Orchestrated saga or how to build business transactions in services with the pattern database per service
Hello! My name is Konstantin Evteev, I work in Avito as the head of the DBA unit. Our team develops Avito's data storage systems, assists in selecting or issuing databases and related infrastructure, supports Service Level Objective for database servers, and we are also responsible for efficient use of resources and monitoring, advising on design, and possibly developing microservices, tied to storage systems or services for the development of the platform in the context of storage.
I want to tell how we decided one of the challenges of the microservice architecture - carrying out business transactions in the infrastructure of services built using the Database per service pattern. I spoke on this topic at the Highload ++ Siberia 2018 conference .

Theory. As briefly as possible
I will not describe in detail the theory of sagas. I will give only a brief introductory, so that you understand the context.
As it was before (from the start of Avito until 2015 - 2016): we lived in a monolith, with monolithic bases and monolithic applications. At a certain point, these conditions began to prevent us from growing. On the one hand, we came up against the performance of the server with the main base, but this is not the main reason, since the performance issue can be solved, for example, using sharding. On the other hand, the monolith has a very complicated logic, and at a certain stage of growth, the delivery of changes (releases) becomes very long and unpredictable: there are a lot of unobvious and complex dependencies (everything is closely related), testing is also time consuming, in general there are a lot of problems. The solution is to switch to microservice architecture. At this stage, we have a question with business transactions strongly tied to ACID, provided by a monolithic base: There is no clarity on how to migrate this business logic. When working with Avito, there are many different scenarios implemented by several services where integrity and consistency of data is very important, for example, buying a premium subscription, writing off money, applying services to a user, purchasing VAS packages — in unexpected circumstances or accidents, everything might not go unexpectedly. according to plan. We found the solution in the sagas.
I like the datasheetThe saga that Kenneth Salem led in 1987 and Hector Garcia-Molina is one of the current members of the Oracle board of directors. As the problem was formulated: there are a relatively small number of long-lived transactions, which for a long time prevent the implementation of small, less resource-intensive and more frequent operations. As a desired result, you can give an example from life: surely many of you were queuing to otkerokopirovat documents, and the operator Xerox, if he had the task to copy a whole book, or just many copies, from time to time made copies of other members of the queue. But resource utilization is only part of the problem. The situation is aggravated by long-term locks when performing resource-intensive tasks, a cascade of which will line up in your DBMS. Besides, Errors can occur during a long transaction: the transaction will not end and rollback will begin. If the transaction was long, the rollback will also take a long time, and probably will still be retry from the application. In general, "everything is quite interesting." The solution proposed in the technical description of "SAGAS": split the long transaction into parts.
It seems to me that many approached this without even reading this document. We have repeatedly talked about our defproc (deferred procedures implemented with pgq). For example, when blocking a user for fraud, we quickly execute a short transaction and respond to the client. In this short transaction, including, we set the task in the transaction queue, and then asynchronously, in small batches, for example, with ten announcements, block its declarations. We did this by implementing the transaction queues from Skype .
But our story today is a little different. We need to look at these problems from the other side: cutting the monolith into microservices built using the database per service pattern.
One of the most important parameters for us is reaching the maximum cutting speed. Therefore, we decided to transfer the old functionality and all the logic as it is to microservices, without changing anything at all. Additional requirements that we needed to fulfill:
- provide dependent data changes for business critical data;
- be able to set a strict order;
- Comply with 100% consistency - reconcile data even in case of accidents;
- guarantee the operation of transactions at all levels.
Under the above requirements, the most appropriate solution is in the form of an orchestrated saga.
Implementing orchestrated saga as a PG Saga service
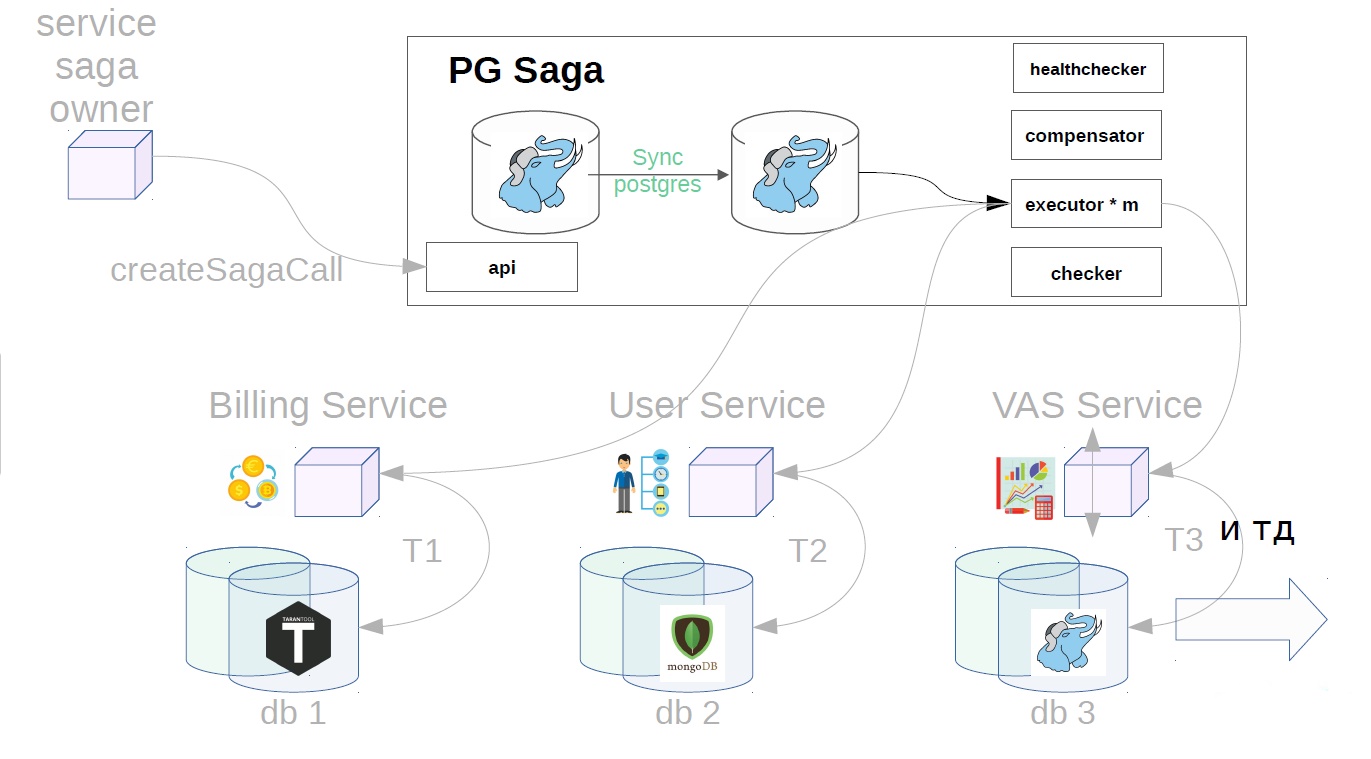
This is the PG Saga service.
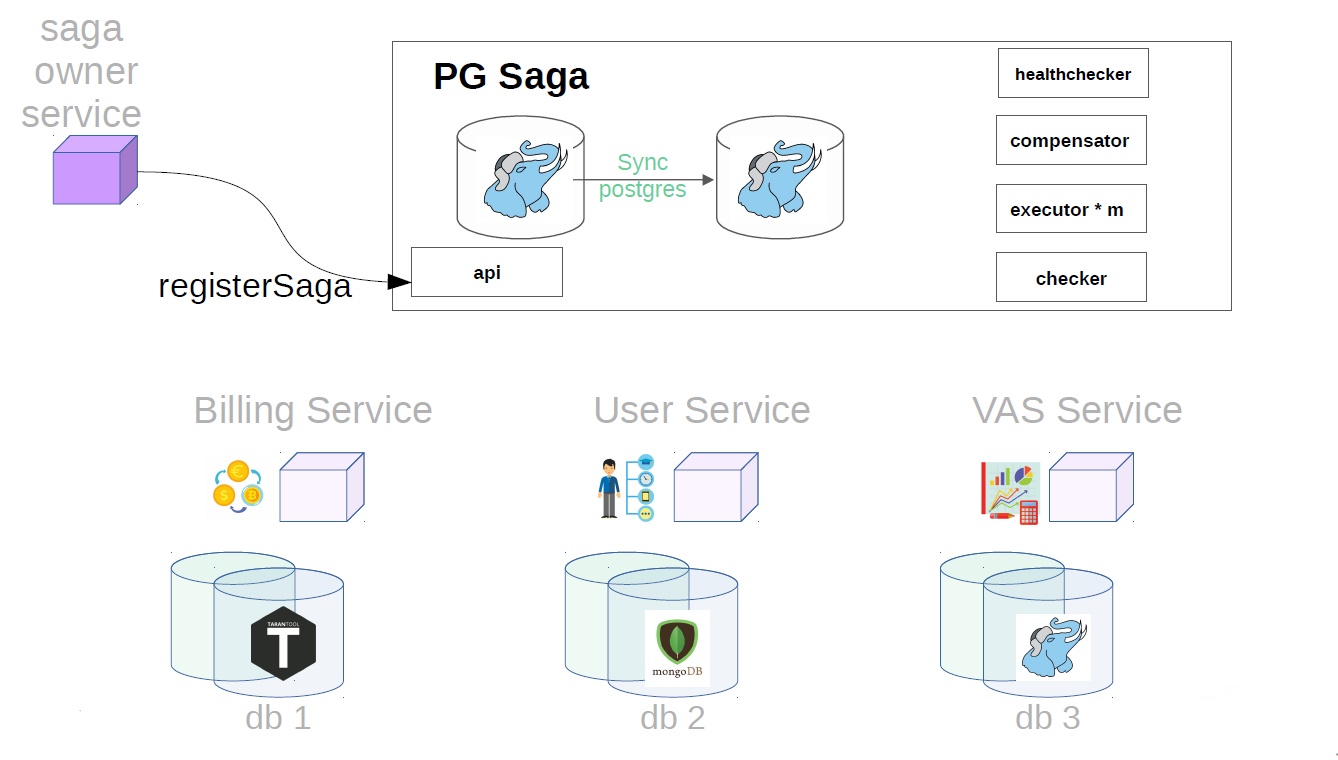
PG in the title, because as a service store uses synchronous PostgreSQL. What else is inside:
- API;
- executor;
- checker;
- healthchecker;
- compensator.
