Money to the wind: why your anti-phishing does not detect phishing sites and how Data Science will make it work?

Recently, phishing is the easiest and most popular way for cybercriminals to steal money or information. There is no need to go far for examples. Last year, leading Russian enterprises were faced with an unprecedented attack - the attackers massively registered fake resources, exact copies of the sites of fertilizer and petrochemical manufacturers, to conclude contracts on their behalf. The average damage from such an attack - from 1.5 million rubles, not to mention the reputational damage suffered by the company. In this article, we’ll talk about how to effectively detect phishing sites using resource analysis (CSS, JS images, etc.) rather than HTML, and how Data Science can solve these problems.
Pavel Slipenchuk, Machine Learning Systems Architect, Group-IB
Phishing epidemic
According to Group-IB, over 900 clients of various banks are victims of only financial phishing in Russia every day - this figure is 3 times the daily number of victims of malware. The damage from a phishing attack on a user varies from 2,000 to 50,000 rubles. Scammers do not just copy the website of a company or a bank, their logos and company colors, content, contact information, register a similar domain name, they also actively advertise their resources in social networks and search engines. For example, they are trying to display links to their phishing sites in the tops of the query “Transfer money to the card”. Most often, fake websites are created precisely in order to steal money when transferring from card to card or when paying for the services of mobile operators instantly.
Phishing (from phishing, from fishing - fishing, fishing) - a type of Internet fraud, the purpose of which is to fraudulently force the victim to provide the fraudster with the confidential information he needs. Most often, passwords of access to a bank account are stolen to further steal money, social network accounts (to extort money or send spam on behalf of the victim), sign up for paid services, send mail or infect a computer, making it a link in the botnet.By means of attacks, you should distinguish between 2 types of phishing targeted at users and companies:
- Phishing sites that copy the original resource of the victim (banks, airlines, online stores, businesses, government agencies, etc.).
- Phishing mailings, e-mail, sms, messages in social networks, etc.
Attacks on users are often done by loners, and the threshold for entry into this segment of the criminal business is so low that minimal “investment” and basic knowledge are enough for implementation. Phishing kits, the developers of phishing sites that can be freely purchased on the Darknet on hacker forums, also contribute to the spread of this type of fraud.
Attacks on companies or banks are arranged differently. They are carried out by more technically savvy attackers. As a rule, large industrial enterprises, online stores, airlines, and most often banks are chosen as victims. In most cases, phishing comes down to sending an email with an infected file attached. In order for such an attack to be successful, it is necessary to have specialists in writing malicious code, programmers to automate their activities, and people who are able to conduct initial reconnaissance on the victim and find weaknesses in the “staff” of the group.
In Russia, we estimate that there are 15 criminal phishing groups targeting financial institutions. The amount of damage is always small (ten times less than from bank Trojans), but the number of victims that they lure to their sites is daily estimated at thousands. About 10–15% of visitors to financial phishing sites themselves enter their data.
When a phishing page appears, the account goes on for hours, and sometimes even for minutes, as users incur serious financial, and in the case of companies, reputational damage. For example, some successful phishing pages were available for less than a day, but were able to cause damage to amounts from 1,000,000 rubles.
In this article we will focus on the first type of phishing: phishing sites. Resources that are “suspected” of phishing can be easily detected using various technical means: honeypots, crawlers, etc., however, it is problematic to make sure that they are really phishing. We will analyze how to solve this problem.
Fishing
If a brand does not follow its reputation, it becomes an easy target. It is necessary to intercept the initiative from the criminals immediately after the registration of their fake sites. In practice, the search phishing page is divided into 4 stages:
- Formation of a set of suspicious URLs for phishing scans (crawler, honeypots, etc.).
- Formation of a set of phishing addresses.
- The classification of already detected phishing addresses in the direction of the activity and the technology being attacked, for example, “RBS :: Sberbank Online” or “RBS :: Alfa-Bank”.
- Search for a donor page.
The implementation of points 2 and 3 falls on the shoulders of specialists in Data Science.
