Kotlin performance on Android
Let's talk today about the performance of Kotlin on Android in production. Let's take a look under the hood, implement cunning optimizations, compare bytecode. Finally, we will seriously approach the comparison and measure the benchmarks.
This article is based on the report by Alexander Smirnov at AppsConf 2017 and will help you figure out whether you can write code on Kotlin, which will not be inferior to Java in speed.
About the speaker: Alexander Smirnov CTO in the company PapaJobs, has a video blog " Android in faces ", and is also one of the organizers of the Mosdroid community.
Let's start with your expectations.
Let's figure it out. Traditionally, when the question of performance comparison arises, everyone wants to see benchmarks and specific numbers. Unfortunately, there is no JMH ( Java Microbenchmark Harness ) for Android , so we cannot measure everything as coolly as Java. So what is left for us to do, as written below?
If you ever try to measure your code this way, then one of the JMH developers will be sad, cry and come to you in a dream - never do that.
On Android, you can do benchmarks, in particular, Google demonstrated this even last year’s I / O. They said that they greatly improved the virtual machine, in this case ART, and if on Android 4.1 one allocation of the object took about 600-700 nanoseconds, then in the eighth version it will take about 60 nanoseconds. Those. they were able to measure it with such accuracy on a virtual machine. Why can not we do the same - we do not have such tools.
If we look at all the documentation, the only thing we can find is the recommendation above, how to measure UI:
adb shell dumpsys gfxinfo% package_name%
Actually, let's do that, and see at the end what it will give. But first we will determine what we will measure and what else we can do.

I like the first option the most, but most likely the majority thinks that it’s impossible to make all the code work very, very quickly and it’s important that at least it doesn’t lag UiThread or custom view. With this, I also agree - this is very, very important. What you have in a separate stream of JSON will be deserialized for 10 milliseconds longer, then no one will notice.
Gestalt psychology says that when we blink, about 150-300 milliseconds, the human eye is at a loss of focus and does not see what is actually happening there. And then these 10 milliseconds of weather do not. But if we return to Gestalt psychology, what is important is not what I really see and what is really happening - what I understand as a user is important.
Those. if we make the user think that everything is very, very fast, and in fact it will just be beautifully beaten up, for example, with the help of beautiful animation, he will be satisfied, even if in fact it is not.
The motives of gestalt psychology in iOS have been moving for a long time. Therefore, if you take two applications with the same processing time, but on different platforms, and put them next to each other, it will seem that everything is faster on iOS. Animation in iOS processes a bit faster, earlier animation starts when loading and many other animations, so that it is beautiful.
So the first rule is to think about the user.
And for the second rule you need to plunge into hardcore.
KOTLIN STYLE
To honestly evaluate the performance of Kotlin, we will compare it with Java. Therefore, it turns out, it is impossible to measure some things that are only in Kotlin, for example:
The collection of the API , which Kotlin provides us with, is very cool, very fast. In Java, this is simply not there, there are only different implementations. For example, the Liteweight Stream API library will be slower because it does the same thing as Kotlin, but with one or two additional allocations per operation, since everything turns into an additional object.
If we take the Stream API from Java 8, then it will run slower than the Kotlin API API collection, but with one condition - there is no paralysis in the API API collection as in Java 8. If we enable parallel, on large amounts of data, the API API streaming Java will bypass the Kotlin Solitaire API. Therefore, we cannot compare such things, because we make comparisons from the point of view of Android.
The second thing that, I think, cannot be compared, is Method default parameters - A very cool feature, which, by the way, is in Dart. When you call a method, it may have some parameters that can take on some value, or they can be NULL. And therefore you do not do 10 different methods, but do one method and say that one of the parameters can be NULL, and later use it without any parameter. Those. it will look, the parameter has come, or it has not come. Very convenient in that you can write a lot less code, but the inconvenience is that you have to pay for it. This is syntactic sugar: you, as a developer, consider that this is one API method, but in reality, under a hood, every variation of a method with missing parameters is generated in the byte code. And in each of these methods a check is made bit by bit whether this parameter has arrived. If he came, then ok, if he did not come, then we make up the bit mask, and depending on this bit mask, the original method that you wrote is already being called. Bitwise operations, allif / else cost a little money, but very little, and it’s normal that you have to pay convenience. It seems to me that this is absolutely normal.
The next item that cannot be compared is Data classes .
Everyone laments that in Java there are parameters for which there are model classes. Those. you take the parameters and make more methods, getters and setters for all these parameters. It turns out that for a class with ten parameters you need a whole pair of getters, setters and a whole heap of everything. Moreover, if you do not use generators, then you have to write it with your hands, which is generally terrible.
Kotlin lets you get away from it all. First, since there are properties in Kotlin, you do not need to write getters and setters. It has no class parameters, all properties. In any case, we think so. Secondly, if you write that it is Data classes, a whole bunch of everything else will be generated. For example, equals (), toStrung () / hasCode (), etc.
Of course, this has its drawbacks. For example, I did not need to have all 20 parameters of my data classes compare at once in equals (), I only needed to compare 3. Someone doesn’t like all this because performance is lost on this, and besides, a lot is generated service functions, and the compiled code is quite voluminous. That is, if you write everything with your hands, the code will be less than if you use data classes.
I do not use data classes for another reason. Previously, there were restrictions on the expansion of such classes and something else. Now with all this better, but the habit has remained.
What is very, very cool in Kotlin, and what will it always be faster than Java? These are Reified types , which is also in Dart, by the way.
You know that when you use generics, then at the compilation stage, type erasure occurs (type erasure) and at runtime you don’t know what object of this generic is actually used.
With Reified types, you do not need to use reflection in many places, when in Java you would need it, because with inline methods with Reified, knowledge of the type remains, and therefore it turns out that you do not use reflection and your code runs faster. Magic.
And there are Coroutines. They are very cool, I like them very much, but at the time of the performance they were only in the alpha version, so there was no possibility to make correct comparisons with them.
FIELDS
Therefore, let's go further, let's move on to what we can compare to Java and what we can influence in general.
As I said, we have no parameters for the class, we have properties.
We have a var, we have a val, we have an external class, one of the properties of which is @JvmField, and we’ll see what actually happens with the work () function: we summarize the value of the a field and the b field of our own class and the value of the field a and the field b of the outer class, which is written in the immutable field c.
The question is, what exactly will be caused in d = a + b. We all know that this is a property, then the getter of this class will be called for this parameter.
