Will the base break if you pull the server out of the socket, or offal DB ORACLE for dummies
I wrote for colleagues - programmers who are far from the subject area, who really, sincerely did not understand what was so complicated in the database. They wanted to store critical data in simple files. I asked them tricky questions about reliability, speed and simultaneous access, they tried to come up with tricky solutions on the go. In the end, they soberly evaluated the required amount of code and realized that they would have to write their own little ORACLE or, at least, MySQL. Then I told them how these problems were solved in DB ORACLE, they were struck by the elegance of some algorithms. I liked the lecture, and I decided to put it in the public domain.
Who does not want to read the theory - at the end of a couple of key points that every developer working with ORACLE should know. He may not know the SQL language, but he must know the features of COMMIT.
For DBA and other experts (in a good way) - the material is deliberately maximally simplified, due to this there are some inaccuracies. The goal was to convey the basic principles to an unprepared person.
In the beginning there was a file and there were tables with records of fixed length.
It's simple - new records were added to existing “holes” in the middle of the file instead of deleted ones, if there are no “holes” - to the end.
Quickly, but you have to reserve a lot of space just in case, for rare, unique data. So, one well-known Spaniard has the name "Pablo Diego Jose Francisco de Paula Juan Nepomukeno Crispin Crispiano de la Santisima Trinidad Ruiz and Picasso" - respectively, the full name field will have to be done with a large margin.
And no long descriptions or notes from several sentences.
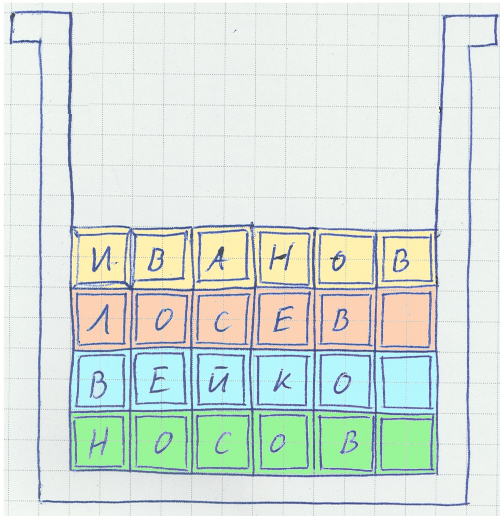
When adding such lines to the end of the file, there is no problem, but when inserting into the middle of the file instead of deleted data and changing the data inside the lines (a couple of sentences were added to the product description), problems appear. The solution was invented by the developers of file systems and memory managers for a long time - to store data in blocks, when the data "spreads" across several blocks - to defragment. In addition, ORACLE allows you to leave an empty space there for future changes when creating a block, in case the length of the new record increases.
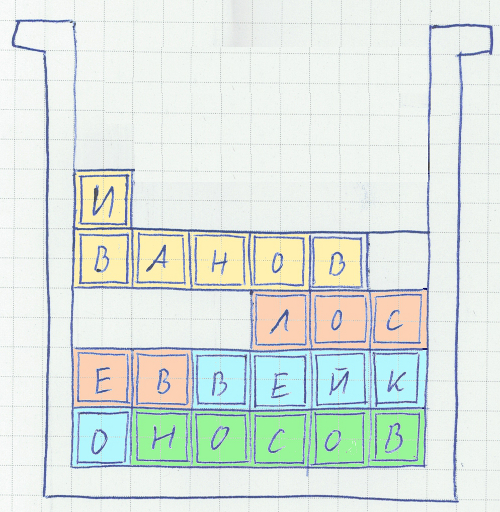
When the functionality was added, the speed dropped a lot. Defragmentation takes a lot of resources, it has to be limited. As a result, many records turned out to be “blurred” into blocks, and, worst of all, these blocks can physically be in different parts of the hard drive. The obvious solution - caching in the buffer cache - saves the situation when reading. When committing changes, all data must be written to disk (when it comes to critical applications, you can not rely on UPS), and preferably not one, but several, for backup. Moreover, the disks should be logical, redundancy exclusively by RAID means will not work, because, in case of the death of the controller, the entire array can go to the dump. And users, in addition, do not want to duplicate data files on the server - server disks are very expensive.