The diagram also shows the service owner of the sagas, and below - the services that will perform the steps of the saga. They may have different stores.
How it works
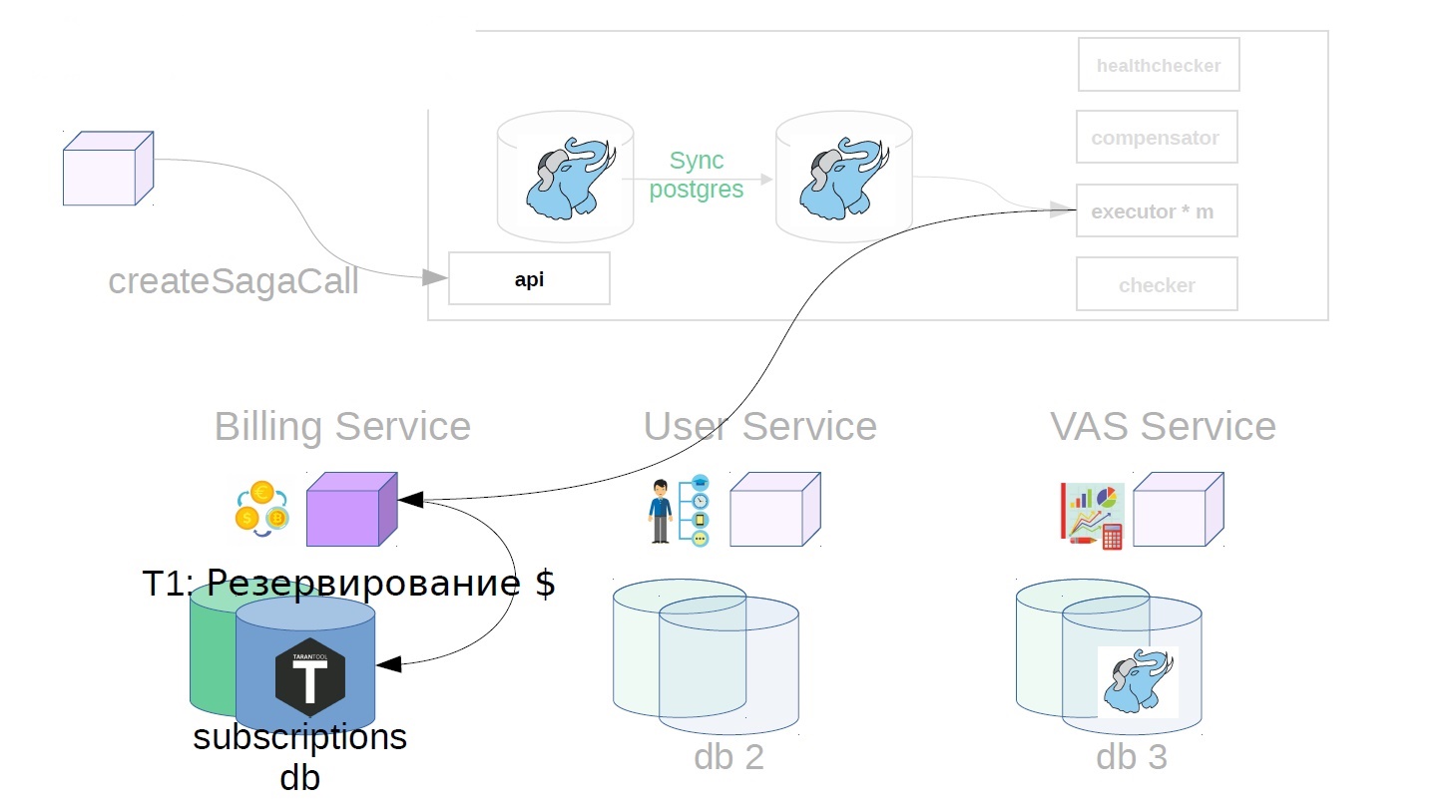
Consider the example of buying VAS-packages. VAS (Values-added services) - paid services to advertise.
First, the service owner of the saga must register the creation of the saga in the service saga
After that, it generates the saga class already with Payload.
