Using Dependent items in Zabbix 4.0 using the example of HPE MSA 2040/2050
Introduction
Everyone who uses the Zabbix monitoring system and monitors its development knows that with the release of Zabbix 3.4 we have a great feature - Dependent Items (dependent data elements), which already had a corresponding post on the Zabbix blog. However, in the form in which it was introduced in 3.4, using it “to the fullest” was problematic in view of the fact that LLD macros were not supported for use in preprocessing rules ( ZBXNEXT-4109 ), and also as a “parent” data item, you could only select the one created by the LLD rule itself ( ZBXNEXT-4200). In short, I had to do everything exactly as described in the link above - to work with my hands, which, with a large number of metrics, was a lot of inconvenience. However, with the release of Zabbix 4.0alpha9, everything has changed.
A bit of history
For me, the described functionality was important due to the fact that our company uses several HP storage systems, namely HP MSA 2040/2050, which metrics are retrieved by querying their XML API using a Python script .
At the very beginning, when the task of monitoring the designated equipment arose and an option was found using the API, it turned out that in the simplest case, to find out, say, the health of one storage component, two requests were required:
- Request authentication token (session key);
- The request itself that returns information on the component.
Now imagine that the storage consists of 24 disks (and maybe more), two power supply units, a pair of controllers, fans, several disk pools, etc. - we multiply all this by 2 and we get more than 50 data elements, which equals so many requests to API at every minute checks. If you try to follow this path, the API quickly “falls”, and in fact we are talking only about requesting the “health” of components, not taking into account other possible and interesting metrics - temperature, hours of working hours for hard drives, fan speed, etc.
The first solution I made to unload the API, even before the release of Zabbix version 3.4, was to create a cache for the resulting token, the value of which was recorded in the file and stored for N-minutes. This made it possible to reduce the number of calls to the API exactly twice, however, the situation did not change much - it was problematic to get something besides the state of health. Around this time, I visited Zabbix Moscow Meetup 2017, hosted by Badoo, where I learned about the above-mentioned functionality of dependent data elements.
The script was refined to the possibility of giving detailed JSON objects containing information of interest to us on various components of the repository and its output began to look something like this instead of single string or numeric values:
{"1.1":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27267"},"1.2":{"health":"OK","health-num":"0","error":"0","temperature":"23","power-on-hours":"27266"},"1.3":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27336"}, ... }This is an example of data being sent across all storage disks. For the rest of the components, the picture is similar - the key is the ID of the component, and the value is the JSON object containing the desired metrics.
Everything was fine, but the nuances described at the beginning of the article quickly surfaced - all dependent metrics had to be created and updated manually, which was quite painful (about 300 metrics per storage system plus triggers and graphs). We could have been saved by the LLD, but here, when creating the prototype, it did not allow us to specify as the parent item that which was not created by the rule itself, but a dirty hack with the creation of a fictitious item through the LLD and replacing its itemid in the database with the necessary one, dropped Zabbix server. The mentioned features quickly appeared in the Zabbix bugtracker, which indicated that this functionality was important not only for me.
Since all the preparatory operations on my part were completed, I decided to suffer and not produce temporary solutions, such as dynamic template generation, and waited only for the closure of the ZBXNEXTs mentioned at the beginning of the article, and just recently it was done.
How it looks now
To demonstrate the new features of Zabbix, we will take:
- Storage HPE MSA 2040 available over HTTP / HTTPS;
- Zabbix 4.0alpha9 server installed from the official repository on CentOS 7.5.1804;
- A script written in Python of the third version that allows us to discover the storage components (LLD) and return the data in JSON format for parsing on the Zabbix server side using the JSON Path.
The parent data element will be an “external check” (external check), calling the script with the necessary arguments and storing the received data as text.