After that, you can already take active steps to block the phishing page. In particular:
- Add URLs to the blacklists of Group-IB products and products of our partners;
- automatically or manually send letters to the owner of the domain zone with a request to remove the phishing URL;
- send letters to the security of the attacked brand;
- etc.

HTML based methods
The classic solution to the problem of checking suspicious addresses for phishing and automatic detection of the affected brand are various ways to parse HTML source pages. The simplest is to write regular expressions. It's funny, but this trick still works. Even today, most novice phishers simply copy content from the original site.
Phishing kits can also develop very effective anti-phishing systems. But in this case, you need to explore the HTML-page. In addition, these solutions are not universal - the base of the “whales” is necessary for their development. Some phishing kits may be unknown to the researcher. And, of course, the analysis of each new “whale” is a rather laborious and expensive process.
All phishing detection systems based on HTML page analysis stop working after obfuscating HTML. And in many cases it is enough to simply change the HTML page frame.
According to Group-IB, at the moment such phishing sites are no more than 10% of the total number, but skipping even one can be costly for the victim.
Thus, it is enough for a fisher to bypass the blocking to simply change the HTML framework, less often to obfuscate the HTML page (confusing markup and / or loading content via JS).
Formulation of the problem. Resource Based Method
Much more effective and versatile methods for detecting phishing pages are based on the analysis of the resources used. A resource is any file that is loaded when rendering a web page (all images, cascading style sheets (CSS), JS files, fonts, etc.).
