The fight against cheating in ratings
The other day I read an interesting article about ratings. As a practical guide, I do not recommend using it (why see in the comments on it), however, the fiction was interesting and gave me one thought.
Suppose we have a rating from 1 to 5. And some estimates are wound up, some users have randomly set. How to filter the grain from the chaff?
If you build a chart of the number of people who put a certain rating, then you can see approximately how many votes were wound. Of course, it is necessary to compare with other diagrams, but from this picture it is clear that part of the “fives” is wound:

In general, a person can determine the wrap from the diagram, which means that the machine can also.
The distribution of votes can be described by the beta distribution function.
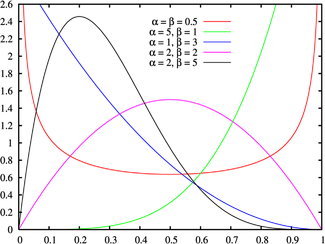
If in most cases voting can be described by the beta function, but not in part, then part of the votes can be removed.

Thus, we will not exclude all the bad voices, we will exclude some of the good ones. For articles with a small number of votes, such manipulations are unacceptable.
The beta distribution has two parameters, alpha and beta. We also have two parameters, the average score (E) and the variance (D) - a measure of scatter. From Wikipedia it is known that.
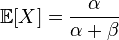
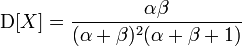
Now we solve the system of equations. This is long and tedious.
As a result, we can build a beta function. All ratings are higher than it, probable markups. If someone will be interested to sign in more detail.
Suppose we have a rating from 1 to 5. And some estimates are wound up, some users have randomly set. How to filter the grain from the chaff?
If you build a chart of the number of people who put a certain rating, then you can see approximately how many votes were wound. Of course, it is necessary to compare with other diagrams, but from this picture it is clear that part of the “fives” is wound:
In general, a person can determine the wrap from the diagram, which means that the machine can also.
The distribution of votes can be described by the beta distribution function.
If in most cases voting can be described by the beta function, but not in part, then part of the votes can be removed.
Thus, we will not exclude all the bad voices, we will exclude some of the good ones. For articles with a small number of votes, such manipulations are unacceptable.
The beta distribution has two parameters, alpha and beta. We also have two parameters, the average score (E) and the variance (D) - a measure of scatter. From Wikipedia it is known that.
Now we solve the system of equations. This is long and tedious.
E = a / (a + b)
d = ab / ((a + b) ^ 2 * (a + b + 1))
replace a / (a + b) with E
d = bE / ((a + b) * (a + b + 1))
replace 1 / (a + b) by E / a
d = b * E ^ 2 / (a * (a + b + 1))
we multiply both sides by (a * (a + b + 1))
d (a * (a + b + 1)) = b * E ^ 2
open the brackets and swap
b * E ^ 2 = da ^ 2 + dab + da
subtract dab from both sides
b * E ^ 2-dab = da ^ 2 + da
b (E ^ 2-da) = da (a + 1)
b = da (a + 1) / (E ^ 2-da)
Let us return to the first equation
E = a / (a + b) => (a + b) = a / E => b = a / E -a
combine both equations
b = a / E -a = da (a + 1) / (E ^ 2-da)
a / E-a = da (a + 1) / (E ^ 2-da)
divide by a
1 / E -1 = d (a + 1) / (E ^ 2-da)
multiply by E (E ^ 2-da )
(1-E) (E ^ 2-da) = Ed (a + 1)
E ^ 2-da -E ^ 3 + Eda = Eda + Ed
Eda shorten
E ^ 2-da -E ^ 3 = Ed
E ^ 2 -E ^ 3 -Ed = da
a = (E ^ 2 -E ^ 3 - Ed) / d
b = a / E -a = a (1 / E-1) = a (1-E) / E = (E ^ 2 -E ^ 3 -Ed) (1-E) / Ed = ( E-E ^ 2 -d) (1-E) / d = (E -E ^ 2 -d - E ^ 2 + E ^ 3 + dE) / d
b = (E ^ 3-2E ^ 2 + E) / d + E -1
As a result, we can build a beta function. All ratings are higher than it, probable markups. If someone will be interested to sign in more detail.