Overrides Equals and GetHashCode. Do you need it?
- Transfer
If you are familiar with C #, you most likely know that you must always redefine

Not every potential performance issue affects the execution time of an application. The method is
(*) Fixed in .NET Core 2.1, and, as I mentioned in a previous post , now the effects can be mitigated using self-configured HasFlag for older versions.
But the problem that we will talk about today is special. If the structure does not create methods
The CLR authors have struggled to make the standard versions of Equals and GetHashCode as efficient as possible for value types. But there are several reasons why these methods lose in the effectiveness of a user version written for a specific type manually (or generated by the compiler).
1. Distribution of packaging-transformation. The CLR is designed in such a way that every call to an element defined in types
(**) If the method does not support JIT compilation. For example, in Core CLR 2.1, the JIT compiler recognizes a method
2. Potential conflicts in the standard version of the method
A traditional hash function of type "struct" combines the hash codes of all fields. But the only way to get the hash code of a field in a method
(***) Judging by the comments in the CoreCLR repository, the situation may change in the future.
This is a reasonable algorithm until something goes wrong. But if you are unlucky and the value of the first field of your struct type matches in most instances, then the hash function will always produce the same result. As you may have guessed, if you save these instances in a hash set or hash table, then the performance will drop dramatically.
3. The speed of implementation based on reflection is low. Very low. Reflection is a powerful tool if used correctly. But the consequences will be terrible if you run it on a resource-intensive piece of code.
Let's look at how an unsuccessful hash function, which can result from (2) and a reflection-based implementation, affects performance:
If the value of the first field is always the same, then by default the hash function returns an equal value for all elements and the hash set is effectively converted into a linked list with O (N) insert and search operations. The number of operations to fill the collection becomes O (N ^ 2) (where N is the number of inserts with complexity O (N) for each insert). This means that inserting 1000 items into the set will result in almost 500,000 calls
As the test shows, the performance will be acceptable if you are lucky and the first element of the structure is unique (in the case
I think now you can guess what problem I recently encountered. A couple of weeks ago I received an error message: the execution time of the application I am working on increased from 10 to 60 seconds. Fortunately, the report was very detailed and contained a trace of Windows events, so the problem place was discovered quickly - it took
After a quick scan of the code, it became clear what the problem was:
I used a tuple that contained a custom type of struct with the standard version
Does the
Both for
The check itself is performed in
But optimization is a very insidious thing.
Firstly, it is difficult to understand when it is turned on; even minor changes to the code can turn it on and off:
For more information about the structure of memory, see my blog "Internal elements of a managed object, part 4. Structure of fields . "
Secondly, a comparison of memory does not necessarily give you the correct result. Here is a simple example:
You can ask me how the above mentioned can happen in a real situation? One of the obvious ways to start the techniques
An application for which performance is critical can have hundreds of struct types that are not necessarily used in hash sets or dictionaries. Therefore, application developers can disable the rule, which will have unpleasant consequences if the type of struct uses modified functions.