In this case, you can build a bichromatic graph, where some vertices will be addresses suspicious of phishing, and others - resources associated with them.
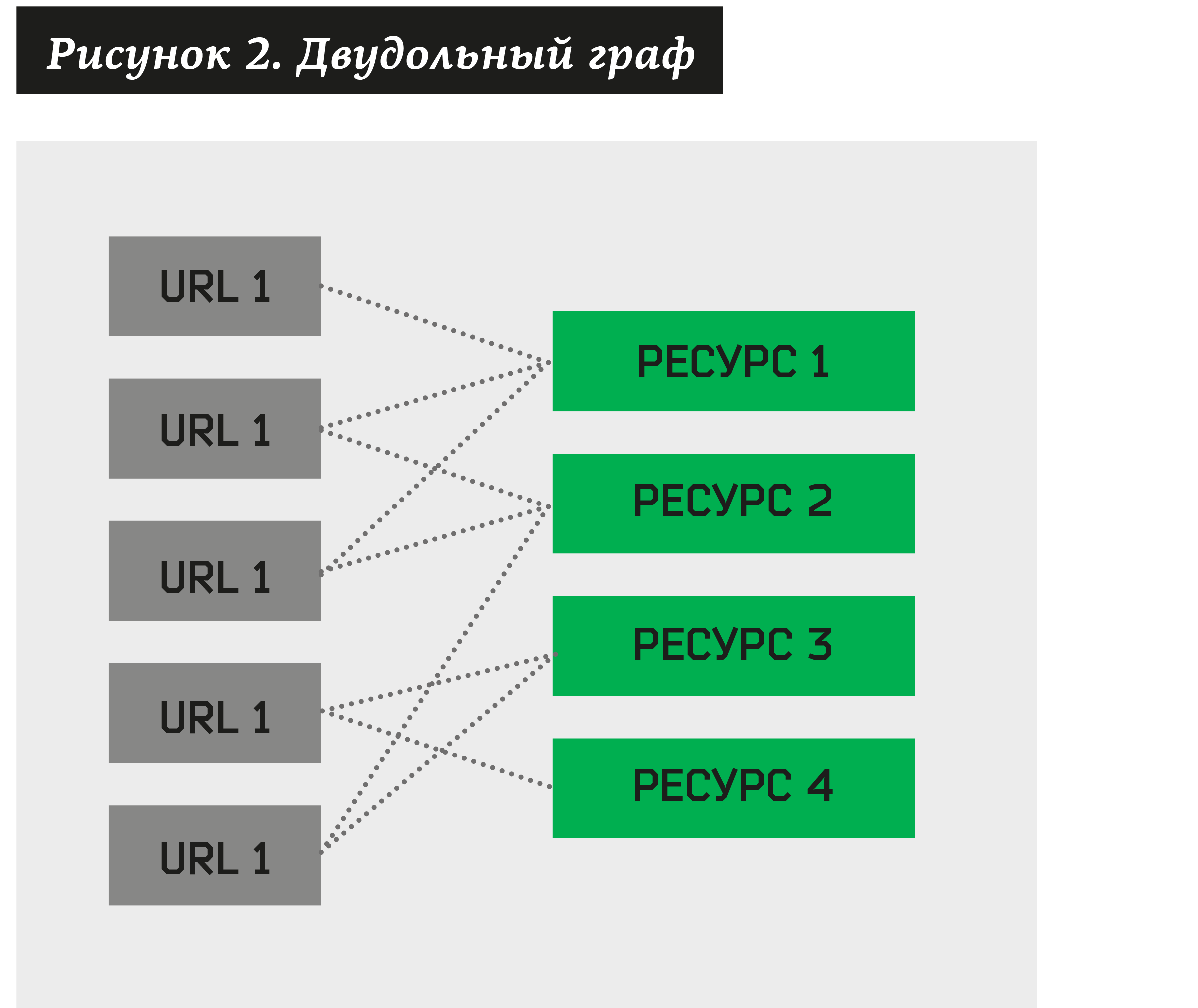
There is a clustering problem - to find a set of such resources that own a sufficiently large number of different URLs. By constructing such an algorithm, we can decompose any bipartite graph into clusters.
The hypothesis is that, based on real data, it is quite likely that the cluster contains a set of URLs that belong to the same brand and are generated by one phishing kits. Then, to test this hypothesis, each such cluster can be sent for manual verification to CERT (Information Security Incident Response Center). The analyst, in turn, would state the status of a cluster: +1 (“approved”) or –1 (rejected). An analyst would also assign an attacked brand to all approved clusters. At this "manual work" ends - the rest of the process is automated. On average, one approved group has 152 phishing addresses (data for June 2018), and sometimes even clusters of 500–1000 addresses come across!
Then, all the rejected clusters are removed from the system, and all their addresses and resources after some time are fed back to the input of the clustering algorithm. As a result, we get new clusters. And again we send them to check, etc.
Thus, for each newly received address, the system should do the following:
- Extract all the resources for a site.
- Check for ownership of at least one previously approved cluster.
- If the URL belongs to a cluster, automatically extract the brand name and perform an action for it (notify the customer, delete the resource, etc.).
- If it is impossible to put a single cluster on the resources, add the address and resources to the bipartite graph. In the future, this URL and resources will be involved in the formation of new clusters.