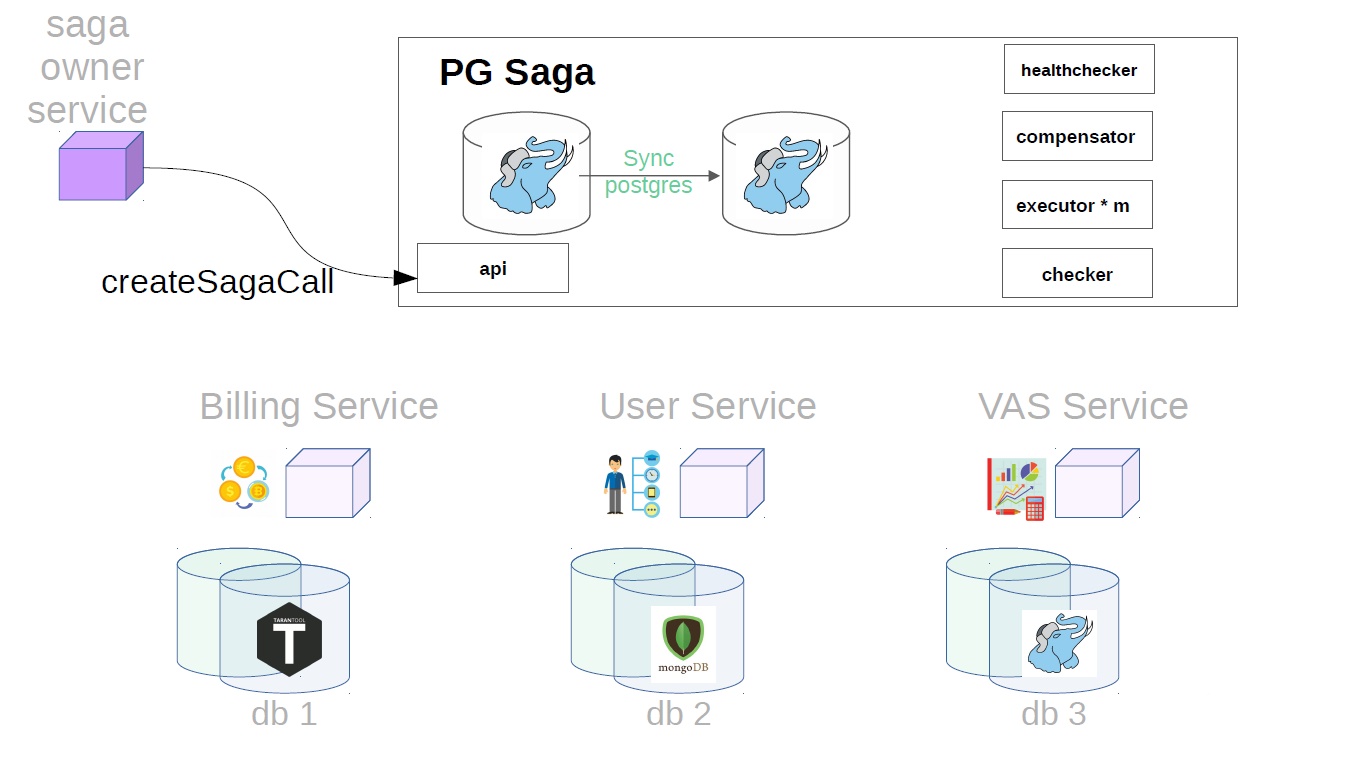
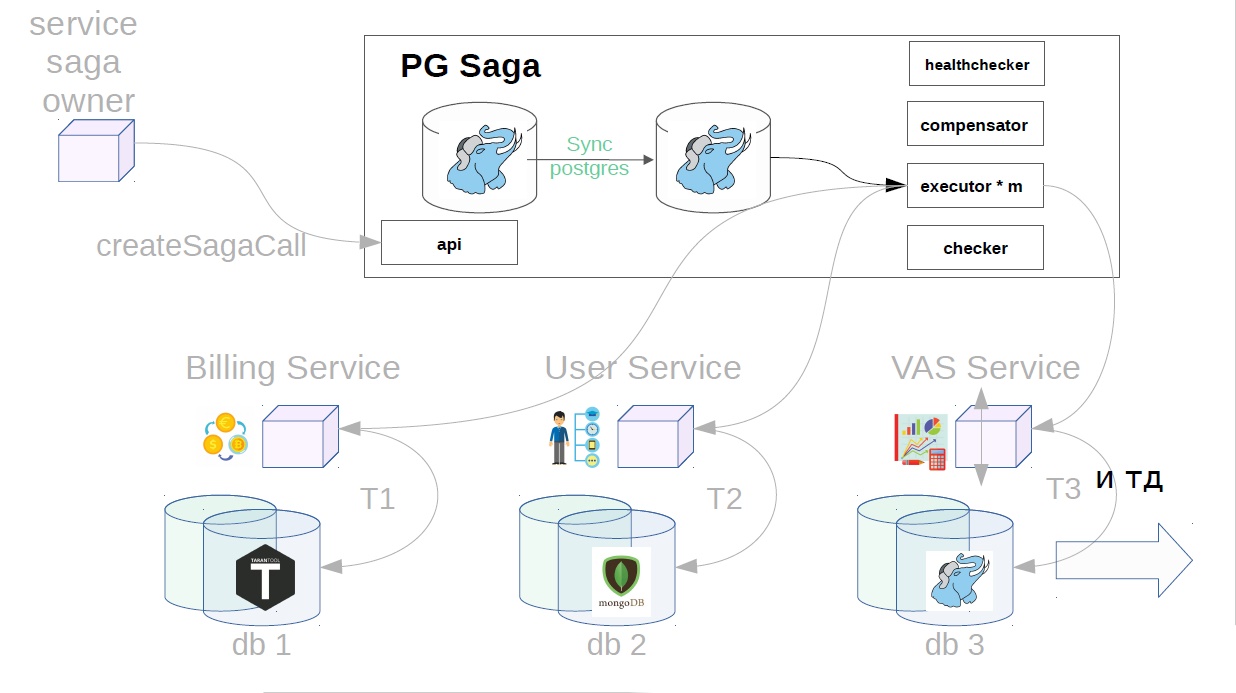
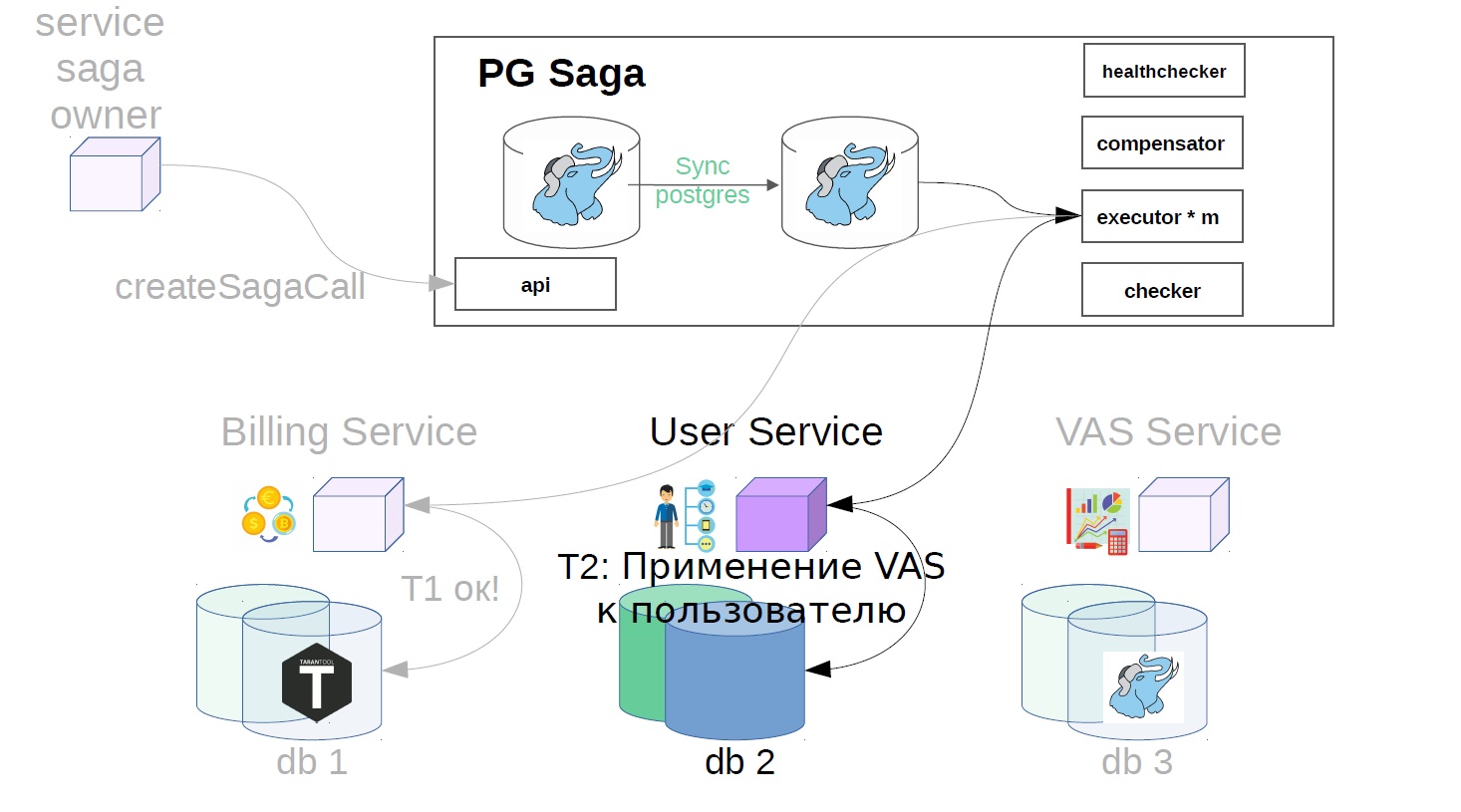
Then, already in the saga service, executor picks up the previously created saga call from the storage and starts to perform it step by step. The first step in our case is the purchase of a premium subscription. At this point, money is reserved in the billing service.

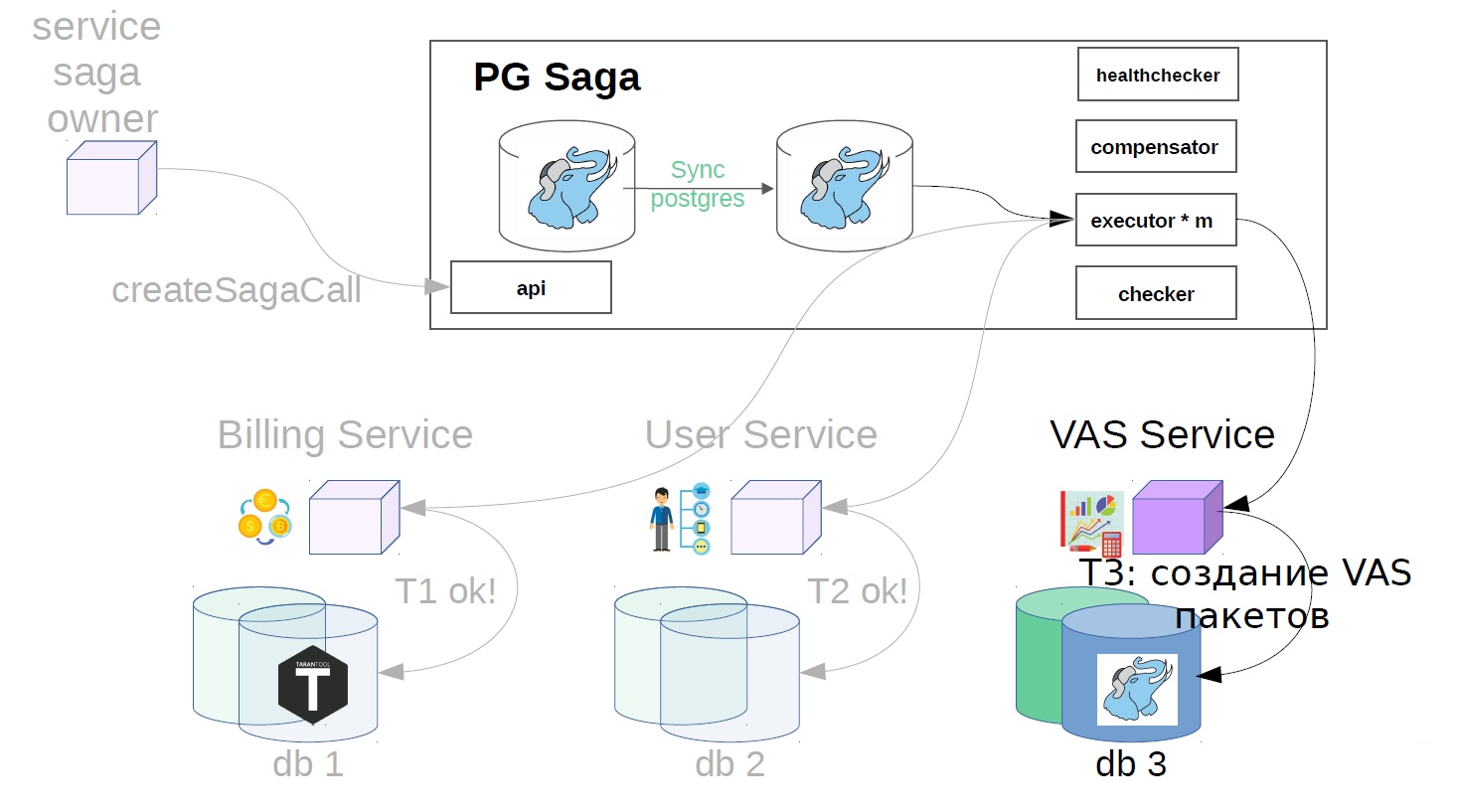
Then, in the user service, VAS operations are applied.
