Building AI for playing shogi Japanese chess
Not so long ago, I already wrote a small post on the development of AI for the game in the so-called. mini-shogi , but the survey showed that the more complete post on development would be interesting to the habrasociety. Who cares, please, under the cat.
Building programs that can play intellectual games is a very interesting task, which has great practical and scientific value.
The first attempts to create machines for playing intellectual games (primarily chess) appeared long before the advent of computers. Around 1769, the famous chess machine “mechanical Turk” appeared. The machine played very well, but its whole secret was a strong chess player hidden inside.
In the 20th century, mechanical machines gave way to digital computers. The pioneer in this field (as in many others) can be called the famous mathematician Alan Turing. By modern standards, the algorithm he developed was very primitive, and due to the lack of access to real computers, it was necessary to execute the algorithm manually.
Around the same time, Claude Shannon justified the existence of a better move for any position. He even proposed an algorithm for finding such a move for any game on the final board. Unfortunately, despite the existence of an optimal algorithm, its practical implementation is impossible due to limited hardware and time resources.
Since the time of Shannon, the task of programming intellectual games has moved from the field of entertainment to the field of serious research. In recent years, based on Shannon's research, practical algorithms have been built, with the help of which computers learned to play checkers accurately and achieved outstanding success in chess and go.
Japanese shogi chess is one of the few games where a person is still stronger than a computer. First of all, this is due to the possibility of returning the taken figures to the game, this rule sharply increases the number of possible moves, which means that it complicates the analysis of the game. If in chess you can make about 40 moves from an arbitrary position, then in shogi the number of possible moves is measured in hundreds.
Rules of the game
Before talking about building algorithms for playing shogi, you need to describe the rules of this game.
Shapes
There are 8 different figures in shogi (if you take into account the inverted figures, then 14). The rules of moves for various figures are presented in the table:

If you analyze the table, you can make the following observations:
These observations allow you to divide all the figures into four groups:
Initial arrangement and sequence of moves
Two players play shogi, which are usually called sente (go first) and gote (go second), on a square board of 9x9 squares. The initial arrangement of the figures is shown in the figure:

Each player also has a special stand (team), where the figures taken from the opponent are placed. It is also customary to say that the figures taken are "in the hand."
Coups
The last three horizontals (relative to each player) are the coup zone. Any untapped piece (except gold and king) that starts or ends its move inside this zone can turn over and turn into another piece. The transformation rules are fixed and shown in the table:

It is important to note that the player decides whether to turn the piece over or not. Cases when a coup is necessary are described in the forbidden moves section.
Resets
The reset rule is what makes the shogi game one of the most difficult games humanity has ever invented. The essence of the rule is that any figure eaten by the enemy can be put on any free field as your own.
There are several limitations to the reset rule, but they are quite simple:
Forbidden moves
If the opponent has made a forbidden move, he will immediately be counted as a defeat, so it is extremely important to know the list of forbidden moves:
The situation with leaving the king under the check is not completely clear. If the player did not notice the check to his king, then the next move the opponent can (but does not have to) eat the king. In this case, the game is considered over.
End of the game
The game ends when one of the players has checked or made a forbidden move. But in shogi there are additional rules for ending the game:
The above rules make a draw extremely rare for shogi (no more than 3% of all games played). Nevertheless, a draw is possible in one case: if both kings entered the enemy camp and strengthened there. If both players agree that the situation is deadlock, then scoring is done. All pieces (including in the hand) except the king, elephant and rook are valued at 1 point, the elephant and rook - at 5 points, the king is not involved in the calculation.
In professional games, a player with less than 24 points loses, if both players have at least 24 points, then a draw is declared. In amateur games, the winner is the one with at least 27 points, if both players have 27 points, then the victory will be awarded to the gote.
Algorithm for finding the best move
MiniMax Algorithm
For the first time, the strategy for finding the best move for any given position was described by Claude Shannon. If you think a little, you can see that this strategy is quite simple and applicable to any game.
Let us have some position in which we need to make an optimal move. First you need to generate all the moves allowed by the rules. Then each of the correct moves must be evaluated. The moves leading to victory will be evaluated as +1, leading to defeat, as -1, and the moves leading to a draw will receive a score of 0.
In order to determine what result the considered move will lead us to, we must assume that the enemy will respond to our every move in the best possible way. Those. in fact, he will use the algorithm in question: he will generate all his correct moves and choose the best one among them, and to assess how good his move is, he will assume that we will respond in the best possible way, etc.