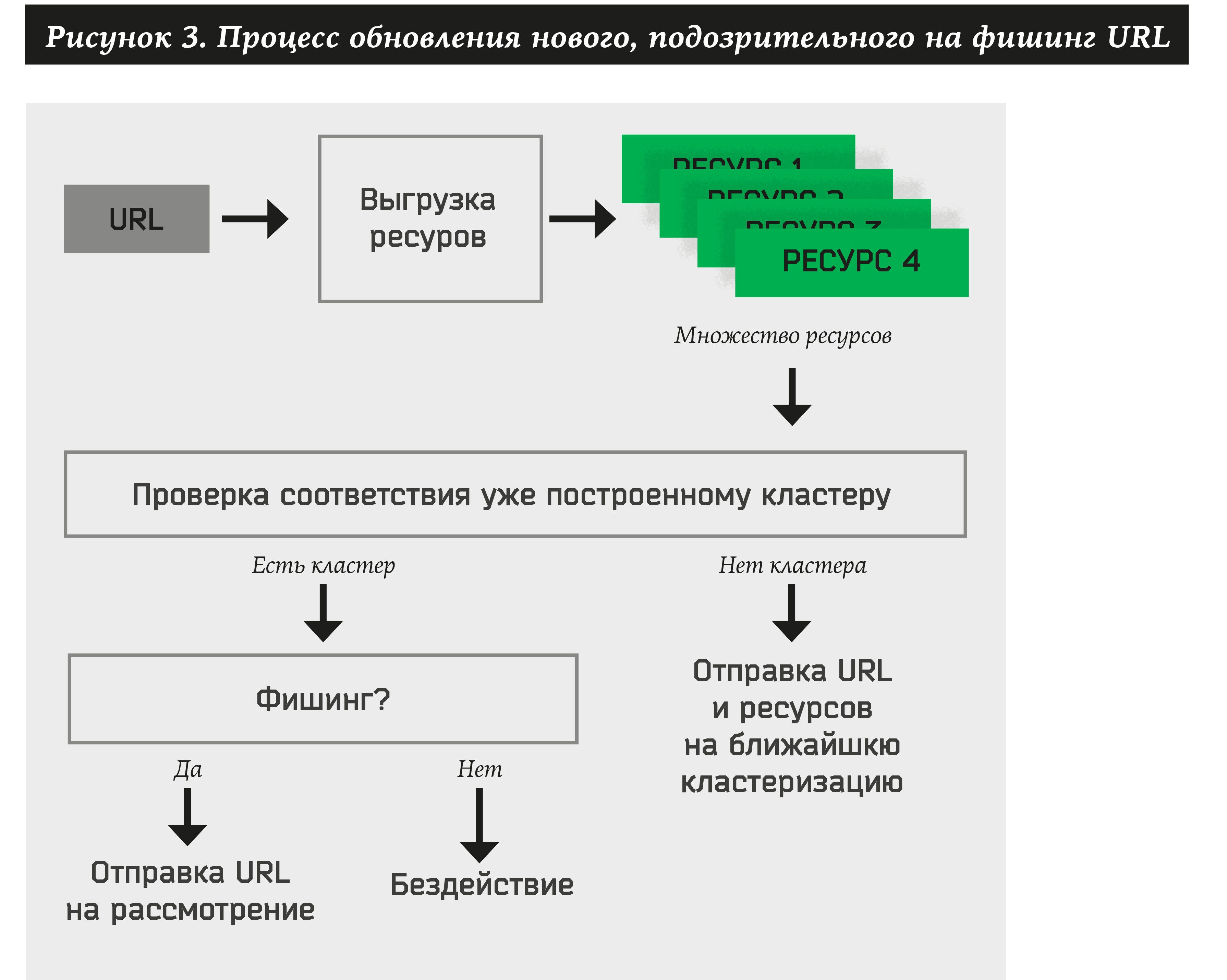
Simple resource clustering algorithm
One of the most important nuances that a Data Science specialist in information security must take into account is the fact that his opponent is a man. For this reason, the conditions and data for analysis change very quickly! A solution that perfectly fixes a problem now, in 2-3 months, can stop working in principle. Therefore, it is important to create either universal (clumsy) mechanisms, if possible, or the most flexible systems that can be quickly finalized. Data Science Specialist in IB will not be able to solve the problem once and for all.
Standard clustering methods do not work due to the large number of features. Each resource can be represented as a Boolean sign. However, in practice, we get from 5,000 website addresses per day, and each of them contains on average 17.2 resources (data for June 2018). The curse of dimension does not even allow to load data into memory, let alone build some kind of clustering algorithms.
Another idea is to try to cluster into clusters using various collaborative filtering algorithms. In this case, it was necessary to create another sign - belonging to a particular brand. The task will be to ensure that the system must predict the presence or absence of this feature for the remaining URLs. The method gave positive results, however, it had two drawbacks:
- for each brand it was necessary to create its own sign for collaborative filtering;
- needed a training set.
Recently, more and more companies want to protect their brand on the Internet and ask to automate the detection of phishing sites. Each new brand, taken under protection, would add a new attribute. Yes, and create a learning sample for each new brand - this is an additional manual labor and time.
We began to look for a solution to this problem. And found a very simple and effective way.