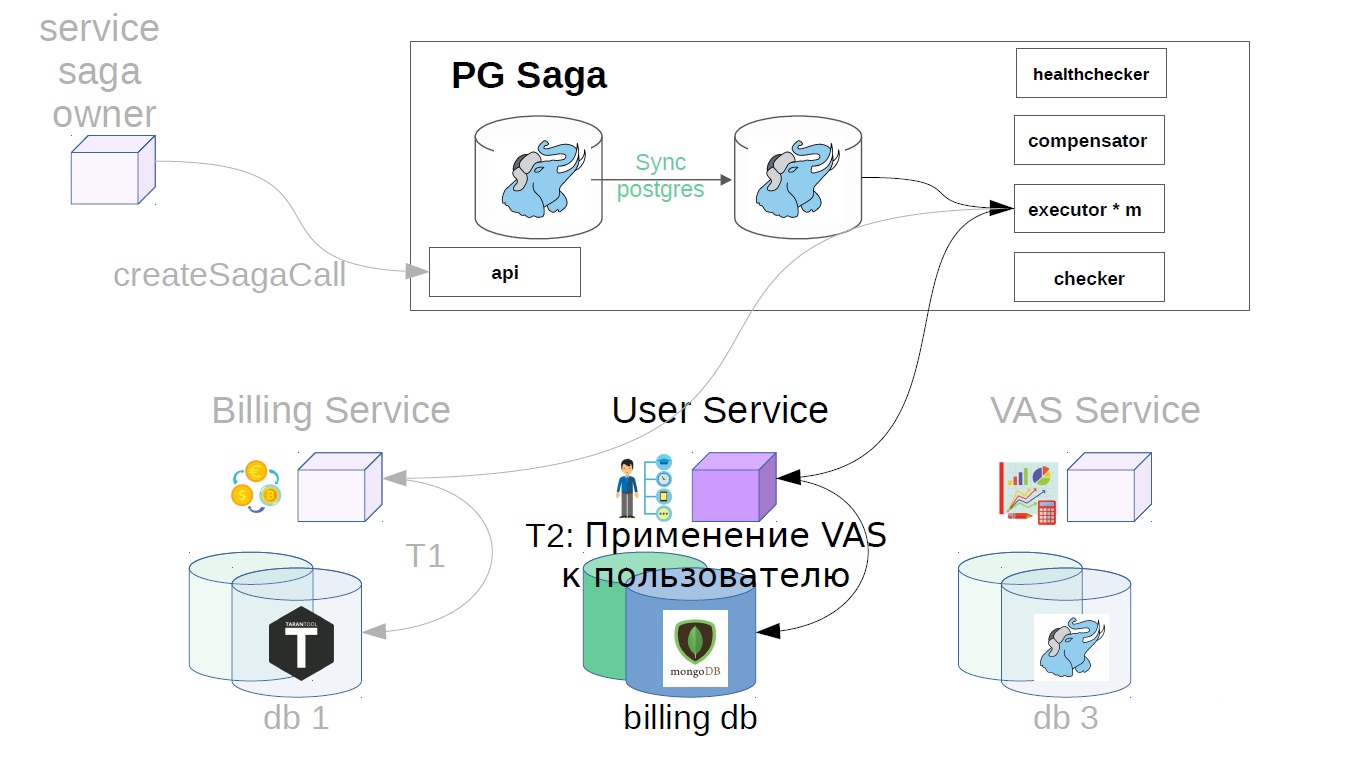
Then, VAS services are already in effect, and packages of WAS are created. Further steps are possible, but they are not so important to us.
Accidents
Accidents can happen in any service, but there are well-known tricks on how to prepare for them. In a distributed system, it is important to know about these techniques. For example, one of the most important limitations is that the network is not always reliable. Approaches to solve interoperability problems in distributed systems:
- Retry.
- Mark each operation with an idempotent key. This is to avoid duplication of operations. You can read more about idempotent keys in this article.
- Compensate for transactions - an action characteristic of the sagas.
Transaction Compensation: How It Works