The solution was found - created - redo log, re-run log. After changing the data in the cache, all new and changed data is sequentially written to this file. If you select a separate disk for this task (or rather several on different controllers), the head will not jump, and the sequential write speed of the disks is high. Pay attention to the elegance of the solution - all changes are written to the log immediately, without waiting for the transaction to be committed. COMMIT only puts down a key marker, which takes a split second. If the transaction is rolled back, information about the changes still remains in the log file, but it ends with a rollback mark.
But what about data files? A process is periodically started that finds modified, so-called "dirty" blocks in the buffer cache and writes them to disk. Due to the "wholesale" processing, the speed and reaction time of the system are increased.
So that the size of the re-run logs does not increase indefinitely, log rotation is used. ORACLE makes sure that when the log files are cyclically changed, all “dirty” blocks get into the data files.
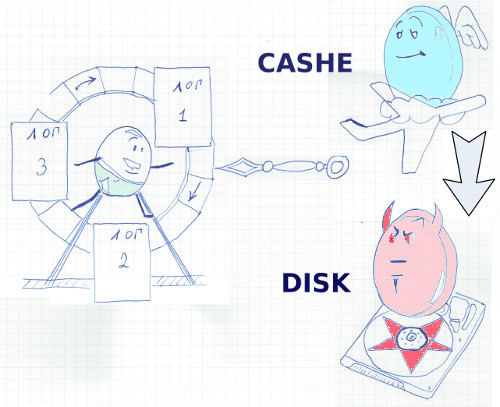
From this scheme follows a feature that is not obvious at first glance, which struck me at one time to the depths of my soul. What to do with the changed blocks which are not confirmed by COMMIT but are no longer placed in the buffer cache? Write changes to temporary file? No, ORACLE writes these changes directly to the data files. Yes, in a system that is initially oriented towards increased reliability, data files may contain non-consistent, not committed COMMIT ”data, and this is normal, it is part of the work process. Instead, the DBMS backs up the changed blocks in special UNDO files. Here, this reserve is maintained until the transaction is committed, and allows other transactions to read data while another transaction changes them. Yes, in ORACLE, changes do not block reading. These are the basics
And - all UNDO changes are also recorded in the redo log.
Thus, the re-run log contains information about all added data, as well as data before and after the change. These logics are very important, only with the help of them can data files be brought into the correct, consistent state. ORACLE recommends duplicating rerun logs on different disks.
If you copy it to another media or server before cyclic rewriting of the next rerun log file, you can get the following buns.
1. Simple backup - just make a full copy of the data files, for example, once a day, and the rest of the time just save the logs.
2. Backup server - further development of the idea. Logs are rolled onto a copy of the database deployed on the backup server, as they become available. When hour X arrives, data processing switches to the backup server.
3. Requests to the past - you can see the table data, which they were, for example, an hour and a half ago. And this can be done on a working basis, no need to “pick up” any backups.
Returning to the headline: what will happen if there is a sudden outage? After all, the data in the files will remain in an inconsistent state? Nothing wrong.
Consider an example: after the last successful write to the database file (time 1), the system confirmed 1 tanzation (time 2), then began to execute the 2nd one, the power turns off right during the recording to the database file (time 3).
So, the server is working again. The system reads the re-run log since the last successful write to disk (since time 1) and rolls back all changes. For this, the log contains all the necessary information. Then the system sequentially repeats all the operations (roll). Finds the COMMIT label (made during time 2) and commits the changes. Then continues to roll. It reaches the end of the repetition log (at this time point -3 - the power has turned off) and does not find the COMMIT mark. The rollback will be performed again, but already to the point (time 2).
The data is again in a consistent state!
Yes, all this information is useful, but what should developers pay attention to?
