Tuning JVM on the example of one project
In this article I want to talk about the experience gained in optimizing applications from memory using standard JVM optimization mechanisms such as various types of links, garbage collection strategies, and many keys that affect garbage collection. I am sure that each of you had to juggle parameters to improve performance and you will not find any black magic or a recipe for lack of memory in the article, you just want to share your experience.
It all started beautifully and cloudlessly. For the needs of one large bank, it was necessary to implement a calculator that calculates the Value-at-Risk value for a specific investment portfolio. Like most financial applications, the methodology does not imply “heavy” calculations, but the data flow is sometimes huge.
The problems of processing a large amount of data are usually solved by two well-known types of scaling: vertical and horizontal. With the vertical, everything was reasonably acceptable. We had at our disposal a machine with 16 cores, with 16 GB RAM, Red Hat and Java 1.6. It was possible to turn around quite well on such hardware, which, in fact, we have successfully done for several months.
Everything was fine until the customer knocked on us and said that the IT infrastructure was revised and instead of 16x16 we have 4x1-2:

Naturally, the requirement for the application’s runtime was increased several times, but. To convey our emotions at that time was difficult enough, but speech, suddenly, became strongly seasoned with various allegories, allusions and comparisons.
First, let me explain what a Value-at-Risk calculator is. This is a program with a lot of "simple" calculations, passing through a large amount of data.
The optimization keys that were most useful:
Naturally, such a simple technique did not give the desired results, and we continued to dig in the direction of further possibilities of “shrinking” the application. The first thing that was decided to do was to remove unnecessary caches and optimize existing ones (those that give a 20% increase in performance out of 80%). Unnecessary ones were quickly removed, and to work on the remaining ones, we decided to look at various types of links in Java.
So, we have the following link types available:
The dependencies between them look something like this:
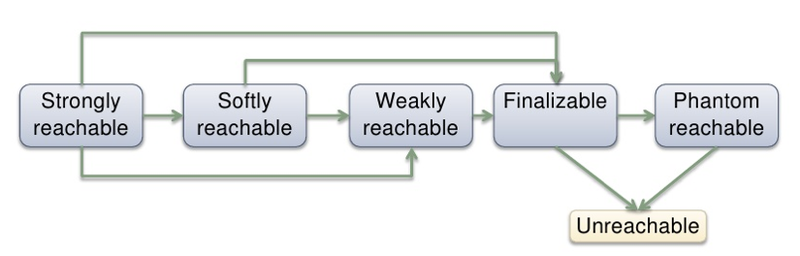
Let's see what the specification for working with these types of links guarantees.
Hard / Strong links are the most common links that are created when we use the “new” keyword. Such a link will be deleted when the number of links to the created object reaches zero. Soft links (Soft) can be deleted if the virtual machine does not have enough memory for further work. Weak links (Weak) can be collected at any time, if the GC decides. Phantom link (Phantom) is a special type of links that is necessary for more flexible file objectization than classic finalize.
Hard and Phantom links were immediately removed from our consideration due to the fact that they do not provide the required functionality and flexibility. Hard are not deleted at the right time, but everything was in order with the file system.
Consider, for example, how Weak links are assembled:

We see that we have no guarantee that the object will be accessible all the time and can be deleted at any time. Because of this specificity, it was decided to rebuild the internal, most “heavy” caches for Soft links. We were driven by the following statement: “Let the object live in the cache for as long as possible, but in case of lack of memory we can calculate it again, due to the fact that the requirements for operating time have been increased.”
The results were significant, but the application did not work in the coveted 4GB.
Further research was carried out using various profiling tools:
Data collection did not take so much time, unlike analysis. After spending several wonderful days observing the numbers and letters, the following conclusions were drawn: a lot of objects are being created and the old generation is very overloaded. In order to solve this problem, we began to look in the direction of various garbage collectors and methods of working with them.
Firstly, it was necessary to reduce the number of generated objects. It was noted that most of the data has a similar structure: "XXX1: XXX2: XXX3 and so on." All patterns of the “XXX” type were replaced by references to objects from the pool, which resulted in a significant reduction in the number of created objects (about five times), and also freed up an additional amount of precious memory.
Secondly, we decided to work in more detail with garbage collection strategies. As we know, we have the following garbage collection strategies available:
G1 was not available to us due to the fact that the sixth version of Java was used. Serial and Parallel are not much different and have not shown themselves very well in our task. Parallel compacting was and was interesting due to the phase, which allows to reduce data defragmentation. Concurrent Mark-Sweep was interesting due to the fact that it allowed to reduce the time for the stop-the-world phase and also did not allow strong fragmentation.
After comparing Parallel compacting and Concurrent Mark-Sweep collectors, it was decided to stop at the second one, which turned out to be a good solution.
After a combat test of all the above techniques, the application has become fully compatible with the new requirements and successfully launched in production! Everyone breathed a sigh of relief!
A more detailed version of the problem and the stages of the solution can be heard at the upcoming JPoint conference , which will be held in St. Petersburg.

