"Boost.Asio C ++ Network Programming." Chapter 5: Synchronous vs Asynchronous
- Transfer
- Tutorial
Hello!
I continue to translate John Torjo's book Boost.Asio C ++ Network Programming.
Content:
The authors of Boost.Asio did a wonderful job, giving us the opportunity to choose what suits our applications best by choosing a synchronous or asynchronous path.
In the previous chapter, we saw frameworks for all types of applications, such as a synchronous client, a synchronous server, as well as their asynchronous options. You can use each of them as a basis for your application. If it becomes necessary to delve into the details of each type of application, then read on.
The Boost.Asio library allows you to mix synchronous and asynchronous programming. Personally, I think this is a bad idea, but Boost.Asio, like C ++ in general, allows you to shoot yourself in the foot if you want to.
You can easily fall into the trap, especially if your application runs asynchronously. For example, in response to an asynchronous write operation you, say, do an asynchronous read operation:
Surely a synchronous read operation will block the current thread, so any other incomplete asynchronous operations will be in standby mode (for this thread). This is bad code and can cause the application to slow down or even become blocked (the whole point of using the asynchronous approach is to avoid blocking, therefore, using synchronous operations, you deny this). If you have a synchronous application, then it is unlikely that you will use asynchronous read or write operations, since thinking synchronously already means thinking in a linear way (do A, then B, then C, and so on).
The only case, in my opinion, when synchronous and asynchronous operations can work together is when they are completely separated from each other, for example, a synchronous network and asynchronous operations of input and output from the database.
A very important part of a good client / server application is the delivery of messages back and forth (from server to client and from client to server). You must specify what identifies the message. In other words, when an incoming message is being read, how can we know that the message has been completely read?
You need to determine the end of the message (the beginning is easy to determine, this is the first byte received after the end of the last message), but you will see that it is not so easy.
You can:
Throughout the book, I decided to use the "\ n 'character as the end of each message." So, reading messages will demonstrate the following code fragment:
Leaving the indication of length as the message prefix as an exercise for the reader is quite easy.
The synchronous client, as a rule, is of two types:
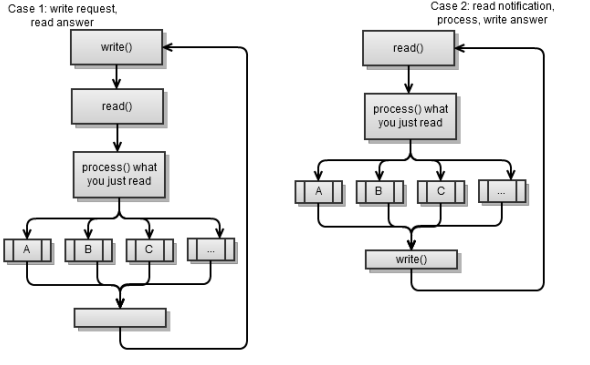
Both scenarios use the following strategy: make a request - read the response. In other words, one party makes a request to which the other party responds. This is an easy way to implement a client / server application and this is what I recommend you.
You can always create a Mambo Jambo client / server, where each side writes whenever you want, but it is very likely that this path will lead to disaster (how do you know what happened when the client or server is blocked?).
Previous scripts may look the same, but they are very different:
Basically, you will come across pull-like client / server applications that make development easier, as well as usually the norm.
You can mix these two approaches: get on demand (client-server) and push the request (server-client), however, it is difficult and it is better to avoid it. There is a problem of mixing these two approaches; if you use the strategy to make a request, read the answer; the following may happen:
In a pull-like client / server application, the previous scenario could be easily avoided. You can simulate push-like behavior by implementing the ping process when the client checks the connection with the server, say, every 5 seconds. The server may respond with something like ping_ok if there is nothing to report, or ping_ [event_name] if there is an event for notification. Then the client can initiate a new request to handle this event.
Again, the previous script illustrates the synchronous client from the previous chapter. Its main loop:
Let me change it to fit the last scenario:
Servers, like clients, are of two types; they correspond to two scenarios from the previous section. Again, both scenarios use a strategy: create a request - read the response.
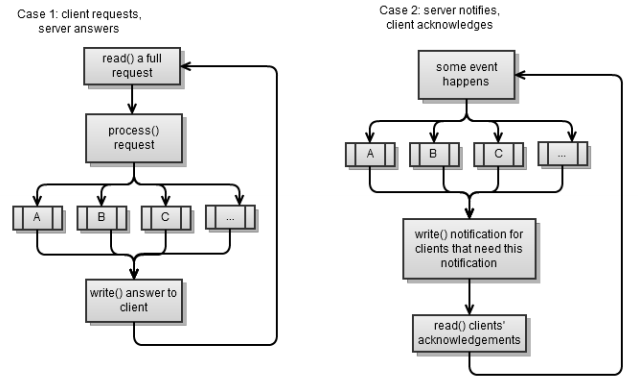
The first scenario is a synchronous server, which we implemented in the previous chapter . Reading the request completely is not easy if you are working synchronously, since you want to avoid blocking (you always read as much as you can).
