Thinning timeframes (cryptocurrency, forex, stock exchange)
Some time ago, I was tasked to write a procedure that performs thinning out the Forex market quotes (more precisely, timeframe data).
Task statement: data is sent to the input at 1 second intervals in this format:
It is necessary to provide recalculation and synchronization of data in the tables: 5 seconds, 15 seconds, 1 minute, 5 minutes, 15 minutes, etc.
The described data storage format is called OHLC, or OHLCV (Open, High, Low, Close, Volume). It is often used, and it is immediately possible to construct the “Japanese Candles” graph.
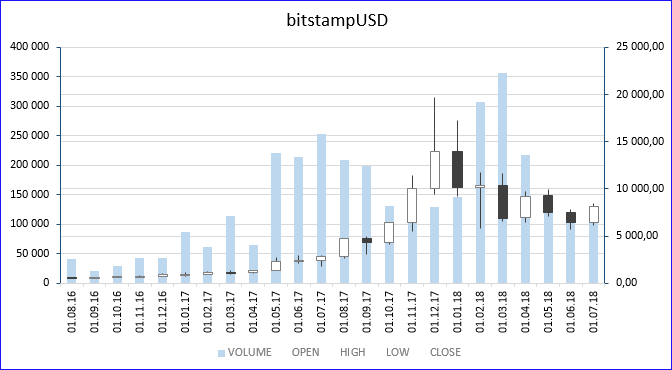
Under the cut, I described all the options that I could think of, how to thin out (enlarge) the obtained data, for analyzing, for example, the winter jump in Bitcoin prices, and from the data obtained, you immediately build the “Japanese Candles” chart (in MS Excel, too) ). In the picture above, this graph is built for the 1 month timeframe, for the “bitstampUSD” tool. The white body of the candle means a rise in price in the interval, black - a decrease in price, the upper and lower wicks mean the maximum and minimum prices that were reached in the interval. Background - the volume of transactions. It is clearly seen that in December 2017, the price came close to the 20K mark.
The solution will be given for the two database engines, for Oracle and MS SQL, which, in some way, will make it possible to compare them on this particular task (we will not generalize the comparison to other tasks).
Then I solved the problem in a trivial way: calculating the correct thinning into a temporary table and synchronizing with the target table — deleting rows that exist in the target table but do not exist in the temporary table and adding rows that exist in the temporary table but do not exist in the target table. At that time, the Customer was satisfied with the decision, and I closed the task.
But now I decided to consider all the options, because the above solution contains one feature - it is difficult to optimize it for two cases at once:
This is due to the fact that the procedure will have to connect the target table and the temporary table, and you need to join to the larger one, and not vice versa. In the above two cases, the larger / smaller are swapped. The optimizer will decide on the join order based on statistics, and the statistics may be outdated, and the decision may be made wrong, leading to significant performance degradation.
In this article I will describe the methods of one-time thinning, which can be useful for readers to analyze, for example, the winter jump in the price of Bitcoin.
Procedures for online thinning can be downloaded from github via the link at the bottom of the article.
To the point ... My task concerned thinning from the 1 sec timeframe to the following, but here I consider thinning from the transaction level (in the source table, the fields STOCK_NAME, UT, ID, APRICE, AVOLUME). Because such data gives the site bitcoincharts.com.
Actually, thinning from the transaction level to the “1 second” level is performed by such a command (the operator is easily translated into thinning from the “1 second” level to the upper levels):
On Oracle:
The avg () keep (dense_rank first order by UT, ID) function works like this: since the query is grouped by GROUP BY, each group is calculated independently of the others. Within each group, the rows are sorted by UT and ID, numbered by the function dense_rank . Since next is the function first, then the line is selected where dense_rank returned 1 (in other words, the minimum is chosen) —the first transaction is selected within the interval. For this minimum UT, ID, if there were several lines, it would be considered average. But in our case there will be guaranteed one line (due to the uniqueness of the ID), so the resulting value is immediately returned as AOPEN. It is easy to see that the first function replaces the two aggregate.
On MS SQL
There are no first / last functions (there is first_value / last_value , but this is not the case). Therefore, you have to connect the table with itself.
I will not give the request separately, but it can be viewed below in the dbo.THINNING_HABR_CALC procedure . Of course, without first / last, it is not so elegant, but it will work.
How can this problem be solved by one operator? (Here, the term “one operator” means not that the operator will be one, but that there will be no cycles “pulling” the data on one line.)
I will list all the solutions to this problem that I know:
Looking ahead to say that this is the rare case when the procedural solution PPTF is the most effective on Oracle.
Download transaction files from http://api.bitcoincharts.com/v1/csv
I recommend selecting kraken * files. Files localbtc * are very noisy - they contain distracting lines with unrealistic prices. All kraken * contain about 31M transactions, I recommend to exclude krakenEUR from there, then the transaction becomes 11M. This is the most convenient volume for testing.
Run the script in Powershell to generate control files for SQLLDR for Oracle and to generate an import request for MSSQL.
Create a transaction table on Oracle.
On Oracle, launch the LoadData-Oracle.bat file , having previously corrected the connection parameters at the beginning of the Powershell script.
I work in a virtual machine. Downloading all 11M transaction files in 8 kraken * files (I missed the EUR file) took about 1 minute.
And create functions that will truncate dates to the boundaries of the intervals:
Consider the options. First, the code for all the options is provided, then scripts for launching and testing. First, the task is described for Oracle, then for MS SQL
The whole set of transactions is multiplied by a Cartesian product into a set of 10 lines with numbers from 1 to 10. This is necessary to get 10 lines with dates truncated to the boundaries of 10 intervals from a single transaction line.
After that, the lines are grouped by interval number and truncated date, and the above query is executed.
Create a VIEW:
In this embodiment, we iteratively thin out from transactions to level 1, from level 1 to level 2, and so on.
Create a table:
You can create an index on the STRIPE_ID field, but it has been experimentally established that in the 11M volume of transactions without an index it turns out more profitable. When used on lshih numbers could change. And you can partition a table by uncommenting a block in a query.
Create a procedure:
For symmetry, create a simple VIEW:
The method is brutal straightforward approach, and is to abandon the principle of "Do not repeat yourself." In this case, the rejection of cycles.
A variant is given here only for completeness.
Looking ahead, I will say that in terms of performance on this particular task, it ranks second.
The variant with the User Defined Aggregated Function will not be given here, but it can be viewed on github.
Create a function (in the package):
Create a VIEW:
The variant iteratively calculates thinning for all 10 levels by using the MODEL clause clause with the phrase ITERATE .
The option is also impractical because it turns out to be slow. In my environment, 1000 transactions on 8 instruments are calculated for 1 minute. Most of the time is spent on calculating the phrase MODEL .
Here I give this option only for completeness and as confirmation of the fact that almost all complex calculations on Oracle can be performed in one query, without using PL / SQL.
One of the reasons for the poor performance of the MODEL phrase in this query is that the search by the criteria on the right is made for eachthe rules that we have 6. The first two rules are calculated fairly quickly, because there is a direct explicit addressing, without jokers. In the other four rules there is the word any - there calculations are made more slowly.
The second difficulty is that the reference model has to be calculated. It is needed because the dimension list must be known before calculating the MODEL phrase ; we cannot calculate new dimensions inside this phrase. Perhaps this can be bypassed with the help of two MODEL phrases, but I did not do this because of the poor performance of a large number of rules.
I ’ll add that you could not count UT_OPEN and UT_CLOSE in the reference model, but use the same functionsavg () keep (dense_rank first / last order by) directly in the MODEL phrase . But it would have been even slower.
Due to performance limitations, I will not include this option in the testing procedure.
The query described below would potentially be the most efficient and consume a quantity of resources equal to the theoretical minimum.
But neither Oracle nor MS SQL allow you to write a query in this form. I guess this is dictated by the standard.
This query corresponds to the following part of the Oracle documentation:
If a subquery_factoring_clause refers to a subquery_factoring_clause. A recursive subquery_factoring_clause must contain two query blocks. Cannot be referenced reference_name. UNION ALL, UNION, INTERSECT or MINUS. The recursive member must follow query_name exactly once. You must combine the recursive member with the anchor member using the UNION ALL set operator.
But contrary to the following paragraph of the documentation:
CAN recursive member of The not the contain the any of the the following elements:
of The the DISTINCT keyword or the GROUP BY clause a clause
of An the aggregate function. However, analytic functions are permitted in the select list.
Thus, in a recursive member, aggregates and grouping are not allowed.
Let's spend at first for Oracle .
Perform the calculation procedure for the CALC method and write down the execution time:
The calculation results for the four methods are in four views:
The execution time for all methods has already been measured by me and is shown in the table at the end of the article.
For the rest of VIEW, we will execute queries and record the execution time:
where XXXX is SIMP, CHIN, PPTF.
These VIEW count set digest. To calculate the digest, you need to fetch all the strings, and with the help of the digest you can compare the sets with each other.
You can also compare sets using the dbms_sqlhash package, but this is much slower, because the initial set is required to be sorted, and the calculation of the hash is not fast.
Also in 12c there is a DBMS_COMPARISON package.
You can simultaneously check the correctness of all algorithms. We calculate the digests with such a request (with 11M records on a virtual machine, it will be relatively long, about 15 minutes):
We see that the digests are the same, so all the algorithms gave the same results.
Now let's reproduce the same thing on MS SQL . I tested on version 2016.
Pre-create a DBTEST database, then create a transaction table in it:
Download the downloaded data.
In MSSQL, create a file format_mssql.bcp:
And run the LoadData-MSSQL.sql script in SSMS (this script was generated by a single powershell script given in the section of this article for Oracle).
Create two functions:
Let's start implementing options:
Run:
The missing first / last functions are implemented by double self-joining tables.
Create a table, procedure and view:
Options 3 (CHIN) and 4 (UDAF) I did not implement in MS SQL.
Create a table function and view. This function is just a tablespace, not a parallel pipelined table function, just the variant retained its historical name from Oracle:
Perform the calculation of the table QUOTES_CALC for the CALC method and record the execution time:
The calculation results for the three methods are in three views:
For two VIEWs, execute the queries and write the execution time:
where XXXX is SIMP, PPTF.
Now you can compare the calculation results for the three methods for MS SQL. This can be done in one request. Run:
If the three lines coincide in all fields - the result of the calculation for the three methods is identical.
I strongly advise at the testing stage to use a small sample, because the performance of this task on MS SQL is low.
If you have only the MS SQL engine, and you want to calculate a larger amount of data, then you can try the following optimization method: you can create indices:
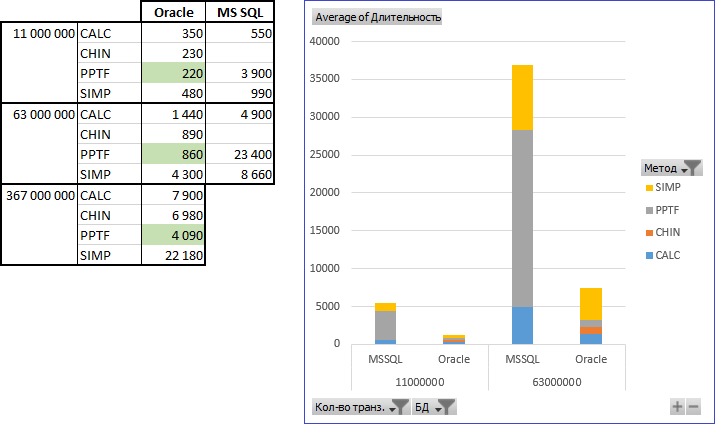
The performance measurement results in my virtual machine are as follows:
Scripts can be downloaded from github : Oracle, the THINNING schema — the scripts of this article, the THINNING_LIVE schema — online data download from bitcoincharts.com and online thinning (but this site provides data in the online mode for the last 5 days only), and the script for MS SQL also for this article.
Conclusion:
This task is solved faster on Oracle than on MS SQL. As the number of transactions grows, the gap becomes more significant.
On Oracle, the best option was PPTF. Here the procedural approach turned out to be more profitable, this happens infrequently. The remaining methods also showed an acceptable result - I even tested the volume of 367M transactions on a virtual machine (the PPTF method calculated thinning in an hour and a half).
On MS SQL, the iterative calculation method (CALC) turned out to be the most productive.
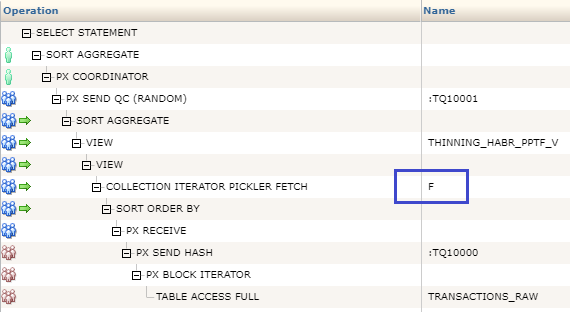
Why is the PPTF method on Oracle turned out to be the leader? Due to parallel execution and because of the architecture, a function that is created as a parallel pipelined table function is built into the middle of the query plan:
Task statement: data is sent to the input at 1 second intervals in this format:
- Instrument name (USDEUR pair code, etc.),
- Date and time in unix time format,
- Open value (price of the first transaction in the interval),
- High value (maximum price)
- Low value (minimum price)
- Close value (last transaction price),
- Volume (volume, or volume of the transaction).
It is necessary to provide recalculation and synchronization of data in the tables: 5 seconds, 15 seconds, 1 minute, 5 minutes, 15 minutes, etc.
The described data storage format is called OHLC, or OHLCV (Open, High, Low, Close, Volume). It is often used, and it is immediately possible to construct the “Japanese Candles” graph.
Under the cut, I described all the options that I could think of, how to thin out (enlarge) the obtained data, for analyzing, for example, the winter jump in Bitcoin prices, and from the data obtained, you immediately build the “Japanese Candles” chart (in MS Excel, too) ). In the picture above, this graph is built for the 1 month timeframe, for the “bitstampUSD” tool. The white body of the candle means a rise in price in the interval, black - a decrease in price, the upper and lower wicks mean the maximum and minimum prices that were reached in the interval. Background - the volume of transactions. It is clearly seen that in December 2017, the price came close to the 20K mark.
The solution will be given for the two database engines, for Oracle and MS SQL, which, in some way, will make it possible to compare them on this particular task (we will not generalize the comparison to other tasks).
Then I solved the problem in a trivial way: calculating the correct thinning into a temporary table and synchronizing with the target table — deleting rows that exist in the target table but do not exist in the temporary table and adding rows that exist in the temporary table but do not exist in the target table. At that time, the Customer was satisfied with the decision, and I closed the task.
But now I decided to consider all the options, because the above solution contains one feature - it is difficult to optimize it for two cases at once:
- when the target table is empty and you need to add a lot of data,
- and when the target table is large, and you need to add data in small chunks.
This is due to the fact that the procedure will have to connect the target table and the temporary table, and you need to join to the larger one, and not vice versa. In the above two cases, the larger / smaller are swapped. The optimizer will decide on the join order based on statistics, and the statistics may be outdated, and the decision may be made wrong, leading to significant performance degradation.
In this article I will describe the methods of one-time thinning, which can be useful for readers to analyze, for example, the winter jump in the price of Bitcoin.
Procedures for online thinning can be downloaded from github via the link at the bottom of the article.
To the point ... My task concerned thinning from the 1 sec timeframe to the following, but here I consider thinning from the transaction level (in the source table, the fields STOCK_NAME, UT, ID, APRICE, AVOLUME). Because such data gives the site bitcoincharts.com.
Actually, thinning from the transaction level to the “1 second” level is performed by such a command (the operator is easily translated into thinning from the “1 second” level to the upper levels):
On Oracle:
select1as STRIPE_ID
, STOCK_NAME
, TRUNC_UT (UT, 1) as UT
, avg (APRICE) keep (dense_rankfirstorderby UT, ID) as AOPEN
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, avg (APRICE) keep (dense_ranklastorderby UT, ID) as ACLOSE
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
groupby STOCK_NAME, TRUNC_UT (UT, 1);
The avg () keep (dense_rank first order by UT, ID) function works like this: since the query is grouped by GROUP BY, each group is calculated independently of the others. Within each group, the rows are sorted by UT and ID, numbered by the function dense_rank . Since next is the function first, then the line is selected where dense_rank returned 1 (in other words, the minimum is chosen) —the first transaction is selected within the interval. For this minimum UT, ID, if there were several lines, it would be considered average. But in our case there will be guaranteed one line (due to the uniqueness of the ID), so the resulting value is immediately returned as AOPEN. It is easy to see that the first function replaces the two aggregate.
On MS SQL
There are no first / last functions (there is first_value / last_value , but this is not the case). Therefore, you have to connect the table with itself.
I will not give the request separately, but it can be viewed below in the dbo.THINNING_HABR_CALC procedure . Of course, without first / last, it is not so elegant, but it will work.
How can this problem be solved by one operator? (Here, the term “one operator” means not that the operator will be one, but that there will be no cycles “pulling” the data on one line.)
I will list all the solutions to this problem that I know:
- SIMP (simple, simple, Cartesian product),
- CALC (calculate, iterative thinning of upper levels),
- CHIN (china way, cumbersome request for all levels at once),
- UDAF (user-defined aggregate function),
- PPTF (pipelined and parallel table function, procedural solution, but with only two cursors, in fact, two SQL statements),
- MODE (model, MODEL phrase),
- and IDEA (ideal, the ideal solution that cannot work now).
Looking ahead to say that this is the rare case when the procedural solution PPTF is the most effective on Oracle.
Download transaction files from http://api.bitcoincharts.com/v1/csv
I recommend selecting kraken * files. Files localbtc * are very noisy - they contain distracting lines with unrealistic prices. All kraken * contain about 31M transactions, I recommend to exclude krakenEUR from there, then the transaction becomes 11M. This is the most convenient volume for testing.
Run the script in Powershell to generate control files for SQLLDR for Oracle and to generate an import request for MSSQL.
# MODIFY PARAMETERS THERE$OracleConnectString = "THINNING/aaa@P-ORA11/ORCL"# For Oracle$PathToCSV = "Z:\10"# without trailing slash$filenames = Get-ChildItem -name *.csv
Remove-Item *.ctl -ErrorAction SilentlyContinue
Remove-Item *.log -ErrorAction SilentlyContinue
Remove-Item *.bad -ErrorAction SilentlyContinue
Remove-Item *.dsc -ErrorAction SilentlyContinue
Remove-Item LoadData-Oracle.bat -ErrorAction SilentlyContinue
Remove-Item LoadData-MSSQL.sql -ErrorAction SilentlyContinue
ForEach ($FilenameExtin$Filenames)
{
Write-Host "Processing file: "$FilenameExt$StockName = $FilenameExt.substring(1, $FilenameExt.Length-5)
$FilenameCtl = '.'+$Stockname+'.ctl'
Add-Content -Path $FilenameCtl -Value "OPTIONS (DIRECT=TRUE, PARALLEL=FALSE, ROWS=1000000, SKIP_INDEX_MAINTENANCE=Y)"
Add-Content -Path $FilenameCtl -Value "UNRECOVERABLE"
Add-Content -Path $FilenameCtl -Value "LOAD DATA"
Add-Content -Path $FilenameCtl -Value "INFILE '.$StockName.csv'"
Add-Content -Path $FilenameCtl -Value "BADFILE '.$StockName.bad'"
Add-Content -Path $FilenameCtl -Value "DISCARDFILE '.$StockName.dsc'"
Add-Content -Path $FilenameCtl -Value "INTO TABLE TRANSACTIONS_RAW"
Add-Content -Path $FilenameCtl -Value "APPEND"
Add-Content -Path $FilenameCtl -Value "FIELDS TERMINATED BY ','"
Add-Content -Path $FilenameCtl -Value "(ID SEQUENCE (0), STOCK_NAME constant '$StockName', UT, APRICE, AVOLUME)"
Add-Content -Path LoadData-Oracle.bat -Value "sqlldr $OracleConnectString control=$FilenameCtl"
Add-Content -Path LoadData-MSSQL.sql -Value "insert into TRANSACTIONS_RAW (STOCK_NAME, UT, APRICE, AVOLUME)"
Add-Content -Path LoadData-MSSQL.sql -Value "select '$StockName' as STOCK_NAME, UT, APRICE, AVOLUME"
Add-Content -Path LoadData-MSSQL.sql -Value "from openrowset (bulk '$PathToCSV\$FilenameExt', formatfile = '$PathToCSV\format_mssql.bcp') as T1;"
Add-Content -Path LoadData-MSSQL.sql -Value ""
}
Create a transaction table on Oracle.
createtable TRANSACTIONS_RAW (
IDnumbernotnull
, STOCK_NAME varchar2 (32)
, UT numbernotnull
, APRICE numbernotnull
, AVOLUME numbernotnull)
pctfree 0parallel4 nologging;
On Oracle, launch the LoadData-Oracle.bat file , having previously corrected the connection parameters at the beginning of the Powershell script.
I work in a virtual machine. Downloading all 11M transaction files in 8 kraken * files (I missed the EUR file) took about 1 minute.
And create functions that will truncate dates to the boundaries of the intervals:
createorreplacefunction TRUNC_UT (p_UT number, p_StripeTypeId number)
returnnumberdeterministicisbeginreturncase p_StripeTypeId
when1then trunc (p_UT / 1) * 1when2then trunc (p_UT / 10) * 10when3then trunc (p_UT / 60) * 60when4then trunc (p_UT / 600) * 600when5then trunc (p_UT / 3600) * 3600when6then trunc (p_UT / ( 4 * 3600)) * ( 4 * 3600)
when7then trunc (p_UT / (24 * 3600)) * (24 * 3600)
when8then trunc ((trunc (date'1970-01-01' + p_UT / 86400, 'Month') - date'1970-01-01') * 86400)
when9then trunc ((trunc (date'1970-01-01' + p_UT / 86400, 'year') - date'1970-01-01') * 86400)
when10then0when11then0end;
end;
createorreplacefunction UT2DATESTR (p_UT number) return varchar2 deterministicisbeginreturn to_char (date'1970-01-01' + p_UT / 86400, 'YYYY.MM.DD HH24:MI:SS');
end;
Consider the options. First, the code for all the options is provided, then scripts for launching and testing. First, the task is described for Oracle, then for MS SQL
Option 1 - SIMP (Trivial)
The whole set of transactions is multiplied by a Cartesian product into a set of 10 lines with numbers from 1 to 10. This is necessary to get 10 lines with dates truncated to the boundaries of 10 intervals from a single transaction line.
After that, the lines are grouped by interval number and truncated date, and the above query is executed.
Create a VIEW:
createorreplaceview THINNING_HABR_SIMP_V asselect STRIPE_ID
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID) as UT
, avg (APRICE) keep (dense_rankfirstorderby UT, ID) as AOPEN
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, avg (APRICE) keep (dense_ranklastorderby UT, ID) as ACLOSE
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
, (selectrownumas STRIPE_ID from dual connectbylevel <= 10)
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID);
Option 2 - CALC (calculated iteratively)
In this embodiment, we iteratively thin out from transactions to level 1, from level 1 to level 2, and so on.
Create a table:
createtable QUOTES_CALC (
STRIPE_ID numbernotnull
, STOCK_NAME varchar2 (128) notnull
, UT numbernotnull
, AOPEN numbernotnull
, AHIGH numbernotnull
, ALOW numbernotnull
, ACLOSE numbernotnull
, AVOLUME numbernotnull
, AAMOUNT numbernotnull
, ACOUNT numbernotnull
)
/*partition by list (STRIPE_ID) (
partition P01 values (1)
, partition P02 values (2)
, partition P03 values (3)
, partition P04 values (4)
, partition P05 values (5)
, partition P06 values (6)
, partition P07 values (7)
, partition P08 values (8)
, partition P09 values (9)
, partition P10 values (10)
)*/parallel4 pctfree 0 nologging;
You can create an index on the STRIPE_ID field, but it has been experimentally established that in the 11M volume of transactions without an index it turns out more profitable. When used on lshih numbers could change. And you can partition a table by uncommenting a block in a query.
Create a procedure:
createorreplaceprocedure THINNING_HABR_CALC_T isbeginrollback;
executeimmediate'truncate table QUOTES_CALC';
insert--+ appendinto QUOTES_CALC
select1as STRIPE_ID
, STOCK_NAME
, UT
, avg (APRICE) keep (dense_rankfirstorderbyID)
, max (APRICE)
, min (APRICE)
, avg (APRICE) keep (dense_ranklastorderbyID)
, sum (AVOLUME)
, sum (APRICE * AVOLUME)
, count (*)
from TRANSACTIONS_RAW a
groupby STOCK_NAME, UT;
commit;
for i in 1..9
loop
insert--+ appendinto QUOTES_CALC
select--+ parallel(4)
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, i + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from QUOTES_CALC a
where STRIPE_ID = i
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, i + 1);
commit;
endloop;
end;
/
For symmetry, create a simple VIEW:
createview THINNING_HABR_CALC_V asselect * from QUOTES_CALC;
Option 3 - CHIN (Chinese code)
The method is brutal straightforward approach, and is to abandon the principle of "Do not repeat yourself." In this case, the rejection of cycles.
A variant is given here only for completeness.
Looking ahead, I will say that in terms of performance on this particular task, it ranks second.
Big request
createorreplaceview THINNING_HABR_CHIN_V aswith
T01 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select1
, STOCK_NAME
, UT
, avg (APRICE) keep (dense_rankfirstorderbyID)
, max (APRICE)
, min (APRICE)
, avg (APRICE) keep (dense_ranklastorderbyID)
, sum (AVOLUME)
, sum (APRICE * AVOLUME)
, count (*)
from TRANSACTIONS_RAW
groupby STOCK_NAME, UT)
, T02 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T01
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T03 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T02
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T04 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T03
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T05 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T04
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T06 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T05
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T07 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T06
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T08 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T07
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T09 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T08
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T10 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T09
groupby STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
select * from T01 union all
select * from T02 union all
select * from T03 union all
select * from T04 union all
select * from T05 union all
select * from T06 union all
select * from T07 union all
select * from T08 union all
select * from T09 union all
select * from T10;
Option 4 - UDAF
The variant with the User Defined Aggregated Function will not be given here, but it can be viewed on github.
Option 5 - PPTF (Pipelined and Parallel table function)
Create a function (in the package):
createorreplacepackage THINNING_PPTF_P istype TRANSACTION_RECORD_T isrecord (STOCK_NAME varchar2(128), UT number, SEQ_NUM number, APRICE number, AVOLUME number);
type CUR_RECORD_T is ref cursor return TRANSACTION_RECORD_T;
type QUOTE_T
is record (STRIPE_ID number, STOCK_NAME varchar2(128), UT number
, AOPEN number, AHIGH number, ALOW number, ACLOSE number, AVOLUME number
, AAMOUNT number, ACOUNT number);
type QUOTE_LIST_T is table of QUOTE_T;
function F (p_cursor CUR_RECORD_T) return QUOTE_LIST_T
pipelined order p_cursor by (STOCK_NAME, UT, SEQ_NUM)
parallel_enable (partition p_cursor by hash (STOCK_NAME));
end;
/
createorreplacepackagebody THINNING_PPTF_P isfunction F (p_cursor CUR_RECORD_T) return QUOTE_LIST_T
pipelinedorder p_cursor by (STOCK_NAME, UT, SEQ_NUM)
parallel_enable (partition p_cursor byhash (STOCK_NAME))
is
QuoteTail QUOTE_LIST_T := QUOTE_LIST_T() ;
rec TRANSACTION_RECORD_T;
rec_prev TRANSACTION_RECORD_T;
type ut_T is table of number index by pls_integer;
ut number;
begin
QuoteTail.extend(10);
loop
fetch p_cursor into rec;
exit when p_cursor%notfound;
if rec_prev.STOCK_NAME = rec.STOCK_NAME
then
if (rec.STOCK_NAME = rec_prev.STOCK_NAME and rec.UT < rec_prev.UT)
or (rec.STOCK_NAME = rec_prev.STOCK_NAME and rec.UT = rec_prev.UT and rec.SEQ_NUM < rec_prev.SEQ_NUM)
then raise_application_error (-20010, 'Rowset must be ordered, ('||rec_prev.STOCK_NAME||','||rec_prev.UT||','||rec_prev.SEQ_NUM||') > ('||rec.STOCK_NAME||','||rec.UT||','||rec.SEQ_NUM||')');
endif;
endif;
if rec.STOCK_NAME <> rec_prev.STOCK_NAME or rec_prev.STOCK_NAME is null
then
for j in 1 .. 10
loop
if QuoteTail(j).UT is not null
then
pipe row (QuoteTail(j));
QuoteTail(j) := null;
endif;
endloop;
endif;
for i in reverse 1..10
loop
ut := TRUNC_UT (rec.UT, i);
if QuoteTail(i).UT <> ut
then
for j in 1..i
loop
pipe row (QuoteTail(j));
QuoteTail(j) := null;
endloop;
endif;
if QuoteTail(i).UT is null
then
QuoteTail(i).STRIPE_ID := i;
QuoteTail(i).STOCK_NAME := rec.STOCK_NAME;
QuoteTail(i).UT := ut;
QuoteTail(i).AOPEN := rec.APRICE;
endif;
if rec.APRICE < QuoteTail(i).ALOW or QuoteTail(i).ALOW is null then QuoteTail(i).ALOW := rec.APRICE; endif;
if rec.APRICE > QuoteTail(i).AHIGH or QuoteTail(i).AHIGH is null then QuoteTail(i).AHIGH := rec.APRICE; endif;
QuoteTail(i).AVOLUME := nvl (QuoteTail(i).AVOLUME, 0) + rec.AVOLUME;
QuoteTail(i).AAMOUNT := nvl (QuoteTail(i).AAMOUNT, 0) + rec.AVOLUME * rec.APRICE;
QuoteTail(i).ACOUNT := nvl (QuoteTail(i).ACOUNT, 0) + 1;
QuoteTail(i).ACLOSE := rec.APRICE;
endloop;
rec_prev := rec;
endloop;
for j in 1 .. 10
loop
if QuoteTail(j).UT is not null
then
pipe row (QuoteTail(j));
endif;
endloop;
exception
when no_data_needed then null;
end;
end;
/
Create a VIEW:
createorreplaceview THINNING_HABR_PPTF_V asselect * fromtable (THINNING_PPTF_P.F (cursor (select STOCK_NAME, UT, ID, APRICE, AVOLUME from TRANSACTIONS_RAW)));
Option 6 - MODE (model clause)
The variant iteratively calculates thinning for all 10 levels by using the MODEL clause clause with the phrase ITERATE .
The option is also impractical because it turns out to be slow. In my environment, 1000 transactions on 8 instruments are calculated for 1 minute. Most of the time is spent on calculating the phrase MODEL .
Here I give this option only for completeness and as confirmation of the fact that almost all complex calculations on Oracle can be performed in one query, without using PL / SQL.
One of the reasons for the poor performance of the MODEL phrase in this query is that the search by the criteria on the right is made for eachthe rules that we have 6. The first two rules are calculated fairly quickly, because there is a direct explicit addressing, without jokers. In the other four rules there is the word any - there calculations are made more slowly.
The second difficulty is that the reference model has to be calculated. It is needed because the dimension list must be known before calculating the MODEL phrase ; we cannot calculate new dimensions inside this phrase. Perhaps this can be bypassed with the help of two MODEL phrases, but I did not do this because of the poor performance of a large number of rules.
I ’ll add that you could not count UT_OPEN and UT_CLOSE in the reference model, but use the same functionsavg () keep (dense_rank first / last order by) directly in the MODEL phrase . But it would have been even slower.
Due to performance limitations, I will not include this option in the testing procedure.
with-- построение первого уровня прореживания из транзакций
SOURCETRANS (STRIPE_ID, STOCK_NAME, PARENT_UT, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select1, STOCK_NAME, TRUNC_UT (UT, 2), UT
, avg (APRICE) keep (dense_rankfirstorderbyID)
, max (APRICE)
, min (APRICE)
, avg (APRICE) keep (dense_ranklastorderbyID)
, sum (AVOLUME)
, sum (AVOLUME * APRICE)
, count (*)
from TRANSACTIONS_RAW
whereID <= 1000-- увеличьте значение для каждого интсрумента здесьgroupby STOCK_NAME, UT)
-- построение карты PARENT_UT, UT для 2...10 уровней и расчёт UT_OPEN, UT_CLOSE-- используется декартово произведение
, REFMOD (STRIPE_ID, STOCK_NAME, PARENT_UT, UT, UT_OPEN, UT_CLOSE)
as (select b.STRIPE_ID
, a.STOCK_NAME
, TRUNC_UT (UT, b.STRIPE_ID + 1)
, TRUNC_UT (UT, b.STRIPE_ID)
, min (TRUNC_UT (UT, b.STRIPE_ID - 1))
, max (TRUNC_UT (UT, b.STRIPE_ID - 1))
from SOURCETRANS a
, (selectrownum + 1as STRIPE_ID from dual connectbylevel <= 9) b
groupby b.STRIPE_ID
, a.STOCK_NAME
, TRUNC_UT (UT, b.STRIPE_ID + 1)
, TRUNC_UT (UT, b.STRIPE_ID))
-- конкатенация первого уровня и карты следующих уровней
, MAINTAB
as (
select STRIPE_ID, STOCK_NAME, PARENT_UT, UT, AOPEN
, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT, null, nullfrom SOURCETRANS
union all
select STRIPE_ID, STOCK_NAME, PARENT_UT, UT, null
, null, null, null, null, null, null, UT_OPEN, UT_CLOSE from REFMOD)
select STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT
from MAINTAB
modelreturn all rows-- референсная модель содержит карту уровней 2...10reference RM on (select * from REFMOD) dimensionby (STRIPE_ID, STOCK_NAME, UT) measures (UT_OPEN, UT_CLOSE)
main MM partitionby (STOCK_NAME) dimensionby (STRIPE_ID, PARENT_UT, UT) measures (AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
rulesiterate (9) (
AOPEN [iteration_number + 2, any, any]
= AOPEN [cv (STRIPE_ID) - 1, cv (UT)
, rm.UT_OPEN [cv (STRIPE_ID), cv (STOCK_NAME), cv (UT)]]
, ACLOSE [iteration_number + 2, any, any]
= ACLOSE [cv (STRIPE_ID) - 1, cv (UT)
, rm.UT_CLOSE[cv (STRIPE_ID), cv (STOCK_NAME), cv (UT)]]
, AHIGH [iteration_number + 2, any, any]
= max (AHIGH)[cv (STRIPE_ID) - 1, cv (UT), any]
, ALOW [iteration_number + 2, any, any]
= min (ALOW)[cv (STRIPE_ID) - 1, cv (UT), any]
, AVOLUME [iteration_number + 2, any, any]
= sum (AVOLUME)[cv (STRIPE_ID) - 1, cv (UT), any]
, AAMOUNT [iteration_number + 2, any, any]
= sum (AAMOUNT)[cv (STRIPE_ID) - 1, cv (UT), any]
, ACOUNT [iteration_number + 2, any, any]
= sum (ACOUNT)[cv (STRIPE_ID) - 1, cv (UT), any]
)
orderby1, 2, 3, 4;
Option 6 - IDEA (ideal, ideal, but inoperable)
The query described below would potentially be the most efficient and consume a quantity of resources equal to the theoretical minimum.
But neither Oracle nor MS SQL allow you to write a query in this form. I guess this is dictated by the standard.
with
QUOTES_S1 as (select1as STRIPE_ID
, STOCK_NAME
, TRUNC_UT (UT, 1) as UT
, avg (APRICE) keep (dense_rankfirstorderbyID) as AOPEN
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, avg (APRICE) keep (dense_ranklastorderbyID) as ACLOSE
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
-- where rownum <= 100groupby STOCK_NAME, TRUNC_UT (UT, 1))
, T1 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select1, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT
from QUOTES_S1
union all
select STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rankfirstorderby UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_ranklastorderby UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T1
where STRIPE_ID < 10groupby STRIPE_ID + 1, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1)
)
select * from T1
This query corresponds to the following part of the Oracle documentation:
If a subquery_factoring_clause refers to a subquery_factoring_clause. A recursive subquery_factoring_clause must contain two query blocks. Cannot be referenced reference_name. UNION ALL, UNION, INTERSECT or MINUS. The recursive member must follow query_name exactly once. You must combine the recursive member with the anchor member using the UNION ALL set operator.
But contrary to the following paragraph of the documentation:
CAN recursive member of The not the contain the any of the the following elements:
of The the DISTINCT keyword or the GROUP BY clause a clause
of An the aggregate function. However, analytic functions are permitted in the select list.
Thus, in a recursive member, aggregates and grouping are not allowed.
Testing
Let's spend at first for Oracle .
Perform the calculation procedure for the CALC method and write down the execution time:
exec THINNING_HABR_CALC_TThe calculation results for the four methods are in four views:
- THINNING_HABR_SIMP_V (will perform the calculation, causing a complex SELECT, so it will take a long time),
- THINNING_HABR_CALC_V (will display data from the QUOTES_CALC table, so it will execute quickly)
- THINNING_HABR_CHIN_V (will also perform the calculation, causing a complex SELECT, so it will take a long time),
- THINNING_HABR_PPTF_V (will perform the function THINNING_HABR_PPTF).
The execution time for all methods has already been measured by me and is shown in the table at the end of the article.
For the rest of VIEW, we will execute queries and record the execution time:
selectcount (*) as CNT
, sum (STRIPE_ID) as S_STRIPE_ID, sum (UT) as S_UT
, sum (AOPEN) as S_AOPEN, sum (AHIGH) as S_AHIGH, sum (ALOW) as S_ALOW
, sum (ACLOSE) as S_ACLOSE, sum (AVOLUME) as S_AVOLUME
, sum (AAMOUNT) as S_AAMOUNT, sum (ACOUNT) as S_ACOUNT
from THINNING_HABR_XXXX_V
where XXXX is SIMP, CHIN, PPTF.
These VIEW count set digest. To calculate the digest, you need to fetch all the strings, and with the help of the digest you can compare the sets with each other.
You can also compare sets using the dbms_sqlhash package, but this is much slower, because the initial set is required to be sorted, and the calculation of the hash is not fast.
Also in 12c there is a DBMS_COMPARISON package.
You can simultaneously check the correctness of all algorithms. We calculate the digests with such a request (with 11M records on a virtual machine, it will be relatively long, about 15 minutes):
with
T1 as (select'SIMP'as ALG_NAME, a.* from THINNING_HABR_SIMP_V a
union all
select'CALC', a.* from THINNING_HABR_CALC_V a
union all
select'CHIN', a.* from THINNING_HABR_CHIN_V a
union all
select'PPTF', a.* from THINNING_HABR_PPTF_V a)
select ALG_NAME
, count (*) as CNT
, sum (STRIPE_ID) as S_STRIPE_ID, sum (UT) as S_UT
, sum (AOPEN) as S_AOPEN, sum (AHIGH) as S_AHIGH, sum (ALOW) as S_ALOW
, sum (ACLOSE) as S_ACLOSE, sum (AVOLUME) as S_AVOLUME
, sum (AAMOUNT) as S_AAMOUNT, sum (ACOUNT) as S_ACOUNT
from T1
groupby ALG_NAME;
We see that the digests are the same, so all the algorithms gave the same results.
Now let's reproduce the same thing on MS SQL . I tested on version 2016.
Pre-create a DBTEST database, then create a transaction table in it:
use DBTEST
gocreatetable TRANSACTIONS_RAW
(
STOCK_NAME varchar (32) notnull
, UT intnotnull
, APRICE numeric (22, 12) notnull
, AVOLUME numeric (22, 12) notnull
, IDbigintidentitynotnull
);
Download the downloaded data.
In MSSQL, create a file format_mssql.bcp:
12.0
3
1 SQLCHAR 0 0 "," 3 UT ""
2 SQLCHAR 0 0 "," 4 APRICE ""
3 SQLCHAR 0 0 "\n" 5 AVOLUME ""
And run the LoadData-MSSQL.sql script in SSMS (this script was generated by a single powershell script given in the section of this article for Oracle).
Create two functions:
use DBTEST
gocreateoralterfunction TRUNC_UT (@p_UT bigint, @p_StripeTypeId int) returnsbigintasbeginreturncase @p_StripeTypeId
when1then @p_UT
when2then @p_UT / 10 * 10when3then @p_UT / 60 * 60when4then @p_UT / 600 * 600when5then @p_UT / 3600 * 3600when6then @p_UT / 14400 * 14400when7then @p_UT / 86400 * 86400when8thendatediff (second, cast ('1970-01-01 00:00:00'as datetime), dateadd(m, datediff (m, 0, dateadd (second, @p_UT, cast ('1970-01-01 00:00:00'as datetime))), 0))
when9thendatediff (second, cast ('1970-01-01 00:00:00'as datetime), dateadd(yy, datediff (yy, 0, dateadd (second, @p_UT, cast ('1970-01-01 00:00:00'as datetime))), 0))
when10then0when11then0end;
end;
go
createoralterfunction UT2DATESTR (@p_UT bigint) returns datetime asbeginreturndateadd(s, @p_UT, cast ('1970-01-01 00:00:00'as datetime));
end;
go
Let's start implementing options:
Option 1 - SIMP
Run:
use DBTEST
gocreateoralterview dbo.THINNING_HABR_SIMP_V aswith
T1 (STRIPE_ID)
as (select1union all
select STRIPE_ID + 1from T1 where STRIPE_ID < 10)
, T2 as (select STRIPE_ID
, STOCK_NAME
, dbo.TRUNC_UT (UT, STRIPE_ID) as UT
, min (1000000 * cast (UT asbigint) + ID) as AOPEN_UT
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, max (1000000 * cast (UT asbigint) + ID) as ACLOSE_UT
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW, T1
groupby STRIPE_ID, STOCK_NAME, dbo.TRUNC_UT (UT, STRIPE_ID))
select t.STRIPE_ID, t.STOCK_NAME, t.UT, t_op.APRICE as AOPEN, t.AHIGH
, t.ALOW, t_cl.APRICE as ACLOSE, t.AVOLUME, t.AAMOUNT, t.ACOUNT
from T2 t
join TRANSACTIONS_RAW t_op on (t.STOCK_NAME = t_op.STOCK_NAME and t.AOPEN_UT / 1000000 = t_op.UT and t.AOPEN_UT % 1000000 = t_op.ID)
join TRANSACTIONS_RAW t_cl on (t.STOCK_NAME = t_cl.STOCK_NAME and t.ACLOSE_UT / 1000000 = t_cl.UT and t.ACLOSE_UT % 1000000 = t_cl.ID);
The missing first / last functions are implemented by double self-joining tables.
Option 2 - CALC
Create a table, procedure and view:
use DBTEST
gocreatetable dbo.QUOTES_CALC
(
STRIPE_ID intnotnull
, STOCK_NAME varchar(32) notnull
, UT bigintnotnull
, AOPEN numeric (22, 12) notnull
, AHIGH numeric (22, 12) notnull
, ALOW numeric (22, 12) notnull
, ACLOSE numeric (22, 12) notnull
, AVOLUME numeric (38, 12) notnull
, AAMOUNT numeric (38, 12) notnull
, ACOUNT intnotnull
);
go
createoralterprocedure dbo.THINNING_HABR_CALC asbeginset nocount on;
truncatetable QUOTES_CALC;
declare @StripeId int;
with
T1 as (select STOCK_NAME
, UT
, min (ID) as AOPEN_ID
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, max (ID) as ACLOSE_ID
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
groupby STOCK_NAME, UT)
insertinto QUOTES_CALC (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
select1, t.STOCK_NAME, t.UT, t_op.APRICE, t.AHIGH, t.ALOW, t_cl.APRICE, t.AVOLUME, t.AAMOUNT, t.ACOUNT
from T1 t
join TRANSACTIONS_RAW t_op on (t.STOCK_NAME = t_op.STOCK_NAME and t.UT = t_op.UT and t.AOPEN_ID = t_op.ID)
join TRANSACTIONS_RAW t_cl on (t.STOCK_NAME = t_cl.STOCK_NAME and t.UT = t_cl.UT and t.ACLOSE_ID = t_cl.ID);
set @StripeId = 1;
while (@StripeId <= 9)
beginwith
T1 as (select STOCK_NAME
, dbo.TRUNC_UT (UT, @StripeId + 1) as UT
, min (UT) as AOPEN_UT
, max (AHIGH) as AHIGH
, min (ALOW) as ALOW
, max (UT) as ACLOSE_UT
, sum (AVOLUME) as AVOLUME
, sum (AAMOUNT) as AAMOUNT
, sum (ACOUNT) as ACOUNT
from QUOTES_CALC
where STRIPE_ID = @StripeId
groupby STOCK_NAME, dbo.TRUNC_UT (UT, @StripeId + 1))
insertinto QUOTES_CALC (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
select @StripeId + 1, t.STOCK_NAME, t.UT, t_op.AOPEN, t.AHIGH, t.ALOW, t_cl.ACLOSE, t.AVOLUME, t.AAMOUNT, t.ACOUNT
from T1 t
join QUOTES_CALC t_op on (t.STOCK_NAME = t_op.STOCK_NAME and t.AOPEN_UT = t_op.UT)
join QUOTES_CALC t_cl on (t.STOCK_NAME = t_cl.STOCK_NAME and t.ACLOSE_UT = t_cl.UT)
where t_op.STRIPE_ID = @StripeId and t_cl.STRIPE_ID = @StripeId;
set @StripeId = @StripeId + 1;
end;
end;
go
createoralterview dbo.THINNING_HABR_CALC_V asselect *
from dbo.QUOTES_CALC;
go
Options 3 (CHIN) and 4 (UDAF) I did not implement in MS SQL.
Option 5 - PPTF
Create a table function and view. This function is just a tablespace, not a parallel pipelined table function, just the variant retained its historical name from Oracle:
use DBTEST
gocreateoralterfunction dbo.THINNING_HABR_PPTF ()
returns @rettab table (
STRIPE_ID bigintnotnull
, STOCK_NAME varchar(32) notnull
, UT bigintnotnull
, AOPEN numeric (22, 12) notnull
, AHIGH numeric (22, 12) notnull
, ALOW numeric (22, 12) notnull
, ACLOSE numeric (22, 12) notnull
, AVOLUME numeric (38, 12) notnull
, AAMOUNT numeric (38, 12) notnull
, ACOUNT bigintnotnull)
asbegindeclare @i tinyint;
declare @tut int;
declare @trans_STOCK_NAME varchar(32);
declare @trans_UT int;
declare @trans_ID int;
declare @trans_APRICE numeric (22,12);
declare @trans_AVOLUME numeric (22,12);
declare @trans_prev_STOCK_NAME varchar(32);
declare @trans_prev_UT int;
declare @trans_prev_ID int;
declare @trans_prev_APRICE numeric (22,12);
declare @trans_prev_AVOLUME numeric (22,12);
declare @QuoteTail table (
STRIPE_ID bigintnotnull primary key clustered
, STOCK_NAME varchar(32) notnull
, UT bigintnotnull
, AOPEN numeric (22, 12) notnull
, AHIGH numeric (22, 12)
, ALOW numeric (22, 12)
, ACLOSE numeric (22, 12)
, AVOLUME numeric (38, 12) notnull
, AAMOUNT numeric (38, 12) notnull
, ACOUNT bigintnotnull);
declare c cursor fast_forward forselect STOCK_NAME, UT, ID, APRICE, AVOLUME
from TRANSACTIONS_RAW
orderby STOCK_NAME, UT, ID; -- THIS ORDERING (STOCK_NAME, UT, ID) IS MANDATORY
open c;
fetch next from c into @trans_STOCK_NAME, @trans_UT, @trans_ID, @trans_APRICE, @trans_AVOLUME;
while @@fetch_status = 0
beginif @trans_STOCK_NAME <> @trans_prev_STOCK_NAME or @trans_prev_STOCK_NAME isnullbegininsertinto @rettab select * from @QuoteTail;
delete @QuoteTail;
end;
set @i = 10;
while @i >= 1
beginset @tut = dbo.TRUNC_UT (@trans_UT, @i);
if @tut <> (select UT from @QuoteTail where STRIPE_ID = @i)
begininsertinto @rettab select * from @QuoteTail where STRIPE_ID <= @i;
delete @QuoteTail where STRIPE_ID <= @i;
end;
if (selectcount (*) from @QuoteTail where STRIPE_ID = @i) = 0begininsertinto @QuoteTail (STRIPE_ID, STOCK_NAME, UT, AOPEN, AVOLUME, AAMOUNT, ACOUNT)
values (@i, @trans_STOCK_NAME, @tut, @trans_APRICE, 0, 0, 0);
end;
update @QuoteTail
set AHIGH = casewhen AHIGH < @trans_APRICE or AHIGH isnullthen @trans_APRICE else AHIGH end
, ALOW = casewhen ALOW > @trans_APRICE or ALOW isnullthen @trans_APRICE else ALOW end
, ACLOSE = @trans_APRICE, AVOLUME = AVOLUME + @trans_AVOLUME
, AAMOUNT = AAMOUNT + @trans_APRICE * @trans_AVOLUME
, ACOUNT = ACOUNT + 1where STRIPE_ID = @i;
set @i = @i - 1;
end;
set @trans_prev_STOCK_NAME = @trans_STOCK_NAME;
set @trans_prev_UT = @trans_UT;
set @trans_prev_ID = @trans_ID;
set @trans_prev_APRICE = @trans_APRICE;
set @trans_prev_AVOLUME = @trans_AVOLUME;
fetch next from c into @trans_STOCK_NAME, @trans_UT, @trans_ID, @trans_APRICE, @trans_AVOLUME;
end;
close c;
deallocate c;
insertinto @rettab select * from @QuoteTail;
return;
endgocreateoralterview dbo.THINNING_HABR_PPTF_V asselect *
from dbo.THINNING_HABR_PPTF ();
Perform the calculation of the table QUOTES_CALC for the CALC method and record the execution time:
use DBTEST
go
exec dbo.THINNING_HABR_CALC
The calculation results for the three methods are in three views:
- THINNING_HABR_SIMP_V (will perform the calculation, causing a complex SELECT, so it will take a long time),
- THINNING_HABR_CALC_V (will display data from the QUOTES_CALC table, so it will execute quickly)
- THINNING_HABR_PPTF_V (will perform the function THINNING_HABR_PPTF).
For two VIEWs, execute the queries and write the execution time:
selectcount (*) as CNT
, sum (STRIPE_ID) as S_STRIPE_ID, sum (UT) as S_UT
, sum (AOPEN) as S_AOPEN, sum (AHIGH) as S_AHIGH, sum (ALOW) as S_ALOW
, sum (ACLOSE) as S_ACLOSE, sum (AVOLUME) as S_AVOLUME
, sum (AAMOUNT) as S_AAMOUNT, sum (ACOUNT) as S_ACOUNT
from THINNING_HABR_XXXX_Vwhere XXXX is SIMP, PPTF.
Now you can compare the calculation results for the three methods for MS SQL. This can be done in one request. Run:
use DBTEST
gowith
T1 as (select'SIMP'as ALG_NAME, a.* from THINNING_HABR_SIMP_V a
union all
select'CALC', a.* from THINNING_HABR_CALC_V a
union all
select'PPTF', a.* from THINNING_HABR_PPTF_V a)
select ALG_NAME
, count (*) as CNT, sum (cast (STRIPE_ID asbigint)) as STRIPE_ID
, sum (cast (UT asbigint)) as UT, sum (AOPEN) as AOPEN
, sum (AHIGH) as AHIGH, sum (ALOW) as ALOW, sum (ACLOSE) as ACLOSE, sum (AVOLUME) as AVOLUME
, sum (AAMOUNT) as AAMOUNT, sum (cast (ACOUNT asbigint)) as ACOUNT
from T1
groupby ALG_NAME;
If the three lines coincide in all fields - the result of the calculation for the three methods is identical.
I strongly advise at the testing stage to use a small sample, because the performance of this task on MS SQL is low.
If you have only the MS SQL engine, and you want to calculate a larger amount of data, then you can try the following optimization method: you can create indices:
createunique clustered index TRANSACTIONS_RAW_I1 on TRANSACTIONS_RAW (STOCK_NAME, UT, ID);
createunique clustered index QUOTES_CALC_I1 on QUOTES_CALC (STRIPE_ID, STOCK_NAME, UT);
The performance measurement results in my virtual machine are as follows:
Scripts can be downloaded from github : Oracle, the THINNING schema — the scripts of this article, the THINNING_LIVE schema — online data download from bitcoincharts.com and online thinning (but this site provides data in the online mode for the last 5 days only), and the script for MS SQL also for this article.
Conclusion:
This task is solved faster on Oracle than on MS SQL. As the number of transactions grows, the gap becomes more significant.
On Oracle, the best option was PPTF. Here the procedural approach turned out to be more profitable, this happens infrequently. The remaining methods also showed an acceptable result - I even tested the volume of 367M transactions on a virtual machine (the PPTF method calculated thinning in an hour and a half).
On MS SQL, the iterative calculation method (CALC) turned out to be the most productive.
Why is the PPTF method on Oracle turned out to be the leader? Due to parallel execution and because of the architecture, a function that is created as a parallel pipelined table function is built into the middle of the query plan: