The history of the first place on the ML Boot Camp VI
Mail.ru has been holding machine learning championships for several years already; each time the task is interesting in its own way and difficult in its own way. I participate in competitions for the fourth time, I really like the platform and organization, and it was with the bootcamps that I started my way into competitive machine learning, but I managed to take first place for the first time. In the article, I will tell you how to show a stable result, without having retrained neither for the public leaderboard, nor for the delayed samples, if the test part is significantly different from the training part of the data.
The full text of the problem is available at → link . Briefly: there is 10 GB of data, where each line contains three json'a of the form “key: counter”, a certain category, a certain timestamp and a user ID. One user can match multiple entries. It is required to determine to which class the user belongs, first or second. The quality metric for the model is ROC-AUC, it is perfectly written on the blog of Alexander Dyakonov [1] .
File entry example
The first idea that arises from a data scientist who successfully downloaded dataset is to turn json columns into a sparse matrix. At this place, many participants experienced problems with a lack of RAM. When deploying even one column in python, memory consumption was higher than that available on an average laptop.
A bit of dry statistics. The number of unique keys in each column: 2053602, 20275, 1057788. At the same time, both in the train part and in the test part are only: 493866, 20268, 141931. 427994 unique users in the train and 181024 in the test part. Approximately 4% of class 1 in the training part.
As we see, we have a lot of signs, using them all is an obvious way to overfit to the train, because, for example, decisive trees use combinations of signs, and unique combinations of such a large number of signs are even greater and almost all of them exist only in the training part data or in test. However, one of the basic models I had was a lightgbm with colsample ~ 0.1 and very tight regularization. However, even despite the huge parameters of regularization, it showed an unstable result in the public and private parts, as it turned out after the end of the competition.
The second thought of the person who decided to participate in this competition would surely be to collect the train and test, aggregating information by identifiers. For example, the sum. Or maximum. And then it turns out two very interesting things that Mail.ru invented for us. First, the test can be classified with very high accuracy. Even according to the statistics on the number of cuid entries and the number of unique keys in the json test, the test significantly exceeds the train. The base classifier gave 0.9+ roc-auc in test recognition. Secondly, the counters have no meaning, almost all models have become better from switching from counters to binary features of the form: there is / is no key. Even trees, which in theory should not be worse than the fact that instead of a unit there is a certain number, seem to have retrained to counters.
The results on the public leaderboard greatly exceeded those on cross-validation. This was apparently due to the fact that it was easier for the model to build the ranking of two records in the test than in the train, because more signs gave more terms for ranking.
At this stage, it became finally clear that the validation in this competition is not a simple thing at all and neither the public nor the CV information of other participants, which could be tricked out in an official chat [2] . Why did it happen? It seems that the train and the test are separated in time, which was later confirmed by the organizers.
Any experienced kaggle member will immediately advise Adversarial validation [3]but it's not that simple. Despite the fact that the accuracy of the classifier on the train and the test is close to 1 according to the roc-auc metric, but there are not so many records similar to the test in the train. I tried to summarize cuid aggregated samples with the same target in order to increase the number of entries with a large number of unique keys in json, but this gave a drawdown for cross-validation and public reporting, and I was afraid to use such models.
There are two ways: to search for eternal values with the help of unsupervised learning or to try to take more important features for the test. I went both ways, using TruncatedSVD for unsupervised and selecting features by frequency in the test.
The first step, however, I did was a deep autoencoder, but I made a mistake by taking the same matrix twice, correcting the error and using the full set of features: the input tensor did not fit into the memory of the GPU for any size of the dense layer. I found a mistake and did not try to encode features in the future.
I generated SVD by all means for which I had enough imagination: on the original dataset with cat_feature and subsequent summation over cuid. For each column separately. By tf-idf on json as bag-of-words [4] (did not help).
For more variety, I tried to select a small number of features in the train, using A-NOVA for the train part of each fold for cross-validation.
The main base models: lightgbm, vowpal wabbit, xgboost, SGD. In addition, I used several neural network architectures. Dmitry Nikitko, who was in the first place of the public leaderboard, advised to use HashEmbeddings , this model after a certain selection of parameters showed a good result and improved the ensemble.
Another neural network model with the search for interactions (factorization machine style) between 3-4-5 data columns (three left inputs), numerical statistics (4 inputs), SVD matrices (5 inputs).
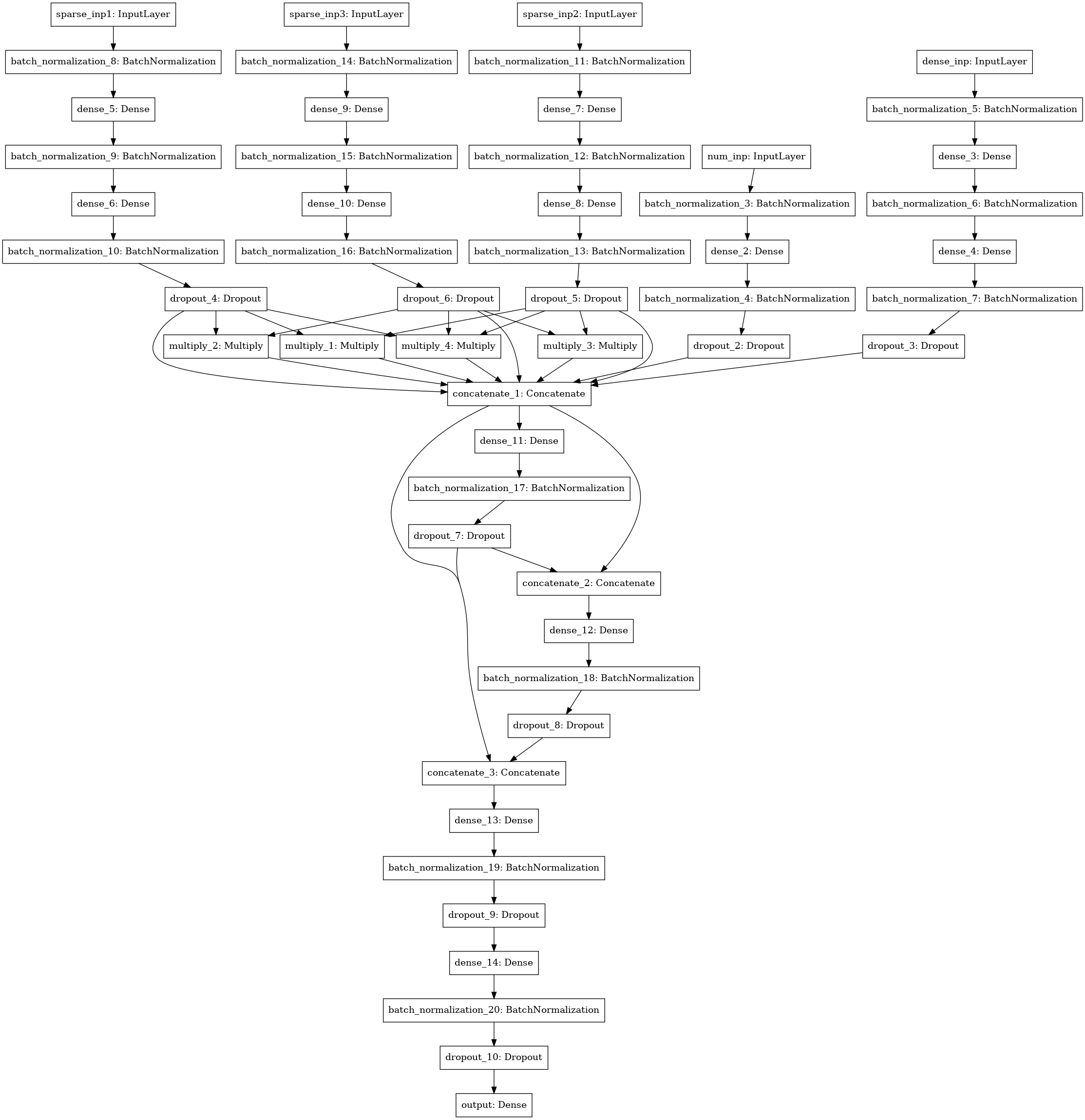
I counted all models by folds, averaging test predictions from models trained on different folds. Train predictions were used for stacking. The best result showed a stack of 1 level using xgboost on the predictions of the basic models and 250 signs from each json-column, selected according to the frequency with which the sign met in the test.
I spent ~ 30 hours of my time on the solution, counted on a server with 4 cores core-i7, 64 gigabytes of RAM, and one GTX 1080. As a result, my solution turned out to be quite stable and I moved up from the third place of the public leaderboard to the first private place.
A substantial part of the code is available on the beatback as laptops [5] .
I want to thank Mail.ru for interesting contests and other participants for interesting communication in the group!
[1] ROC-AUC in the blog Alexandrova Dyakonova
[2] Official chat ML BootCamp official
[3] Adversarial validation
[4] bag-of-words
[5] source code of most models
Task
The full text of the problem is available at → link . Briefly: there is 10 GB of data, where each line contains three json'a of the form “key: counter”, a certain category, a certain timestamp and a user ID. One user can match multiple entries. It is required to determine to which class the user belongs, first or second. The quality metric for the model is ROC-AUC, it is perfectly written on the blog of Alexander Dyakonov [1] .
File entry example
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1}
{"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39Decision
The first idea that arises from a data scientist who successfully downloaded dataset is to turn json columns into a sparse matrix. At this place, many participants experienced problems with a lack of RAM. When deploying even one column in python, memory consumption was higher than that available on an average laptop.
A bit of dry statistics. The number of unique keys in each column: 2053602, 20275, 1057788. At the same time, both in the train part and in the test part are only: 493866, 20268, 141931. 427994 unique users in the train and 181024 in the test part. Approximately 4% of class 1 in the training part.
As we see, we have a lot of signs, using them all is an obvious way to overfit to the train, because, for example, decisive trees use combinations of signs, and unique combinations of such a large number of signs are even greater and almost all of them exist only in the training part data or in test. However, one of the basic models I had was a lightgbm with colsample ~ 0.1 and very tight regularization. However, even despite the huge parameters of regularization, it showed an unstable result in the public and private parts, as it turned out after the end of the competition.
The second thought of the person who decided to participate in this competition would surely be to collect the train and test, aggregating information by identifiers. For example, the sum. Or maximum. And then it turns out two very interesting things that Mail.ru invented for us. First, the test can be classified with very high accuracy. Even according to the statistics on the number of cuid entries and the number of unique keys in the json test, the test significantly exceeds the train. The base classifier gave 0.9+ roc-auc in test recognition. Secondly, the counters have no meaning, almost all models have become better from switching from counters to binary features of the form: there is / is no key. Even trees, which in theory should not be worse than the fact that instead of a unit there is a certain number, seem to have retrained to counters.
The results on the public leaderboard greatly exceeded those on cross-validation. This was apparently due to the fact that it was easier for the model to build the ranking of two records in the test than in the train, because more signs gave more terms for ranking.
At this stage, it became finally clear that the validation in this competition is not a simple thing at all and neither the public nor the CV information of other participants, which could be tricked out in an official chat [2] . Why did it happen? It seems that the train and the test are separated in time, which was later confirmed by the organizers.
Any experienced kaggle member will immediately advise Adversarial validation [3]but it's not that simple. Despite the fact that the accuracy of the classifier on the train and the test is close to 1 according to the roc-auc metric, but there are not so many records similar to the test in the train. I tried to summarize cuid aggregated samples with the same target in order to increase the number of entries with a large number of unique keys in json, but this gave a drawdown for cross-validation and public reporting, and I was afraid to use such models.
There are two ways: to search for eternal values with the help of unsupervised learning or to try to take more important features for the test. I went both ways, using TruncatedSVD for unsupervised and selecting features by frequency in the test.
The first step, however, I did was a deep autoencoder, but I made a mistake by taking the same matrix twice, correcting the error and using the full set of features: the input tensor did not fit into the memory of the GPU for any size of the dense layer. I found a mistake and did not try to encode features in the future.
I generated SVD by all means for which I had enough imagination: on the original dataset with cat_feature and subsequent summation over cuid. For each column separately. By tf-idf on json as bag-of-words [4] (did not help).
For more variety, I tried to select a small number of features in the train, using A-NOVA for the train part of each fold for cross-validation.
Models
The main base models: lightgbm, vowpal wabbit, xgboost, SGD. In addition, I used several neural network architectures. Dmitry Nikitko, who was in the first place of the public leaderboard, advised to use HashEmbeddings , this model after a certain selection of parameters showed a good result and improved the ensemble.
Another neural network model with the search for interactions (factorization machine style) between 3-4-5 data columns (three left inputs), numerical statistics (4 inputs), SVD matrices (5 inputs).
Ensemble
I counted all models by folds, averaging test predictions from models trained on different folds. Train predictions were used for stacking. The best result showed a stack of 1 level using xgboost on the predictions of the basic models and 250 signs from each json-column, selected according to the frequency with which the sign met in the test.
I spent ~ 30 hours of my time on the solution, counted on a server with 4 cores core-i7, 64 gigabytes of RAM, and one GTX 1080. As a result, my solution turned out to be quite stable and I moved up from the third place of the public leaderboard to the first private place.
A substantial part of the code is available on the beatback as laptops [5] .
I want to thank Mail.ru for interesting contests and other participants for interesting communication in the group!
[1] ROC-AUC in the blog Alexandrova Dyakonova
[2] Official chat ML BootCamp official
[3] Adversarial validation
[4] bag-of-words
[5] source code of most models