After the message has been completely read, we simply process it and respond to the client:
If we wanted our server to become a push-like server, then we would change it as follows:
Function
This is a very important factor: how many threads will we allocate for customer processing?
For a synchronous server, we need at least one thread that will handle new connections:
For existing customers:
The third option is very difficult to implement in a synchronous server. The whole class has
The following code, which is similar to the original function
We will modify it as shown below:
While we will process the client, its instance
The main workflow is somewhat reminiscent of the same process in a synchronous client application, with the difference that Boost.Asio is between each request
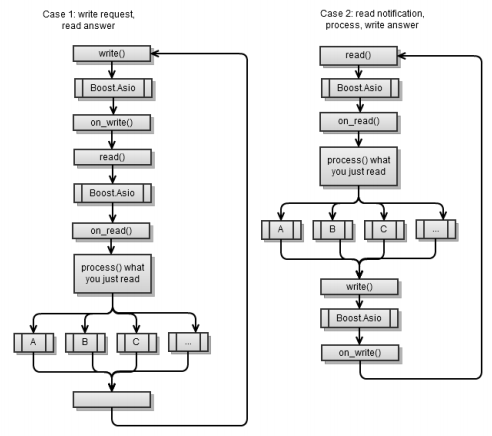
The first scenario is the same as the asynchronous client in chapter 4 was implemented . Remember that at the end of each asynchronous operation, you must start another asynchronous operation so that the function
To bring the first scenario to the second, we need to use the following code fragment:
Please note that as soon as you connect successfully, you start reading from the server. Each function
The beauty of the asynchronous approach is that you can mix network I / O with any other asynchronous operations using Boost.Asio to organize all this. Even though the stream is not as clear as a synchronous stream, you can practically think of it as a synchronous one.
Say you read a file from a web server and save it to a database (asynchronously). You can practically think about it, as shown in the following flowchart:

Again the ubiquitous two cases, the first script (pull) and the second script (push):

The first script of the asynchronous server was implemented in the previous chapter . At the end of each asynchronous operation, it is necessary to start another asynchronous operation so that it
Here is the code framework that has been trimmed. Below are all members of the class
In a nutshell, we always wait for a read operation, as soon as it is completed, we process the message and respond back to the client.
Convert the previous code to the push server:
When an event occurs, say,
The asynchronous server was shown in Chapter 4; it is single-threaded, since everything happens in the function there
The beauty of the asynchronous approach is the ease of transition from a single-threaded to a multi-threaded version. You can always go one-way, at least until your customers are more than 200 at the same time or so. Then, in order to switch from one thread to 100 threads, you will need to use the following code fragment:
Of course, once you start using multi-threading, you should think about thread-safe. Even if you call
This, however, means that there can only be one asynchronous operation pending for a client. If at some point the client has two pending asynchronous functions, then you will need mutexes. Because two pending operations can complete at about the same time, and ultimately we could call their handlers in two different threads simultaneously. Thus, there is a need for thread-safe, thus mutexes.
In our asynchronous server, there are actually two pending operations at the same time:
When performing a read operation, we will asynchronously wait for its completion for a certain period. Thus, there is a need for thread-safe. My advice is, if you plan on choosing a multi-threaded option, then make your class thread-safe from the start. This usually does not hurt performance (you can of course check this out). In addition, if you plan to go a multi-stream path, then follow it from the very beginning. Thus, you will encounter potential problems at an early stage. As soon as you find a problem, the first thing you should check is this happening with one running thread? If yes, then this is easy, just debug. Otherwise, you probably forgot to mutex some function.
Since our example needs thread-safe, we changed
Avoiding deadlock and memory corruption is not so simple. Here's how to change the function
What we want to avoid is that the two mutexes are locked at the same time (which can lead to a deadlock situation). In our case, we do not want the
Boost.Asio also allows you to perform any of your functions asynchronously. Just use the following code snippet:
You can verify that it
There is no function
Please note that while the operation is not completed, we are constructing the instance
The function
To verify this, we will create a function
Notice how I just showed you a possible implementation of a function call asynchronously. Instead of implementing a background thread, as I did, you can use an internal instance
You can also expand the class to show the progress of asynchronous work (for example, in percent). In this case, you could show the progress in the progress bar, in the main stream.