It turns out that in the search for the best move on our part, the procedure for finding the best answer from the opponent’s side will be called, from which the procedure for finding our best answer to the opponent’s response will be called, etc.
The search function for the best move will recursively call itself until a matte or draw situation occurs.
Moreover, the assessment of the final position is not difficult, and when evaluating the parent nodes use the following rules:
Such an algorithm is called MiniMax. If you graphically depict a chain of calls, you get the so-called game tree:

Each node in this tree represents one analyzed move. A node score will be equal to the maximum score of its child nodes. The order in which the nodes will be analyzed is shown below (green - victory, red - defeat, yellow - draw):
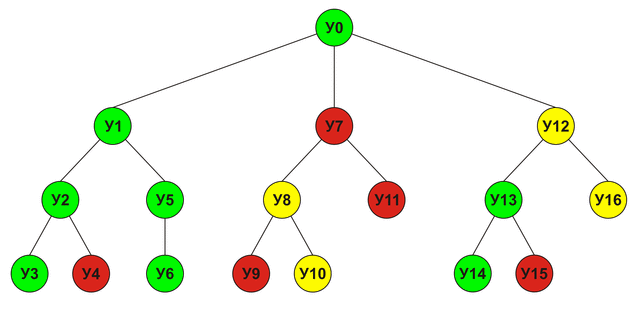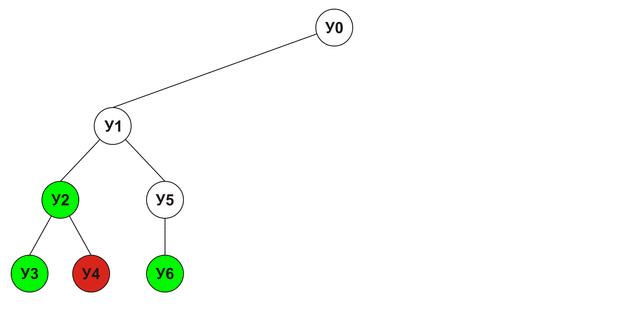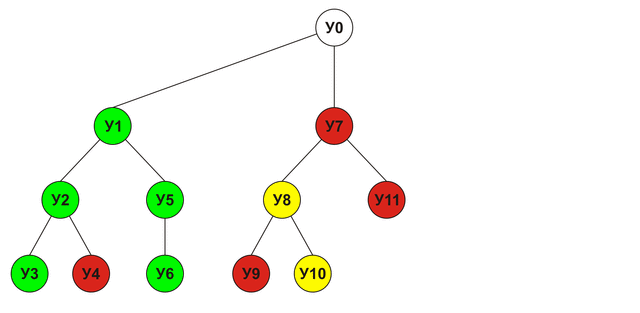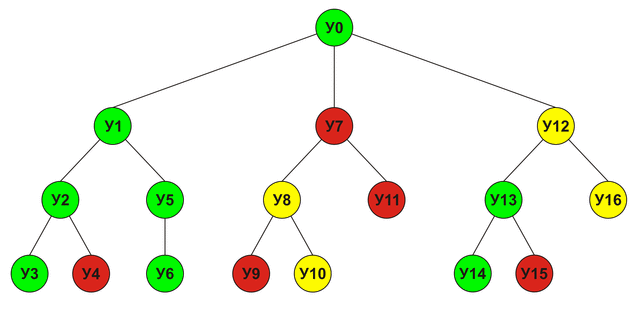
Alpha-Beta clipping
In the above example, in order to get the final score of the U0 node, I had to get estimates for all the other nodes U1-U16, but in fact this was not necessary: as soon as we found out that the node U1 leads to victory, the need to analyze the nodes U7- U16 disappears, because any estimates obtained for those nodes will not exceed the estimate of U1 (since it is maximum), which means that there is simply no better move than U1. Given this, the analyzed tree will look as follows:

Obviously, such a shortened analysis does not impair the accuracy of the solution, but significantly reduces the time it takes to find the best move. It is the idea of “pruning” unpromising tree branches that underlies the Alpha-Beta clipping algorithm.
When using cutoffs, two variables are additionally introduced: a minimum for sente (A) and a maximum for gote (B). The Alpha-Beta cutoff algorithm itself is similar to the MiniMax algorithm, except for the following points:
1. If the evaluation of any move falls outside the [A, B] range, the branch analysis can be stopped ahead of schedule, because players have moves leading to a better position.