Project history
It all started beautifully and cloudlessly. For the needs of one large bank, it was necessary to implement a calculator that calculates the Value-at-Risk value for a specific investment portfolio. Like most financial applications, the methodology does not imply “heavy” calculations, but the data flow is sometimes huge.
The problems of processing a large amount of data are usually solved by two well-known types of scaling: vertical and horizontal. With the vertical, everything was reasonably acceptable. We had at our disposal a machine with 16 cores, with 16 GB RAM, Red Hat and Java 1.6. It was possible to turn around quite well on such hardware, which, in fact, we have successfully done for several months.
Everything was fine until the customer knocked on us and said that the IT infrastructure was revised and instead of 16x16 we have 4x1-2:
Naturally, the requirement for the application’s runtime was increased several times, but. To convey our emotions at that time was difficult enough, but speech, suddenly, became strongly seasoned with various allegories, allusions and comparisons.
First attempts
First, let me explain what a Value-at-Risk calculator is. This is a program with a lot of "simple" calculations, passing through a large amount of data.
The optimization keys that were most useful:
- -server is an extremely useful key, the JVM expands loops, inlines many functions, etc.
- Work with strings: -XX: + UseCompressedStrings, -XX: + UseStringCache, -XX: + OptimizeStringConcat
Naturally, such a simple technique did not give the desired results, and we continued to dig in the direction of further possibilities of “shrinking” the application. The first thing that was decided to do was to remove unnecessary caches and optimize existing ones (those that give a 20% increase in performance out of 80%). Unnecessary ones were quickly removed, and to work on the remaining ones, we decided to look at various types of links in Java.
So, we have the following link types available:
- Hard / strong
- Soft
- Weak
- Phantom
The dependencies between them look something like this:
Let's see what the specification for working with these types of links guarantees.
Hard / Strong links are the most common links that are created when we use the “new” keyword. Such a link will be deleted when the number of links to the created object reaches zero. Soft links (Soft) can be deleted if the virtual machine does not have enough memory for further work. Weak links (Weak) can be collected at any time, if the GC decides. Phantom link (Phantom) is a special type of links that is necessary for more flexible file objectization than classic finalize.
Hard and Phantom links were immediately removed from our consideration due to the fact that they do not provide the required functionality and flexibility. Hard are not deleted at the right time, but everything was in order with the file system.
Consider, for example, how Weak links are assembled:
We see that we have no guarantee that the object will be accessible all the time and can be deleted at any time. Because of this specificity, it was decided to rebuild the internal, most “heavy” caches for Soft links. We were driven by the following statement: “Let the object live in the cache for as long as possible, but in case of lack of memory we can calculate it again, due to the fact that the requirements for operating time have been increased.”
The results were significant, but the application did not work in the coveted 4GB.
Detailed study
Further research was carried out using various profiling tools:
- Standard JVM tools: -XX: + PrintGCDetails, -XX: + PrintGC, -XX: PrintReferenceGC, etc
- MXBean
- Visualvm
Data collection did not take so much time, unlike analysis. After spending several wonderful days observing the numbers and letters, the following conclusions were drawn: a lot of objects are being created and the old generation is very overloaded. In order to solve this problem, we began to look in the direction of various garbage collectors and methods of working with them.
Firstly, it was necessary to reduce the number of generated objects. It was noted that most of the data has a similar structure: "XXX1: XXX2: XXX3 and so on." All patterns of the “XXX” type were replaced by references to objects from the pool, which resulted in a significant reduction in the number of created objects (about five times), and also freed up an additional amount of precious memory.
Secondly, we decided to work in more detail with garbage collection strategies. As we know, we have the following garbage collection strategies available:
- Serial
- Parallel
- Parallel compacting
- Concurrent mark-sweep
- G1 collector
G1 was not available to us due to the fact that the sixth version of Java was used. Serial and Parallel are not much different and have not shown themselves very well in our task. Parallel compacting was and was interesting due to the phase, which allows to reduce data defragmentation. Concurrent Mark-Sweep was interesting due to the fact that it allowed to reduce the time for the stop-the-world phase and also did not allow strong fragmentation.
After comparing Parallel compacting and Concurrent Mark-Sweep collectors, it was decided to stop at the second one, which turned out to be a good solution.
After a combat test of all the above techniques, the application has become fully compatible with the new requirements and successfully launched in production! Everyone breathed a sigh of relief!
Lesson learned
- The keys for working with strings helped: -XX: + UseCompressedStrings, -XX: + UseStringCache, -XX: + OptimizeStringConcat and the specifics of the string data itself
- Reducing the number of objects used
- Fine-tuning the JVM takes a lot of time, but the results are more than justified
- Get to know your requirements as early as possible! :)
A more detailed version of the problem and the stages of the solution can be heard at the upcoming JPoint conference , which will be held in St. Petersburg.