A proxy is usually located between the client and server. It receives a request from the client, can change it, and sends it to the server. Then he takes the response from the server, can change it, and sends it to the client.
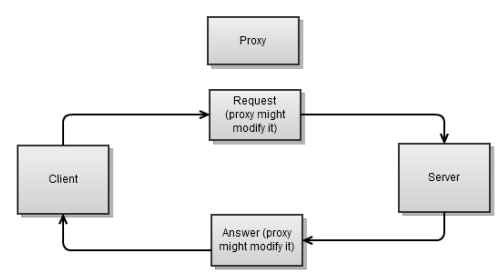
What is the special feature of the proxy server? For our purposes, we will have two sockets for each connection, one for the client, the other for the server. This complicates the implementation of the proxy quite a bit.
Implementing a proxy for a synchronous application will be more complicated than for an asynchronous one; data can come from both ends (from the client and server), at the same time, data can be sent to both of them (client and server). This means that if we choose the synchronous option, we can end up blocking reading or writing on the one hand, while we need to read or write on the other hand, which means that we will stop responding at one end.
Consider the following points in a simple example of an asynchronous proxy:
This is a very simple proxy. When connected at both ends, it starts reading on both connections (function
After each successful read (on_read), it passes the message to the other side. Once the message has been successfully transmitted (on_write), we begin to read again.
For this to work, use the following code snippet:
You have noticed that I am reusing buffers (
Leave this as an exercise for you.
There are many more things to consider when deciding which direction to go: synchronous or asynchronous.
In this chapter we examined:
Next, we are going to consider several not so well-known features of Boost.Asio, as well as my favorite feature of Boost.Asio -
Resources for this article: link
Thank you all for your attention, see you soon!
I continue to translate John Torjo's book Boost.Asio C ++ Network Programming.
Content:
- Chapter 1: Getting Started with Boost.Asio
- Chapter 2: Boost.Asio Basics
- Chapter 3: Echo Server / Client
- Chapter 4: Client and Server
- Chapter 5: Synchronous vs Asynchronous
- Chapter 6: Boost.Asio - Other Features
- Chapter 7: Boost.Asio - additional topics
The authors of Boost.Asio did a wonderful job, giving us the opportunity to choose what suits our applications best by choosing a synchronous or asynchronous path.
In the previous chapter, we saw frameworks for all types of applications, such as a synchronous client, a synchronous server, as well as their asynchronous options. You can use each of them as a basis for your application. If it becomes necessary to delve into the details of each type of application, then read on.
Mix synchronous and asynchronous programming
The Boost.Asio library allows you to mix synchronous and asynchronous programming. Personally, I think this is a bad idea, but Boost.Asio, like C ++ in general, allows you to shoot yourself in the foot if you want to.
You can easily fall into the trap, especially if your application runs asynchronously. For example, in response to an asynchronous write operation you, say, do an asynchronous read operation:
io_service service;
ip::tcp::socket sock(service);
ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 8001);
void on_write(boost::system::error_code err, size_t bytes)
{
char read_buff[512];
read(sock, buffer(read_buff));
}
async_write(sock, buffer("echo"), on_write);
Surely a synchronous read operation will block the current thread, so any other incomplete asynchronous operations will be in standby mode (for this thread). This is bad code and can cause the application to slow down or even become blocked (the whole point of using the asynchronous approach is to avoid blocking, therefore, using synchronous operations, you deny this). If you have a synchronous application, then it is unlikely that you will use asynchronous read or write operations, since thinking synchronously already means thinking in a linear way (do A, then B, then C, and so on).
The only case, in my opinion, when synchronous and asynchronous operations can work together is when they are completely separated from each other, for example, a synchronous network and asynchronous operations of input and output from the database.
Delivery of messages from client to server and vice versa
A very important part of a good client / server application is the delivery of messages back and forth (from server to client and from client to server). You must specify what identifies the message. In other words, when an incoming message is being read, how can we know that the message has been completely read?
You need to determine the end of the message (the beginning is easy to determine, this is the first byte received after the end of the last message), but you will see that it is not so easy.
You can:
- Making a message of a fixed size (this is not a good idea; what to do when you need to send more data?)
- Make a specific character ending the message, such as '\ n' or '\ 0'
- Specify the length of the message as the message prefix, and so on.
Throughout the book, I decided to use the "\ n 'character as the end of each message." So, reading messages will demonstrate the following code fragment:
char buff_[512];
// synchronous read
read(sock_, buffer(buff_), boost::bind(&read_complete, this, _1, _2));
// asynchronous read
async_read(sock_ buffer(buff_),MEM_FN2(read_complete,_1,_2),
MEM_FN2(on_read,_1,_2));
size_t read_complete(const boost::system::error_code & err, size_t bytes)
{
if ( err)
return 0;
already_read_ = bytes;
bool found = std::find(buff_, buff_ + bytes, '\n') < buff_ + bytes;
// we read one-by-one until we get to enter, no buffering
return found ? 0 : 1;
}
Leaving the indication of length as the message prefix as an exercise for the reader is quite easy.