An important point when using this algorithm is the order in which moves are viewed. If we first consider those moves that most narrow the range [A, B], then the number of cut branches will be quite large. Returning to the tree discussed above, it is easy to notice that the viewing order of U7, U12, U1 will give a much smaller performance gain. Therefore, before using cut-off algorithms, the moves are pre-sorted according to the expected efficiency.
Of course, it is impossible to know in advance which move will be the best, but there are some heuristic rules. For example, taking moves, checkers, moves that improve a position, etc. are considered good.
Position Evaluation Function
All the algorithms described above scan the game tree to the full depth, but it is practically impossible to implement such algorithms in practice, so the viewing depth is artificially limited: recursive calls are terminated not only in the case of mat and draws, but also when the maximum analysis depth is reached. Mats when viewing a tree to a limited depth are relatively rare, and all nematic positions have to be assigned some heuristic rating, for which the methods described below are used.
Material assessment
In most chess-like games, a very accurate position estimate is material evaluation. In this case, each figure is assigned a certain value, and the position estimate for the player is the difference between the sum of his pieces and the sum of the opponent’s figures. Shogi also uses material evaluation, a table of the cost of the figures is given below:

All figures in the hand are estimated at 30% more expensive, because their mobility due to the possibility of dumping increases significantly.
Some explanations require the high cost of the king and token. Such a high cost of the king is explained by the fact that the king is a figure of absolute importance, the party ends with his loss, therefore the king is valued more than all other pieces combined. And the cost of the token is so high, because the token is the best figure for exchanges: when exchanging a token-silver, one player receives in the hand of the silver general, and the second player turns out to be just a pawn.
Strategic evaluation
Before speaking about the importance of strategic evaluation, it is necessary to once again note the fact that the pieces never leave the game and all the pieces taken can return at any time. This fact fundamentally changes the approach to evaluating a position.
First, the heuristic of exchanges extremely effective in chess-like games becomes not only ineffective, but also harmful. If in chess you win one pawn and constantly go for equivalent exchanges, then in the endgame the advantage in one pawn often turns out to be decisive. In shogi, such exchanges can lead to the dumping of enemy figures in your camp.
Secondly, victims of shogi are very popular. For example, at the end of a game, you often have to give an older piece for a gold general or horse to get a piece in your hand that you can checkmate or make an effective fork.
If you look at what these two situations have in common, you can see that the enemy took advantage of the poor arrangement of your pieces. In such cases, it is customary to say that the figures have a “bad shape”. In shogi, the form is often more important than the material advantage, so the characteristics of the form must be evaluated when evaluating the position. The figures below show examples of bad and good forms (generals who are not protected by anything are highlighted in red):

Further development of the idea of “good forms” are fortresses - fortifications for the king, ensuring his safety and protecting him from shahs. Examples of common fortresses are given in the table:

It is clear that good forms should give a certain plus to the strategic evaluation, and bad forms, respectively, should worsen the evaluation, but in addition to the form, you must also take into account the control of the board, the proximity of the generals to your or enemy king, the presence of locked pieces, etc. ...
Summing up the above , it should be noted again that in the function of evaluating a position, it is necessary to take into account not only the material component, but also the strategic one.
Selective Renewal Algorithm The
already discussed MiniMax and Alpha-Beta cutoff algorithms always find the best move at a given depth, but the problem is that the analysis depth (8-10 moves) is insufficient for a strong game. Professionals calculate positions for 12-14 moves, and some positions for more than 20 moves. Such a depth for computers is unattainable.
Some compromise option is to view to a considerable depth only certain branches of the tree, while the remaining branches will be viewed to a reduced depth. This approach is called selective renewal.
In chess programs, chess usually prolongs, pawn moves to the last horizontal and strong captures. But in shogi, this approach is ineffective. It was decided to search without a fixed depth, increasing the depth step by step. Moreover, all possible moves can theoretically be considered at different depths, so you need to additionally remember the depth to which each move was considered.