• The first non-obvious point - unlike other DBMSs in ORACLE, frequent COMMIT is harmful. Upon receipt of this command information, albeit in small quantities, should be written to disk. This process occurs as quickly as possible, but if you try to execute it after changing each record for the 10 millionth table ... The system is designed to do COMMIT when it is necessary from the point of view of business logic, and not more often.
The rollback of the transaction (ROLLBACK) should be avoided as much as possible, as a rule, the time to rollback is often comparable to the time of changes. UPDATE was running an hour, we decided to roll back, ROLLBACK will also run a comparable time. And the commit would have passed for a split second.
• The second point, for some reason not obvious to many developers, is that data changes never block reading. This must be remembered, but in general the implementation of simultaneous access to data from the point of view of the developer requires a separate article.
• The third point - do not be afraid of join'ov, it is not flawed MySQL. A properly tuned database will help maintain both data integrity and performance. HASH JOUN, MERGE JOIN, INDEX ORGANIZED TABLES, setting CARDINALITY, QUERY REWRITING and MATRIALIZED VIEW UPDATE ON COMMIT will allow the knowledgeable admin to achieve good speed. But maintaining a non-consistent denormalized system in order in a couple of years will be much more difficult.
• And finally - use related variables! This will allow you to significantly, often several times increase productivity at once and, as a free bonus, avoid SQL!

Conclusion - ORACLE has created a reliable DBMS, but how fast it will work depends on the developers. Non-optimal solutions will make any server ask for mercy.
Who does not want to read the theory - at the end of a couple of key points that every developer working with ORACLE should know. He may not know the SQL language, but he must know the features of COMMIT.
For DBA and other experts (in a good way) - the material is deliberately maximally simplified, due to this there are some inaccuracies. The goal was to convey the basic principles to an unprepared person.
In the beginning there was a file and there were tables with records of fixed length.
It's simple - new records were added to existing “holes” in the middle of the file instead of deleted ones, if there are no “holes” - to the end.
Quickly, but you have to reserve a lot of space just in case, for rare, unique data. So, one well-known Spaniard has the name "Pablo Diego Jose Francisco de Paula Juan Nepomukeno Crispin Crispiano de la Santisima Trinidad Ruiz and Picasso" - respectively, the full name field will have to be done with a large margin.
And no long descriptions or notes from several sentences.
When adding such lines to the end of the file, there is no problem, but when inserting into the middle of the file instead of deleted data and changing the data inside the lines (a couple of sentences were added to the product description), problems appear. The solution was invented by the developers of file systems and memory managers for a long time - to store data in blocks, when the data "spreads" across several blocks - to defragment. In addition, ORACLE allows you to leave an empty space there for future changes when creating a block, in case the length of the new record increases.
When the functionality was added, the speed dropped a lot. Defragmentation takes a lot of resources, it has to be limited. As a result, many records turned out to be “blurred” into blocks, and, worst of all, these blocks can physically be in different parts of the hard drive. The obvious solution - caching in the buffer cache - saves the situation when reading. When committing changes, all data must be written to disk (when it comes to critical applications, you can not rely on UPS), and preferably not one, but several, for backup. Moreover, the disks should be logical, redundancy exclusively by RAID means will not work, because, in case of the death of the controller, the entire array can go to the dump. And users, in addition, do not want to duplicate data files on the server - server disks are very expensive.
The solution was found - created - redo log, re-run log. After changing the data in the cache, all new and changed data is sequentially written to this file. If you select a separate disk for this task (or rather several on different controllers), the head will not jump, and the sequential write speed of the disks is high. Pay attention to the elegance of the solution - all changes are written to the log immediately, without waiting for the transaction to be committed. COMMIT only puts down a key marker, which takes a split second. If the transaction is rolled back, information about the changes still remains in the log file, but it ends with a rollback mark.
But what about data files? A process is periodically started that finds modified, so-called "dirty" blocks in the buffer cache and writes them to disk. Due to the "wholesale" processing, the speed and reaction time of the system are increased.