To begin with, we will construct a pair of resources according to the following algorithm:
- Take all kinds of resources (we denote them as a), for which at least N1 addresses, we denote this ratio as # (a) ≥ N1.
- We construct all possible pairs of resources (a1, a2) and select only those for which there will be at least N2 addresses, i.e. # (a1, a2) ≥ N2.
Then, we similarly consider pairs consisting of pairs obtained in the previous paragraph. As a result, we get fours: (a1, a2) + (a3, a4) → (a1, a2, a3, a4). Moreover, if at least one element is present in one of the pairs, instead of quadruples we get triples: (a1, a2) + (a2, a3) → (a1, a2, a3). From the resulting set, we leave only those fours and triples, which correspond to at least N3 addresses. And so on ...
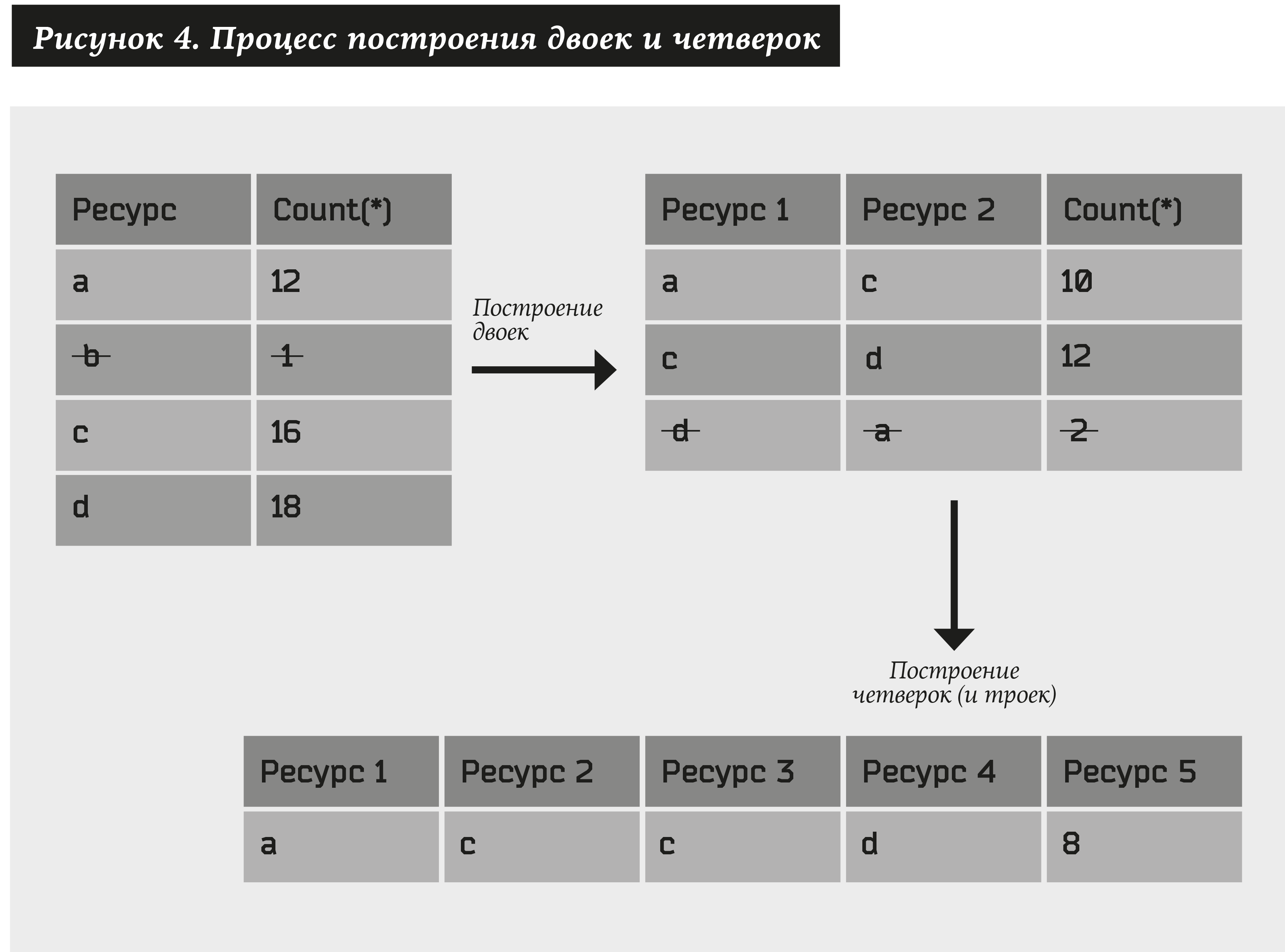
You can get a variety of resources of arbitrary length. We limit the number of steps to U. Then N1, N2 ... NU are the parameters of the system.
