Why did I rip one CD 300 times
- Transfer
I collect music: I buy CDs, digitize them with the Exact Audio Copy program , scan covers and inserts. Sometimes it is not easy if the CD is released in a limited edition abroad 10 years ago. The hardest thing is if there is a manufacturing defect on the compact - and some tracks are not readable.
 Piano Arranging Album 帰 る べ き 城 by Altneulandwas released in 2005. I found it three years later (probably on YouTube), downloaded the best copy - and made the disc on my list of future purchases. Recent advances in international mail technology allowed us to buy a second-hand disk last year. Unfortunately, none of my CD drives could read track number 3. This often happens when buying old CDs, especially when they went through the USPS international delivery center. I put it off and started looking for another copy that I found last month. He arrived on Friday - and I immediately tried to rip him. But with pushed with the exact same mistake . It seems that it’s not a matter of wear or damage - the disk probably came out defective right from the factory.
Piano Arranging Album 帰 る べ き 城 by Altneulandwas released in 2005. I found it three years later (probably on YouTube), downloaded the best copy - and made the disc on my list of future purchases. Recent advances in international mail technology allowed us to buy a second-hand disk last year. Unfortunately, none of my CD drives could read track number 3. This often happens when buying old CDs, especially when they went through the USPS international delivery center. I put it off and started looking for another copy that I found last month. He arrived on Friday - and I immediately tried to rip him. But with pushed with the exact same mistake . It seems that it’s not a matter of wear or damage - the disk probably came out defective right from the factory.
ADDITION: After the investigation, I no longer believe that this is a factory defect. When I record the beginning or end of a failed track on an empty CD-R and copy it, the ripper gives the same error! Try it yourself with the file minimal.flac .
There are two options left: either to try sometime to find another copy that will be successfully copied (unlikely), or somehow restore the original sound data from damaged discs. You already know which option I chose.
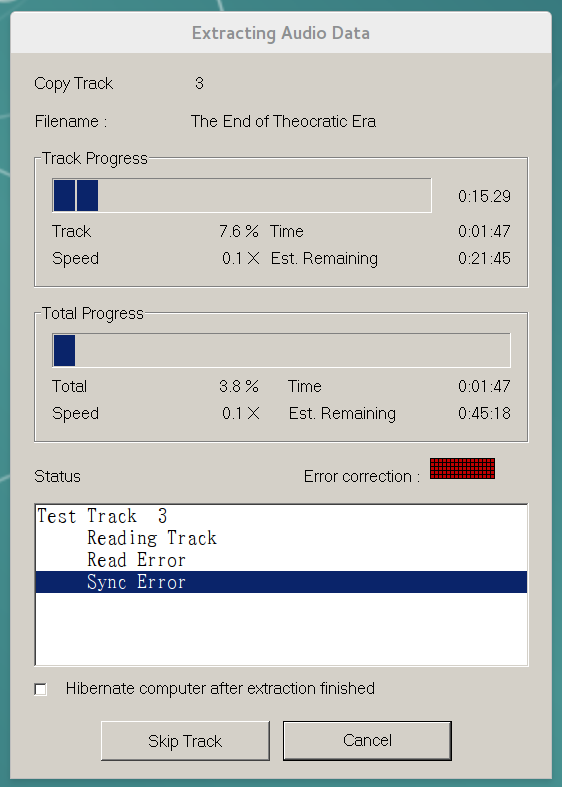
EAC was unable to read track 3 from the CD [帰 る べ き 城]
CDs store digital data, but there is a completely analog interface between disks, lasers and optical diodes. Reading errors occur for various reasons: dirty media, scratches on the protective layer of polycarbonate, vibration of the drive itself. Primitive error correction codes in the CDDA standard help to minimize sound distortion on rarely used discs, but are not able to fully recover the bitstream on a CD with a large number of errors. Modern rippers solve the problem using two important error detection methods: redundant reading and AccurateRip.
The EAC: Extraction Technology pagedescribes how EAC performs redundant reading:
It's simple. If a read request sometimes returns incorrect data, read it again, and then be especially careful if the first two reads give different results. AccurateRip uses the same principle, but distributed: in this service, rippers send checksums of copied audio files. The idea is that if a thousand people copied a track with the same bits, this is probably the right rip.