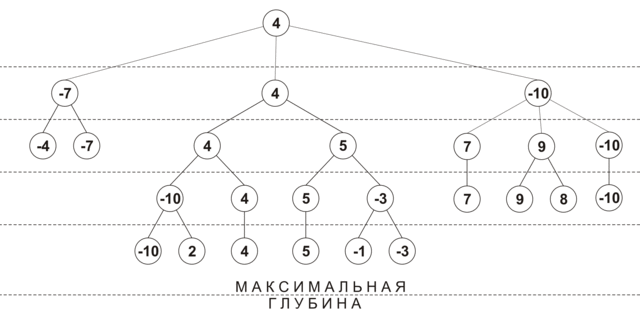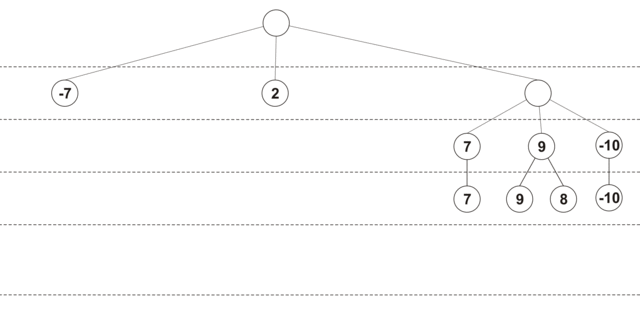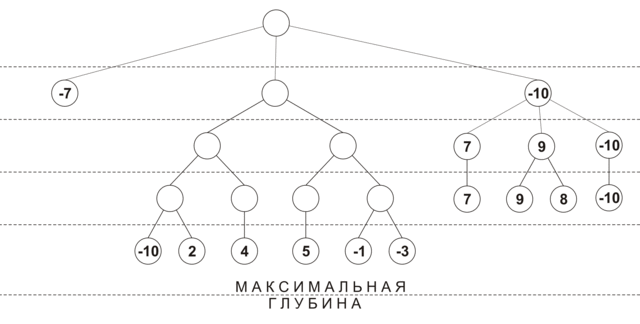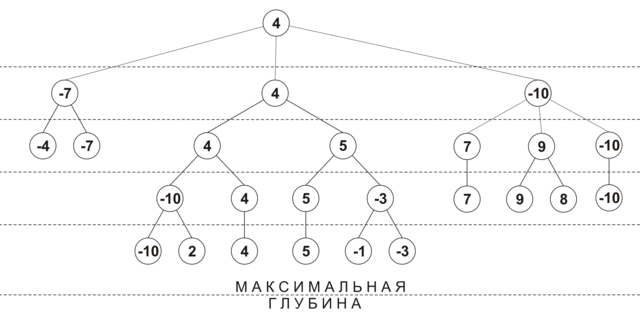
Initially, the depth of view of each move is 0, and the move score is -INF (i.e., loss). At the first iteration, a position analysis is performed at a depth of 1 for all moves, with each move receiving its own performance rating, and its viewing depth is increased by 1. Then all moves are sorted by efficiency, and the best moves are analyzed at a depth of 2. If during the next extension it turned out that the move with the maximum score has already been analyzed to the maximum depth, then this move is excluded from further consideration. The deepening process continues until all moves are viewed to the minimum depth. The figure below shows an approximate procedure for constructing a tree using selective extensions (maximum depth - 4, minimum depth - 2, the nodes show the estimated position at the current viewing depth):
An additional advantage of this algorithm is its effectiveness in time-limited games: when the time allotted for a move runs out, you can return the best of the calculated results.
Caching Caching
is known to be one of the most effective ways to improve program performance. In the context of building gaming algorithms, caching is used to search for already analyzed positions.
Indeed, during the search for the best move, some positions may be repeated within the same branch or occur in different branches of the tree. A classic algorithm would re-examine each such position. Such multiple calculations significantly reduce overall performance. Caching is designed to eliminate the need to perform repeated calculations.
The search for a position in the cache is based on comparing the hash functions of the position in question with the hash functions of the positions that have already hit the cache. A feature of most hash functions is the presence of collisions (situations where different input give the same value). For games, this behavior of hash functions is unacceptable, because even the smallest changes in position greatly affect the optimal move. Given the above, it was decided to use a string that uniquely describes the position as a hash function.
To use caching of results, the following changes must be made to the algorithm for finding the best move:
There is another pretty subtle point. If the cache already contains the desired position, calculated at a shallow depth, this result can also be used. Recall that the Alpha-Beta cutoff algorithm is very sensitive to the order of moves. Practice shows that an estimate obtained with a shallow rendering depth is a fairly high-quality heuristic assessment of the quality of the move. Those. values stored in the cache can be used to sort moves before calling Alpha-Beta cutoffs.
The effectiveness of using the cache can be estimated using the following graph, which shows the dependence of the depth of miscalculation of the position depending on the time and number of repeated calls.


The graph shows that using the cache significantly increases the rendering depth for repeated positions. For example, with a time limit of 5 seconds per turn, using a cache allows you to achieve the same analysis depth as a 100-second analysis without using a cache.