For each positive transaction, we need to describe the reverse actions: the business scenario of a step in case something goes wrong.
In our implementation, we offer the following compensation scenario:
If a step of the saga ended in failure, and we did a lot of retry, then there is a chance that the last repetition of the operation was a success, but we just did not get an answer. Let's try to compensate for the transaction, although this step is not necessary if the service provider of the problem step has really broken and is completely inaccessible.
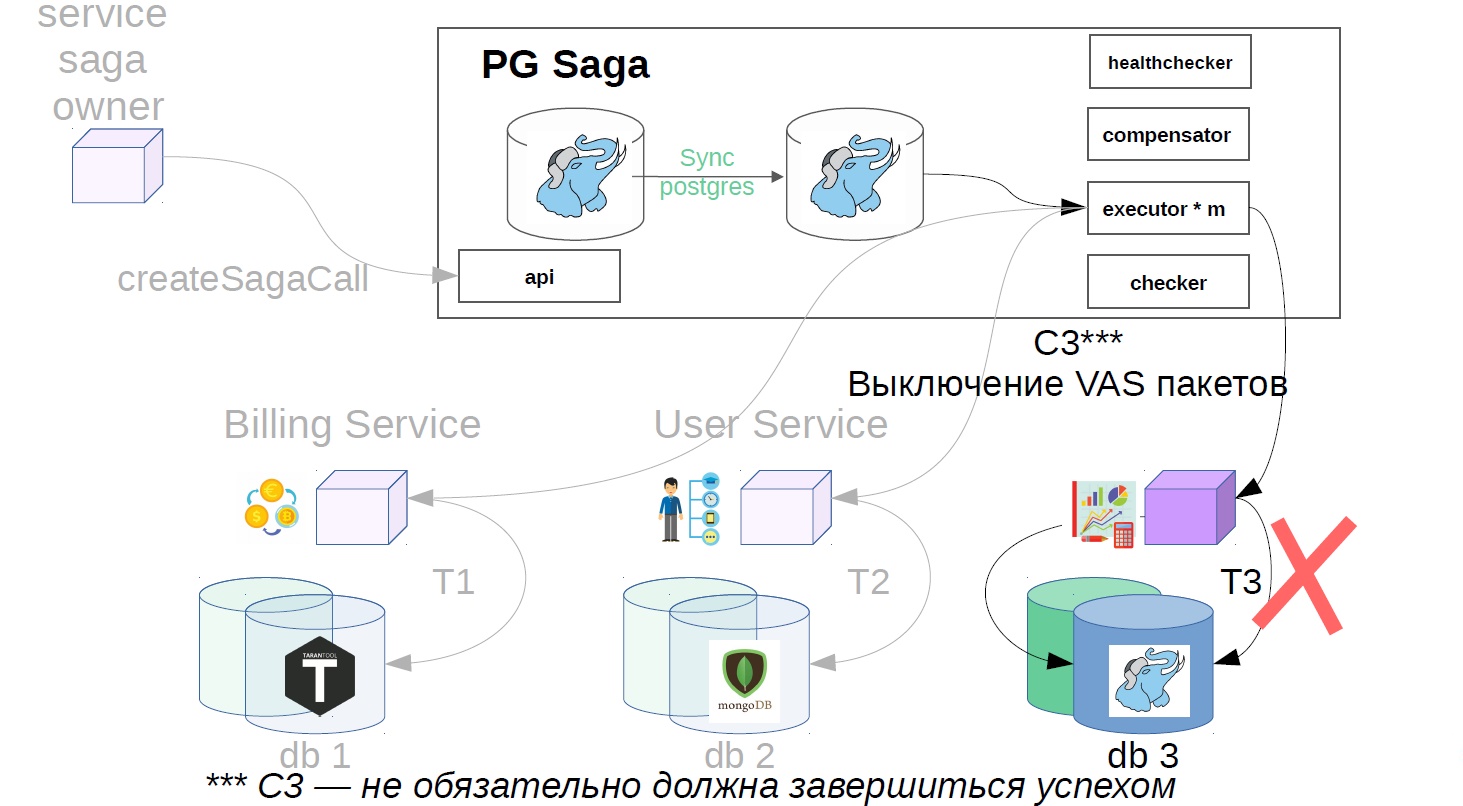
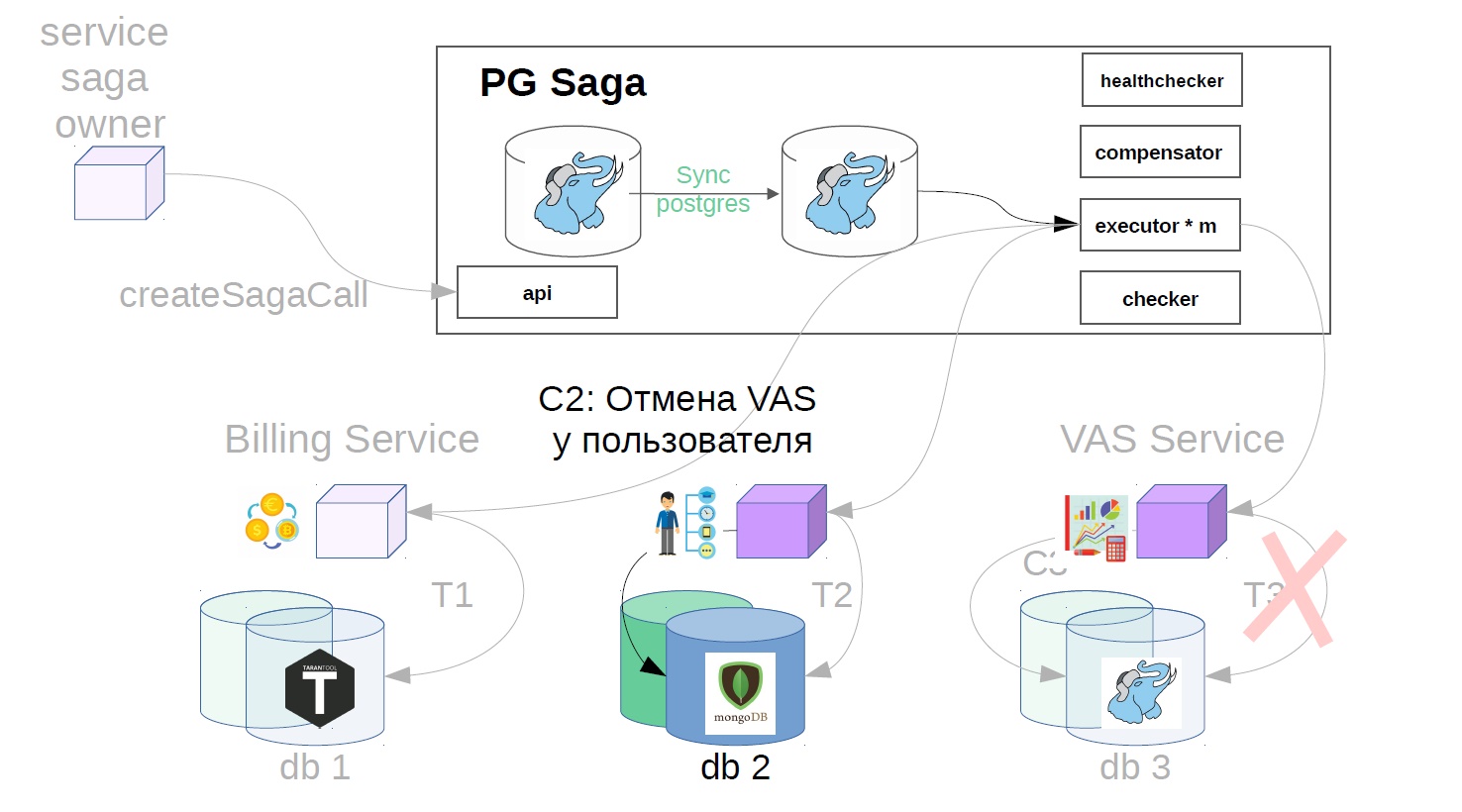
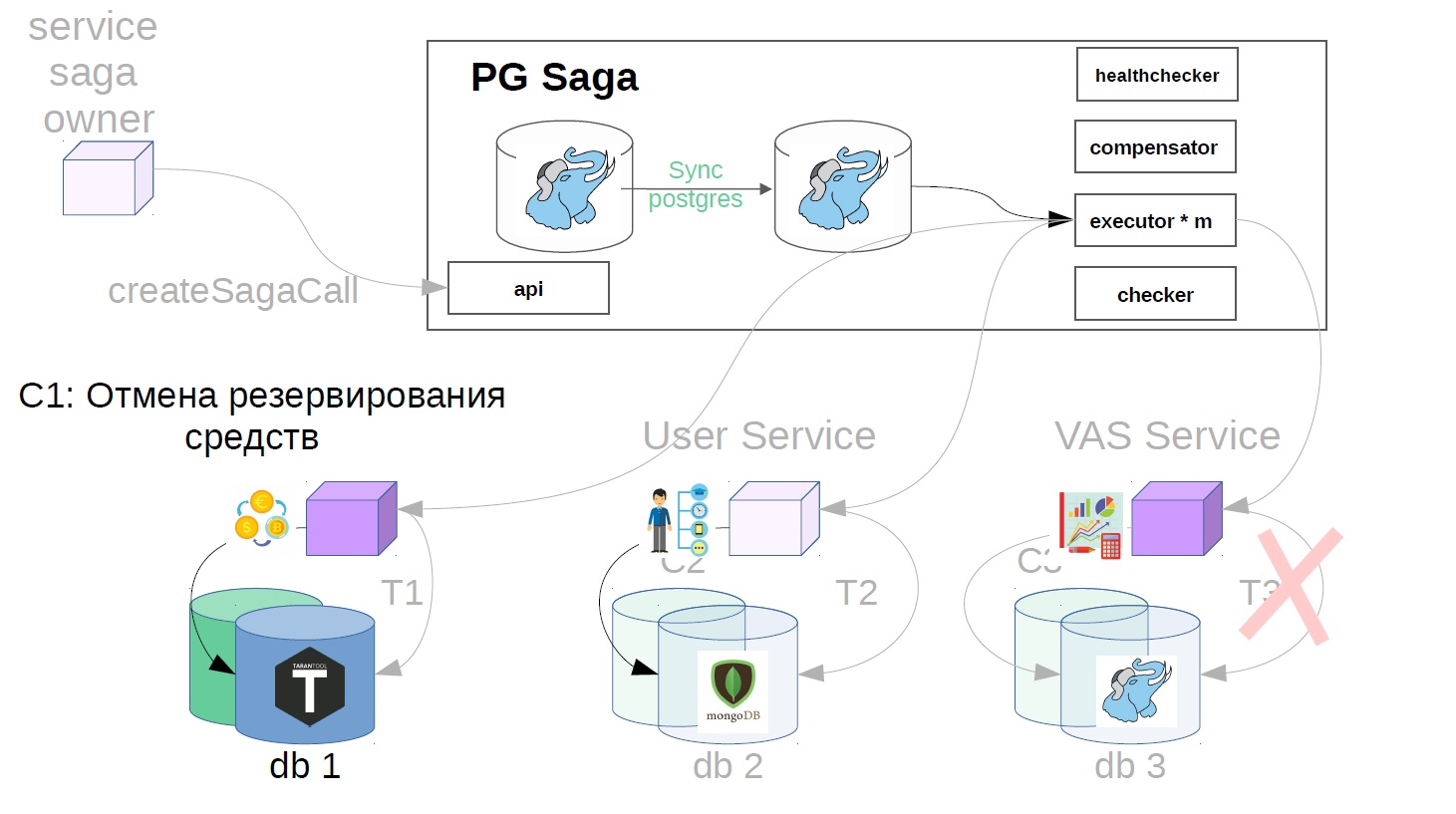
In our example, it will look like this:
- Turn off VAS packages.
- We cancel user operation.
- We cancel the reservation of funds.