This article is about what to do if both methods cannot help. EAC does not give a result if each read returns a different data, and in the AccurateRip database there is only one record about a rare disk [1].

Asus, LG, Lite-On, Pioneer and OEM OEM Optical Drives.
If the CD is not copied, it’s logical to use another drive. Sometimes a particular model is more condescending about the specifications of CDDA, or is there the best firmware for fixing errors, or something else. The DBpoweramp forum has an accuracy rating of CD / DVD drives to select the most suitable drive for rip.
I bought five new CD drives from different manufacturers on Saturday morning [2], tried them all - and found one that could keep the sync on the beat track. Unfortunately, the confirmation of the rip could not be obtained - between all the rips there were about 20,000 different bytes.
But now I had .wav files on the disk, and from this you can benefit. I reasoned that reading errors on a bad track are somewhere near the “right” one. Therefore, it makes sense to make a few rips and find a “consensus” value for unstable bytes. This approach was ultimately successful, but it required much more work than I expected.
I started by repeatedly copying the disk on one of the drives, writing all the values for each byte and declaring the error “correctable” if more than half of the rips produce a certain byte value for this position. The start was good: the unrecoverable error was reduced from almost 6900 bytes with N = 4 to ~ 5000 bytes with N = 10. The benefit from each additional rip decreased over time, until approximately by N = 80 the number of uncorrectable errors stabilized at ~ 3700. I stopped rips at N = 100.
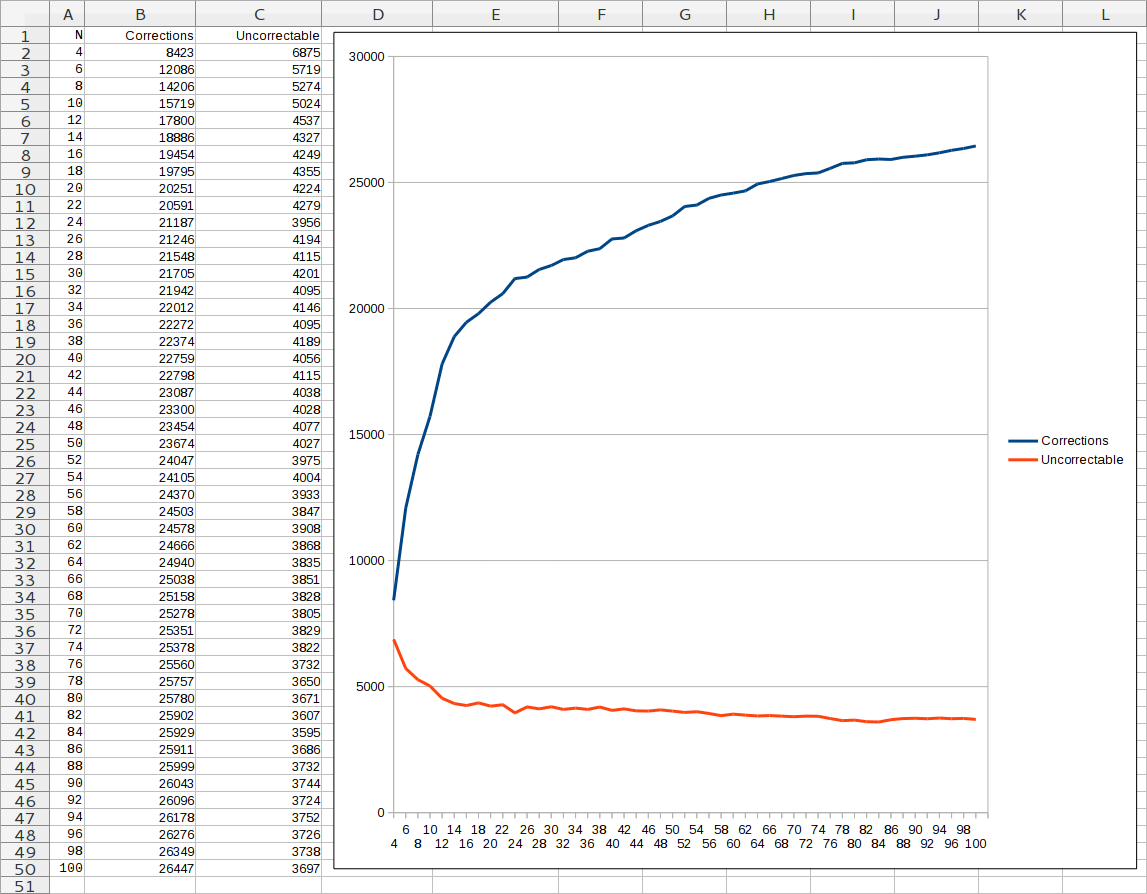
Corrected and unrecoverable errors on the number of rip
Then I tried to copy the disk 100 times on the second drive and use two correction cards to “fill” the uncorrectable error positions from the first drive. But it didn't work: on each drive there were thousands of fixes that did not match the fixes on the other! It turns out that you can not eliminate the noise by combining it with another, but related source of noise.