T.O. we can conclude that the use of caching significantly increases the speed of analysis, but requires significant memory costs for storing processed items.
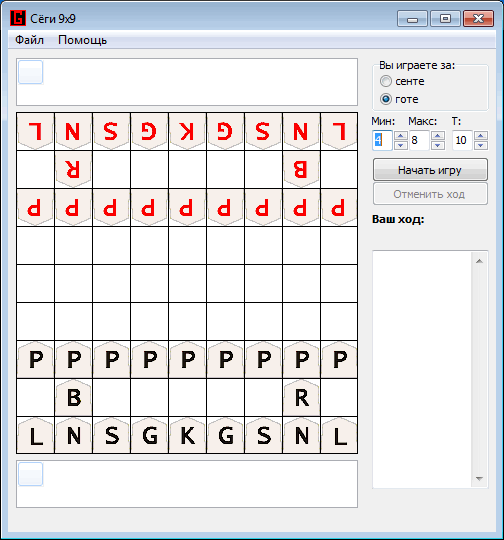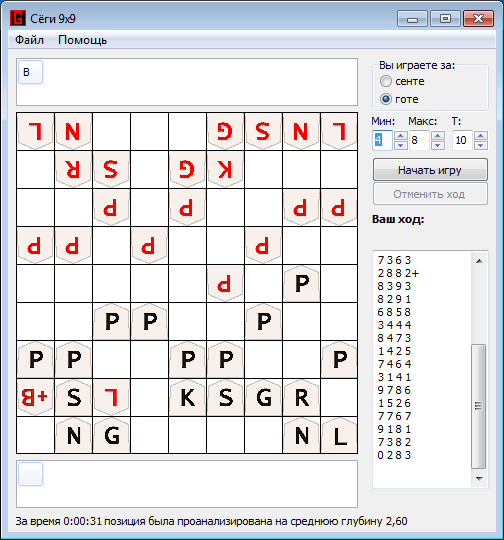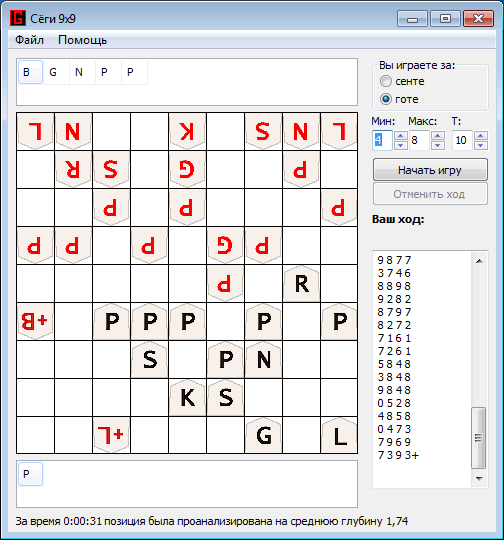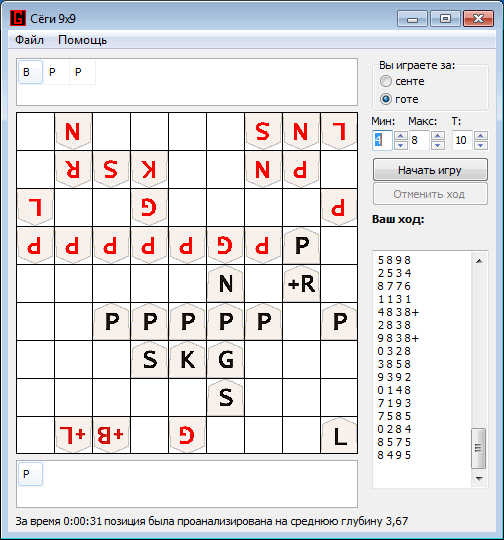
And as a conclusion, a small example of a game developed by the program against the Shogi Lvl program. 100:
Building programs that can play intellectual games is a very interesting task, which has great practical and scientific value.
The first attempts to create machines for playing intellectual games (primarily chess) appeared long before the advent of computers. Around 1769, the famous chess machine “mechanical Turk” appeared. The machine played very well, but its whole secret was a strong chess player hidden inside.
In the 20th century, mechanical machines gave way to digital computers. The pioneer in this field (as in many others) can be called the famous mathematician Alan Turing. By modern standards, the algorithm he developed was very primitive, and due to the lack of access to real computers, it was necessary to execute the algorithm manually.