The values N1, N2 ... NU are the parameters of the algorithm, they are set manually. In the general case, we have CL2 different pairs, where L is the amount of resources, i.e. the complexity for constructing pairs will be O (L2). Then a quad is created from each pair. And in theory, we might get O (L4). However, in practice, these pairs are much smaller, and with a large number of addresses, the O (L2log L) dependence was obtained empirically. At the same time, the next steps (transformations of twos into fours, fours into eights, etc.) are negligible.
It should be noted that L is the number of nonclustered URLs. All URLs that can already be attributed to any previously approved cluster are not included in the clustering sample.
At the output, you can create many clusters consisting of the largest possible sets of resources. For example, if there is (a1, a2, a3, a4, a5) that satisfies the Ni boundaries, you should remove from the set of clusters (a1, a2, a3) and (a4, a5).
Each received cluster is then sent to a manual check, where the CERT analyst assigns it a status: +1 (“approved”) or –1 (“discarded”), and also indicates whether the URLs that fall into the cluster are phishing or legitimate sites.
When adding a new resource, the number of URLs may decrease, remain the same, but never increase. Therefore, for any resources a1 ... aN, the following relationship holds:
# (a1) ≥ # (a1, a2) ≥ # (a1, a2, a3) ≥ ... ≥ # (a1, a2, ..., aN).
Therefore, it is reasonable to set the parameters:
N1 ≥ N2 ≥ N3 ≥ ... ≥ NU.
At the exit, we give out all sorts of groups to check. In fig. 1 at the very beginning of the article shows the real clusters for which all resources are images.
Using the algorithm in practice
Note that now completely eliminate the need to explore phishing kits! The system automatically clusters and finds the desired phishing page.
Daily, the system receives from 5,000 phishing pages and constructs only 3 to 25 new clusters per day. For each cluster, a list of resources is unloaded, a lot of screenshots are created. This cluster is sent to the CERT analyst for confirmation or denial.
When you run the accuracy of the algorithm was low - only 5%. However, after 3 months the system kept the accuracy from 50 to 85%. In fact, accuracy does not matter! The main thing is that analysts have time to view the clusters. Therefore, if the system, for example, generates about 10,000 clusters per day and you have only one analyst, you will have to change the system parameters. If not more than 200 per day, this is a task feasible for one person. As practice shows, on average, visual analysis takes about 1 minute.
The completeness of the system is about 82%. The remaining 18% are either unique phishing cases (so they cannot be grouped), or phishing, which has a small amount of resources (there is nothing to group), or phishing pages that have gone beyond the boundaries of the N1, N2 ... NU parameters.
An important point: how often to launch a new clustering on fresh, undelivered URLs? We do this every 15 minutes. At the same time, depending on the amount of data, the clustering time itself takes 10–15 minutes. This means that after the appearance of a phishing URL, there is a 30-minute lag in time.