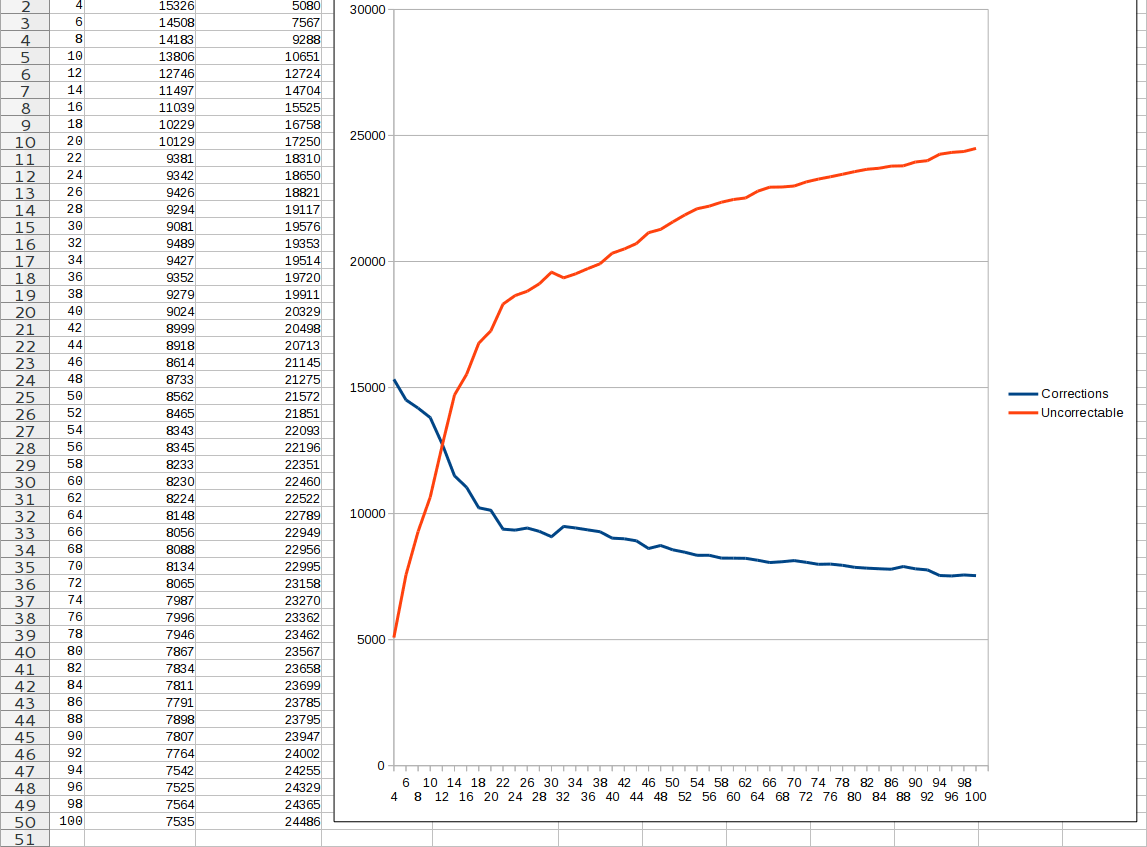
The same, but for two disks with cross-checking fixes

On the EAC website there is another good resource: the DAE quality test , which determines the quality of the drive firmware by the level of correctable errors. This is a lower level error handling when the drive corrects read errors and not just reports them. The catch is that the EAC “safe mode” is available only when this built-in error correction code is turned off, assuming its malfunction.