Around the same time, Claude Shannon justified the existence of a better move for any position. He even proposed an algorithm for finding such a move for any game on the final board. Unfortunately, despite the existence of an optimal algorithm, its practical implementation is impossible due to limited hardware and time resources.
Since the time of Shannon, the task of programming intellectual games has moved from the field of entertainment to the field of serious research. In recent years, based on Shannon's research, practical algorithms have been built, with the help of which computers learned to play checkers accurately and achieved outstanding success in chess and go.
Japanese shogi chess is one of the few games where a person is still stronger than a computer. First of all, this is due to the possibility of returning the taken figures to the game, this rule sharply increases the number of possible moves, which means that it complicates the analysis of the game. If in chess you can make about 40 moves from an arbitrary position, then in shogi the number of possible moves is measured in hundreds.
Rules of the game
Before talking about building algorithms for playing shogi, you need to describe the rules of this game.
Shapes
There are 8 different figures in shogi (if you take into account the inverted figures, then 14). The rules of moves for various figures are presented in the table:
If you analyze the table, you can make the following observations:
- There are only two long-range figures in shogi: a boat and an elephant;
- The retreat possibilities of many figures are limited or completely absent.
These observations allow you to divide all the figures into four groups:
- A king of absolute value;
- Senior pieces (rook and bishop), capable of long-range attacks and a quick retreat;
- Generals (gold and silver), whose chances of advance far exceed the chances of retreat;
- Younger pieces (horse, arrow, pawn), not able to retreat.
Initial arrangement and sequence of moves
Two players play shogi, which are usually called sente (go first) and gote (go second), on a square board of 9x9 squares. The initial arrangement of the figures is shown in the figure:
Each player also has a special stand (team), where the figures taken from the opponent are placed. It is also customary to say that the figures taken are "in the hand."
Coups
The last three horizontals (relative to each player) are the coup zone. Any untapped piece (except gold and king) that starts or ends its move inside this zone can turn over and turn into another piece. The transformation rules are fixed and shown in the table:
It is important to note that the player decides whether to turn the piece over or not. Cases when a coup is necessary are described in the forbidden moves section.
Resets
The reset rule is what makes the shogi game one of the most difficult games humanity has ever invented. The essence of the rule is that any figure eaten by the enemy can be put on any free field as your own.
There are several limitations to the reset rule, but they are quite simple:
- All figures are discarded not upside down (even if they are discarded in the flip zone);
- You cannot drop a pawn on the vertical where there is already a pawn (a token is not considered a pawn);
- You cannot fold a pawn with a checkmate.
Forbidden moves
If the opponent has made a forbidden move, he will immediately be counted as a defeat, so it is extremely important to know the list of forbidden moves:
- Moves that violate the rules (for example, diagonalization of gold);
- Violation of the rules of reset (for example, resetting the second pawn to the vertical);
- A move, after which the piece cannot make a single move. This rule requires clarification. You cannot go on a pawn to the last horizontal without a coup or a horse to the last or penultimate horizontal without a coup. Obviously, it is impossible to discard figures in this way.
The situation with leaving the king under the check is not completely clear. If the player did not notice the check to his king, then the next move the opponent can (but does not have to) eat the king. In this case, the game is considered over.
End of the game
The game ends when one of the players has checked or made a forbidden move. But in shogi there are additional rules for ending the game:
- If the position was repeated three times as a result of a continuous series of checkers (the so-called “eternal check”), then for the fourth time the attacking player must make another move, otherwise he will be counted defeat.
- If the position was repeated 4 times without declaring a check, then the players replay the game without announcing the results, but with a color change for the remaining time.
The above rules make a draw extremely rare for shogi (no more than 3% of all games played). Nevertheless, a draw is possible in one case: if both kings entered the enemy camp and strengthened there. If both players agree that the situation is deadlock, then scoring is done. All pieces (including in the hand) except the king, elephant and rook are valued at 1 point, the elephant and rook - at 5 points, the king is not involved in the calculation.
In professional games, a player with less than 24 points loses, if both players have at least 24 points, then a draw is declared. In amateur games, the winner is the one with at least 27 points, if both players have 27 points, then the victory will be awarded to the gote.
Algorithm for finding the best move
MiniMax Algorithm
For the first time, the strategy for finding the best move for any given position was described by Claude Shannon. If you think a little, you can see that this strategy is quite simple and applicable to any game.
Let us have some position in which we need to make an optimal move. First you need to generate all the moves allowed by the rules. Then each of the correct moves must be evaluated. The moves leading to victory will be evaluated as +1, leading to defeat, as -1, and the moves leading to a draw will receive a score of 0.
In order to determine what result the considered move will lead us to, we must assume that the enemy will respond to our every move in the best possible way. Those. in fact, he will use the algorithm in question: he will generate all his correct moves and choose the best one among them, and to assess how good his move is, he will assume that we will respond in the best possible way, etc.
It turns out that in the search for the best move on our part, the procedure for finding the best answer from the opponent’s side will be called, from which the procedure for finding our best answer to the opponent’s response will be called, etc.
The search function for the best move will recursively call itself until a matte or draw situation occurs.
Moreover, the assessment of the final position is not difficult, and when evaluating the parent nodes use the following rules:
- The move score for the first player is calculated as the maximum score of the child nodes;
- The move score for the second player is calculated as a minimum of the score of the child nodes.
Such an algorithm is called MiniMax. If you graphically depict a chain of calls, you get the so-called game tree:
Each node in this tree represents one analyzed move. A node score will be equal to the maximum score of its child nodes. The order in which the nodes will be analyzed is shown below (green - victory, red - defeat, yellow - draw):
Alpha-Beta clipping
In the above example, in order to get the final score of the U0 node, I had to get estimates for all the other nodes U1-U16, but in fact this was not necessary: as soon as we found out that the node U1 leads to victory, the need to analyze the nodes U7- U16 disappears, because any estimates obtained for those nodes will not exceed the estimate of U1 (since it is maximum), which means that there is simply no better move than U1. Given this, the analyzed tree will look as follows:
Obviously, such a shortened analysis does not impair the accuracy of the solution, but significantly reduces the time it takes to find the best move. It is the idea of “pruning” unpromising tree branches that underlies the Alpha-Beta clipping algorithm.
When using cutoffs, two variables are additionally introduced: a minimum for sente (A) and a maximum for gote (B). The Alpha-Beta cutoff algorithm itself is similar to the MiniMax algorithm, except for the following points:
1. If the evaluation of any move falls outside the [A, B] range, the branch analysis can be stopped ahead of schedule, because players have moves leading to a better position.
- If at any moment the score of the first player becomes greater than A, then the value of A is updated;
- The same goes for a score of B for the second player.
An important point when using this algorithm is the order in which moves are viewed. If we first consider those moves that most narrow the range [A, B], then the number of cut branches will be quite large. Returning to the tree discussed above, it is easy to notice that the viewing order of U7, U12, U1 will give a much smaller performance gain. Therefore, before using cut-off algorithms, the moves are pre-sorted according to the expected efficiency.
Of course, it is impossible to know in advance which move will be the best, but there are some heuristic rules. For example, taking moves, checkers, moves that improve a position, etc. are considered good.
Position Evaluation Function
All the algorithms described above scan the game tree to the full depth, but it is practically impossible to implement such algorithms in practice, so the viewing depth is artificially limited: recursive calls are terminated not only in the case of mat and draws, but also when the maximum analysis depth is reached. Mats when viewing a tree to a limited depth are relatively rare, and all nematic positions have to be assigned some heuristic rating, for which the methods described below are used.
Material assessment
In most chess-like games, a very accurate position estimate is material evaluation. In this case, each figure is assigned a certain value, and the position estimate for the player is the difference between the sum of his pieces and the sum of the opponent’s figures. Shogi also uses material evaluation, a table of the cost of the figures is given below:
All figures in the hand are estimated at 30% more expensive, because their mobility due to the possibility of dumping increases significantly.
Some explanations require the high cost of the king and token. Such a high cost of the king is explained by the fact that the king is a figure of absolute importance, the party ends with his loss, therefore the king is valued more than all other pieces combined. And the cost of the token is so high, because the token is the best figure for exchanges: when exchanging a token-silver, one player receives in the hand of the silver general, and the second player turns out to be just a pawn.
Strategic evaluation
Before speaking about the importance of strategic evaluation, it is necessary to once again note the fact that the pieces never leave the game and all the pieces taken can return at any time. This fact fundamentally changes the approach to evaluating a position.
First, the heuristic of exchanges extremely effective in chess-like games becomes not only ineffective, but also harmful. If in chess you win one pawn and constantly go for equivalent exchanges, then in the endgame the advantage in one pawn often turns out to be decisive. In shogi, such exchanges can lead to the dumping of enemy figures in your camp.