Training
The Python script is installed in accordance with the documentation and has the “requests” library in the Python dependencies. If you have a RHEL-based distribution, you can install it using the yum package manager:
[root@zabbix]# yum install python3-requestsOr using pip:
[root@zabbix]# pip install requestsYou can test the operation of the script from the shell by requesting, for example, LLD data about the disks:
[root@zabbix]# ./zbx-hpmsa.py -m MSA_DNS_NAME_OR_IP -d -c disks
{"data":[{"{#DISK.ID}":"1.1","{#DISK.SN}":"KFGY7LVF"},{"{#DISK.ID}":"1.2","{#DISK.SN}":"Z0K02QVG0000C4297CH3"},{"{#DISK.ID}":"1.3","{#DISK.SN}":"KLK7XG0F"}, ... }
Host setup
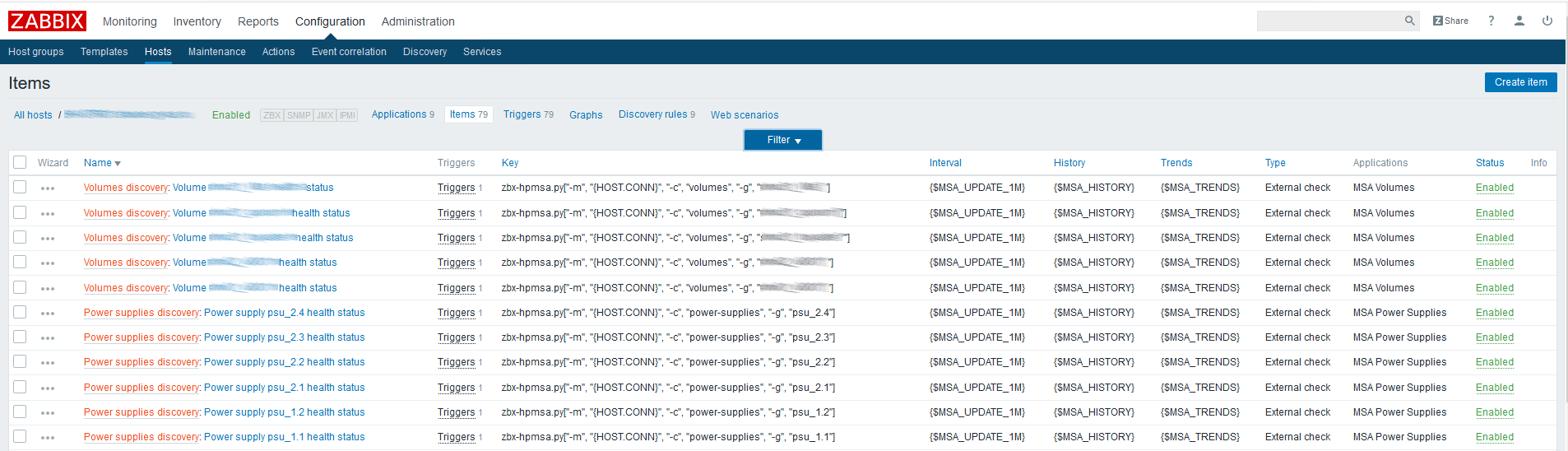
First you need to create parent data elements that will contain all the metrics we need. As an example, let's create such an element for physical disks:
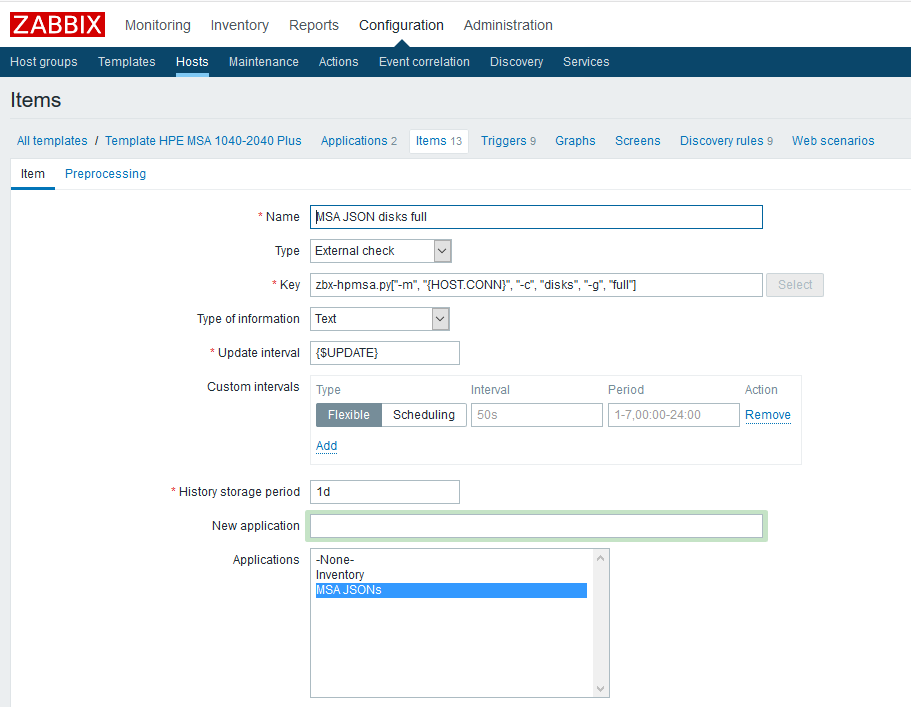
Name - arbitrarily specified;
Type - external check;
The key is a script call with the necessary parameters (see the script documentation on GitHub);
Type of information - text;
Update interval — the example uses the custom macro {$ UPDATE}, which expands to the value “1m”;
The storage period is one day. I think that keeping the parent data element for longer does not make sense.