But if we look at the byte-code, we will see that in reality there is a getfield conversion. That is, it is not a call to the InvokeVirtual function that occurs in the bytecode, but a direct call to the field. There is nothing that was promised to us initially, that we have all the properties, not the field. It turns out that Kotlin is deceiving us, there is a direct appeal.
What will happen if we still see which bytecode is generated for another string: val e = ca + cb?
Previously, if you turned to the non-privileged property, then you always had a call to InvokeVirtual. If it was a private property, then it was accessed via GetField. GetField is much faster than InvokeVirtual, in the specification from Android it is stated that it is 3–7 times faster to access the field directly. Therefore, it is recommended to always refer to the Field, and not through getters or setters. Now, especially in the eighth ART virtual machine, there will already be other numbers, but if you still support 4.1, this will be true.
Therefore, it turns out, we still benefit from having GetField, not InvokeVirtual.
Now, you can get GetField if you are accessing a property of your own class, or, if it is a public property, then you need to put @JvmField. Then just in the bytecode there will be a call to GetField, which is 3–7 times faster.
It is clear that here we speak in nanoseconds and, on the one trona, this is very, very little. But, on the other hand, if you do it in the UI stream, for example, in the ondraw method you apply to some view, this will affect the rendering of each frame, and you can do it a little faster.
If you add up all the optimizations, then in sum it may give something.
STATIC !?
And what about the statics? We all know that in Kotlin static is a companion object. Previously, you probably added some kind of tag, for example, public static, final static, etc., if you convert it into code on Kotlin, then you will get a companion object, in which something like this will be written:
Yes, indeed, Kotlin declares that here it is in Kotlin - static, that object says that it is static. In reality, it is not static.
If we look at the generated byte-code, we will see the following:
Test.Companion is generated by the singleton object for which the instancé is created, this instancé is recorded in its own field. After that, access to any of the companion object occurs through this object. It takes getstatic, that is, a static instance of this class and calls the invokevirtual function getK, and exactly the same for the work2 function. Thus, we get that it is not static.
This is important, for the reason that the old JVM invokestatic was about 30% faster than invokevirtual. Now, of course, optimized virtualization is happening on HotSpot very cool, and it is almost imperceptible. However, you need to keep this in mind, especially since there is one extra allocation here, and an extra location on 4ST1 is 700 nanoseconds, also a lot.
Let's look at the Java-code, which turns out, if you reverse the byte-code back:
A static field is created, a static final implementation of the Companion object, getters and setters are created, and, as you can see, by accessing the static field inside, an additional static method appears. Everything is quite sad.
What can we do by making sure that this is not static? We can try adding @JvmField and @JvmStatic and see what happens.
I’ll say right away that you can’t get away from @JvmStatic, in the same way it will be an object, since this is a companion object, there will be an extra allocation of this object and there will be an extra call.
But the call will change only for k, because it will be @JvmField, it will be taken directly as getstatic, getters and setters will not be generated anymore. And for the work2 function, nothing will change.
The second option, how to create static is suggested in the Kotlin documentation, so it’s said that we can simply create an object and this will be static code.
In reality, this is also not the case.
It turns out that we make a call to getstatic instance from singletone, which is being created, and we call the exact same virtual methods.
The only way we can achieve exactly invokestatic is Higher-Order Functions. When we simply write some function outside the class, for example, fun test2 will actually be called static.
Moreover, the most interesting thing is that a class will be created, an object, in this case, testKt, it will generate an object for itself, it will generate a function that it will put into this object, and then it will be invoked as invokestatic.
Why this was done is not clear. Many are unhappy with this, but there are those who consider this implementation quite normal. Since the virtual machine, incl. Art is improving, now it is not so critical. In the eighth version of Android, just like on HotSpot, everything is optimized, but still these little things slightly affect the overall performance.
NULLABILITY
This is the next interesting example. It would seem that we noted that the second can be nullable, and it must be checked before doing something with it. In this case, I expect that we have one if. When this code is deployed in if second is not equal to zero, then I think that the execution will go on and output only first.
How does this all really unfold in java code? Actually there will be a check.
We will get Intrinsics initially. Suppose that what I am saying is that this one here is
If will unfold into a ternary operator. But besides this, although we have even fixed that the first parameter cannot be nullable, it will still be checked through Intrinsics.
Intrinsics is an internal class in Kotlin that has some set of parameters and checks. And every time you make a method parameter not nullable, it still checks it. What for? Because we work in Interop Java, and it may happen that you expect that it will not be nullable here, but it will come from Java somewhere.
If you check it, it will go further along the code, and then after 10-20 method calls, you will do something with a parameter that, although it cannot be nullable, but for some reason it turned out to be. You will all fall, and you can not understand what actually happened. To avoid this situation, every time you pass the null parameter, you will still have to check it. And if it is nullable, it will be exception.
This test is also worth something, and if there are a lot of them, it will not be very good.
But in fact, if we talk about HotSpot, then 10 calls of these Intrinsics will take about four nanoseconds. This is very, very little, and you should not worry about this, but this is an interesting factor.
PRIMITIVES
In Java, there is such a thing as primitives. In Kotlin, as we all know, there are no primitives, we always operate with objects. In Java, they are used to provide better performance of objects on any minor calculations. Folding two objects is much more expensive than adding two primitives. Consider an example.
There are three numbers, for the first two, not null type will be displayed, and about the third we ourselves say that it can be nullable.
If you look at the bytecode and see which Java code is generated, then the first two numbers are not null, and therefore they can be primitives. But the primitive cannot contain a Null, only an object can do this, so an object will be generated for the third number.
AUTOBOXING
When you work with primitives, and perform an operation with a primitive and non-primitive, then either you need to translate one of them into a primitive, or into an object.
And, it would seem, it is no wonder that if you do operations with nullable and not nullable in Kotlin, then you lose a little bit in performance. Moreover, if there are many such operations, then you lose a lot.
See where Boxing / Unboxing will be here? I also did not see until I looked at the byte code.
Actually, I expected that there would be something like this comparison: if the string is not null and if it is empty, then set to true, otherwise, set to false. It seems simple, but in reality the following code is generated:
Let's look inside. The variable a is taken , it is cast in CharSequence, after it has been cast, which has also been spent some time, another check is called - StringsKt.isBlank - this is how the extension function for CharSequence is written, so it is cast and sent. Since the first expression can be nullable, it takes it and makes Boxing, and wraps it all in Boolean.valueOf. Therefore, the primitive true also becomes an object, and only after that a check occurs and Intrinsics.areEqual is called.
It would seem such a simple operation, but such an unexpected result. In fact, such things are very few. But when you can have nullable / not nullable, you can generate a lot of this, and that you would never expect. Therefore, I recommend you to avoid confusions as early as possible. Those. as soon as possible to come to the immunity of values and move away from nullable , so that you can operate as quickly as possible, not null.
Loops
The next interesting thing.
You can use the usual for, which is in Java, but you can also use the new user-friendly API - just write through the list in the list. For example, you can call the work function in a loop, where it will be some element of this list.
An iterator will be generated and there will be a trivial iteration over the iterator. This is normal, it is much recommended. But if we see what advice Google gives us, then we find out, in terms of performance, specifically for ArrayList, iteration through for works 3 times faster than through an iterator. In all other cases, the iterator will work identically.
Therefore, if you are sure that you have an ArrayList, it is logical to do another thing - to write your foreach.
This will also be an API, but which will generate a slightly different code. Here we use all the power that Kotlin gives us: we will make an extension function that will be “inline”, which will be of type reified, i.e. we will not erase anything, and we will also do so that we will give the lambda, for which we will perform the crossinline. Therefore, everything will become very good everywhere, even perfect, the bill works very quickly. 3 times faster, as recommended by Google’s Android specification.
Rangs
We could do the same with Ranges.
The previous example and this with: Unit will be identically worked out in bytecode. But if you try to do here either −1, or until add, or another step, then there will be back iterators. And besides this, there will be an allocation for the object that will generate ranges. Those. you allocate the object to which the starting point is written. Each subsequent iteration will call this method with the next step value. It's worth remembering.
INTRINSICS
Let us return to Intrinsics, and consider another interesting example:
In this case Intrinsics is called twice - for both second and first.
They can be turned off, but they can not be turned off in the gradle. If you highlight what is very, very important up to these 4 nanoseconds, then you can turn them off there. You can make a Kotlin module with a UI, where you are sure that nothing can get there nullable, and pass directly to Kotlin to the compiler:
kotlinc -Xno-call-assertions -Xno-param-assertions Test.kt
This will cut down Intrinsics, as checking input parameters and result.
In fact, I have never seen the second part be particularly useful. But the parameter - Xno-param-assertions - cuts down these two Intrinsics, and everything works very well.
If this is done everywhere, it will not work very well, because it leads to what I have already said that the program may fall where you don’t expect. And in those places where you are really sure that an additional check is not needed, you can do so.
REDEX
Many believe that the getters and setters, as written in the documentation, inline in Proguard. But I would say that in 99% of cases a method that consists of a single function will not be inline. In Android 8.0, this was optimized, and there it is already invaded. It only remains to wait, when we will all be on it.
Another option is to use other than Proguard, a Facebook tool called Redex . It also uses bytecode optimizations, but in the same way it does not inline everything, and so does not inline getters and setters. It turns out that Jvm Fields is currently the only way to get away from the getter and setter for simple properties.
In addition, other optimizations are included in Redex. In particular, I created a primitive application where I did not write any code at all, I added Proguard for it, which cut out everything that was possible. After that, I turned this application through Redex and received a minus 7% by weight of the APK. I think this is good enough.
We turn to the benchmarks. I took an interesting enough application that has a lot of frames and a lot of animations to make it convenient to measure. This application was written by Jaroslav Mytkalyk , and I measured the benchmarks on four different phones. Actually, I did dumpsys gfxinfo and collected data thousands of times, which I then reduced to the final value. In my github profilegithub.com/smred you can find the source and results.
So, on a rather weak Huawei device.
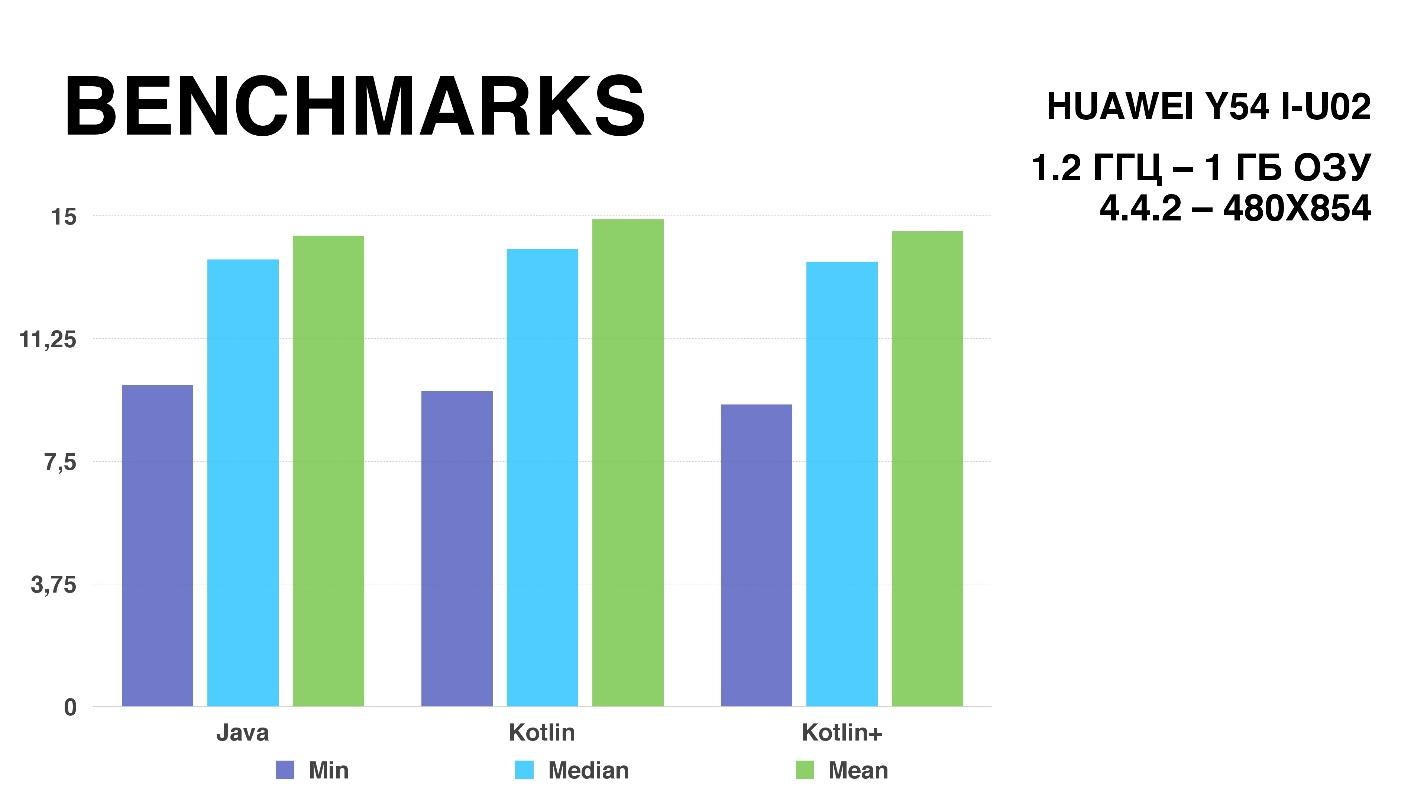
The purple column shows the minimum version of one frame. Green - maximum, always jumping on different calculations. The blue bar represents the median value, which was fairly stable; the error was about 0.04 milliseconds. But, unfortunately, according to the schedule, the benchmark result is quite difficult to understand - everything is very close, so let's look at the time of drawing one frame in milliseconds.
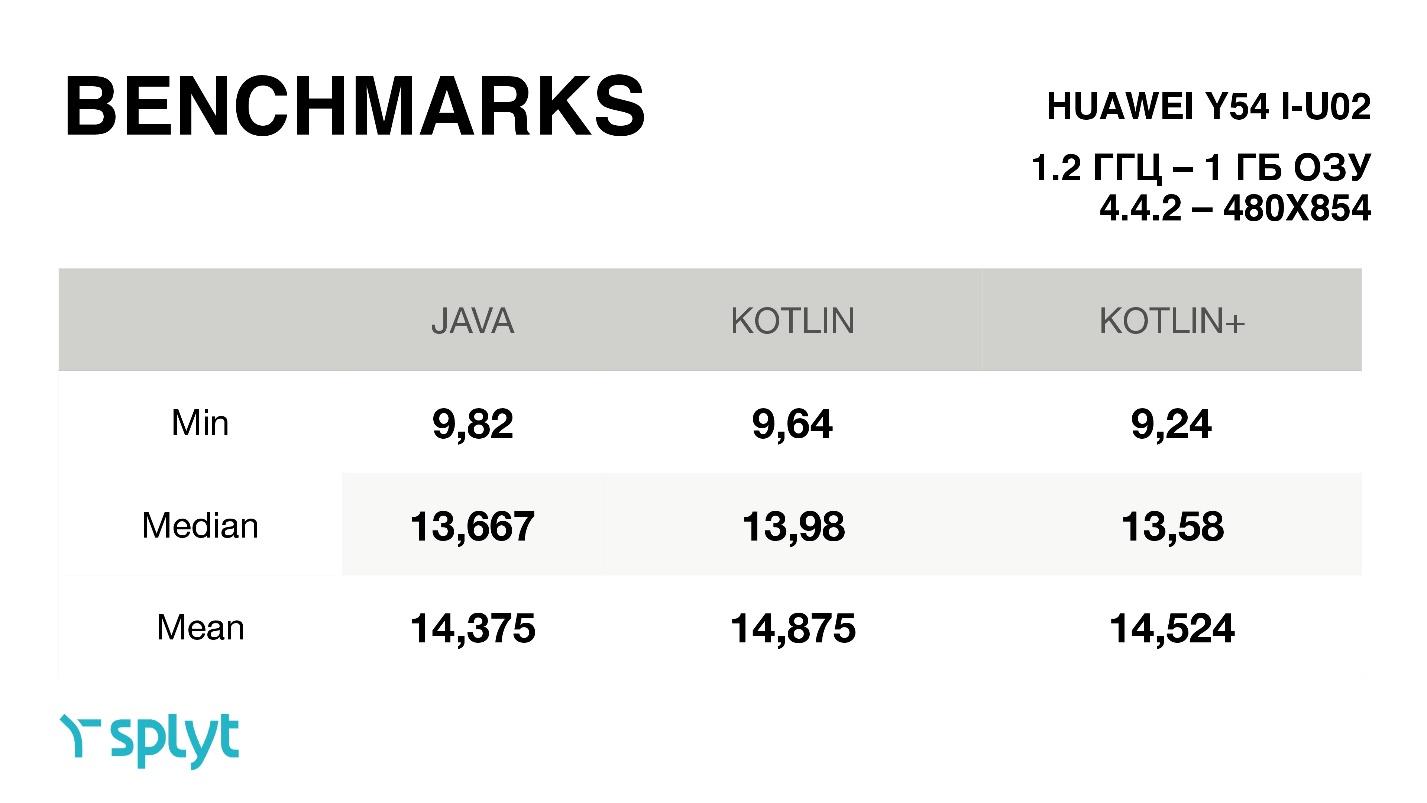
When we just switched to Kotlin, we got a little more time per frame. After all the optimizations have been made, the differences are almost within the margin of error. But for some reason it turned out that the median in optimized Kotlin is even greater than that of Java. But if you look at the average, then, of course, the results were always slightly better than in the just autogenerated Kotlin code. On four devices, a similar circuit was obtained.

It turns out that the optimization I was talking about really helped and led to the fact that Kotlin offhand almost always works the same way as Java code. Yes, because of some features and differences, for example, in abstractions, there is a little extra workload, but if you want, you can always achieve almost identical speed of work.