What to do if compensation does not work
Obviously, it is necessary to act on approximately the same scenario. Again, use retry, idempotent keys for compensating transactions, but if nothing comes out and this time, for example, the service is not available, you need to contact the service-owner of the saga, informing you that the saga has been merged. Further more serious actions: to escalate the problem, for example, for a manual trial or launch of automation to solve such problems.
What else is important: Imagine that any step of the saga service is not available. Surely the initiator of these actions will still do some kind of retry. As a result, your saga service takes the first step, the second step, and its performer is unavailable, you cancel the second step, cancel the first step, and anomalies related to the lack of isolation may occur. In general, the saga service in this situation is engaged in useless work, which still generates pressure and errors.
How to do? Healthchecker should poll the services that perform the steps of the saga, and see if they work. If the service has become unavailable, then there are two ways: the sagas that are in operation - to compensate, and the new sagas - either to prevent the creation of new instances (calls), or to create, without taking them into work with the executer, so that the service does not work unnecessary actions.
Another accident scenario
Imagine that we are again making the same premium subscription.
- We buy VAS-packages and reserve money.
- Apply to the user of the service.
- We create VAS packages.
It seems to be good. But suddenly, when the transaction is completed, it turns out that the user service uses asynchronous replication and an accident has occurred on the master base. There can be several reasons for a replica lagging: the presence of a specific load on a replica, which either slows replication playback speed or blocks replication playback. In addition, the source (master) is overloaded, and a lag of sending changes appears on the source side. In general, for some reason, the replica was lagging behind, and the changes of the successfully completed step after the accident suddenly disappeared (result / condition).
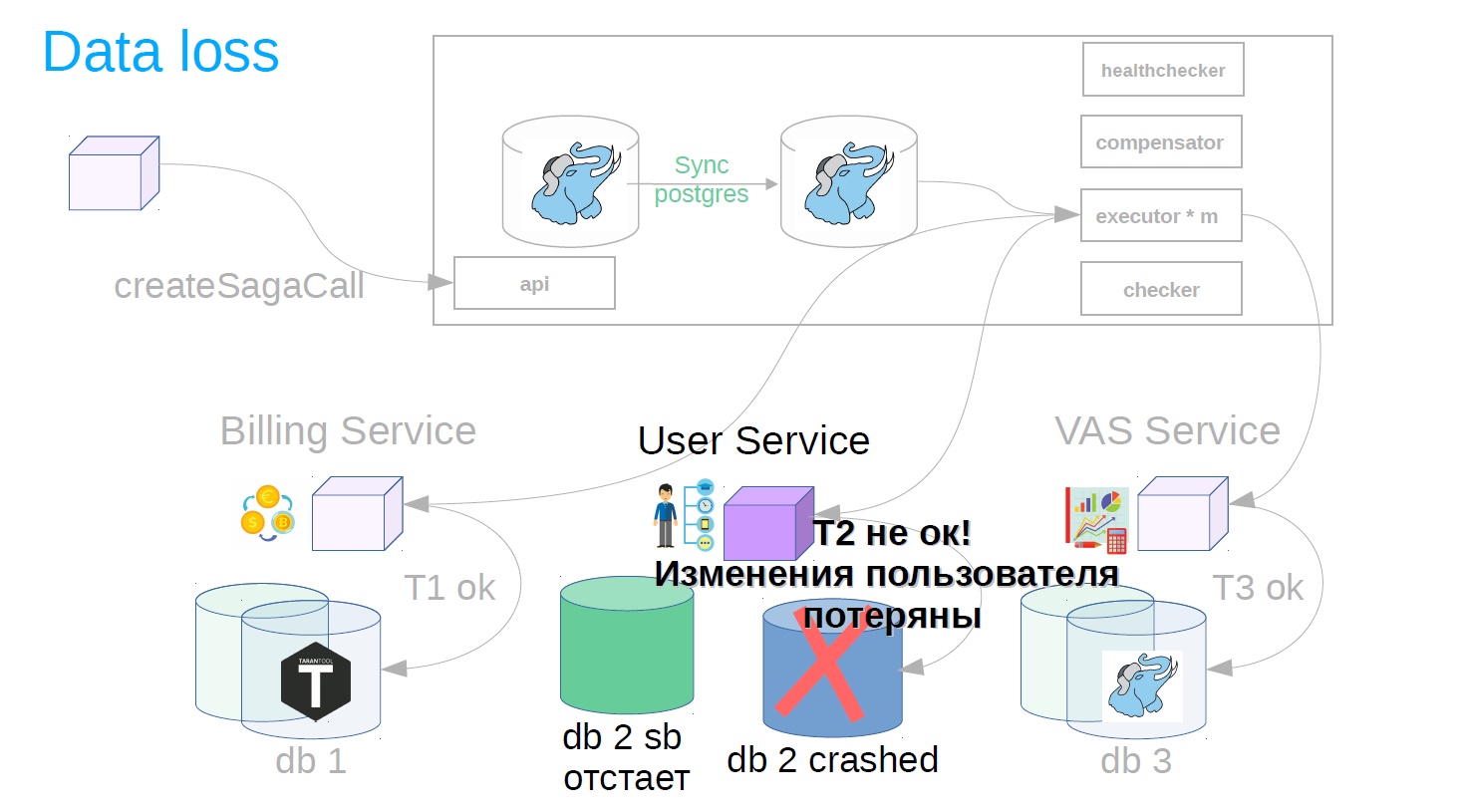
To do this, we implement another component in the system - use the checker. The checker goes through all the steps of successful sagas through time that is obviously greater than all possible lags (for example, after 12 hours), and checks whether they have been successfully completed until now. If the step is suddenly not executed, the saga rolls back.
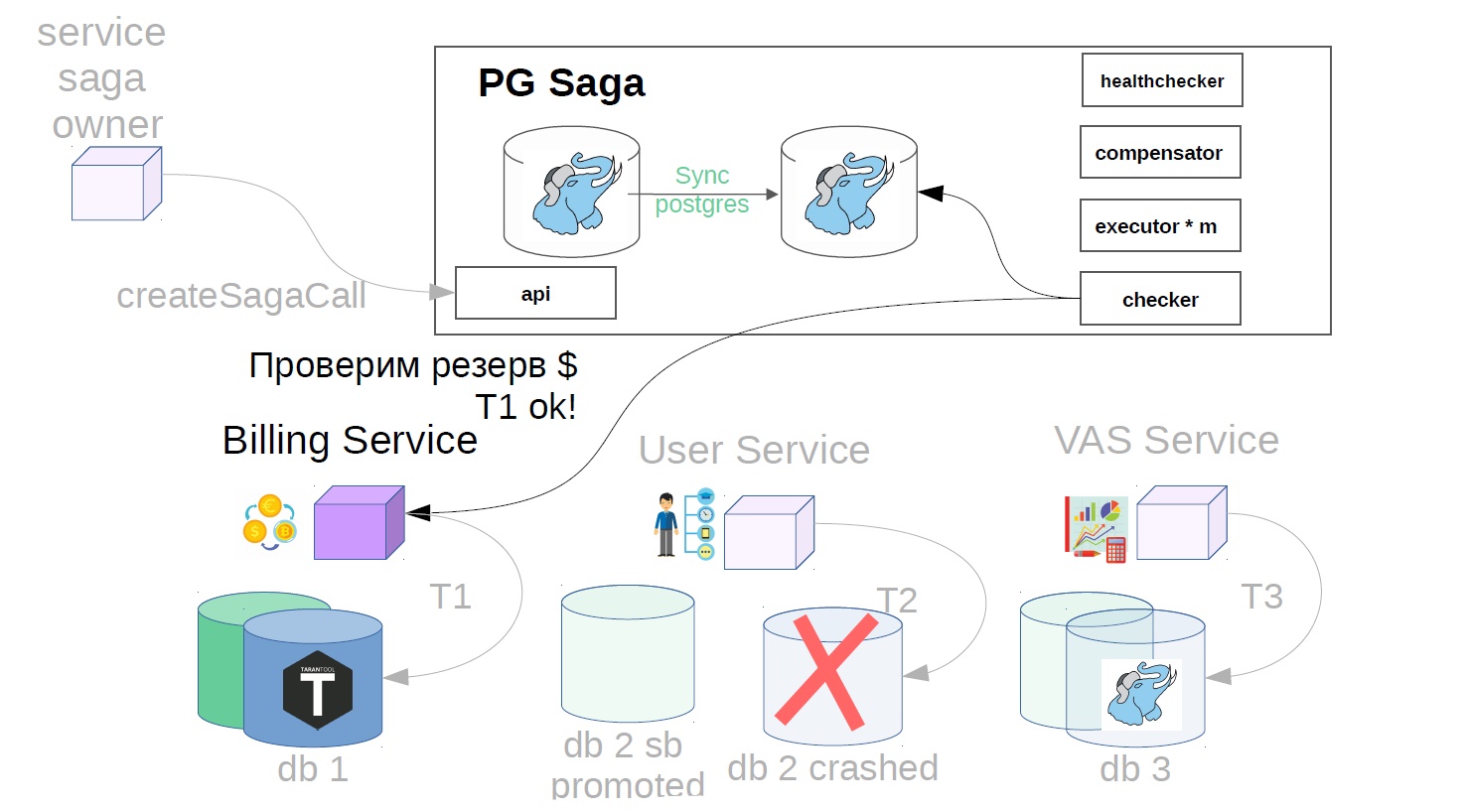
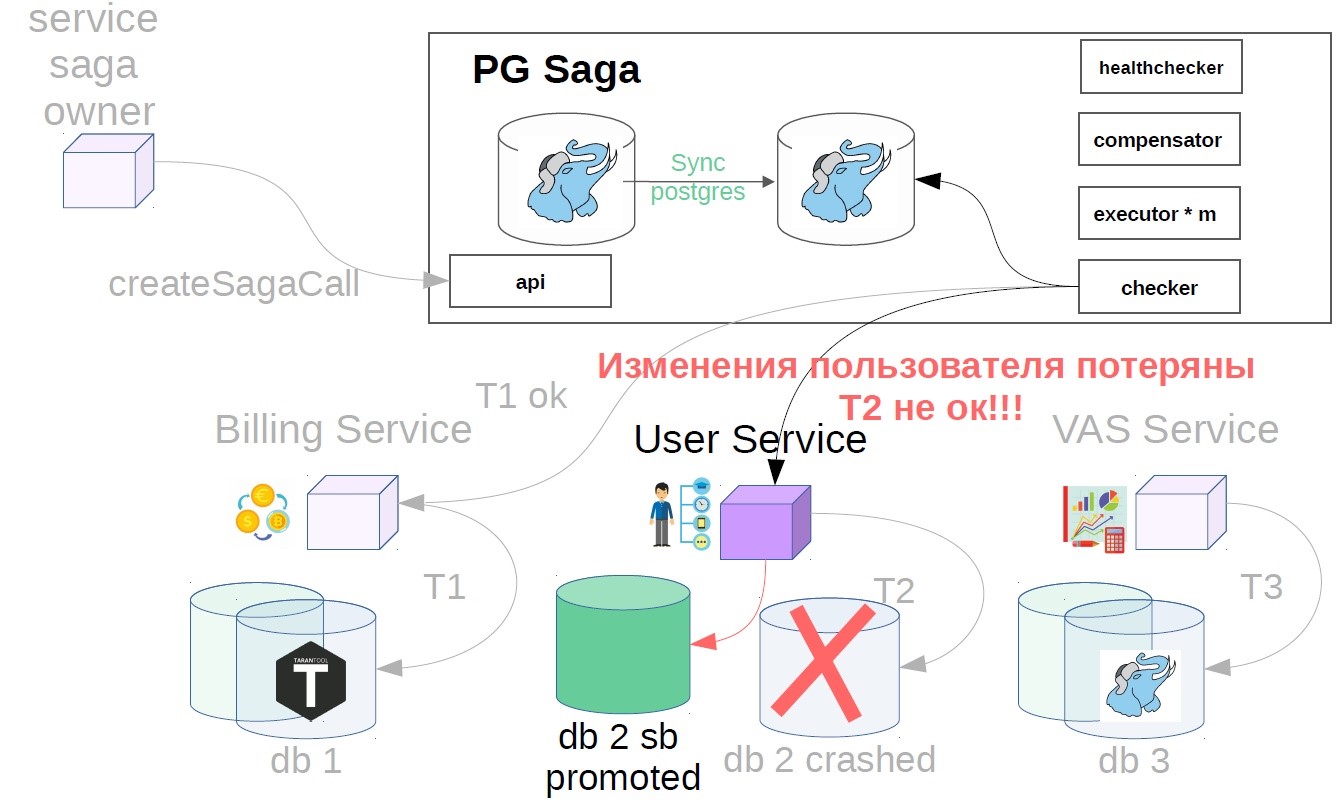
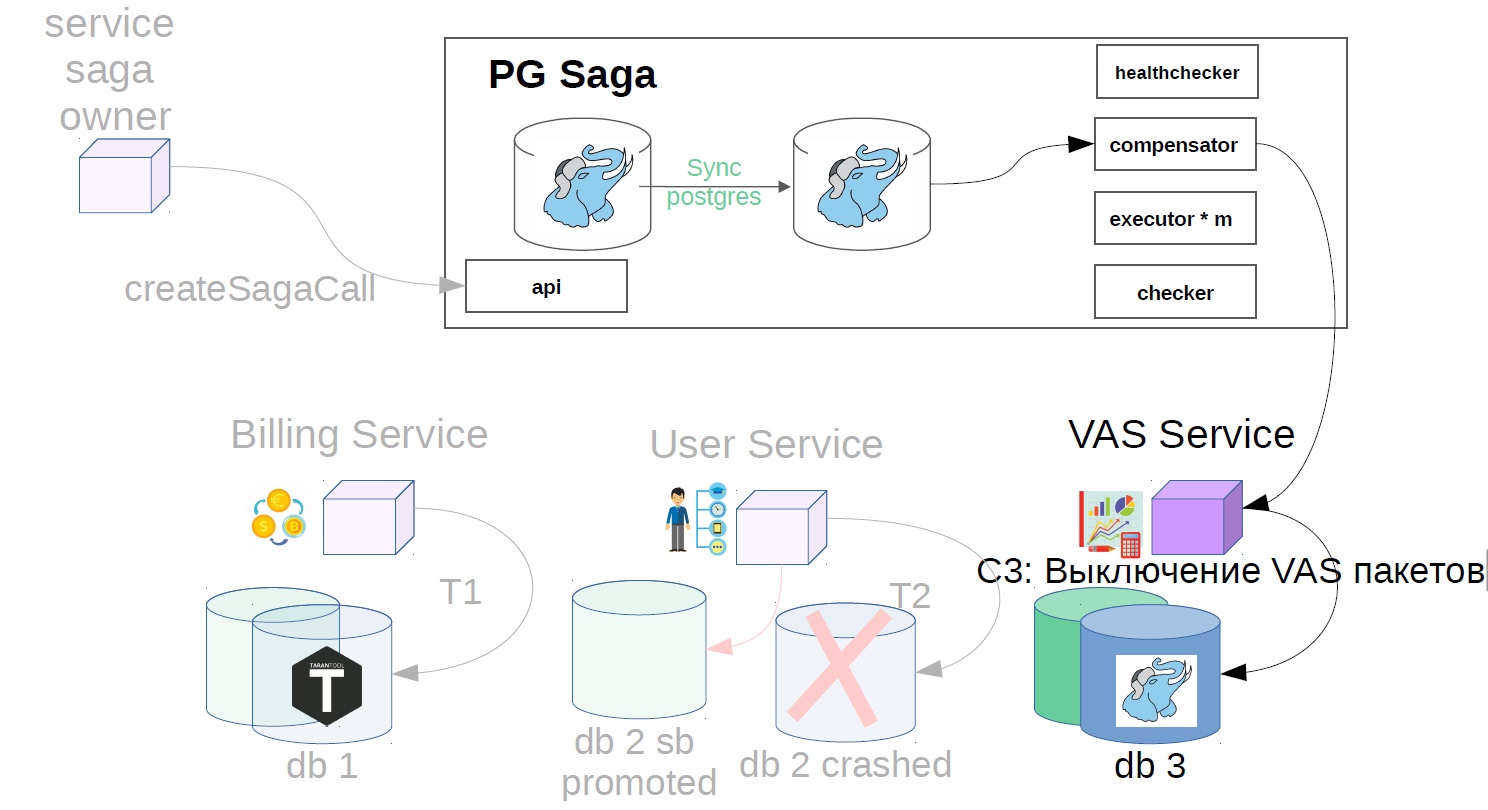