Secondly, victims of shogi are very popular. For example, at the end of a game, you often have to give an older piece for a gold general or horse to get a piece in your hand that you can checkmate or make an effective fork.
If you look at what these two situations have in common, you can see that the enemy took advantage of the poor arrangement of your pieces. In such cases, it is customary to say that the figures have a “bad shape”. In shogi, the form is often more important than the material advantage, so the characteristics of the form must be evaluated when evaluating the position. The figures below show examples of bad and good forms (generals who are not protected by anything are highlighted in red):
Further development of the idea of “good forms” are fortresses - fortifications for the king, ensuring his safety and protecting him from shahs. Examples of common fortresses are given in the table:
It is clear that good forms should give a certain plus to the strategic evaluation, and bad forms, respectively, should worsen the evaluation, but in addition to the form, you must also take into account the control of the board, the proximity of the generals to your or enemy king, the presence of locked pieces, etc. ...
Summing up the above , it should be noted again that in the function of evaluating a position, it is necessary to take into account not only the material component, but also the strategic one.
Selective Renewal Algorithm The
already discussed MiniMax and Alpha-Beta cutoff algorithms always find the best move at a given depth, but the problem is that the analysis depth (8-10 moves) is insufficient for a strong game. Professionals calculate positions for 12-14 moves, and some positions for more than 20 moves. Such a depth for computers is unattainable.
Some compromise option is to view to a considerable depth only certain branches of the tree, while the remaining branches will be viewed to a reduced depth. This approach is called selective renewal.
In chess programs, chess usually prolongs, pawn moves to the last horizontal and strong captures. But in shogi, this approach is ineffective. It was decided to search without a fixed depth, increasing the depth step by step. Moreover, all possible moves can theoretically be considered at different depths, so you need to additionally remember the depth to which each move was considered.
Initially, the depth of view of each move is 0, and the move score is -INF (i.e., loss). At the first iteration, a position analysis is performed at a depth of 1 for all moves, with each move receiving its own performance rating, and its viewing depth is increased by 1. Then all moves are sorted by efficiency, and the best moves are analyzed at a depth of 2. If during the next extension it turned out that the move with the maximum score has already been analyzed to the maximum depth, then this move is excluded from further consideration. The deepening process continues until all moves are viewed to the minimum depth. The figure below shows an approximate procedure for constructing a tree using selective extensions (maximum depth - 4, minimum depth - 2, the nodes show the estimated position at the current viewing depth):
An additional advantage of this algorithm is its effectiveness in time-limited games: when the time allotted for a move runs out, you can return the best of the calculated results.
Caching Caching
is known to be one of the most effective ways to improve program performance. In the context of building gaming algorithms, caching is used to search for already analyzed positions.
Indeed, during the search for the best move, some positions may be repeated within the same branch or occur in different branches of the tree. A classic algorithm would re-examine each such position. Such multiple calculations significantly reduce overall performance. Caching is designed to eliminate the need to perform repeated calculations.
The search for a position in the cache is based on comparing the hash functions of the position in question with the hash functions of the positions that have already hit the cache. A feature of most hash functions is the presence of collisions (situations where different input give the same value). For games, this behavior of hash functions is unacceptable, because even the smallest changes in position greatly affect the optimal move. Given the above, it was decided to use a string that uniquely describes the position as a hash function.
To use caching of results, the following changes must be made to the algorithm for finding the best move:
- Before miscalculation, check the availability of a position in the cache;
- If the position is in the cache, then stop the calculation and return the previously received value;
- At the end of the miscalculation, write the result to the cache;
There is another pretty subtle point. If the cache already contains the desired position, calculated at a shallow depth, this result can also be used. Recall that the Alpha-Beta cutoff algorithm is very sensitive to the order of moves. Practice shows that an estimate obtained with a shallow rendering depth is a fairly high-quality heuristic assessment of the quality of the move. Those. values stored in the cache can be used to sort moves before calling Alpha-Beta cutoffs.
The effectiveness of using the cache can be estimated using the following graph, which shows the dependence of the depth of miscalculation of the position depending on the time and number of repeated calls.
The graph shows that using the cache significantly increases the rendering depth for repeated positions. For example, with a time limit of 5 seconds per turn, using a cache allows you to achieve the same analysis depth as a 100-second analysis without using a cache.
T.O. we can conclude that the use of caching significantly increases the speed of analysis, but requires significant memory costs for storing processed items.
And as a conclusion, a small example of a game developed by the program against the Shogi Lvl program. 100: