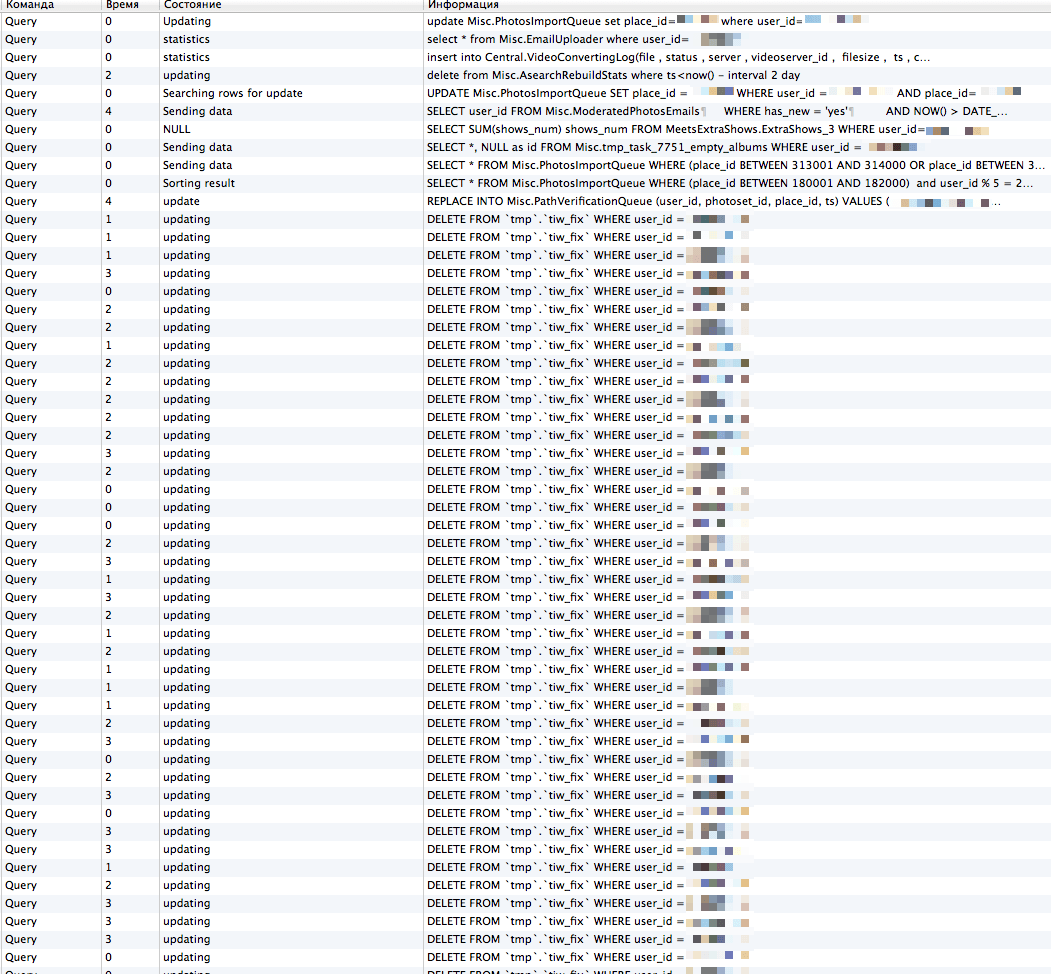
One possible solution to the problem is to set the isolation level READ COMMITED for a transaction that deletes data, and then InnoDB will not put locks on those rows that do not fit under the WHERE clause. To illustrate how this was a serious problem, here is a screenshot taken during the migration. The tmp.tiw_fix table in the screenshot contains only about 60 entries (!) And does not contain an index on user_id.
User stream allocation
Initially, we distributed users by flows evenly, regardless of which server a particular user is on. Also, in each thread, we leave open connections to all MySQL servers that we had to meet to migrate users allocated to the corresponding thread. As a result, we got two more problems:
- When a MySQL server started to slow down, the migration of users living on this server slowed down. As all other threads continued to execute, they gradually also reached the user living on the problem server. Gradually, an increasing number of threads accumulated on this server, and it began to slow down even more. To prevent the server from crashing, we introduced temporary patches to the code directly during operation, using various “crutches” to limit the load on this server.
- Since we kept open MySQL connections in each of the flows to all the necessary MySQL servers, we gradually came to the conclusion that each thread had a large number of open connections to all MySQL servers, and we started to rest on max_connections.
In the end, we changed the algorithm for distributing users by flows and allocated to each thread users who live on only one MySQL server. Thus, we immediately solved the problem of an avalanche-like load increase in the case of “brakes” of this server, as well as the problem with too many simultaneous connections on some weak hosts.
To be continued…
In the following parts we will talk about how we pre-migrated user photos and what data structures we used to limit the load on the server with photos. After that, we will describe in more detail how we managed to coordinate the work of 2,000 simultaneously executing migration flows on 16 servers in two data centers and what technical solutions were used to make it all work.
Yuri youROCK Nasretdinov, PHP developer
Anton antonstepanenko Stepanenko, Team Lead, PHP developer