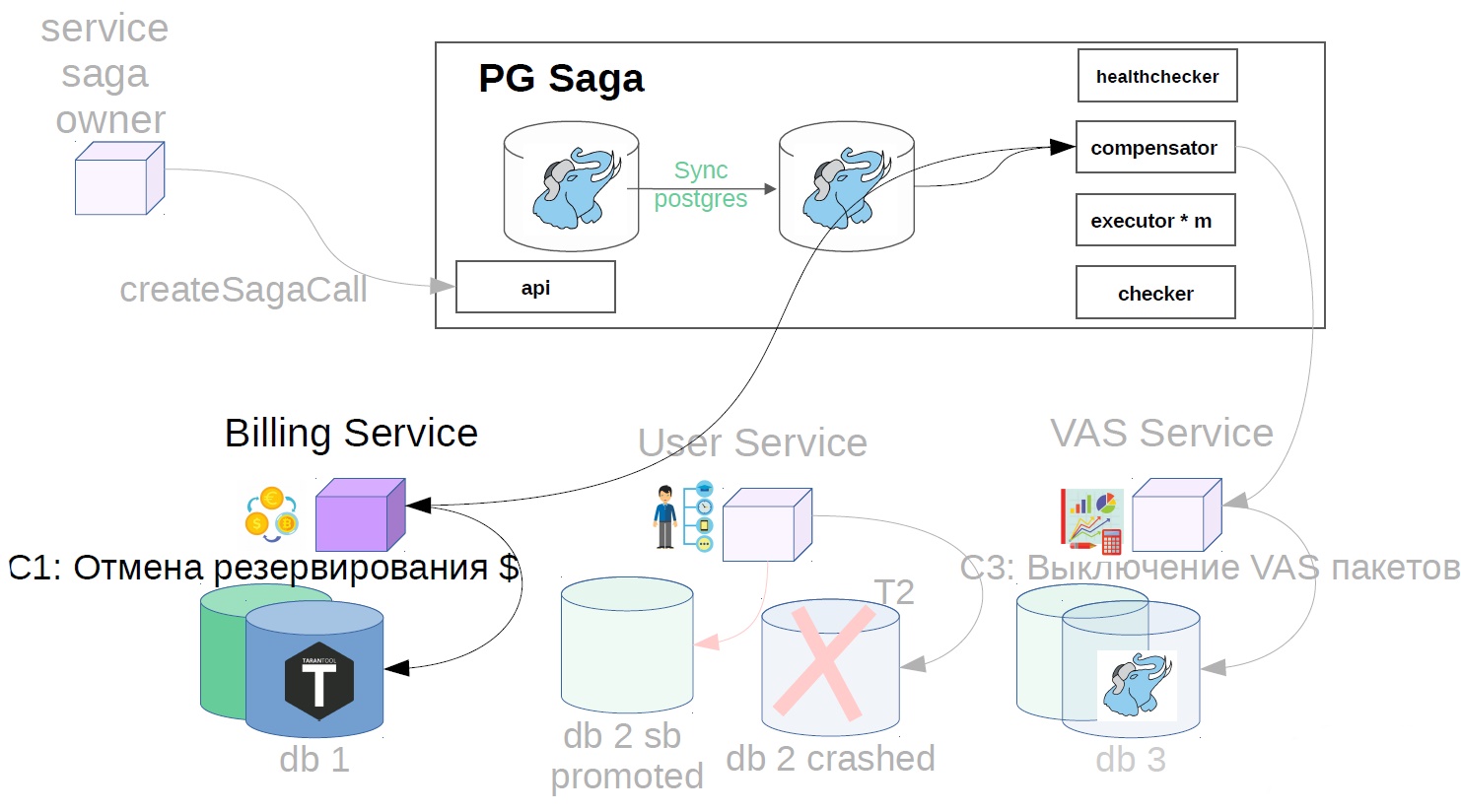
There may still be situations when, after 12 hours, there is already nothing left to cancel - everything changes and moves. In this case, instead of the cancellation scenario, the solution may be an alarm to the service of the owner of the saga that this operation has not been completed. If the cancellation operation is impossible, say, you need to cancel after the money is credited to the user, and his balance is already zero, and the money cannot be written off. We have such scenarios are always solved in the direction of the user. You may have another principle, this is consistent with product representatives.
As a result, as you can see, in different places for the integration with the sagas service you need to implement a lot of different logic. Therefore, when client teams want to create a saga, they will have a very large set of very unobvious tasks. First of all, we create a saga so that duplication does not work out, for this we work with some idempotent operation of creating a saga and its tracking. Also, the services need to realize the ability to track every step of each saga, in order not to execute it twice on the one hand, and to be able to answer whether it was executed on the other hand. And all these mechanisms must somehow be maintained so that the service repositories do not overflow. In addition, there are many languages in which services can be written, and a huge selection of repositories. At each stage, you need to understand the theory and implement all this logic in different parts. If you do not, you can make a whole bunch of mistakes.
There are many correct ways, but there are no less situations where you can “shoot yourself a limb”. In order for the sagas to work correctly, all the above mechanisms should be encapsulated in client libraries that will transparently implement them for your clients.
An example of saga generation logic that can be hidden in the client library
You can do it differently, but I suggest the following approach.
- We get the request ID, on which we have to create a saga.
- We go to the saga service, we get its unique identifier, we save it in the local storage in conjunction with the request ID from item 1.
- We start the saga with payload in the saga service. An important caveat: I suggest local operations of the service, which creates a saga, to arrange as the first step of the saga.
- There is a kind of race when the saga service can perform this step (point 3), and our backend, which initiates the creation of the saga, will also perform it. To do this, we do idempotent operations everywhere: one of them performs it, and the second call simply receives “OK”.
- We call the first step (point 4) and only after that we answer the client who initiated this action.