A more correct approach is to warn the developer if a “inappropriate” type of struct with equal values of default elements (defined in an application or a third-party library) is stored in a hash set. Of course, I'm talking aboutErrorProne.NET and the rule I added there as soon as I ran into this problem:

The ErrorProne.NET version is not perfect and will “blame” the correct code if the designer uses a custom equality mapper:
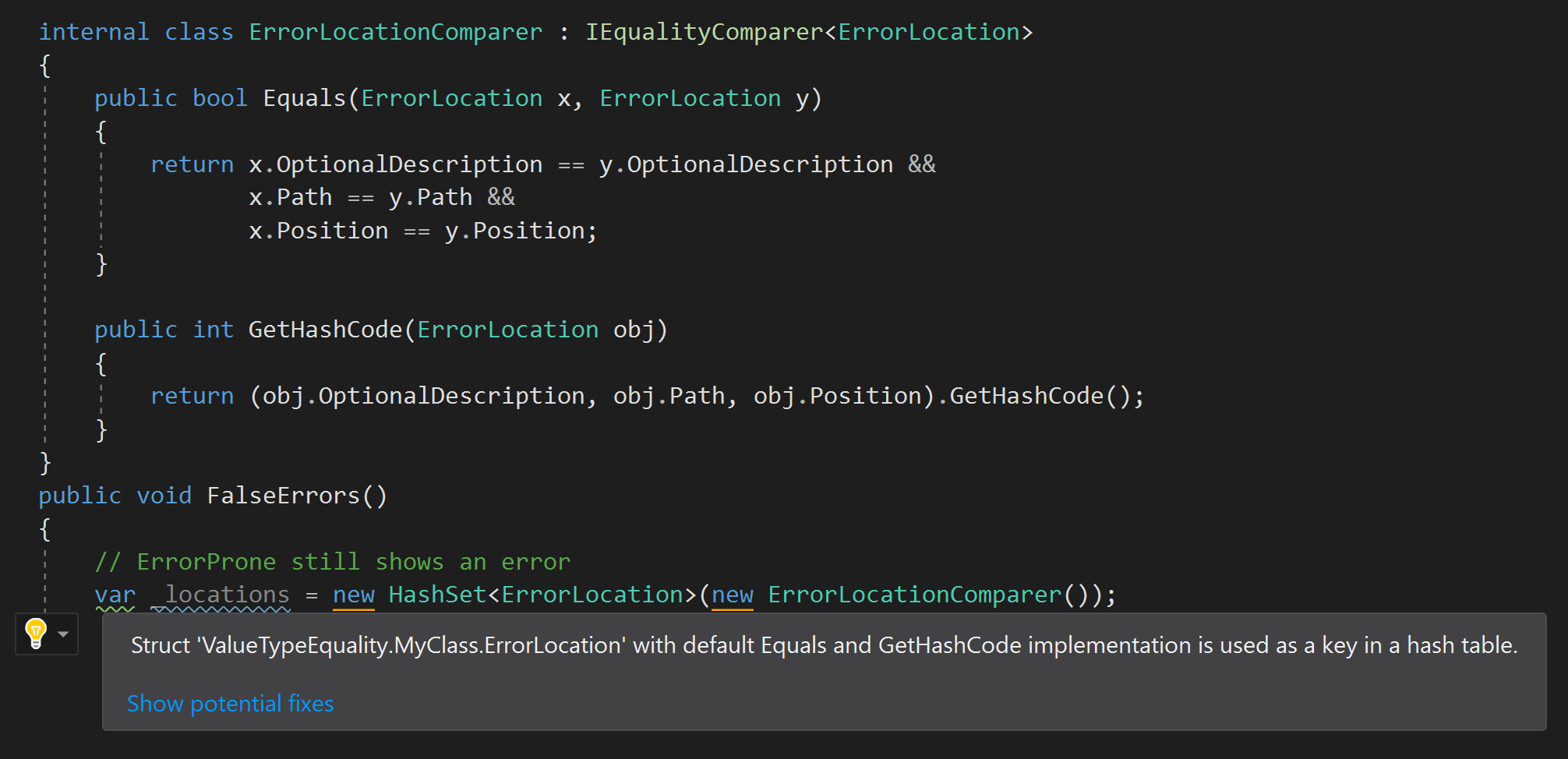
But I still think it is worth warning if the type of struct with equal elements is not used when produced. For example, when I checked my rule, I realized that the structure
Equals, and also GetHashCodeto avoid performance degradation. But what happens if this is not done? Today, let's compare the performance with the two settings and consider the tools to help avoid errors.How serious is this problem?
Not every potential performance issue affects the execution time of an application. The method is
Enum.HasFlagnot very effective (*), but if you do not use it on a resource-intensive piece of code, then there will be no serious problems in the project. This is also true for protected copies created by non-readonly struct types in a readonly context. The problem exists, but is unlikely to be noticeable in ordinary applications. (*) Fixed in .NET Core 2.1, and, as I mentioned in a previous post , now the effects can be mitigated using self-configured HasFlag for older versions.
But the problem that we will talk about today is special. If the structure does not create methods
Equals and GetHashCode, then their standard versions fromSystem.ValueType. And they can significantly reduce the performance of the final application.Why are standard versions slow?
The CLR authors have struggled to make the standard versions of Equals and GetHashCode as efficient as possible for value types. But there are several reasons why these methods lose in the effectiveness of a user version written for a specific type manually (or generated by the compiler).
1. Distribution of packaging-transformation. The CLR is designed in such a way that every call to an element defined in types
System.ValueTypeor System.Enumstarts a wrapping-transform (**). (**) If the method does not support JIT compilation. For example, in Core CLR 2.1, the JIT compiler recognizes a method
Enum.HasFlagand generates suitable code that does not launch wrapping. 2. Potential conflicts in the standard version of the method
GetHashCode. When implementing a hash function, we are faced with a dilemma: make hash function distribution good or fast. In some cases, you can do both, but in the type ValueType.GetHashCodeit is usually fraught with difficulties. A traditional hash function of type "struct" combines the hash codes of all fields. But the only way to get the hash code of a field in a method
ValueTypeis to use reflection. That is why the CLR authors decided to sacrifice speed for the sake of distribution, and the standard version GetHashCodeonly returns the hash code of the first non-zero field and “spoils” it with a type identifier (***) (for more details, see RegularGetValueTypeHashCodecoreclr repo on github). (***) Judging by the comments in the CoreCLR repository, the situation may change in the future.
publicreadonlystruct Location
{
publicstring Path { get; }
publicint Position { get; }
publicLocation(string path, int position) => (Path, Position) = (path, position);
}
var hash1 = new Location(path: "", position: 42).GetHashCode();
var hash2 = new Location(path: "", position: 1).GetHashCode();
var hash3 = new Location(path: "1", position: 42).GetHashCode();
// hash1 and hash2 are the same and hash1 is different from hash3This is a reasonable algorithm until something goes wrong. But if you are unlucky and the value of the first field of your struct type matches in most instances, then the hash function will always produce the same result. As you may have guessed, if you save these instances in a hash set or hash table, then the performance will drop dramatically.
3. The speed of implementation based on reflection is low. Very low. Reflection is a powerful tool if used correctly. But the consequences will be terrible if you run it on a resource-intensive piece of code.
Let's look at how an unsuccessful hash function, which can result from (2) and a reflection-based implementation, affects performance:
publicreadonlystruct Location1
{
publicstring Path { get; }
publicint Position { get; }
publicLocation1(string path, int position) => (Path, Position) = (path, position);
}
publicreadonlystruct Location2
{
// The order matters!// The default GetHashCode version will get a hashcode of the first fieldpublicint Position { get; }
publicstring Path { get; }
publicLocation2(string path, int position) => (Path, Position) = (path, position);
}
publicreadonlystruct Location3 : IEquatable<Location3>
{
publicstring Path { get; }
publicint Position { get; }
publicLocation3(string path, int position) => (Path, Position) = (path, position);
publicoverrideintGetHashCode() => (Path, Position).GetHashCode();
publicoverrideboolEquals(object other) => other is Location3 l && Equals(l);
publicboolEquals(Location3 other) => Path == other.Path && Position == other.Position;
}
private HashSet<Location1> _locations1;
private HashSet<Location2> _locations2;
private HashSet<Location3> _locations3;
[Params(1, 10, 1000)]
publicint NumberOfElements { get; set; }
[GlobalSetup]
publicvoidInit()
{
_locations1 = new HashSet<Location1>(Enumerable.Range(1, NumberOfElements).Select(n => new Location1("", n)));
_locations2 = new HashSet<Location2>(Enumerable.Range(1, NumberOfElements).Select(n => new Location2("", n)));
_locations3 = new HashSet<Location3>(Enumerable.Range(1, NumberOfElements).Select(n => new Location3("", n)));
_locations4 = new HashSet<Location4>(Enumerable.Range(1, NumberOfElements).Select(n => new Location4("", n)));
}
[Benchmark]
publicboolPath_Position_DefaultEquality()
{
var first = new Location1("", 0);
return _locations1.Contains(first);
}
[Benchmark]
publicboolPosition_Path_DefaultEquality()
{
var first = new Location2("", 0);
return _locations2.Contains(first);
}
[Benchmark]
publicboolPath_Position_OverridenEquality()
{
var first = new Location3("", 0);
return _locations3.Contains(first);
} Method | NumOfElements | Mean | Gen 0 | Allocated |
-------------------------------- |------ |--------------:|--------:|----------:|
Path_Position_DefaultEquality | 1 | 885.63 ns | 0.0286 | 92 B |
Position_Path_DefaultEquality | 1 | 127.80 ns | 0.0050 | 16 B |
Path_Position_OverridenEquality | 1 | 47.99 ns | - | 0 B |
Path_Position_DefaultEquality | 10 | 6,214.02 ns | 0.2441 | 776 B |
Position_Path_DefaultEquality | 10 | 130.04 ns | 0.0050 | 16 B |
Path_Position_OverridenEquality | 10 | 47.67 ns | - | 0 B |
Path_Position_DefaultEquality | 1000 | 589,014.52 ns | 23.4375 | 76025 B |
Position_Path_DefaultEquality | 1000 | 133.74 ns | 0.0050 | 16 B |
Path_Position_OverridenEquality | 1000 | 48.51 ns | - | 0 B |If the value of the first field is always the same, then by default the hash function returns an equal value for all elements and the hash set is effectively converted into a linked list with O (N) insert and search operations. The number of operations to fill the collection becomes O (N ^ 2) (where N is the number of inserts with complexity O (N) for each insert). This means that inserting 1000 items into the set will result in almost 500,000 calls
ValueType.Equals. Here are the consequences of the method that uses reflection! As the test shows, the performance will be acceptable if you are lucky and the first element of the structure is unique (in the case
Position_Path_DefaultEquality). But if this is not the case, then the performance will be extremely low.Real problem
I think now you can guess what problem I recently encountered. A couple of weeks ago I received an error message: the execution time of the application I am working on increased from 10 to 60 seconds. Fortunately, the report was very detailed and contained a trace of Windows events, so the problem place was discovered quickly - it took
ValueType.Equals50 seconds to load. After a quick scan of the code, it became clear what the problem was:
privatereadonly HashSet<(ErrorLocation, int)> _locationsWithHitCount;
readonlystruct ErrorLocation
{
// Empty almost all the timepublicstring OptionalDescription { get; }
publicstring Path { get; }
publicint Position { get; }
}I used a tuple that contained a custom type of struct with the standard version
Equals. And, unfortunately, he had an optional first field, which was almost always equal String.equals. Performance remained high until the number of elements in the set increased significantly. Within minutes, a collection with tens of thousands of elements was initialized.Does the ValueType.Equals/GetHashCodedefault implementation always work slowly?
Both for
ValueType.Equalsand for ValueType.GetHashCodethere are special optimization methods. If the type does not have “pointers” and it is packaged correctly (I will show an example in a minute), then optimized versions are used: iterations GetHashCode are performed on the blocks of the instance, XOR is used, 4 bytes in size, the method Equals compares two instances using memcmp.// Optimized ValueType.GetHashCode implementationstatic INT32 FastGetValueTypeHashCodeHelper(MethodTable *mt, void *pObjRef)
{
INT32 hashCode = 0;
INT32 *pObj = (INT32*)pObjRef;
// this is a struct with no refs and no "strange" offsets, just go through the obj and xor the bits
INT32 size = mt->GetNumInstanceFieldBytes();
for (INT32 i = 0; i < (INT32)(size / sizeof(INT32)); i++)
hashCode ^= *pObj++;
return hashCode;
}
// Optimized ValueType.Equals implementation
FCIMPL2(FC_BOOL_RET, ValueTypeHelper::FastEqualsCheck, Object* obj1, Object* obj2)
{
TypeHandle pTh = obj1->GetTypeHandle();
FC_RETURN_BOOL(memcmp(obj1->GetData(), obj2->GetData(), pTh.GetSize()) == 0);
}The check itself is performed in
ValueTypeHelper::CanCompareBits, it is called from both iteration ValueType.Equalsand iteration ValueType.GetHashCode. But optimization is a very insidious thing.
Firstly, it is difficult to understand when it is turned on; even minor changes to the code can turn it on and off:
publicstruct Case1
{
// Optimization is "on", because the struct is properly "packed"publicint X { get; }
publicbyte Y { get; }
}
publicstruct Case2
{
// Optimization is "off", because struct has a padding between byte and intpublicbyte Y { get; }
publicint X { get; }
}For more information about the structure of memory, see my blog "Internal elements of a managed object, part 4. Structure of fields . "
Secondly, a comparison of memory does not necessarily give you the correct result. Here is a simple example:
publicstruct MyDouble
{
publicdouble Value { get; }
publicMyDouble(doublevalue) => Value = value;
}
double d1 = -0.0;
double d2 = +0.0;
// Truebool b1 = d1.Equals(d2);
// False!bool b2 = new MyDouble(d1).Equals(new MyDouble(d2));-0,0and +0,0equal, but have different binary representations. This means that it Double.Equalswill be true, and MyDouble.Equals- false. In most cases, the difference is not significant, but imagine how many hours you will spend on correcting the problem caused by this difference.How to avoid a similar problem?
You can ask me how the above mentioned can happen in a real situation? One of the obvious ways to start the techniques
Equals and GetHashCode in the types struct - use rule FxCop CA1815 . But there is one problem: this is too strict an approach. An application for which performance is critical can have hundreds of struct types that are not necessarily used in hash sets or dictionaries. Therefore, application developers can disable the rule, which will have unpleasant consequences if the type of struct uses modified functions.
A more correct approach is to warn the developer if a “inappropriate” type of struct with equal values of default elements (defined in an application or a third-party library) is stored in a hash set. Of course, I'm talking aboutErrorProne.NET and the rule I added there as soon as I ran into this problem:
The ErrorProne.NET version is not perfect and will “blame” the correct code if the designer uses a custom equality mapper:
But I still think it is worth warning if the type of struct with equal elements is not used when produced. For example, when I checked my rule, I realized that the structure
System.Collections.Generic.KeyValuePair <TKey, TValue>defined in mscorlib does not overwrite Equals and GetHashCode. It is unlikely that today someone will define a type variable HashSet <KeyValuePair<string, int>>, but I believe that even the BCL can break the rule. Therefore, it is useful to discover this before it is too late.Conclusion
- Implementing the default equality for struct types can have serious consequences for your application. This is a real, not a theoretical problem.
- The default equality elements for value types are based on reflection.
- The distribution performed by the standard version
GetHashCodewill be very bad if the first field of many instances has the same value. - For standard methods,
EqualsandGetHashCodethere are optimized versions, but you should not rely on them, because even a small code change can turn them off. - Use the FxCop rule to ensure that each struct type overrides the elements of equality. However, it is better to prevent the problem with the analyzer if the “inappropriate” structure is stored in a hash set or in a hash table.