Synchronous I / O in client applications
The synchronous client, as a rule, is of two types:
- It requests something from the server, reads and processes the response. Then it asks for something else and so on. This is essentially a synchronous client, which was discussed in the previous chapter.
- Reads an incoming message from the server, processes it and writes a response. Then it reads the next incoming message and so on.
Both scenarios use the following strategy: make a request - read the response. In other words, one party makes a request to which the other party responds. This is an easy way to implement a client / server application and this is what I recommend you.
You can always create a Mambo Jambo client / server, where each side writes whenever you want, but it is very likely that this path will lead to disaster (how do you know what happened when the client or server is blocked?).
Previous scripts may look the same, but they are very different:
- In the first case, the server responds to requests (the server waits for requests from clients and responds to them). This is a pull-like connection when the client receives what it needs on request from the server.
- In the latter case, the server sends the client events to which it responds. This is a push-like connection when the server pushes notifications / events to clients.
Basically, you will come across pull-like client / server applications that make development easier, as well as usually the norm.
You can mix these two approaches: get on demand (client-server) and push the request (server-client), however, it is difficult and it is better to avoid it. There is a problem of mixing these two approaches; if you use the strategy to make a request, read the answer; the following may happen:
- The client writes (makes a request)
- The server writes (sends a notification to the client)
- The client reads what the server wrote and interprets this as a response to its request
- The server blocks waiting for a response from the client that will arrive when the client makes a new request
- The client writes (makes a new request)
- The server will interpret this request as the response it was waiting for
- The client is blocked (the server does not send a return response because it interpreted the client’s request as a response to its notification).
In a pull-like client / server application, the previous scenario could be easily avoided. You can simulate push-like behavior by implementing the ping process when the client checks the connection with the server, say, every 5 seconds. The server may respond with something like ping_ok if there is nothing to report, or ping_ [event_name] if there is an event for notification. Then the client can initiate a new request to handle this event.
Again, the previous script illustrates the synchronous client from the previous chapter. Its main loop:
void loop()
{
// read answer to our login
write("login " + username_ + "\n");
read_answer();
while ( started_)
{
write_request();
read_answer();
...
}
}
Let me change it to fit the last scenario:
void loop()
{
while ( started_)
{
read_notification();
write_answer();
}
}
void read_notification()
{
already_read_ = 0;
read(sock_, buffer(buff_), boost::bind(&talk_to_svr::read_complete, this, _1, _2));
process_notification();
}
void process_notification()
{
// ... see what the notification is, and prepare answer
}
Synchronous I / O in server applications
Servers, like clients, are of two types; they correspond to two scenarios from the previous section. Again, both scenarios use a strategy: create a request - read the response.
The first scenario is a synchronous server, which we implemented in the previous chapter . Reading the request completely is not easy if you are working synchronously, since you want to avoid blocking (you always read as much as you can).
void read_request()
{
if ( sock_.available())
already_read_ += sock_.read_some(buffer(buff_ + already_read_,
max_msg –already_read_));
}
After the message has been completely read, we simply process it and respond to the client:
void process_request()
{
bool found_enter = std::find(buff_, buff_ + already_read_, '\n') < buff_ + already_read_;
if ( !found_enter)
return; // message is not full
size_t pos = std::find(buff_, buff_ + already_read_, '\n') - buff_;
std::string msg(buff_, pos);
...
if ( msg.find("login ") == 0)
on_login(msg);
else if ( msg.find("ping") == 0)
on_ping();
else
...
}
If we wanted our server to become a push-like server, then we would change it as follows:
typedef std::vector array;
array clients;
array notify;
std::string notify_msg;
void on_new_client()
{
// on a new client, we notify all clients of this event
notify = clients;
std::ostringstream msg;
msg << "client count " << clients.size();
notify_msg = msg.str();
notify_clients();
}
void notify_clients()
{
for ( array::const_iterator b = notify.begin(), e = notify.end(); b != e; ++b)
{
(*b)->sock_.write_some(notify_msg);
}
}
Function
on_new_client()- the function of one event, where we must notify all customers about it. notify_clientsThis is a function that will notify customers who are subscribed to this event. The server sends a message, but does not wait for a response from each client, as this can lead to blocking. When a response comes from the client, the client can tell us that this is the answer to our notification (and we can process it correctly).Threads in a synchronous server
This is a very important factor: how many threads will we allocate for customer processing?
For a synchronous server, we need at least one thread that will handle new connections:
void accept_thread()
{
ip::tcp::acceptor acceptor(service, ip::tcp::endpoint(ip::tcp::v4(),8001));
while ( true)
{
client_ptr new_( new talk_to_client);
acceptor.accept(new_->sock());
boost::recursive_mutex::scoped_lock lk(cs);
clients.push_back(new_);
}
}
For existing customers:
- We can go one-way way. This is the easiest way, and we chose it when we implemented the synchronous server in Chapter 4 . It easily copes with 100-200 simultaneous connections, and sometimes it can be more, which is enough for the vast majority of cases.
- We can make a flow for each client. This is rarely a good option, it will spend a lot of threads, making debugging sometimes difficult, and although it is likely that more than 200 concurrent users will be processed, it will soon reach its limit.
- We can make a fixed number of threads to handle existing customers.
The third option is very difficult to implement in a synchronous server. The whole class has
talk_to_client become thread safe. Then you will need a special mechanism to know which threads process which clients. You have two options for this:- Assign a specific client to a specific thread; for example, the first thread processes the first 20 clients, the second thread processes clients from 21 to 40, and so on. When a customer is in use, we extract it from many existing customers. After we have worked with this client, we put him back on the list. Each thread will cycle through all existing clients, and take the first client to process with a full request (we completely read the incoming message from the client) and respond to it.
- The server may stop responding:
- In the first case, several clients processed in one thread simultaneously create requests, and one thread can only process one request at a time. However, we cannot do anything in this case.
- In the second case, we simultaneously receive more requests than we have threads. In this case, we can simply create new threads to handle the load.
The following code, which is similar to the original function
answer_to_client, shows how the last script can be implemented:struct talk_to_client : boost::enable_shared_from_this
{
...
void answer_to_client()
{
try
{
read_request();
process_request();
}
catch ( boost::system::system_error&)
{
stop();
}
}
};
We will modify it as shown below:
struct talk_to_client : boost::enable_shared_from_this
{
boost::recursive_mutex cs;
boost::recursive_mutex cs_ask;
bool in_process;
void answer_to_client()
{
{
boost::recursive_mutex::scoped_lock lk(cs_ask);
if ( in_process)
return;
in_process = true;
}
{
boost::recursive_mutex::scoped_lock lk(cs);
try
{
read_request();
process_request();
}
catch ( boost::system::system_error&)
{
stop();
}
}
{
boost::recursive_mutex::scoped_lock lk(cs_ask);
in_process = false;
}
}
};
While we will process the client, its instance
in_process will be installed in true, and other threads will ignore this client. An added bonus is that the function handle_clients_thread()cannot be modified; you can just create as many functions handle_clients_thread()as you want.Asynchronous I / O in client applications
The main workflow is somewhat reminiscent of the same process in a synchronous client application, with the difference that Boost.Asio is between each request
async_read and async_write. The first scenario is the same as the asynchronous client in chapter 4 was implemented . Remember that at the end of each asynchronous operation, you must start another asynchronous operation so that the function
service.run()does not end its activity. To bring the first scenario to the second, we need to use the following code fragment:
void on_connect()
{
do_read();
}
void do_read()
{
async_read(sock_, buffer(read_buffer_), MEM_FN2(read_complete,_1,_2),
MEM_FN2(on_read,_1,_2));
}
void on_read(const error_code & err, size_t bytes)
{
if ( err)
stop();
if ( !started() )
return;
std::string msg(read_buffer_, bytes);
if ( msg.find("clients") == 0)
on_clients(msg);
else
...
}
void on_clients(const std::string & msg)
{
std::string clients = msg.substr(8);
std::cout << username_ << ", new client list:" << clients ;
do_write("clients ok\n");
}
Please note that as soon as you connect successfully, you start reading from the server. Each function
on_[event]finishes it and writes a response to the server. The beauty of the asynchronous approach is that you can mix network I / O with any other asynchronous operations using Boost.Asio to organize all this. Even though the stream is not as clear as a synchronous stream, you can practically think of it as a synchronous one.
Say you read a file from a web server and save it to a database (asynchronously). You can practically think about it, as shown in the following flowchart:
Asynchronous I / O in server applications
Again the ubiquitous two cases, the first script (pull) and the second script (push):
The first script of the asynchronous server was implemented in the previous chapter . At the end of each asynchronous operation, it is necessary to start another asynchronous operation so that it
service.run()does not cease to exist. Here is the code framework that has been trimmed. Below are all members of the class
talk_to_client:void start()
{
...
do_read(); // first, we wait for client to login
}
void on_read(const error_code & err, size_t bytes)
{
std::string msg(read_buffer_, bytes);
if ( msg.find("login ") == 0)
on_login(msg);
else if ( msg.find("ping") == 0)
on_ping();
else
...
}
void on_login(const std::string & msg)
{
std::istringstream in(msg);
in >> username_ >> username_;
do_write("login ok\n");
}
void do_write(const std::string & msg)
{
std::copy(msg.begin(), msg.end(), write_buffer_);
sock_.async_write_some( buffer(write_buffer_, msg.size()),
MEM_FN2(on_write,_1,_2));
}
void on_write(const error_code & err, size_t bytes)
{
do_read();
}
In a nutshell, we always wait for a read operation, as soon as it is completed, we process the message and respond back to the client.
Convert the previous code to the push server:
void start()
{
...
on_new_client_event();
}
void on_new_client_event()
{
std::ostringstream msg;
msg << "client count " << clients.size();
for ( array::const_iterator b = clients.begin(), e = clients.end();b != e; ++b)
(*b)->do_write(msg.str());
}
void on_read(const error_code & err, size_t bytes)
{
std::string msg(read_buffer_, bytes);
// basically here, we only acknowledge
// that our clients received our notifications
}
void do_write(const std::string & msg)
{
std::copy(msg.begin(), msg.end(), write_buffer_);
sock_.async_write_some( buffer(write_buffer_, msg.size()),
MEM_FN2(on_write,_1,_2));
}
void on_write(const error_code & err, size_t bytes)
{
do_read();
}
When an event occurs, say,
on_new_client_eventall clients who need to be informed about this event will be sent messages. When they answer, we will understand that they processed the received event. Please note that we will never finish waiting for events asynchronously (therefore, service.run()it will not finish working), since we are always waiting for new customers.Threads in an Asynchronous Server
The asynchronous server was shown in Chapter 4; it is single-threaded, since everything happens in the function there
main():int main()
{
talk_to_client::ptr client = talk_to_client::new_();
acc.async_accept(client->sock(), boost::bind(handle_accept,client,_1));
service.run();
}
The beauty of the asynchronous approach is the ease of transition from a single-threaded to a multi-threaded version. You can always go one-way, at least until your customers are more than 200 at the same time or so. Then, in order to switch from one thread to 100 threads, you will need to use the following code fragment:
boost::thread_group threads;
void listen_thread()
{
service.run();
}
void start_listen(int thread_count)
{
for ( int i = 0; i < thread_count; ++i)
threads.create_thread( listen_thread);
}
int main(int argc, char* argv[])
{
talk_to_client::ptr client = talk_to_client::new_();
acc.async_accept(client->sock(), boost::bind(handle_accept,client,_1));
start_listen(100);
threads.join_all();
}
Of course, once you start using multi-threading, you should think about thread-safe. Even if you call
async_*in thread A, the procedure for completing it can be called in thread B (as long as thread B calls service.run()). This in itself is not a problem. As long as you follow the logical sequence, that is, from async_read()k on_read(), from on_read()to process_request, from process_requestk async_write(), from async_write()k on_write(), from on_write()k async_read()and there are no public functions that would call your class talk_to_client, although different functions can be called in different threads, they will still be called sequentially. Thus, mutexes are not needed.This, however, means that there can only be one asynchronous operation pending for a client. If at some point the client has two pending asynchronous functions, then you will need mutexes. Because two pending operations can complete at about the same time, and ultimately we could call their handlers in two different threads simultaneously. Thus, there is a need for thread-safe, thus mutexes.
In our asynchronous server, there are actually two pending operations at the same time:
void do_read()
{
async_read(sock_, buffer(read_buffer_),
MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2));
post_check_ping();
}
void post_check_ping()
{
timer_.expires_from_now(boost::posix_time::millisec(5000));
timer_.async_wait( MEM_FN(on_check_ping));
}
When performing a read operation, we will asynchronously wait for its completion for a certain period. Thus, there is a need for thread-safe. My advice is, if you plan on choosing a multi-threaded option, then make your class thread-safe from the start. This usually does not hurt performance (you can of course check this out). In addition, if you plan to go a multi-stream path, then follow it from the very beginning. Thus, you will encounter potential problems at an early stage. As soon as you find a problem, the first thing you should check is this happening with one running thread? If yes, then this is easy, just debug. Otherwise, you probably forgot to mutex some function.