I prepared a test by burning a .wav file onto a CD-R, highlighting the exact sector on the data surface and carefully painting it with a black marker. Here it is - guaranteed fatal errors on a deterministic pattern.
I tested all the drives and got two interesting results:
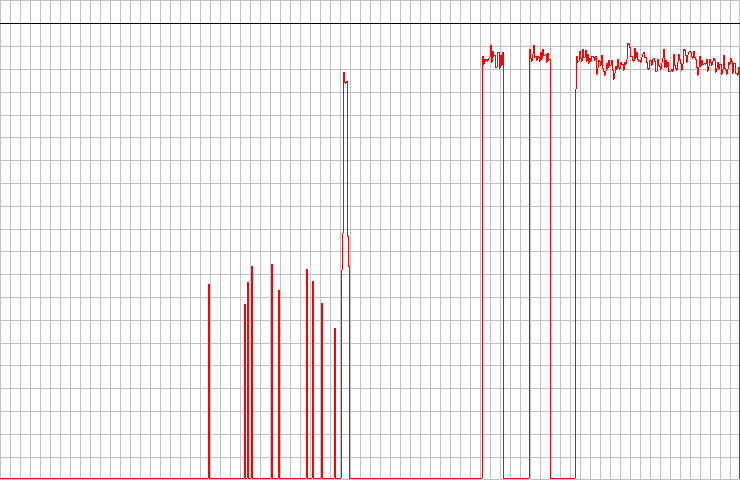
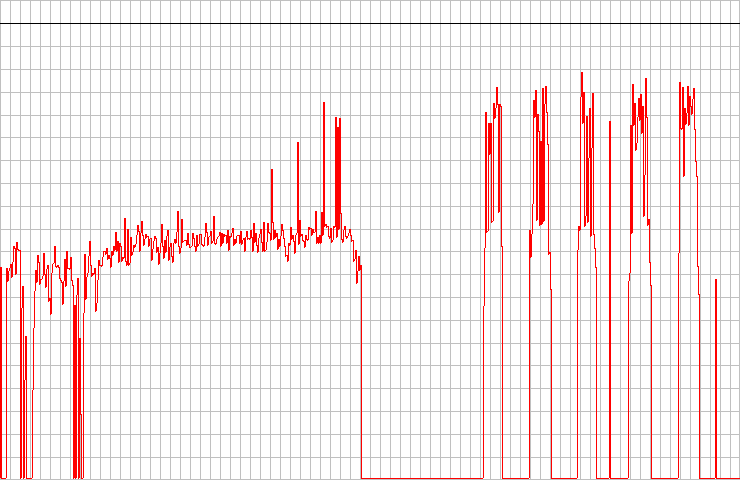
I used the Lite-On Drive before to get around sync errors. He happily chewed on the magic marker, but he was greatly embarrassed by the straight lines on the data surface. You can see how instead of the three separate peaks on the right one giant crash blob. Drive Pioneer received the highest score on the test DAE. In my opinion, the graph does not look any special, but the analysis tool said that it is the best firmware for fixing errors in my small set.
How to use the Pioneer firmware with a good bug fix if the EAC "safe mode" ignores it? Very simple: switch EAC to “burst mode” (burst mode) and write a stream of bits to the disk in the form in which the firmware reports them. How do you turn this bunch of unverified .wav files into a good quality file, like in "safe mode"? Yes, the same error analysis tool that we used in Rips with Lite-On!
After a few EAC configuration settings and after all, we get such a beautiful diagram.