Check the latest data on the created item:
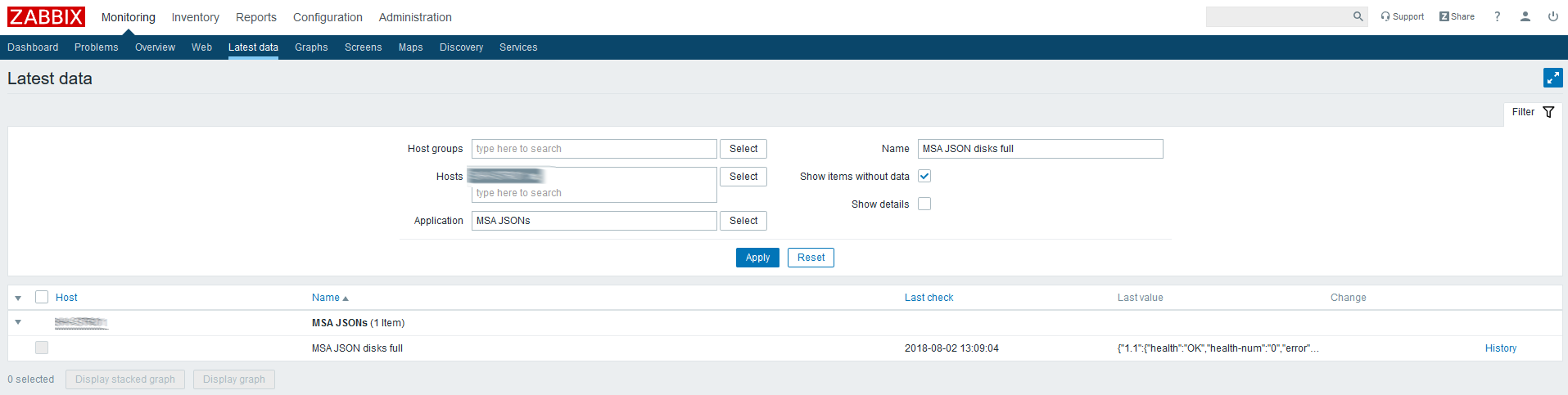
JSON comes, so everything is done correctly.
The next step is to set up detection rules that will find all components available for monitoring and create dependent items and triggers. Continuing with the example of physical disks, it will look like this:
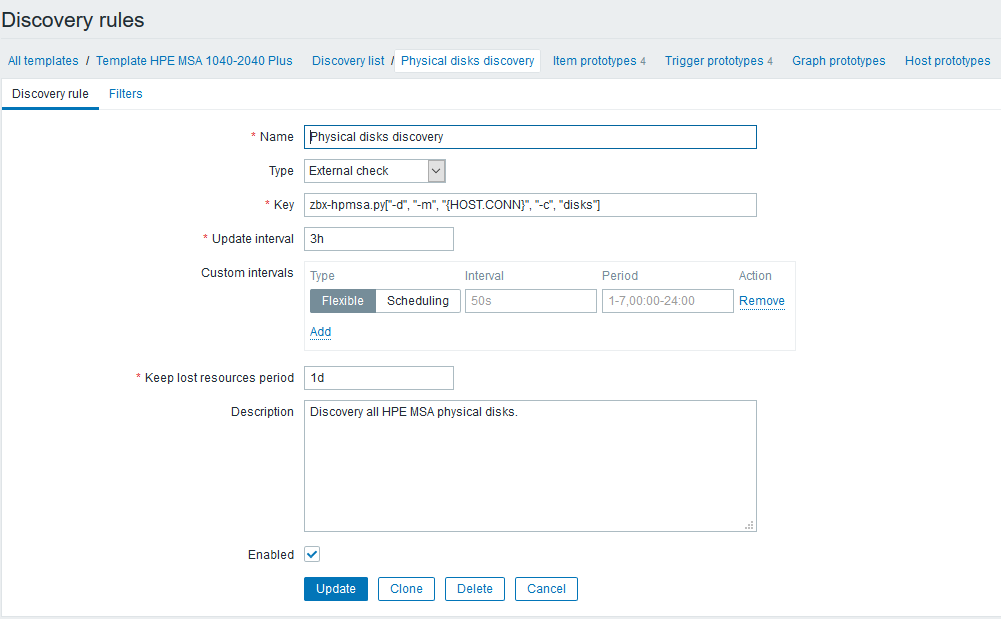
After creating the LLD rule, you need to create prototypes of data elements. Let's create such a prototype, using data on temperature as an example:
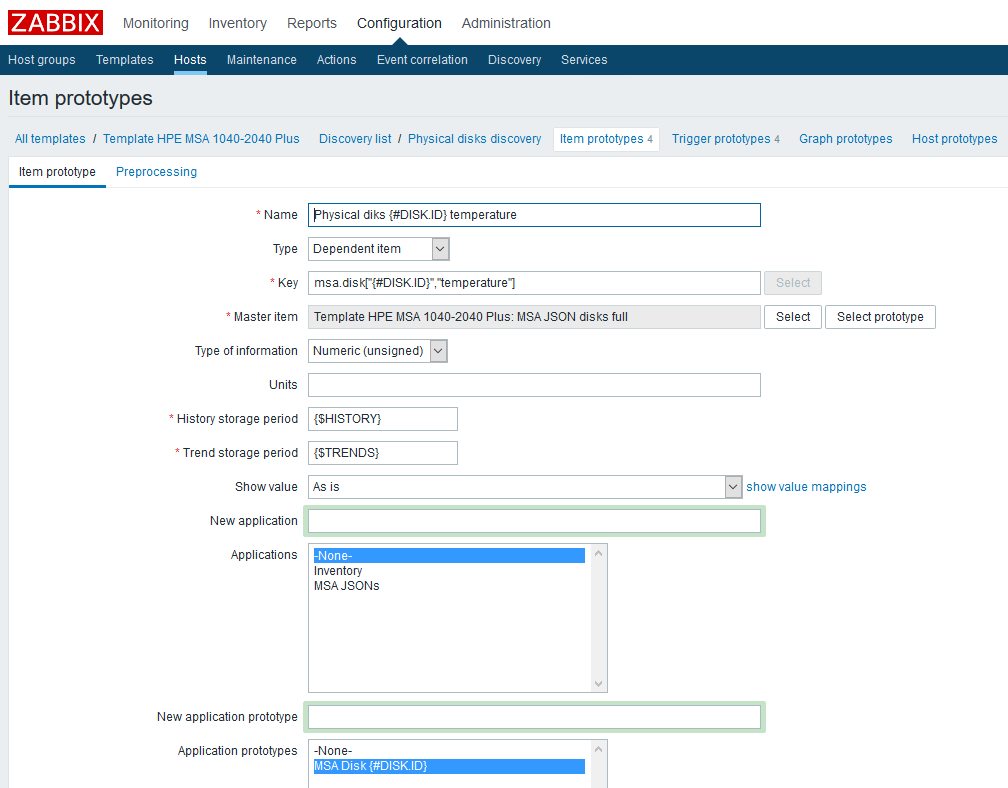
Name - we indicate arbitrarily;
Type - dependent. As the parent data element, select the corresponding element created earlier;
The key is to show imagination, but you need to consider that each key must be unique, so we will include the LLD macro in it;