Since our example needs thread-safe, we changed
talk_to_clientusing mutexes. In addition, we have an array of clients, which we refer to several times in the code, which also needs its own mutex. Avoiding deadlock and memory corruption is not so simple. Here's how to change the function
update_clients_changed():void update_clients_changed()
{
array copy;
{
boost::recursive_mutex::scoped_lock lk(clients_cs);
copy = clients;
}
for( array::iterator b = copy.begin(), e = copy.end(); b != e; ++b)
(*b)->set_clients_changed();
}
What we want to avoid is that the two mutexes are locked at the same time (which can lead to a deadlock situation). In our case, we do not want the
clients_cs client cs_ mutex to be locked at the same time.Asynchronous operations
Boost.Asio also allows you to perform any of your functions asynchronously. Just use the following code snippet:
void my_func()
{
...
}
service.post(my_func);
You can verify that it
my_func is being called in one of the threads that are being called service.run(). You can also run the asynchronous function and make a trailing handler that tells you when the function will complete. The pseudocode will look like this:void on_complete()
{
...
}
void my_func()
{
...
service.post(on_complete);
}
async_call(my_func);
There is no function
async_call, you have to create your own. Fortunately, this is not so difficult. See the following code snippet:struct async_op : boost::enable_shared_from_this, ...
{
typedef boost::function completion_func;
typedef boost::function op_func;
struct operation { ... };
void start()
{
{
boost::recursive_mutex::scoped_lock lk(cs_);
if ( started_)
return;
started_ = true;
}
boost::thread t( boost::bind(&async_op::run,this));
}
void add(op_func op, completion_func completion, io_service &service)
{
self_ = shared_from_this();
boost::recursive_mutex::scoped_lock lk(cs_);
ops_.push_back( operation(service, op, completion));
if ( !started_)
start();
}
void stop()
{
boost::recursive_mutex::scoped_lock lk(cs_);
started_ = false;
ops_.clear();
}
private:
boost::recursive_mutex cs_;
std::vector ops_;
bool started_;
ptr self_;
};
async_op A background thread is created
in the structure that will work ( run()) with all the asynchronous functions that you add ( add()) to it. For me, this does not seem to be something complicated, since for each operation the following is performed:- The function is called asynchronously.
completionthe function is called upon the first completion of the function- The instance
io_servicethat will perform thecompletionfunction. This is the place where you will be notified of completion. See the following code snippet:struct async_op : boost::enable_shared_from_this, private boost::noncopyable { struct operation { operation(io_service & service, op_func op, completion_func completion): service(&service), op(op)completion(completion), work(new o_service::work(service)){} operation() : service(0) {} io_service * service; op_func op; completion_func completion; typedef boost::shared_ptr
Please note that while the operation is not completed, we are constructing the instance
io_service::work, therefore it service.run()does not end its work on this until we have finished our asynchronous call (while the instance is alive, it io_service::work, service.run()will assume that it has work). Take a look at the following code:struct async_op : ...
{
typedef boost::shared_ptr ptr;
static ptr new_()
{
return ptr(new async_op);
}
...
void run()
{
while ( true)
{
{
boost::recursive_mutex::scoped_lock lk(cs_);
if ( !started_)
break;
}
boost::this_thread::sleep( boost::posix_time::millisec(10));
operation cur;
{
boost::recursive_mutex::scoped_lock lk(cs_);
if ( !ops_.empty())
{
cur = ops_[0];
ops_.erase( ops_.begin());
}
}
if ( cur.service)
cur.service->post(boost::bind(cur.completion, cur.op() ));
}
self_.reset();
}
};
The function
run()working in the background thread looks to see if there is work to do it; if so, it performs the asynchronous functions in turn. At the end of each call, it calls the corresponding termination function. To verify this, we will create a function
compute_file_checksumthat will execute asynchronously:size_t checksum = 0;
boost::system::error_code compute_file_checksum(std::string file_name)
{
HANDLE file = ::CreateFile(file_name.c_str(), GENERIC_READ, 0, 0,
OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED, 0);
windows::random_access_handle h(service, file);
long buff[1024];
checksum = 0;
size_t bytes = 0, at = 0;
boost::system::error_code ec;
while ( (bytes = read_at(h, at, buffer(buff), ec)) > 0)
{
at += bytes;
bytes /= sizeof(long);
for ( size_t i = 0; i < bytes; ++i)
checksum += buff[i];
}
return boost::system::error_code(0, boost::system::generic_category());
}
void on_checksum(std::string file_name, boost::system::error_code)
{
std::cout << "checksum for " << file_name << "=" << checksum << std::endl;
}
int main(int argc, char* argv[])
{
std::string fn = "readme.txt";
async_op::new_()->add( service, boost::bind(compute_file_checksum,fn),
boost::bind(on_checksum,fn,_1));
service.run();
}
Notice how I just showed you a possible implementation of a function call asynchronously. Instead of implementing a background thread, as I did, you can use an internal instance
io_serviceto which you send ( post()) an asynchronous function call. Let us leave this as an exercise for the reader. You can also expand the class to show the progress of asynchronous work (for example, in percent). In this case, you could show the progress in the progress bar, in the main stream.
Proxy implementation
A proxy is usually located between the client and server. It receives a request from the client, can change it, and sends it to the server. Then he takes the response from the server, can change it, and sends it to the client.
What is the special feature of the proxy server? For our purposes, we will have two sockets for each connection, one for the client, the other for the server. This complicates the implementation of the proxy quite a bit.
Implementing a proxy for a synchronous application will be more complicated than for an asynchronous one; data can come from both ends (from the client and server), at the same time, data can be sent to both of them (client and server). This means that if we choose the synchronous option, we can end up blocking reading or writing on the one hand, while we need to read or write on the other hand, which means that we will stop responding at one end.
Consider the following points in a simple example of an asynchronous proxy:
- In our case, we know that both connections are established. This is not always the case, for example, for a web proxy, the client tells us the server address.
- For the sake of simplicity, consider the following code fragment, it is not thread-safe:
class proxy : public boost::enable_shared_from_this{ proxy(ip::tcp::endpoint ep_client, ip::tcp::endpoint ep_server) : ... {} public: static ptr start(ip::tcp::endpoint ep_client, ip::tcp::endpoint ep_svr) { ptr new_(new proxy(ep_client, ep_svr)); // ... connect to both endpoints return new_; } void stop() { // ... stop both connections } bool started() { return started_ == 2; } private: void on_connect(const error_code & err) { if ( !err) { if ( ++started_ == 2) on_start(); } else stop(); } void on_start() { do_read(client_, buff_client_); do_read(server_, buff_server_); } ... private: ip::tcp::socket client_, server_; enum { max_msg = 1024 }; char buff_client_[max_msg], buff_server_[max_msg]; int started_; };
This is a very simple proxy. When connected at both ends, it starts reading on both connections (function
on_start()):class proxy : public boost::enable_shared_from_this
{
...
void on_read(ip::tcp::socket & sock, const error_code& err, size_t bytes)
{
char * buff = &sock == &client_ ? buff_client_ : buff_server_;
do_write(&sock == &client_ ? server_ : client_, buff, bytes);
}
void on_write(ip::tcp::socket & sock, const error_code &err, size_t bytes)
{
if ( &sock == &client_)
do_read(server_, buff_server_);
else
do_read(client_, buff_client_);
}
void do_read(ip::tcp::socket & sock, char* buff)
{
async_read(sock, buffer(buff, max_msg),
MEM_FN3(read_complete,ref(sock),_1,_2),
MEM_FN3(on_read,ref(sock),_1,_2));
}
void do_write(ip::tcp::socket & sock, char * buff, size_t size)
{
sock.async_write_some(buffer(buff,size),
MEM_FN3(on_write,ref(sock),_1,_2));
}
size_t read_complete(ip::tcp::socket & sock, const error_code & err, size_t bytes)
{
if ( sock.available() > 0)
return sock.available();
return bytes > 0 ? 0 : 1;
}
};
After each successful read (on_read), it passes the message to the other side. Once the message has been successfully transmitted (on_write), we begin to read again.
For this to work, use the following code snippet:
int main(int argc, char* argv[])
{
ip::tcp::endpoint ep_c( ip::address::from_string("127.0.0.1"), 8001);
ip::tcp::endpoint ep_s( ip::address::from_string("127.0.0.1"), 8002);
proxy::start(ep_c, ep_s);
service.run();
}
You have noticed that I am reusing buffers (
buff_client_ and buff_server_) for reading and writing. This reuse is normal because the read message from the client is written to the server before the new message is read from the client and vice versa. It also means that this particular implementation suffers from a live response problem. While we are in the process of recording on side B, we are not reading from side A (we restart reading from side A after the write operation on side B is completed). You can change the implementation to overcome this problem by following these steps:- You must use multiple buffers to read.
- After each successful read operation, in addition to asynchronous write on the other side, make an additional asynchronous read (to a new buffer).
- After each successful write operation, destroy (or reuse) the buffer.
Leave this as an exercise for you.
Summary
There are many more things to consider when deciding which direction to go: synchronous or asynchronous.
In this chapter we examined:
- How to easily implement, test and debug each type of application
- How threads affect your application
- How application behavior (pull-like or push-like) affects its implementation
- How can you connect your own asynchronous operations when you implement an asynchronous application
Next, we are going to consider several not so well-known features of Boost.Asio, as well as my favorite feature of Boost.Asio -
co-routineswhich will allow you to use all the advantages of the asynchronous approach. Resources for this article: link
Thank you all for your attention, see you soon!