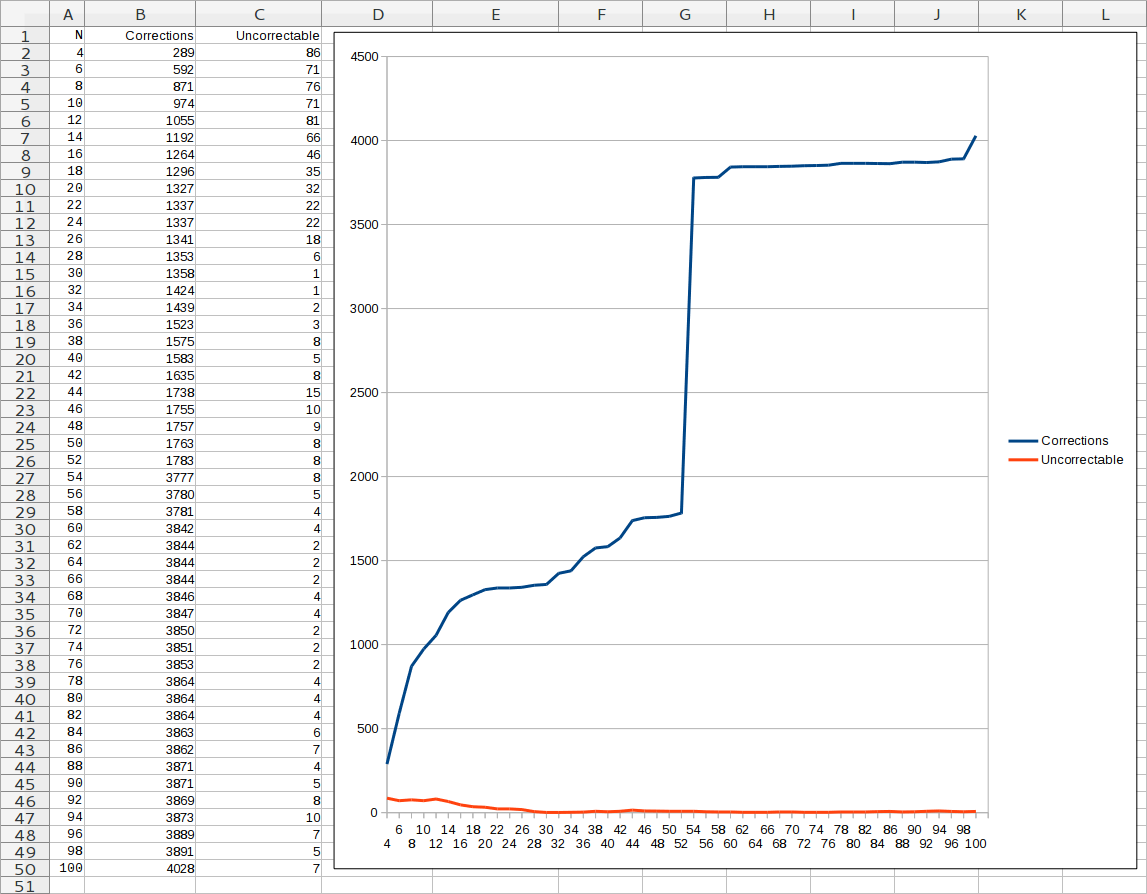
Corrected and unrecoverable errors on the number of rips (Pioneer)
What can be noted:
Using Pioneer's near-perfect error correction, I generated the “Better Assumption” file and began comparing it with Pioneer rips. As expected, there were several poor-quality sites that I fixed by making 10 more rips: I also found something really interesting: several rips gave out exactly the same content! Remember, this is precisely the criterion of success in the EAC "safe mode". The command is used to calculate the CRC32 raw audio checksum: it is used by the EAC. In the meantime, repeated rips of substandard sites allowed the analysis to be completed with zero unrecoverable errors. And when I checked this file, there was exactly the same audio content as in the “normal” rip! This is enough to declare victory.
I am 99% sure that I successfully copied this problem CD, and 0xA595BC09 is the correct CRC sum for track 3.
I used this tool to calculate probable byte errors. It is not intended for long-term use, so it is a bit ugly, but it may be interesting to those who stumbled upon this page, solving the same problem.