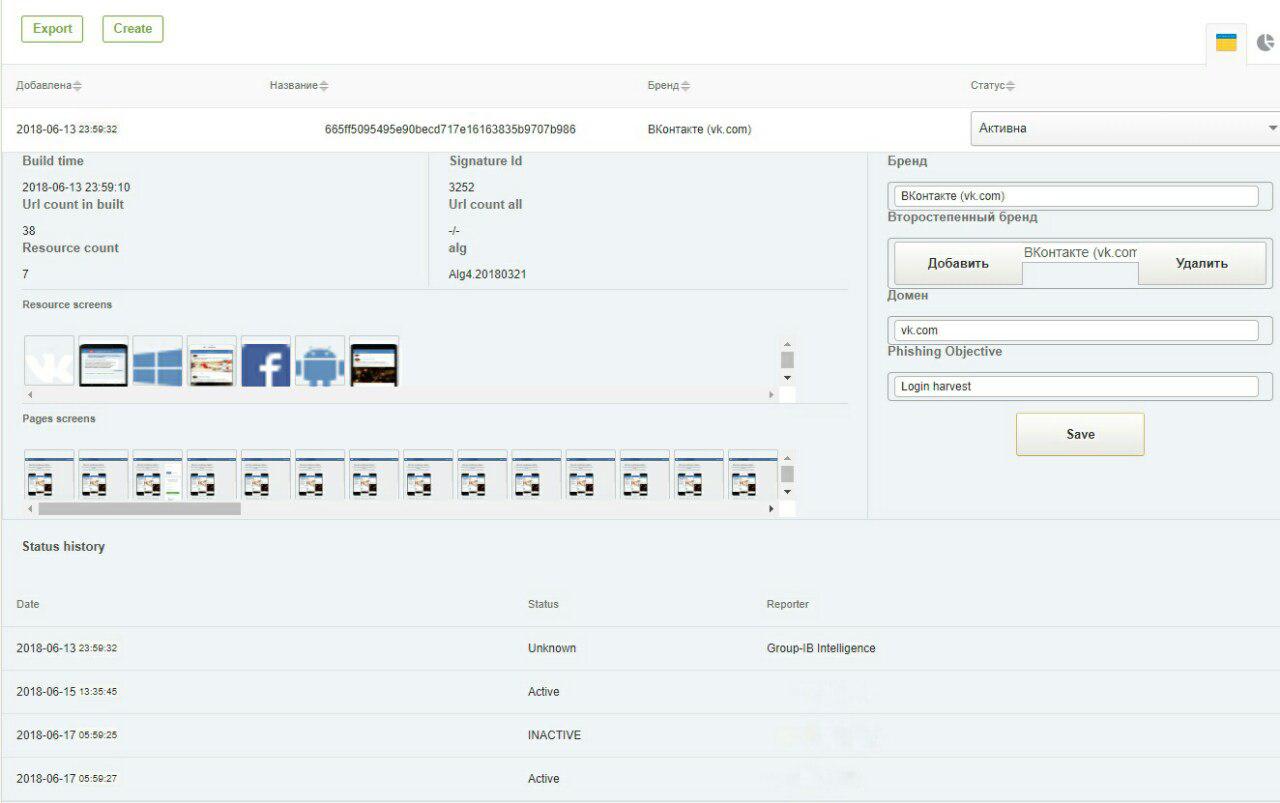
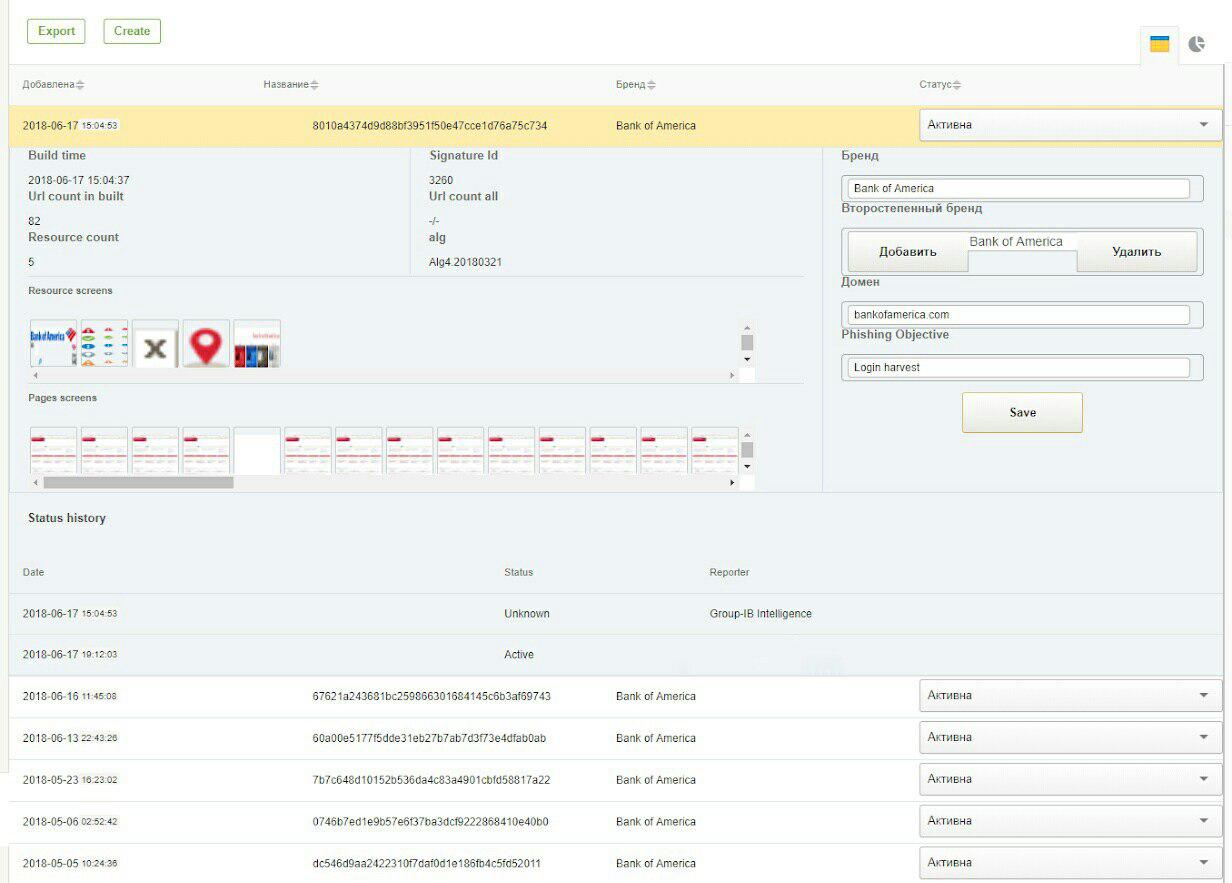
Below are 2 screenshots from the GUI system: signatures for detecting phishing on VKontakte and Bank Of America.
When the algorithm does not work
As mentioned above, the algorithm does not work in principle, if the boundaries specified by the parameters N1, N2, N3 ... NU are not reached, or if the amount of resources is too small to form the necessary cluster.
Fisher can bypass the algorithm, creating unique resources for each phishing site. For example, in each image you can change one pixel, and for loadable JS and CSS libraries you can use obfuscation. In this case, it is necessary to develop an algorithm for a comparable hash (perceptual hash) for each type of documents loaded. However, these questions are beyond the scope of this article.
We connect all together
We combine our module with classic HTML regulars, data obtained from Threat Intelligence (cyber intelligence system), and we get a completeness of 99.4%. Of course, this is completeness on data that has already been pre-classified by Threat Intelligence as suspicious of phishing.
Nobody knows what completeness on all possible data, since it is impossible in principle to cover the entire Darknet, however, according to Gartner, IDC and Forrester reports, in terms of its capabilities Group-IB is one of the leading international suppliers of Threat Intelligence solutions.
And what to do with unclassified phishing pages? On the day they get about 25-50. They can be checked manually. In general, in any task that is quite difficult for Data Sciense, there is always manual labor in the field of information security, and any statements about 100% automation are marketing fiction. The task of Data Sciense specialist is to reduce manual labor by 2–3 orders of magnitude, making the work of the analyst as effective as possible.
Article published on JETINFO