So that the size of the re-run logs does not increase indefinitely, log rotation is used. ORACLE makes sure that when the log files are cyclically changed, all “dirty” blocks get into the data files.
From this scheme follows a feature that is not obvious at first glance, which struck me at one time to the depths of my soul. What to do with the changed blocks which are not confirmed by COMMIT but are no longer placed in the buffer cache? Write changes to temporary file? No, ORACLE writes these changes directly to the data files. Yes, in a system that is initially oriented towards increased reliability, data files may contain non-consistent, not committed COMMIT ”data, and this is normal, it is part of the work process. Instead, the DBMS backs up the changed blocks in special UNDO files. Here, this reserve is maintained until the transaction is committed, and allows other transactions to read data while another transaction changes them. Yes, in ORACLE, changes do not block reading. These are the basics
And - all UNDO changes are also recorded in the redo log.
Thus, the re-run log contains information about all added data, as well as data before and after the change. These logics are very important, only with the help of them can data files be brought into the correct, consistent state. ORACLE recommends duplicating rerun logs on different disks.
If you copy it to another media or server before cyclic rewriting of the next rerun log file, you can get the following buns.
1. Simple backup - just make a full copy of the data files, for example, once a day, and the rest of the time just save the logs.
2. Backup server - further development of the idea. Logs are rolled onto a copy of the database deployed on the backup server, as they become available. When hour X arrives, data processing switches to the backup server.
3. Requests to the past - you can see the table data, which they were, for example, an hour and a half ago. And this can be done on a working basis, no need to “pick up” any backups.
Returning to the headline: what will happen if there is a sudden outage? After all, the data in the files will remain in an inconsistent state? Nothing wrong.
Consider an example: after the last successful write to the database file (time 1), the system confirmed 1 tanzation (time 2), then began to execute the 2nd one, the power turns off right during the recording to the database file (time 3).
So, the server is working again. The system reads the re-run log since the last successful write to disk (since time 1) and rolls back all changes. For this, the log contains all the necessary information. Then the system sequentially repeats all the operations (roll). Finds the COMMIT label (made during time 2) and commits the changes. Then continues to roll. It reaches the end of the repetition log (at this time point -3 - the power has turned off) and does not find the COMMIT mark. The rollback will be performed again, but already to the point (time 2).
The data is again in a consistent state!
Yes, all this information is useful, but what should developers pay attention to?
• The first non-obvious point - unlike other DBMSs in ORACLE, frequent COMMIT is harmful. Upon receipt of this command information, albeit in small quantities, should be written to disk. This process occurs as quickly as possible, but if you try to execute it after changing each record for the 10 millionth table ... The system is designed to do COMMIT when it is necessary from the point of view of business logic, and not more often.
The rollback of the transaction (ROLLBACK) should be avoided as much as possible, as a rule, the time to rollback is often comparable to the time of changes. UPDATE was running an hour, we decided to roll back, ROLLBACK will also run a comparable time. And the commit would have passed for a split second.
• The second point, for some reason not obvious to many developers, is that data changes never block reading. This must be remembered, but in general the implementation of simultaneous access to data from the point of view of the developer requires a separate article.
• The third point - do not be afraid of join'ov, it is not flawed MySQL. A properly tuned database will help maintain both data integrity and performance. HASH JOUN, MERGE JOIN, INDEX ORGANIZED TABLES, setting CARDINALITY, QUERY REWRITING and MATRIALIZED VIEW UPDATE ON COMMIT will allow the knowledgeable admin to achieve good speed. But maintaining a non-consistent denormalized system in order in a couple of years will be much more difficult.
• And finally - use related variables! This will allow you to significantly, often several times increase productivity at once and, as a free bonus, avoid SQL!
Conclusion - ORACLE has created a reliable DBMS, but how fast it will work depends on the developers. Non-optimal solutions will make any server ask for mercy.