one. In this single AccurateRip record to my disk, the CRCs for all tracks are the same except for track No. 3: the sum is 0x84B9DD1A, and I have 0xA595BC09. I suspect that the ripper did not understand that he has a bad disk. [return]
2.The obvious question when buying a CD or DVD drive in 2018: "Damn, where can I buy them?". And I needed not one, but several from different brands . I know only one store nearby that has 5.25 "DVD drives available. Only one store is big enough not to regret space on the shelves for such drives, and strange enough so that they don't seem out of place there. Of course, I I'm talking about Frys Electronics. [back]
Piano Arranging Album 帰 る べ き 城 by Altneulandwas released in 2005. I found it three years later (probably on YouTube), downloaded the best copy - and made the disc on my list of future purchases. Recent advances in international mail technology allowed us to buy a second-hand disk last year. Unfortunately, none of my CD drives could read track number 3. This often happens when buying old CDs, especially when they went through the USPS international delivery center. I put it off and started looking for another copy that I found last month. He arrived on Friday - and I immediately tried to rip him. But with pushed with the exact same mistake . It seems that it’s not a matter of wear or damage - the disk probably came out defective right from the factory.ADDITION: After the investigation, I no longer believe that this is a factory defect. When I record the beginning or end of a failed track on an empty CD-R and copy it, the ripper gives the same error! Try it yourself with the file minimal.flac .
There are two options left: either to try sometime to find another copy that will be successfully copied (unlikely), or somehow restore the original sound data from damaged discs. You already know which option I chose.
How does the ripper
EAC was unable to read track 3 from the CD [帰 る べ き 城]
CDs store digital data, but there is a completely analog interface between disks, lasers and optical diodes. Reading errors occur for various reasons: dirty media, scratches on the protective layer of polycarbonate, vibration of the drive itself. Primitive error correction codes in the CDDA standard help to minimize sound distortion on rarely used discs, but are not able to fully recover the bitstream on a CD with a large number of errors. Modern rippers solve the problem using two important error detection methods: redundant reading and AccurateRip.
The EAC: Extraction Technology pagedescribes how EAC performs redundant reading:
In safe mode, the program reads each sector at least twice [...] If an error occurs (read or synchronize), then the program continues to read this sector until 8 out of 16 attempts are identical. This procedure is carried out a maximum of one, three or five times (in accordance with the chosen quality of error recovery). So in the worst case, bad sectors are read 82 times!
It's simple. If a read request sometimes returns incorrect data, read it again, and then be especially careful if the first two reads give different results. AccurateRip uses the same principle, but distributed: in this service, rippers send checksums of copied audio files. The idea is that if a thousand people copied a track with the same bits, this is probably the right rip.
This article is about what to do if both methods cannot help. EAC does not give a result if each read returns a different data, and in the AccurateRip database there is only one record about a rare disk [1].
"I passed ten thousand passes, ten thousand passes to see you"
Asus, LG, Lite-On, Pioneer and OEM OEM Optical Drives.
If the CD is not copied, it’s logical to use another drive. Sometimes a particular model is more condescending about the specifications of CDDA, or is there the best firmware for fixing errors, or something else. The DBpoweramp forum has an accuracy rating of CD / DVD drives to select the most suitable drive for rip.
I bought five new CD drives from different manufacturers on Saturday morning [2], tried them all - and found one that could keep the sync on the beat track. Unfortunately, the confirmation of the rip could not be obtained - between all the rips there were about 20,000 different bytes.
But now I had .wav files on the disk, and from this you can benefit. I reasoned that reading errors on a bad track are somewhere near the “right” one. Therefore, it makes sense to make a few rips and find a “consensus” value for unstable bytes. This approach was ultimately successful, but it required much more work than I expected.
"Quantity goes into quality"
I started by repeatedly copying the disk on one of the drives, writing all the values for each byte and declaring the error “correctable” if more than half of the rips produce a certain byte value for this position. The start was good: the unrecoverable error was reduced from almost 6900 bytes with N = 4 to ~ 5000 bytes with N = 10. The benefit from each additional rip decreased over time, until approximately by N = 80 the number of uncorrectable errors stabilized at ~ 3700. I stopped rips at N = 100.
Corrected and unrecoverable errors on the number of rip
Then I tried to copy the disk 100 times on the second drive and use two correction cards to “fill” the uncorrectable error positions from the first drive. But it didn't work: on each drive there were thousands of fixes that did not match the fixes on the other! It turns out that you can not eliminate the noise by combining it with another, but related source of noise.
The same, but for two disks with cross-checking fixes
Handicraft
On the EAC website there is another good resource: the DAE quality test , which determines the quality of the drive firmware by the level of correctable errors. This is a lower level error handling when the drive corrects read errors and not just reports them. The catch is that the EAC “safe mode” is available only when this built-in error correction code is turned off, assuming its malfunction.
I prepared a test by burning a .wav file onto a CD-R, highlighting the exact sector on the data surface and carefully painting it with a black marker. Here it is - guaranteed fatal errors on a deterministic pattern.
I tested all the drives and got two interesting results:
I used the Lite-On Drive before to get around sync errors. He happily chewed on the magic marker, but he was greatly embarrassed by the straight lines on the data surface. You can see how instead of the three separate peaks on the right one giant crash blob. Drive Pioneer received the highest score on the test DAE. In my opinion, the graph does not look any special, but the analysis tool said that it is the best firmware for fixing errors in my small set.
Errors total Num : 206645159
Errors (Loudness) Num : 965075 - Avg : -21.7 dB(A) - Max : -5.5 dB(A)
Error Muting Num : 154153 - Avg : 99.1 Samples - Max : 3584 Samples
Skips Num : 103 - Avg : 417.3 Samples - Max : 2939 Samples
Total Test Result : 45.3 points (of 100.0 maximum)Errors total Num : 2331952
Errors (Loudness) Num : 147286 - Avg : -77.2 dB(A) - Max : -13.2 dB(A)
Error Muting Num : 8468 - Avg : 1.5 Samples - Max : 273 Samples
Skips Num : 50 - Avg : 6.5 Samples - Max : 30 Samples
Total Test Result : 62.7 points (of 100.0 maximum)“From a certain moment numbers matter”
How to use the Pioneer firmware with a good bug fix if the EAC "safe mode" ignores it? Very simple: switch EAC to “burst mode” (burst mode) and write a stream of bits to the disk in the form in which the firmware reports them. How do you turn this bunch of unverified .wav files into a good quality file, like in "safe mode"? Yes, the same error analysis tool that we used in Rips with Lite-On!
After a few EAC configuration settings and after all, we get such a beautiful diagram.
Corrected and unrecoverable errors on the number of rips (Pioneer)
What can be noted:
- Uncorrectable bit errors quickly go to zero, but never reach it.
- Huge jump in bug fixes in 53–54 rips.
- The number of errors before and after this big jump practically does not change, which indicates areas of stability in the copied data.
0xA595BC09
Using Pioneer's near-perfect error correction, I generated the “Better Assumption” file and began comparing it with Pioneer rips. As expected, there were several poor-quality sites that I fixed by making 10 more rips: I also found something really interesting: several rips gave out exactly the same content! Remember, this is precisely the criterion of success in the EAC "safe mode". The command is used to calculate the CRC32 raw audio checksum: it is used by the EAC. In the meantime, repeated rips of substandard sites allowed the analysis to be completed with zero unrecoverable errors. And when I checked this file, there was exactly the same audio content as in the “normal” rip! This is enough to declare victory.
$ for RIP_ID in $(seq -w 1 100); do echo -n "rip$RIP_ID: "; cmp -l analysis-out.wav rips-cd1-pioneer/rip${RIP_ID}/*.wav | wc -l ; done | sort -rgk2 | head -n 10
rip054: 2865
rip099: 974
rip007: 533
rip037: 452
rip042: 438
rip035: 404
rip006: 392
rip059: 381
rip043: 327
rip014: 323shncat -q -e | rhash --print="%C"$ for wav in rips-cd1-pioneer/*/*.wav; do shncat "$wav" -q -e | rhash --printf="%C $wav\n" - ; done | sort -k1
[...]
9DD05FFF rips-cd1-pioneer/rip059/rip.wav
9F8D1B53 rips-cd1-pioneer/rip072/rip.wav
A2EA0283 rips-cd1-pioneer/rip082/rip.wav
A595BC09 rips-cd1-pioneer/rip021/rip.wav
A595BC09 rips-cd1-pioneer/rip022/rip.wav
A595BC09 rips-cd1-pioneer/rip023/rip.wav
A595BC09 rips-cd1-pioneer/rip024/rip.wav
A595BC09 rips-cd1-pioneer/rip025/rip.wav
A595BC09 rips-cd1-pioneer/rip026/rip.wav
A595BC09 rips-cd1-pioneer/rip027/rip.wav
A595BC09 rips-cd1-pioneer/rip028/rip.wav
A595BC09 rips-cd1-pioneer/rip030/rip.wav
A595BC09 rips-cd1-pioneer/rip031/rip.wav
A595BC09 rips-cd1-pioneer/rip040/rip.wav
A595BC09 rips-cd1-pioneer/rip055/rip.wav
A595BC09 rips-cd1-pioneer/rip058/rip.wav
AA3B5929 rips-cd1-pioneer/rip043/rip.wav
ABAAE784 rips-cd1-pioneer/rip033/rip.wav
[...]I am 99% sure that I successfully copied this problem CD, and 0xA595BC09 is the correct CRC sum for track 3.
Appendix A: compare.rs
I used this tool to calculate probable byte errors. It is not intended for long-term use, so it is a bit ugly, but it may be interesting to those who stumbled upon this page, solving the same problem.
externcrate memmap;
use std::cmp;
use std::collections::HashMap;
use std::env;
use std::fs;
use std::sync;
use std::sync::mpsc;
use std::thread;
use memmap::Mmap;
const CHUNK_SIZE: usize = 1 << 20;
fnsuspect_positions(
mmaps: &HashMap<String, Mmap>,
start_idx: usize,
end_idx: usize,
) -> Vec<usize> {
letmut positions = Vec::new();
for ii in start_idx..end_idx {
letmut first = true;
letmut byte: u8 = 0;
for (_file_name, file_content) in mmaps {
if first {
byte = file_content[ii];
first = false;
}
elseif byte != file_content[ii] {
positions.push(ii);
break;
}
}
}
positions
}
fnmain() {
letmut args: Vec<String> = env::args().collect();
args.remove(0);
letmut first = true;
letmut size: usize = 0;
letmut files: Vec<fs::File> = Vec::new();
letmut mmaps: HashMap<String, Mmap> = HashMap::new();
for filename in args {
letmut file = fs::File::open(&filename).unwrap();
files.push(file);
let mmap = unsafe { Mmap::map(files.last().unwrap()).unwrap() };
if first {
first = false;
size = mmap.len();
} else {
assert!(size == mmap.len());
}
mmaps.insert(filename, mmap);
}
let (suspects_tx, suspects_rx) = mpsc::channel();
letmut start_idx = 0;
let mmaps_ref = sync::Arc::new(mmaps);
loop {
let t_start_idx = start_idx;
let t_end_idx = cmp::min(start_idx + CHUNK_SIZE, size);
if start_idx == t_end_idx {
break;
}
let mmaps_ref = mmaps_ref.clone();
let suspects_tx = suspects_tx.clone();
thread::spawn(move || {
let suspects = suspect_positions(mmaps_ref.as_ref(), t_start_idx, t_end_idx);
suspects_tx.send(suspects).unwrap();
});
start_idx = t_end_idx;
}
drop(suspects_tx);
letmut suspects: Vec<usize> = Vec::with_capacity(size);
formut suspects_chunk in suspects_rx {
suspects.append(&mut suspects_chunk);
}
suspects.sort();
println!("{{\"files\": [");
letmut first_file = true;
for (file_name, file_content) in mmaps_ref.iter() {
let file_comma = if first_file { "" } else { "," };
first_file = false;
println!("{}{{\"name\": \"{}\", \"suspect_bytes\": [", file_comma, file_name);
for (ii, position) in suspects.iter().enumerate() {
let comma = if ii == suspects.len() - 1 { "" } else { "," };
println!("[{}, {}]{}", position, file_content[*position], comma);
}
println!("]}}");
}
println!("]}}");
}one. In this single AccurateRip record to my disk, the CRCs for all tracks are the same except for track No. 3: the sum is 0x84B9DD1A, and I have 0xA595BC09. I suspect that the ripper did not understand that he has a bad disk. [return]
2.The obvious question when buying a CD or DVD drive in 2018: "Damn, where can I buy them?". And I needed not one, but several from different brands . I know only one store nearby that has 5.25 "DVD drives available. Only one store is big enough not to regret space on the shelves for such drives, and strange enough so that they don't seem out of place there. Of course, I I'm talking about Frys Electronics. [back]