Type of information - in this case numeric;
History retention period- in the example, this is a custom macro, specified at your discretion;
The trend storage period is, again, a user macro;
I also added a prototype of the “Application” - you can conveniently bind to it metrics related to one component.
On the “Preprocessing” tab, we will create a “JSON Path” step with a rule that extracts temperature readings:
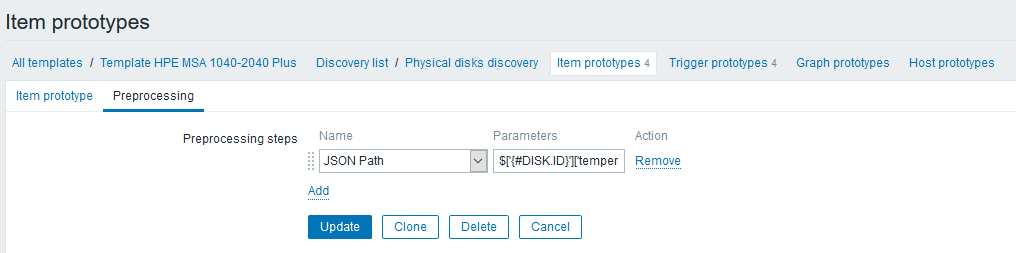
The step expression looks like this:
$['{#DISK.ID}']['temperature']Pay attention that now you can use LLD macros in the expression, which not only makes our work much easier, but also allows us to things are pretty simple (you would have been sent to the Zabbix API before).
Next, by analogy with the temperature, we will create the remaining prototypes of the data elements:

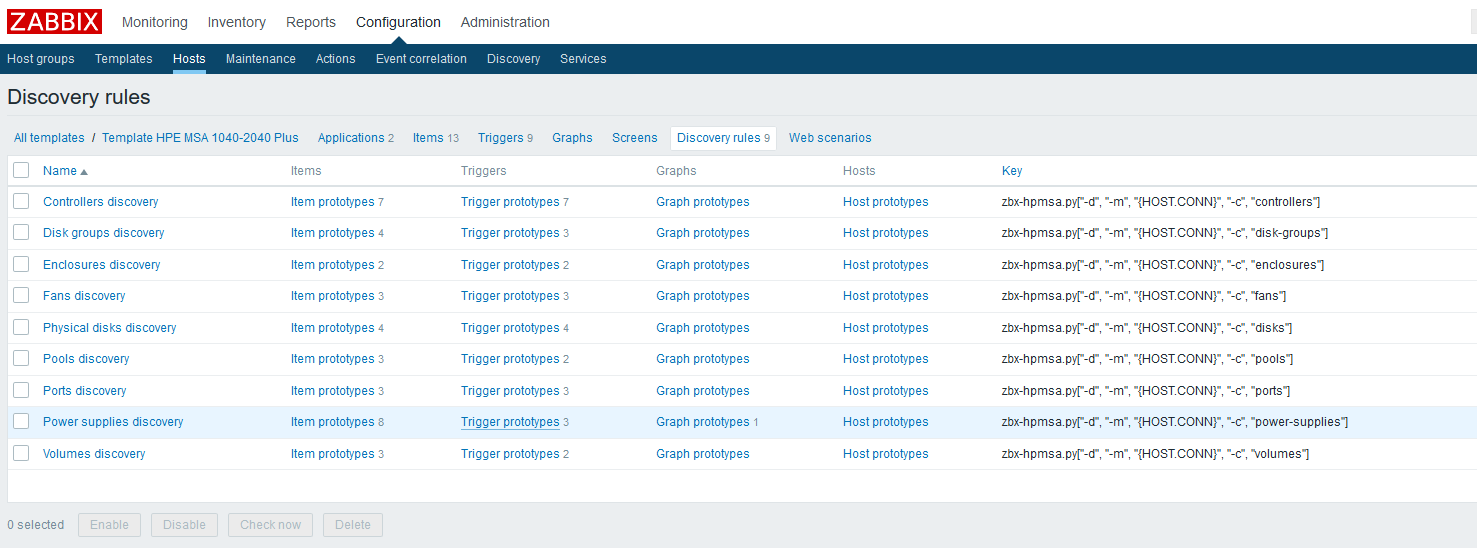
At this stage, you can check the result obtained by going to the "Latest data" on the host. If everything suits you there, we continue to work further. I ended up getting the following picture:
We are waiting for the configuration cache to be updated or push its update manually:
[root@zabbix]# zabbix_server -R config_cache_reloadAfter this, you can use another cool feature of version 4.0 - the “Check now” button to launch the created LLD rules:
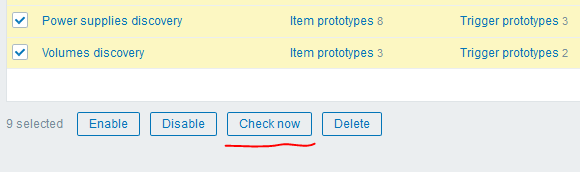
I got the following result:
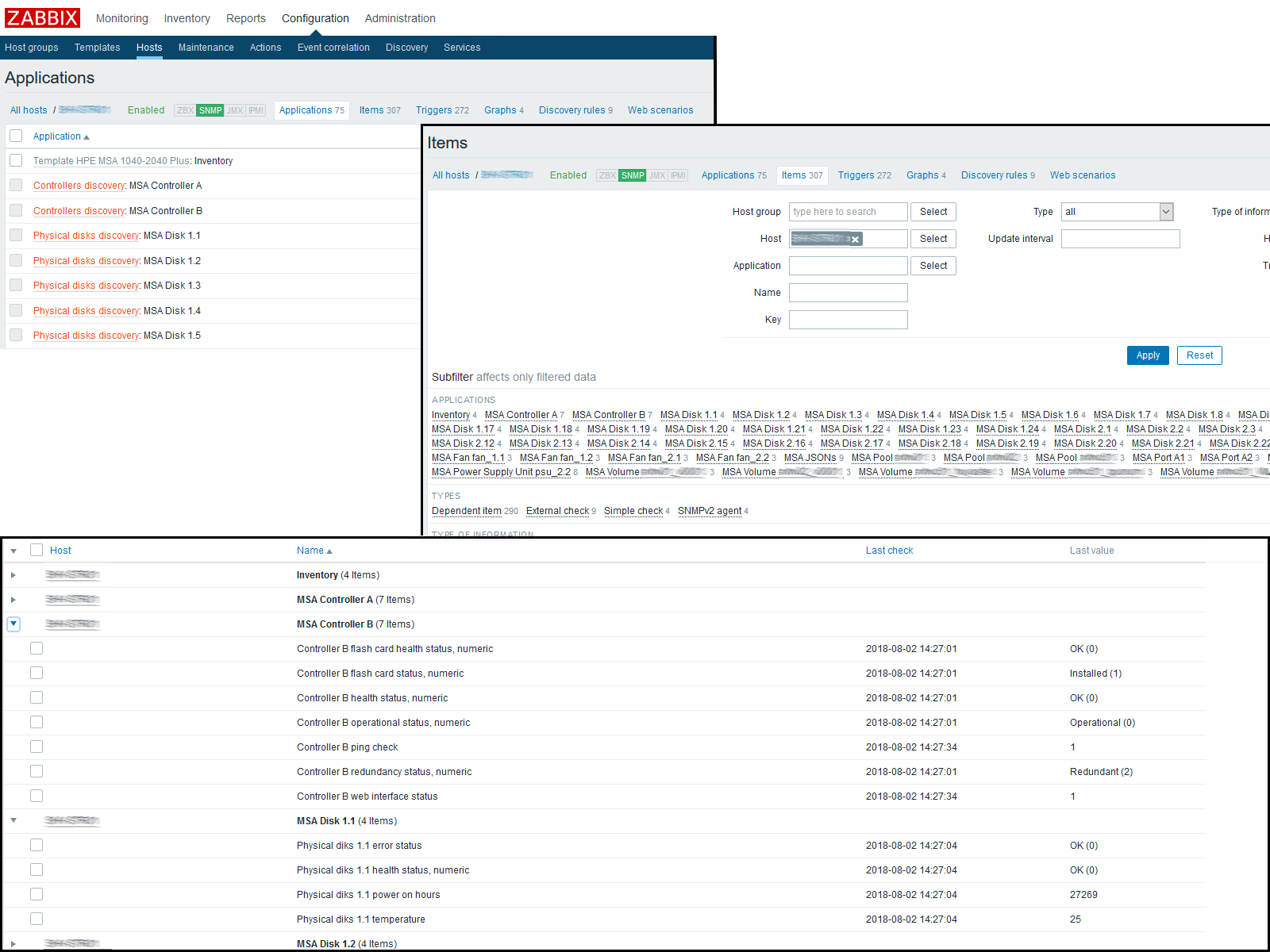
Conclusion
As a result, with only nine requests to the XML API, we were able to get more than three hundred metrics from one network node, spending a minimum of time and getting maximum flexibility. LLD will give us the ability to automatically discover new components or update old ones.
Thank you for reading the links to the materials used, and there you can find the current HPE MSA P2000G3 / 2040/2050 template below.
PS By the way, in version 4.0, a new type of checks is also presented - an HTTP agent that paired with preprocessing and XML Path can potentially save us from using external scripts - you just need to solve the issue of obtaining an authentication token, which still needs to be updated periodically. One of the options I see is the use of a global macro with this token, which can be updated via Zabbix API by cron, t.ch. interested people can develop this idea. =)
Script
Template on Zabbix Share
Dependent
JSON Path data elements
Zabbix 4.0alpha9