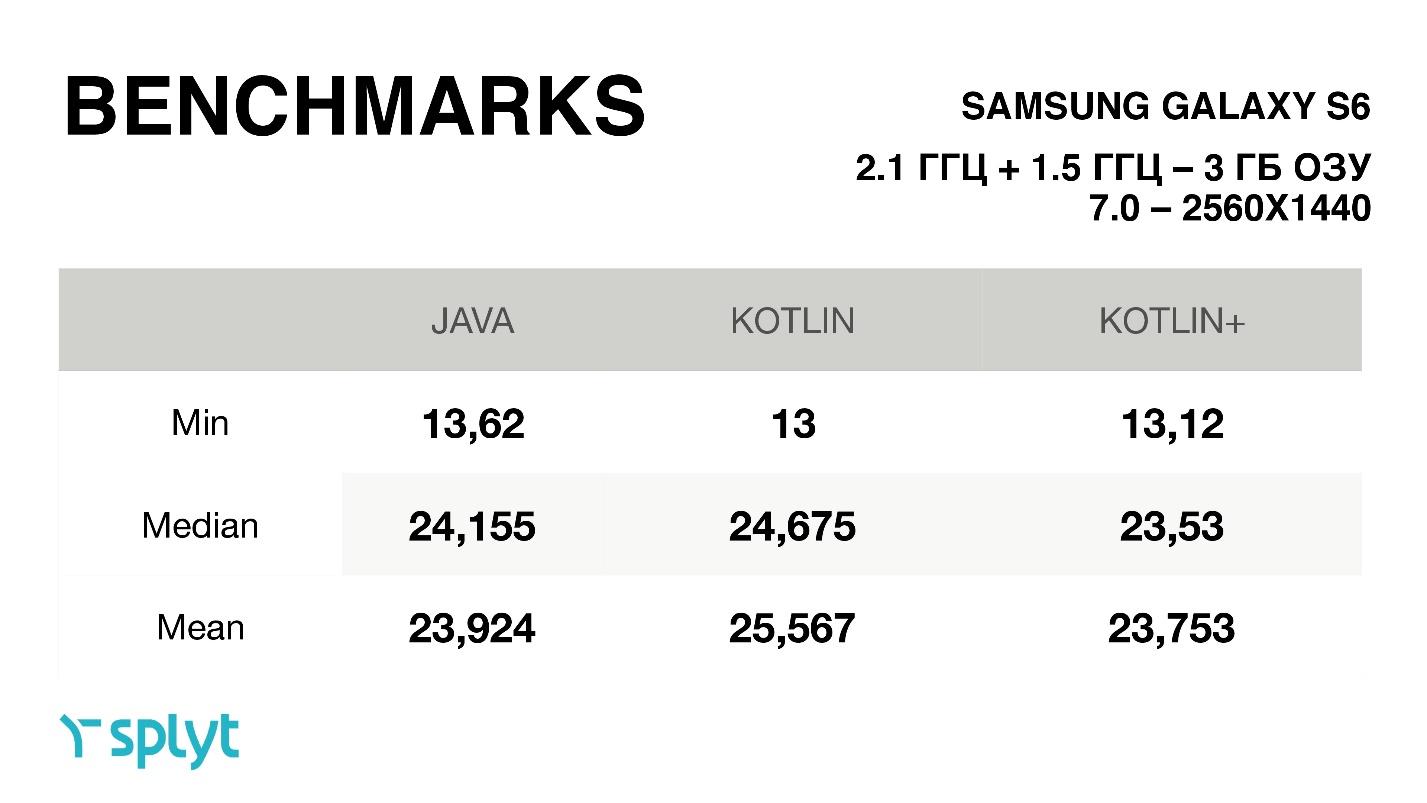
By the way, one more feature: for some reason, in these benchmarks, always for Kotlin the minimum time for drawing one frame was reduced, i.e. it got even better. On average, it was either a small increase, or exactly the same time. Surprisingly, some Chinese phone with a small resolution gets a lot of time to draw one frame — much less — almost 2 times less than that of the cool Galaxy S6, with a very large screen resolution.

This is a benchmark on Google Pixel. For him, the difference is very small, everything is within 0.1 millisecond.
FINDINGS
To summarize, I would like to say that
Everything that I did could have spent a lot of time on you. There are developers who believe that some modern tools, for example, Kotlin, are bad in terms of performance. But I managed to present evidence that Kotlin does not affect this in any way and can be used in production without any problems.
Do not waste time where you could not spend it.
This article is based on the report by Alexander Smirnov at AppsConf 2017 and will help you figure out whether you can write code on Kotlin, which will not be inferior to Java in speed.
About the speaker: Alexander Smirnov CTO in the company PapaJobs, has a video blog " Android in faces ", and is also one of the organizers of the Mosdroid community.
Let's start with your expectations.
Do you think Kotlin at runtime is slower than Java? Or faster? Or maybe there is not much difference? After all, both work on the bytecode that the virtual machine provides us.
Let's figure it out. Traditionally, when the question of performance comparison arises, everyone wants to see benchmarks and specific numbers. Unfortunately, there is no JMH ( Java Microbenchmark Harness ) for Android , so we cannot measure everything as coolly as Java. So what is left for us to do, as written below?
funmeasure() : Long {
val startTime = System.nanoTime()
work()
return System.nanoTime() - startTime
}
adb shell dumpsys gfxinfo %package_name%
If you ever try to measure your code this way, then one of the JMH developers will be sad, cry and come to you in a dream - never do that.
On Android, you can do benchmarks, in particular, Google demonstrated this even last year’s I / O. They said that they greatly improved the virtual machine, in this case ART, and if on Android 4.1 one allocation of the object took about 600-700 nanoseconds, then in the eighth version it will take about 60 nanoseconds. Those. they were able to measure it with such accuracy on a virtual machine. Why can not we do the same - we do not have such tools.
If we look at all the documentation, the only thing we can find is the recommendation above, how to measure UI:
adb shell dumpsys gfxinfo% package_name%
Actually, let's do that, and see at the end what it will give. But first we will determine what we will measure and what else we can do.
Next question. Where do you think performance is important when you create a first-class application?
- Definitely everywhere.
- Ui thread
- Custom view + animations.
I like the first option the most, but most likely the majority thinks that it’s impossible to make all the code work very, very quickly and it’s important that at least it doesn’t lag UiThread or custom view. With this, I also agree - this is very, very important. What you have in a separate stream of JSON will be deserialized for 10 milliseconds longer, then no one will notice.
Gestalt psychology says that when we blink, about 150-300 milliseconds, the human eye is at a loss of focus and does not see what is actually happening there. And then these 10 milliseconds of weather do not. But if we return to Gestalt psychology, what is important is not what I really see and what is really happening - what I understand as a user is important.
Those. if we make the user think that everything is very, very fast, and in fact it will just be beautifully beaten up, for example, with the help of beautiful animation, he will be satisfied, even if in fact it is not.
The motives of gestalt psychology in iOS have been moving for a long time. Therefore, if you take two applications with the same processing time, but on different platforms, and put them next to each other, it will seem that everything is faster on iOS. Animation in iOS processes a bit faster, earlier animation starts when loading and many other animations, so that it is beautiful.
So the first rule is to think about the user.
And for the second rule you need to plunge into hardcore.
KOTLIN STYLE
To honestly evaluate the performance of Kotlin, we will compare it with Java. Therefore, it turns out, it is impossible to measure some things that are only in Kotlin, for example:
- Sollection Api.
- Method default parameters.
- Data classes.
- Reified types.
- Coroutines.
The collection of the API , which Kotlin provides us with, is very cool, very fast. In Java, this is simply not there, there are only different implementations. For example, the Liteweight Stream API library will be slower because it does the same thing as Kotlin, but with one or two additional allocations per operation, since everything turns into an additional object.
If we take the Stream API from Java 8, then it will run slower than the Kotlin API API collection, but with one condition - there is no paralysis in the API API collection as in Java 8. If we enable parallel, on large amounts of data, the API API streaming Java will bypass the Kotlin Solitaire API. Therefore, we cannot compare such things, because we make comparisons from the point of view of Android.
The second thing that, I think, cannot be compared, is Method default parameters - A very cool feature, which, by the way, is in Dart. When you call a method, it may have some parameters that can take on some value, or they can be NULL. And therefore you do not do 10 different methods, but do one method and say that one of the parameters can be NULL, and later use it without any parameter. Those. it will look, the parameter has come, or it has not come. Very convenient in that you can write a lot less code, but the inconvenience is that you have to pay for it. This is syntactic sugar: you, as a developer, consider that this is one API method, but in reality, under a hood, every variation of a method with missing parameters is generated in the byte code. And in each of these methods a check is made bit by bit whether this parameter has arrived. If he came, then ok, if he did not come, then we make up the bit mask, and depending on this bit mask, the original method that you wrote is already being called. Bitwise operations, allif / else cost a little money, but very little, and it’s normal that you have to pay convenience. It seems to me that this is absolutely normal.
The next item that cannot be compared is Data classes .
Everyone laments that in Java there are parameters for which there are model classes. Those. you take the parameters and make more methods, getters and setters for all these parameters. It turns out that for a class with ten parameters you need a whole pair of getters, setters and a whole heap of everything. Moreover, if you do not use generators, then you have to write it with your hands, which is generally terrible.
Kotlin lets you get away from it all. First, since there are properties in Kotlin, you do not need to write getters and setters. It has no class parameters, all properties. In any case, we think so. Secondly, if you write that it is Data classes, a whole bunch of everything else will be generated. For example, equals (), toStrung () / hasCode (), etc.
Of course, this has its drawbacks. For example, I did not need to have all 20 parameters of my data classes compare at once in equals (), I only needed to compare 3. Someone doesn’t like all this because performance is lost on this, and besides, a lot is generated service functions, and the compiled code is quite voluminous. That is, if you write everything with your hands, the code will be less than if you use data classes.
I do not use data classes for another reason. Previously, there were restrictions on the expansion of such classes and something else. Now with all this better, but the habit has remained.
What is very, very cool in Kotlin, and what will it always be faster than Java? These are Reified types , which is also in Dart, by the way.
You know that when you use generics, then at the compilation stage, type erasure occurs (type erasure) and at runtime you don’t know what object of this generic is actually used.
With Reified types, you do not need to use reflection in many places, when in Java you would need it, because with inline methods with Reified, knowledge of the type remains, and therefore it turns out that you do not use reflection and your code runs faster. Magic.
And there are Coroutines. They are very cool, I like them very much, but at the time of the performance they were only in the alpha version, so there was no possibility to make correct comparisons with them.
FIELDS
Therefore, let's go further, let's move on to what we can compare to Java and what we can influence in general.
classTest{
var a = 5var b = 6val c = B()
funwork() {
val d = a + b
val e = c.a + c.b
}
}
classB(@JvmFieldvar a: Int = 5,var b: Int = 6)
As I said, we have no parameters for the class, we have properties.
We have a var, we have a val, we have an external class, one of the properties of which is @JvmField, and we’ll see what actually happens with the work () function: we summarize the value of the a field and the b field of our own class and the value of the field a and the field b of the outer class, which is written in the immutable field c.
The question is, what exactly will be caused in d = a + b. We all know that this is a property, then the getter of this class will be called for this parameter.
L0
LINENUMBER 10 L0
ALOAD 0
GETFIELD kotlin/Test.a : I
ALOAD 0
GETFIELD kotlin/Test.b : I
IADD
ISTORE 1But if we look at the byte-code, we will see that in reality there is a getfield conversion. That is, it is not a call to the InvokeVirtual function that occurs in the bytecode, but a direct call to the field. There is nothing that was promised to us initially, that we have all the properties, not the field. It turns out that Kotlin is deceiving us, there is a direct appeal.
What will happen if we still see which bytecode is generated for another string: val e = ca + cb?
L1
LINENUMBER 11 L1
ALOAD 0
GETFIELD kotlin/Test.c : Lkotlin/B;
GETFIELD kotlin/B.a : I
ALOAD 0
GETFIELD kotlin/Test.c : Lkotlin/B;
INVOKEVIRTUAL kotlin/B.getB ()I
IADD
ISTORE 2Previously, if you turned to the non-privileged property, then you always had a call to InvokeVirtual. If it was a private property, then it was accessed via GetField. GetField is much faster than InvokeVirtual, in the specification from Android it is stated that it is 3–7 times faster to access the field directly. Therefore, it is recommended to always refer to the Field, and not through getters or setters. Now, especially in the eighth ART virtual machine, there will already be other numbers, but if you still support 4.1, this will be true.
Therefore, it turns out, we still benefit from having GetField, not InvokeVirtual.
Now, you can get GetField if you are accessing a property of your own class, or, if it is a public property, then you need to put @JvmField. Then just in the bytecode there will be a call to GetField, which is 3–7 times faster.
It is clear that here we speak in nanoseconds and, on the one trona, this is very, very little. But, on the other hand, if you do it in the UI stream, for example, in the ondraw method you apply to some view, this will affect the rendering of each frame, and you can do it a little faster.
If you add up all the optimizations, then in sum it may give something.
STATIC !?
And what about the statics? We all know that in Kotlin static is a companion object. Previously, you probably added some kind of tag, for example, public static, final static, etc., if you convert it into code on Kotlin, then you will get a companion object, in which something like this will be written:
companionobject {
var k = 5funwork2() : Int = 42
}
Do you think this entry is identical to the standard static end of Java declaration? Is it generally static or not?
Yes, indeed, Kotlin declares that here it is in Kotlin - static, that object says that it is static. In reality, it is not static.
If we look at the generated byte-code, we will see the following:
L2
LINENUMBER 21 L2
GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion;
INVOKEVIRTUAL kotlin/Test$Companion.getK ()I
GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion;
INVOKEVIRTUAL kotlin/Test$Companion.work2 ()I
IADD
ISTORE 3Test.Companion is generated by the singleton object for which the instancé is created, this instancé is recorded in its own field. After that, access to any of the companion object occurs through this object. It takes getstatic, that is, a static instance of this class and calls the invokevirtual function getK, and exactly the same for the work2 function. Thus, we get that it is not static.
This is important, for the reason that the old JVM invokestatic was about 30% faster than invokevirtual. Now, of course, optimized virtualization is happening on HotSpot very cool, and it is almost imperceptible. However, you need to keep this in mind, especially since there is one extra allocation here, and an extra location on 4ST1 is 700 nanoseconds, also a lot.
Let's look at the Java-code, which turns out, if you reverse the byte-code back:
privatestaticint k = 5;
publicstaticfinal Test.Companion Companion =
new Test.Companion((DefaultConstructorMarker)null);
publicstaticfinalclassCompanion{
publicfinalintgetK(){ return Test.k;}
publicfinalvoidsetK(int var1){
Test.k = var1;
}
publicfinalintwork2(){ return42; }
privateCompanion(){ }
// $FF: synthetic methodpublicCompanion(DefaultConstructorMarker
$constructor_marker){ this(); }
}
A static field is created, a static final implementation of the Companion object, getters and setters are created, and, as you can see, by accessing the static field inside, an additional static method appears. Everything is quite sad.
What can we do by making sure that this is not static? We can try adding @JvmField and @JvmStatic and see what happens.
val i = k + work2()
companionobject {
@JvmFieldvar k = 5
JvmStatic
funwork2() : Int = 42
}
I’ll say right away that you can’t get away from @JvmStatic, in the same way it will be an object, since this is a companion object, there will be an extra allocation of this object and there will be an extra call.
privatestaticint k = 5;
publicstaticfinal Test.Companion Companion =
new Test.Companion((DefaultConstructorMarker)null);
publicstaticfinalclassCompanion{
@JvmStaticpublicfinalintwork2(){ return42; }
privateCompanion(){}
// $FF: synthetic methodpublicCompanion(DefaultConstructorMarker
$constructor_marker){ this(); }
}
But the call will change only for k, because it will be @JvmField, it will be taken directly as getstatic, getters and setters will not be generated anymore. And for the work2 function, nothing will change.
L2
LINENUMBER 21 L2
GETSTATIC kotlin/Test.k : I
GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion;
INVOKEVIRTUAL kotlin/Test$Companion.work2 ()I
IADD
ISTORE 3The second option, how to create static is suggested in the Kotlin documentation, so it’s said that we can simply create an object and this will be static code.
object A {
funtest() = 53
}
In reality, this is also not the case.
L3
LINENUMBER 23 L3
GETSTATIC kotlin/A.INSTANCE : Lkotlin/A;
INVOKEVIRTUAL kotlin/A.test ()I
POP
It turns out that we make a call to getstatic instance from singletone, which is being created, and we call the exact same virtual methods.
The only way we can achieve exactly invokestatic is Higher-Order Functions. When we simply write some function outside the class, for example, fun test2 will actually be called static.
funtest2() = 99
L4
LINENUMBER 24 L4
INVOKESTATIC kotlin/TestKt.test2 ()I
POP
Moreover, the most interesting thing is that a class will be created, an object, in this case, testKt, it will generate an object for itself, it will generate a function that it will put into this object, and then it will be invoked as invokestatic.
Why this was done is not clear. Many are unhappy with this, but there are those who consider this implementation quite normal. Since the virtual machine, incl. Art is improving, now it is not so critical. In the eighth version of Android, just like on HotSpot, everything is optimized, but still these little things slightly affect the overall performance.
NULLABILITY
funtest(first: String, second: String?) : String {
second ?: return first
return"$first$second"
}
This is the next interesting example. It would seem that we noted that the second can be nullable, and it must be checked before doing something with it. In this case, I expect that we have one if. When this code is deployed in if second is not equal to zero, then I think that the execution will go on and output only first.
How does this all really unfold in java code? Actually there will be a check.
@NotNullpublicfinal String test(@NotNull String first,@Nullable String second){
Intrinsics.checkParameterIsNotNull(first, "first");
return second != null ? (first + " " + second) : first;
}
We will get Intrinsics initially. Suppose that what I am saying is that this one here is
If will unfold into a ternary operator. But besides this, although we have even fixed that the first parameter cannot be nullable, it will still be checked through Intrinsics.
Intrinsics is an internal class in Kotlin that has some set of parameters and checks. And every time you make a method parameter not nullable, it still checks it. What for? Because we work in Interop Java, and it may happen that you expect that it will not be nullable here, but it will come from Java somewhere.
If you check it, it will go further along the code, and then after 10-20 method calls, you will do something with a parameter that, although it cannot be nullable, but for some reason it turned out to be. You will all fall, and you can not understand what actually happened. To avoid this situation, every time you pass the null parameter, you will still have to check it. And if it is nullable, it will be exception.
This test is also worth something, and if there are a lot of them, it will not be very good.
But in fact, if we talk about HotSpot, then 10 calls of these Intrinsics will take about four nanoseconds. This is very, very little, and you should not worry about this, but this is an interesting factor.
PRIMITIVES
In Java, there is such a thing as primitives. In Kotlin, as we all know, there are no primitives, we always operate with objects. In Java, they are used to provide better performance of objects on any minor calculations. Folding two objects is much more expensive than adding two primitives. Consider an example.
var a = 5var b = 6var bOption : Int? = 6There are three numbers, for the first two, not null type will be displayed, and about the third we ourselves say that it can be nullable.
privateint a = 5;
privateint b = 6;
@Nullableprivate Integer bOption = Integer.valueOf(6);
If you look at the bytecode and see which Java code is generated, then the first two numbers are not null, and therefore they can be primitives. But the primitive cannot contain a Null, only an object can do this, so an object will be generated for the third number.
AUTOBOXING
When you work with primitives, and perform an operation with a primitive and non-primitive, then either you need to translate one of them into a primitive, or into an object.
And, it would seem, it is no wonder that if you do operations with nullable and not nullable in Kotlin, then you lose a little bit in performance. Moreover, if there are many such operations, then you lose a lot.
val a: String? = nullvar b = a?.isBlank() == trueSee where Boxing / Unboxing will be here? I also did not see until I looked at the byte code.
if (a != null && a.isBlank()) trueelsefalseActually, I expected that there would be something like this comparison: if the string is not null and if it is empty, then set to true, otherwise, set to false. It seems simple, but in reality the following code is generated:
String a = (String)null;
boolean b = Intrinsics.areEqual(a != null ?
Boolean.valueOf(StringsKt.isBlank((CharSequence)a)) : null,
Boolean.valueOf(true));
Let's look inside. The variable a is taken , it is cast in CharSequence, after it has been cast, which has also been spent some time, another check is called - StringsKt.isBlank - this is how the extension function for CharSequence is written, so it is cast and sent. Since the first expression can be nullable, it takes it and makes Boxing, and wraps it all in Boolean.valueOf. Therefore, the primitive true also becomes an object, and only after that a check occurs and Intrinsics.areEqual is called.
It would seem such a simple operation, but such an unexpected result. In fact, such things are very few. But when you can have nullable / not nullable, you can generate a lot of this, and that you would never expect. Therefore, I recommend you to avoid confusions as early as possible. Those. as soon as possible to come to the immunity of values and move away from nullable , so that you can operate as quickly as possible, not null.
Loops
The next interesting thing.
You can use the usual for, which is in Java, but you can also use the new user-friendly API - just write through the list in the list. For example, you can call the work function in a loop, where it will be some element of this list.
list.forEach {
work(it * 2)
}
An iterator will be generated and there will be a trivial iteration over the iterator. This is normal, it is much recommended. But if we see what advice Google gives us, then we find out, in terms of performance, specifically for ArrayList, iteration through for works 3 times faster than through an iterator. In all other cases, the iterator will work identically.
Therefore, if you are sure that you have an ArrayList, it is logical to do another thing - to write your foreach.
inlinefun<reified T> List<T>.foreach(crossinline action: (T)
-> Unit): Unit {
val size = size
var i = 0while (i < size) {
action(get(i))
i++
}
}
list.foreach { }
This will also be an API, but which will generate a slightly different code. Here we use all the power that Kotlin gives us: we will make an extension function that will be “inline”, which will be of type reified, i.e. we will not erase anything, and we will also do so that we will give the lambda, for which we will perform the crossinline. Therefore, everything will become very good everywhere, even perfect, the bill works very quickly. 3 times faster, as recommended by Google’s Android specification.
Rangs
We could do the same with Ranges.
inlinefun<reified T> List<T>.foreach(crossinline action: (T)
-> Unit): Unit {
val size = size
for(i in0..size) {
work(i * 2)
}
}
The previous example and this with: Unit will be identically worked out in bytecode. But if you try to do here either −1, or until add, or another step, then there will be back iterators. And besides this, there will be an allocation for the object that will generate ranges. Those. you allocate the object to which the starting point is written. Each subsequent iteration will call this method with the next step value. It's worth remembering.
INTRINSICS
Let us return to Intrinsics, and consider another interesting example:
classTest{
funconcat(first: String, second: String) = "$first$second"
}
In this case Intrinsics is called twice - for both second and first.
publicfinalclassTest{
@NotNullpublicfinal String concat(@NotNull String first, @NotNull String second){
Intrinsics.checkParameterIsNotNull(first, "first");
Intrinsics.checkParameterIsNotNull(second, "second");
return first + " " + second;
}
}
They can be turned off, but they can not be turned off in the gradle. If you highlight what is very, very important up to these 4 nanoseconds, then you can turn them off there. You can make a Kotlin module with a UI, where you are sure that nothing can get there nullable, and pass directly to Kotlin to the compiler:
kotlinc -Xno-call-assertions -Xno-param-assertions Test.kt
This will cut down Intrinsics, as checking input parameters and result.
In fact, I have never seen the second part be particularly useful. But the parameter - Xno-param-assertions - cuts down these two Intrinsics, and everything works very well.
If this is done everywhere, it will not work very well, because it leads to what I have already said that the program may fall where you don’t expect. And in those places where you are really sure that an additional check is not needed, you can do so.
REDEX
Many believe that the getters and setters, as written in the documentation, inline in Proguard. But I would say that in 99% of cases a method that consists of a single function will not be inline. In Android 8.0, this was optimized, and there it is already invaded. It only remains to wait, when we will all be on it.
Another option is to use other than Proguard, a Facebook tool called Redex . It also uses bytecode optimizations, but in the same way it does not inline everything, and so does not inline getters and setters. It turns out that Jvm Fields is currently the only way to get away from the getter and setter for simple properties.
In addition, other optimizations are included in Redex. In particular, I created a primitive application where I did not write any code at all, I added Proguard for it, which cut out everything that was possible. After that, I turned this application through Redex and received a minus 7% by weight of the APK. I think this is good enough.
BENCHMARKS
We turn to the benchmarks. I took an interesting enough application that has a lot of frames and a lot of animations to make it convenient to measure. This application was written by Jaroslav Mytkalyk , and I measured the benchmarks on four different phones. Actually, I did dumpsys gfxinfo and collected data thousands of times, which I then reduced to the final value. In my github profilegithub.com/smred you can find the source and results.
So, on a rather weak Huawei device.
The purple column shows the minimum version of one frame. Green - maximum, always jumping on different calculations. The blue bar represents the median value, which was fairly stable; the error was about 0.04 milliseconds. But, unfortunately, according to the schedule, the benchmark result is quite difficult to understand - everything is very close, so let's look at the time of drawing one frame in milliseconds.
When we just switched to Kotlin, we got a little more time per frame. After all the optimizations have been made, the differences are almost within the margin of error. But for some reason it turned out that the median in optimized Kotlin is even greater than that of Java. But if you look at the average, then, of course, the results were always slightly better than in the just autogenerated Kotlin code. On four devices, a similar circuit was obtained.
It turns out that the optimization I was talking about really helped and led to the fact that Kotlin offhand almost always works the same way as Java code. Yes, because of some features and differences, for example, in abstractions, there is a little extra workload, but if you want, you can always achieve almost identical speed of work.
By the way, one more feature: for some reason, in these benchmarks, always for Kotlin the minimum time for drawing one frame was reduced, i.e. it got even better. On average, it was either a small increase, or exactly the same time. Surprisingly, some Chinese phone with a small resolution gets a lot of time to draw one frame — much less — almost 2 times less than that of the cool Galaxy S6, with a very large screen resolution.
This is a benchmark on Google Pixel. For him, the difference is very small, everything is within 0.1 millisecond.
FINDINGS
To summarize, I would like to say that
- Speed is only important on the UI stream or custom view.
- Very critical onmeasure-onlayout-ondraw. Try to avoid there all autoboxing, non null parameters, etc.
- Almost always you can write code on Kotlin, which will work with identical Java speed, and in some places it may even turn out faster.
- Premature optimization is evil.
Everything that I did could have spent a lot of time on you. There are developers who believe that some modern tools, for example, Kotlin, are bad in terms of performance. But I managed to present evidence that Kotlin does not affect this in any way and can be used in production without any problems.
Do not waste time where you could not spend it.
Alexander Smirnov is on the program committee of our brand new AppsConf , including thanks to his work, the Android section will be so strong. Although, the whole program will be cool. Book your tickets and see you on October 8 and 9 at a large-scale conference on mobile topics.