Don Jones. “Creating a unified IT monitoring system in your environment” Chapter 3. Connecting everything into a single IT management cycle
- Transfer
 We continue the translation. In this chapter, we will talk about organizing a service desk and how to build interactions with users, as well as getting feedback from them. We will see why 'good' from the point of view of IT does not always mean 'good' from the point of view of the user and how these two ratings can be balanced.
We continue the translation. In this chapter, we will talk about organizing a service desk and how to build interactions with users, as well as getting feedback from them. We will see why 'good' from the point of view of IT does not always mean 'good' from the point of view of the user and how these two ratings can be balanced. Contents
Chapter 1. Managing your IT environment: four things that you do wrong
Chapter 2. Eliminating management practices for individual sites in IT management
Chapter 3. Connecting everything into a single IT management cycle
Chapter 4. Monitoring: looking beyond the data center
Chapter 5 : Turning Problems into Solutions
Chapter 6: Unified Management with Examples
Chapter 3. Connecting everything into a single IT management cycle
For a long time, the practice of discrete processes disconnected from real life has been present in IT, often making key participants interested in what is happening inside IT. Combining everyone - users, managers, IT specialists and other employees in a single cycle can provide significant benefits, as well as reduce the tendency to return to IT management in individual areas. This is where the true integration between the service desk and the monitoring system takes place, and these two concepts form the basis for the most central and important topics discussed in this book. All this relates to communications - ways to achieve better interaction, as well as creating opportunities for continuous improvement. Users sometimes perceive their IT department as impregnable, highbrow and weird types with poor communication skills.prejudice , fair or not, often exists. And all because the IT service may too often be the last to learn about events that users perceive as a problem. The server can work within the set values, but the application for entering orders is very slow. IT says that mail works great, but I’ve been waiting for an incoming message with a purchase order for an hour, so there’s no chance the mail system is working properly!
IT sometimes has to deal with its own unique difficulties, which involve falling out of the management process - for example, finding windows in a schedule where approved changes must be made to the infrastructure can be an extremely non-trivial task. It can be difficult to simply coordinate changes — proposed, approved, under development, ready for deployment, and so on. Many organizations have adopted procedures for managing change, similar to the method described in ITIL, highlighting a specific process for revising and approving changes. However physical coordinationworks, from the side looks more like an attempt to graze a cat flock. This is even worse than the situation in which IT was managed in separate technological areas: the DBMS team needs to make changes scheduled for midnight, but this change will conflict with the work on power systems carried out by the data center infrastructure team. So all our statements remain valid - we need to keep everyone on the same page.
We start the cycle: we connect monitoring and service desk
Today, most organizations have ticket-based systems for coordinating IT work. Also in these organizations usually have monitoring systems that allow you to monitor IT systems and respond to any problems. However, in very few companies, these two systems work together. Ideally, this would be what you need: a single integrated IT management system that is able to detect problems and then open tickets assigned to specific employees. If the mail server crashes, then the corresponding administrator must receive a ticket to work. Of course, these tickets must have notification methods, such as text messages, mail, or any other method, so that the recipient knowsthat the alarm is announced. The automatic appointment of tickets, which is sometimes called automatic routing, should have a fair share of artificial intelligence.
Different systems installed in different places, at different times - all of them can affect the way a ticket is created, as well as change the circle of people involved in working on a problem.
Tickets should be as complete as possible, in the sense that the values for the filled fields of the “alarm ticket” should be collected automatically as much as possible. When filling out the details, you should not rely heavily on the help desk or anyone else.
The detailed information may contain information regarding the servers affected by the problem. Fig. 3.1. it is shown how, approximately, an automatically created ticket might look like, with the main fields pre-filled by the system.

Figure 3.1: Tickets automatically created by the system in response to received alarms.
The idea is to have a solution for organizing a service desk - software that helps coordinate and manage IT activities (often through tickets), working in conjunction with a monitoring system, which thus creates a truly integrated solution to work with problems arising in IT.
It is assumed that all of this will benefit. The first and most important thing is faster resolution of incidents. Without waiting for your users to report a problem, you proceed to quickly solve it, and if you have pre-filled tickets, IT specialists will work faster because they have more information on hand.
You can go deeper into this process even more if you have the right software for organizing the service desk. Frameworks such as ITIL strongly encourage root cause analysis, which means that your team should not only deal with immediate difficulties, but also make the overall environment more stable and resistant to difficulties. To achieve this, a service desk solution must define two types of situations: a global problem and a specific incident.
A specific incident can be a common embarrassment such as: “E-mail is slow,” “Order entry is slow,” and so on. Both incidents can be related to the global “Unclear Network Slowdowns” problem that needs to be checked and fixed - perhaps it’s because of an overloaded router that drops packets more often than usual.
Sometimes, specific incidents cannot be completely resolved until the global problem that overlaps them is resolved. By tracking individual incidents along with a global issue, you can help your users and their leaders be more informed. For example, after an overheated router has been detected and replaced, the message “Most likely we found the reason for the slow operation, so now there should be no problems” could be sent to each employee who was affected by this specific problem. In Fig. 3.2. It is shown how a single global problem can be attached to many incidents.

Figure 3.2: Relationship between several incidents and one problem.
I used a couple of keywords in the current discussion and would like to outline them in the context of this book:
- An incident is something that happens in an environment, for example, a failed server or a slow-running application.
- To deal with the incident, IT staff creates a record of the problem . Problems, in fact, may be associated with many incidents, such as, for example, in the case of an overheated router, which caused repeated, at first glance, unrelated failures that manifested themselves in the whole environment.
From this place I am going to use these two terms in that sense. I hope that some of the benefits of combining monitoring and problem solving will become clear. For example, simpler solutions used to organize a help desk allow you to open many tickets for an event, which is actually the same problem. This can lead to a significant duplication of efforts when many specialists try, each - on their own, to solve the same problem. It can also lead to a lot of bureaucratic work, because trying to find the root cause requires a lot of time to process and close each ticket. If a more advanced system is used, all incoming events can be consolidated into a single, controlled process. Moreover,
However, problems and incidents are not the only reason why users interact with the IT service, moreover, I hope that this is not the main reason why users contact the IT service! In addition to reporting incidents, users also request routine services: ask for advice, make requests for hardware updates, changes, requests for access, etc. All these requests should be processed through a formalized set of procedures (workflow), at the entrance to which users place their request, and after approval, he gets to the appropriate technical specialist, and inside the process itself there is an opportunity to monitor the status of requests.
For instance:
- The user visits the website to select a single request from the “catalog” that he can create - access to systems, replacement of equipment, etc.
- The user selects an item from the catalog and makes additional clarifying information to complete the request.
- A ticket containing a user request is created in the service desk. Depending on the request, the ticket can be sent to the user’s manager for approval.
- After approval, the ticket can be automatically transferred to the work of the appropriate IT technical specialist.
- As you work, the user can receive information about the status of the request, for example via e-mail. The information includes a status message “completed” after the ticket is closed.
- When using the same system for processing tickets, both for solving problems and for processing routine requests, IT specialists can use a single interface to manage their workload. Fig. 3.3 shows what a request for processing a ticket related to a routine request might look like.

Figure 3.3: Routine requests can also be issued in the form of tickets.
It is much better when IT management can rely on full documentation and monitoring of its own work in a single system - this allows management to be aware of the problems and have all the necessary set of reports, dashboards and other mechanisms. In Fig. 3.4. An example of how such a report might look is shown:

Figure 3.4: Management reports become more effective when they include all IT service work.
The main idea is to keep everyone in a single cycle: users, IT, management — so that everyone is informed about the state of affairs. The main burden of notification falls on the software, which has the ability to send updated information about the state of affairs via e-mail or other means, so everyone is aware of the current situation.
Alteration. How to find the right window
Large IT departments, with many specializations, have their own specific problems. In the previous chapter, I talked about management problems in individual technology sectors, where narrow experts spent a lot of time transferring the problem to each other, but because everyone used his own tool exclusively and thought that the problem was not with him, search and eliminating the causes dragged on. Without a doubt, we are not going to get rid of narrow specialists, and our solution is to use tools that will bring information from different sources into a single console, which makes it possible to combine common efforts.
Another problem created by management practices for individual technology areas is related to change management. At the beginning of this chapter, I outlined one of these problems: database specialists are ready to make their changes to the system, but they conflict with the changes that another group is going to make. Managing schedule windows to make changes becomes extremely difficult. Applications and services not only require round-the-clock work, which leads to very small windows for making changes, but also leads to competition for these windows by different groups of specialists.
“Chef, we need to install this fix pack long ago, but this can only be done at night. It will take us 4 hours, and we fit in the window. But all last week, other groups used the same window and their work, did not allow us to engage in our work at the same time. ” The situation is not so rare; it becomes difficult for management to track what changes need to be made to the configuration, and when to allocate for them an already limited time among the windows for maintenance.
Lack of visibility of windows, competition for them, often leads to the inability to make the right management decisions. For example, if management sees a certain number of pending changes, and seescompetition, then it may decide to expand the service window for a period sufficient to implement these tasks. Or he may decide not to. At the very least, this will be a conscious decision , but not ignoring serious problems.
The way out of the situation is the use of software that makes it convenient to coordinate various departments. Think about it: if you use a solution for organizing a service desk to track tickets, then tickets can also be created for proposed changes. These tickets can be assigned to a technical specialist, sent for approval or review, and so on, and that’s all through your workflow.
By the way, this is a very good way to implement ITIL processes. Tickets can then be entered into a unified calendar built right into the service desk, and planners can create an acceptable work schedule. They can see consistent service windows, manage competition between conflicting changes, and so on. By receiving this information in a familiar calendar form, they can also decide whether to expand the service windows or not, if necessary and will benefit the organization. Figure 3.5 shows the change management calendar:

Figure 3.5: Change management schedule in a calendar view.
This is just another way to help keep everyone in a single cycle of interaction. Management now has a clear visual representation of changes and competition for the schedule. Such a calendar can even be made available to users so that they can plan their work correctly and consciously.
Communications: how to engage users in a single cycle
The idea of supporting user information is, of course, not new, but many companies that have tried to engage their users in the process have failed. Too often, “engaging users in a single cycle” takes the form of self-service web portals where registered users can see the status of their tickets or check the status of a particular service. This is all good and great, but portals of this type do not always coincide with the user's natural train of thought. For example, most users, if they encounter any problems, will not at all necessarily think that they should go and check the information on the website - they simply call the help desk.
But users spend a lot of time checking mail in their inbox. Why not make it your communications channel? Organizations try not to use this method of communication, in part because it can easily become a great time eater for your IT service. “I am fully engaged in solving the problem, and at the same time should I send hourly updates about the state of affairs?” There’s a direct cartoon about Dilbert.
In fact, a good service desk solution can do this for you. Distribution of updates via e-mails, if, for example, a user ticket has changed - this is a simple operation for the software. Such messages can be informative and relieve users of most concerns about the status of their requests. Figure 3.6. shown how it might look.
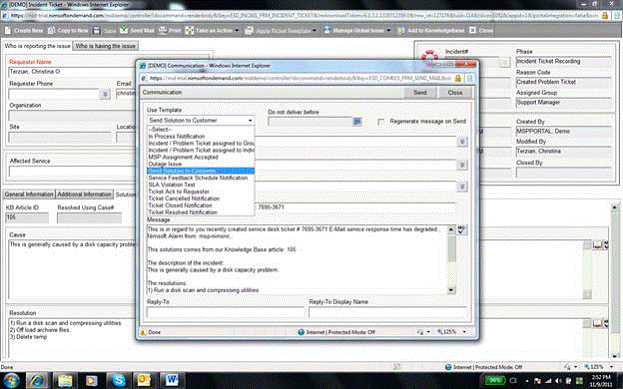
Figure 3.6. Informing users through detailed e-mails.
A service solution is even more in demand, which in reality can receive requests by e-mail instead of waiting for users to go to the website and open a ticket. Take it as it is - your users are much more willing to pick up the phone than they will visit the website and issue a ticket, well, of course, if you do not arrange significant artificial barriers along the way - such as complex voice menus in the telephone system. More willing userswill send an email. If your service desk, instead of a technical specialist, will be able to receive these messages and use them to create tickets, you really have created a system that users will meet with open arms. Such tickets can be automatically assigned and routed, helping the technician to get started resolving the problem faster. Messages sent via e-mail can be valuable even for routine, problem-free processes. When their request is approved, rejected, executed, completed, etc., an e-mail message helps users to be informed without any additional human effort.
Note
I would like to emphasize that self-service portals are a good thing . They can improve the user's personal experience, push the user in the right direction if he is trying to solve his problem using the self-service system and much more, but they should not be the only ways to communicate with people.
Service Level Agreements: Agreements and Realistic Expectations
If you, of course, have not lived in the middle of the past ten years, then the phrase 'service level agreement (SLA)' should be familiar to you. In its simplest form, it is a commitment made by an IT service and provides a specific level of availability, performance and availability for a particular service. “The postal service will be available 99.999% of the working time per year” is an example of a simple SLA.
SLAs become complex very quickly and you won’t be able to understand just a single number from them. What level of service can you reasonably provide? What is your historically established level of service? And what fits the needs of the business? How do you track the level of SLAs that were once put into circulation, and how do you make sure that they fit the business? And do you, ideally, have a notice of impending danger of non-compliance with the terms of the agreement?
SLAs may not be the only type of agreement to be accepted and monitored. Some also use underpinning contracts ( UCs ) or operational level agreements- OLA) for various internal and external services often supported in SLAs.
A well-designed service desk and monitoring solutions will help you more accurately comply with these agreements. You can start by defining a top-level SLA, then, based on them, determine the UC and OLA as you require. (It is necessary to make an amendment to the local legislation and the established business practice of fulfilling obligations by third-party companies. If, for example, all of your local communication providers have a recovery interval of 72 hours, then it is unreasonable to subscribe to your own SLA, which indicates responsibility for a shorter period, and there must also be good reason and management approval for finding a provider with shorter recovery periods. Very often, any decrease in such seemingly long intervals leads to a disproportionate increase in the cost of the service, and subsequently in practice it turns out to be not so necessary - etc. )
Once having registered the parameters of the agreement, the software solution should monitor the current performance and availability, signal it, perhaps in the form of a simple indicator, shown in Figure 3.7 and showing your compliance with the current SLA. You may also have access to more comprehensive and detailed reports on SLA metrics.

Figure 3.7: SLA Management. Indicators of the current status of the SLA.
However, more importantly, the software solution you are using should be able to determine the rules of your SLAs according to which tickets can be created if there is a danger of violation of the conditions, and in the future, as we said earlier, they should be sent to specific specialists. The solution should support escalation rules: if SLA values for which the execution rules begin to be not followed, approach the threshold and do not return within a certain point in time, then the application should try to automatically enter the reserve, call on additional technical specialists, notify the management and so on Further.
It must be admitted that there are no perfect SLAs. Sometimes, for any reason, a business may decide that the claimed service should be kept disabled. Sometimes it can be, for example, a software update or maintenance work. In these cases, you do NOT violate the SLA; you agree - with the part of the business that affects it - to temporarily suspend the SLA until the work is completed. A software solution for organizing a service desk should support these types of exceptions, including SLAs, valid only at certain time periods; correctly handle exceptions in the form of weekends and holidays, agreed service windows, changes in the size of service windows, etc.
The idea is to automate and manage SLA definitions, and also to automate notifications that are associated with the agreement. If the SLA is violated, you can accept that affected business users receive automatic notifications. This will allow them to be aware that IT knows about their problems and works on them - without forcing users to visit the self-service portal and open tickets there. This kind of proactive answer to the problem will help to go a long way towards improving the relationship between IT and users, and will enable IT to receive the correct assessment from the point of view of the business, as well as meet its requirements and support them.
Tell me what you really think
IT managers love it when IT thinks of users as "customers." In some cases, your users can really be “customers”, in the sense that they really “transfer money to you for the services that you provide them”. In other cases, your users are internal, but still “customers” in the sense that they consume your services, which you, the IT department, provide, and for which, in fact, you are paid a salary.
A very big problem is that IT is always struggling with its perception among its customers. Do users really think you are doing a good job? And what is a good job?
The monitoring of user assessment metrics (EUE - End-User Experience), which we discussed in the first chapter, is becoming a hot trend in the IT industry. You can see that the performance of your server is within normal limits, but after everything goes through old client computers, routers, cable system and everything else, where service delivery to users is involved, they can perceive server performance in a completely different way. Measuring user ratings is an opportunity to look at the big picture of what your users or customers have to deal with if you like.
Different types of business use another important way of disclosing user opinions: a survey. Call your bank, and the robot answering the phone can tell you that you are selected to participate in a short survey of service satisfaction, which will begin immediately after you end the conversation with your manager. If you came to an amusement park, then a smiling employee with a tablet will probably ask you a few questions. Look at the check from your last purchase, you will surely find there that you have the opportunity to win a gift card or other prize if you fill out an online evaluation survey about your impressions when visiting the store.
Evaluation reviews are an effective way of collecting information about what users really think, and a good solution for organizing a service desk should enable you to evaluate your work by your customers. You may want them to share their opinions on the completion of each request. Or maybe you want to be less annoying and ask users only on the third or fourth request. Whatever decision you make, the software for the service desk should be able to automate this process. You may even wish to engage users in a special survey regarding their opinions on daily tasks, service levels, and so on.
Of course, such surveys are useless without the ability to collect data and see what and how you are doing. The final part of the review should be presented in the form of reports, possibly with tables and graphs that help you visualize the perception of your service.
Compare this report with your SLA's Compliance Report - See the difference?
If your SLAs show that you are doing your job perfectly, and user assessment reviews are far from brilliant, then your SLAs may not be at the right level — or your SLAs are not the only metrics to consider.
I worked with a certain number of clients who had this situation: “Our SLAs are being implemented, but our users still do not believe that we are doing our job well. What can be wrong?". We found the answer through several specialized surveys regarding “small” difficulties, such as the “position” of the IT team while helping users. It turned out that the employees who worked with clients behaved unceremoniously, and sometimes rudely. We spent some time side by side with the team, and found that they were under incredible pressure due to the large number of tickets served. As a result, the company managed to develop internal metrics that made it possible to track the workload of each of the specialists and worked to reduce the load to an acceptable and manageable level,
The moral of this story is that SLAs are not the only metrics to keep in mind, and integrated questionnaires can help uncover critical information that is important for understanding the overall performance of services.
When Everyone Doesn't Need to See Everything: A Multi-Ownership Approach
The multitenant approach is a growing trend among IT solutions offered by different software manufacturers and there are good reasons for this. If you are a service provider, or, more precisely, a provider of a managed service - MSP (Managed Service Provider), then you should be aware of the availability of tools that can be configured and allocated for each of your users. Client A needs such indicator panels, while client B needs others . Client B absolutely does not need to see tickets from client A (and client A absolutely does not want client B to see them!). In the recent past, the presence of such multi-tenant properties was only characteristic of solutions developed exclusively for MSP.
Today, however, things are changing. Large companies with many departments want to deploy software that can serve the needs of all departments without the need for unique solutions for each service. In this case, multi-tenant solutions can help: they allow you to take a single solution, tailor it to specific needs, divide it into parts and provide it to each unit in the same way as if it were the only solution for one unit, although in fact this solution serves all.
Different units may have different views for viewing theirparts of the environment. For example, Unit A can see indicators, while Unit B sees something completely different. Nevertheless, the multi-ownership approach is far from what an arbitrary individual company needs. However, this is a good enough property that can be held in the back pocket and floated when it really becomes necessary. Therefore, this functionality should be taken into account if you have to make an assessment when choosing from several solutions - even if multi-tenant features are not an immediate necessity. Of course, if you are MSP, then this property of the product must be present in your decisions.
This directly relates to the topic of this chapter about involving everyone in a single control cycle: the ability to provide specific, customized environments to different groups of users - both external and internal, helps the latter to have more accurate information about the state of affairs.
Call it a private cloud: cost sharing
There is one more thing that you should pay attention to when involving all employees in the work - these are the costs associated with them and the ability to provide your customers with detailed reports on the use of infrastructure, and, if necessary, issue real accounts based on these figures.
In fig. 3.8. an example of such a report is given:

Figure 3.8: Report for billing to measure user activity.
And again, although this type of report is an obvious and mandatory function for MSP, the demand for reports of this kind is increasingly growing among organizations working only with internal users. One of the key elements of cloud computing is the concept of billing for the actual use of resources. The cloud provider builds and manages the infrastructure, which in a certain way is divided among customers. Each client pays for the parts and functions that he used. This is an obvious and well-understood cloud computing model, which is also a model for privatethe clouds. Instead of presenting IT in the form of a giant basket of costs, companies are increasingly looking for ways to share IT costs between consumers of IT services. “Is marketing going to deploy a dozen virtual web servers for a new website?” Great, but do they have a budget for this? ”
The chargeback, as it is called, is nothing new. But solutions for monitoring and for organizing service desks can increasingly provide such a level of detail that will allow you to carry out accounting and reallyinvoice. Technological advances that made public cloud creation possible can be quickly integrated into private data centers and work there in the same capacity: billing (or cost allocation) for current use.
Binding IT costs directly to consumers of IT services is an excellent approach to helping IT make better business decisions. Instead of entrusting IT with the role of Cerberus, who decides who can and who cannot have access to certain IT services, managementthe organization must decide who, how much money and what services can spend. It should be so. On the other hand, IT has always been outsourced, non-business activity, if you look at it from a business point of view. Although the work of the IT department is paid by the organization, it is not directly involved in creating profit - it is a separate unit. So, when a business sees IT as an “outsourcing” team (although in fact it is internal), then why not keep records and invoice by users, just like any IT service seller does?
This is also another way to link everyone together into a single procedural cycle. Even if you do not use internal billing or accounts for their intended purpose, they can be useful for senior management to understand the sources of costs and the value of IT investments. An IT manager can tell the CEO: “Well, you spent $ 25 billion on IT in the last quarter, but it’s here when and how these investments were used by the organization. If you want to save money, start with users and find ways to consume our services less ”
Conclusion
This chapter talked about keeping employees in a single IT management cycle. Starting from users who are informed about IT processes, to better connect IT professionals with current events and provide information for management to help make more correct and informed decisions - it was all about communication . I have said very little in this chapter that any organization will not be able to do this right now, even if they put enough effort into it. The key point is to use specialized software, which has features that allow it to be implemented with a minimum of costs, which makes it possible to achieve your goals.
In the next chapter ...
In the next chapter, we are going to consider the challenges that are encountered in the life of IT more and more often: key services and IT elements exist outside of their data centers. Yes, they can be called a “cloud” or simply “outsourced services”. But don’t call them, they are still critical for business and you need to treat them exactly as if they were your local services. They cannot be taken as a separate technological area, because in the end you will manage them separately from the overall system. Naturally, monitoring outsourced services is a game according to different rules, unlike local services, so we will have to look for some non-trivial solutions.
Go to Chapter 2