In this example, we work with the saga as with a database. You can send a request, and then the connection may be terminated, but the action will be executed. Here is about the same approach.
How to check it all
It is necessary to cover the entire service sagas tests. Most likely, you will make changes, and tests written at the start will help to avoid unexpected surprises. In addition, it is necessary to check the sagas themselves. For example, how we have arranged the testing of the service of the sagas and the testing of the sequence of the sagas in one transaction. There are different blocks of tests. If we are talking about the saga service, he is able to perform positive transactions and compensation transactions, if the compensation does not work, he informs the service owner of the sagas. We write tests in general, to work with an abstract saga.
On the other hand, positive transactions and compensation transactions on services that perform the steps of the sagas are the same simple API, and tests of this part are in the area of responsibility of the team owning this service.
And then the team owner of the saga writes end-to-end tests, where it checks that all business logic works correctly when the saga is executed. The end-to-end test takes place on a full-fledged dev-environment, all instances of services, including the service sagas, are raised, and the business scenario is being tested there.
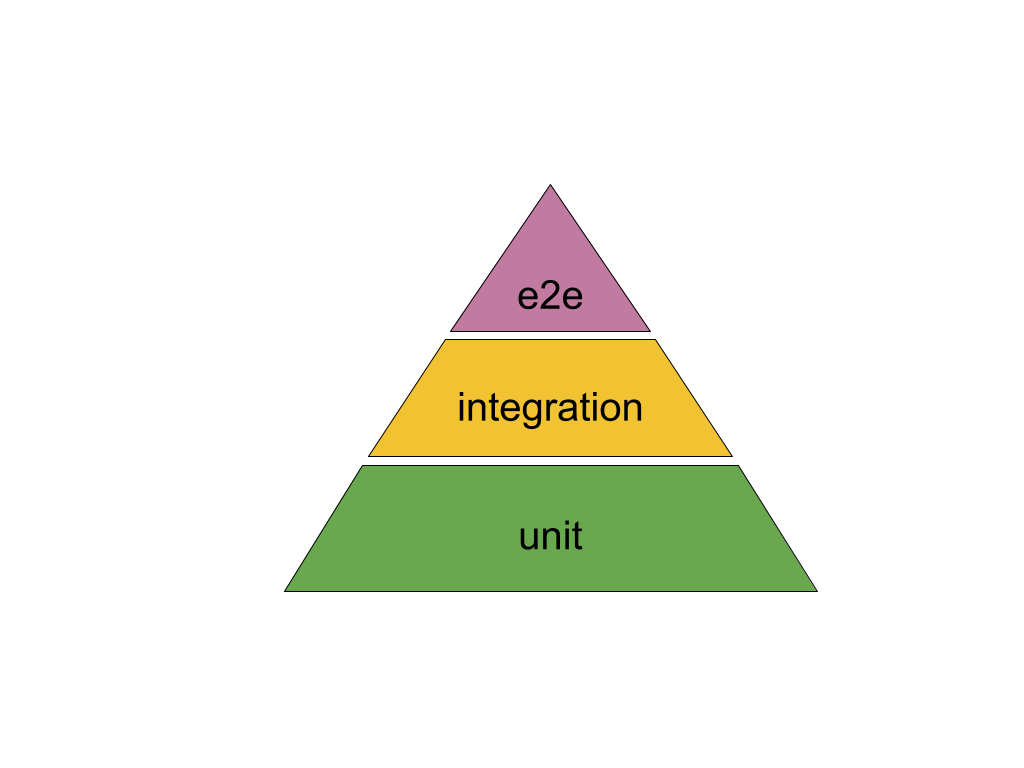
Total:
- write more unit tests;
- write integration tests;
- write end-to-end tests.
The next step is the CDC. Microservice architecture affects the specifics of tests. In Avito, we adopted the following approach to testing microservice architecture: Consumer-Driven Contracts. This approach helps, above all, to highlight the problems that can be identified in the end-to-end tests, but the end-to-end test is “very expensive.”
What is the essence of the CDC? There is a service that provides a contract. It has an API - this is a provider. And there is another service that calls the API, that is, uses the contract - the consumer.
Service-consumer writes tests for the provider contract, and the tests that only the contract will check are non-functional tests. It is important for us to ensure that if we change the API, we will not break steps in this context. After we have written the tests, another service broker element appears - it records the information on CDC tests. With each change of the service provider, he will raise the isolated environment and run the tests that are written by the consumer. What is the result: the team that generates the sagas, writes tests for all the steps of the saga and registers them.
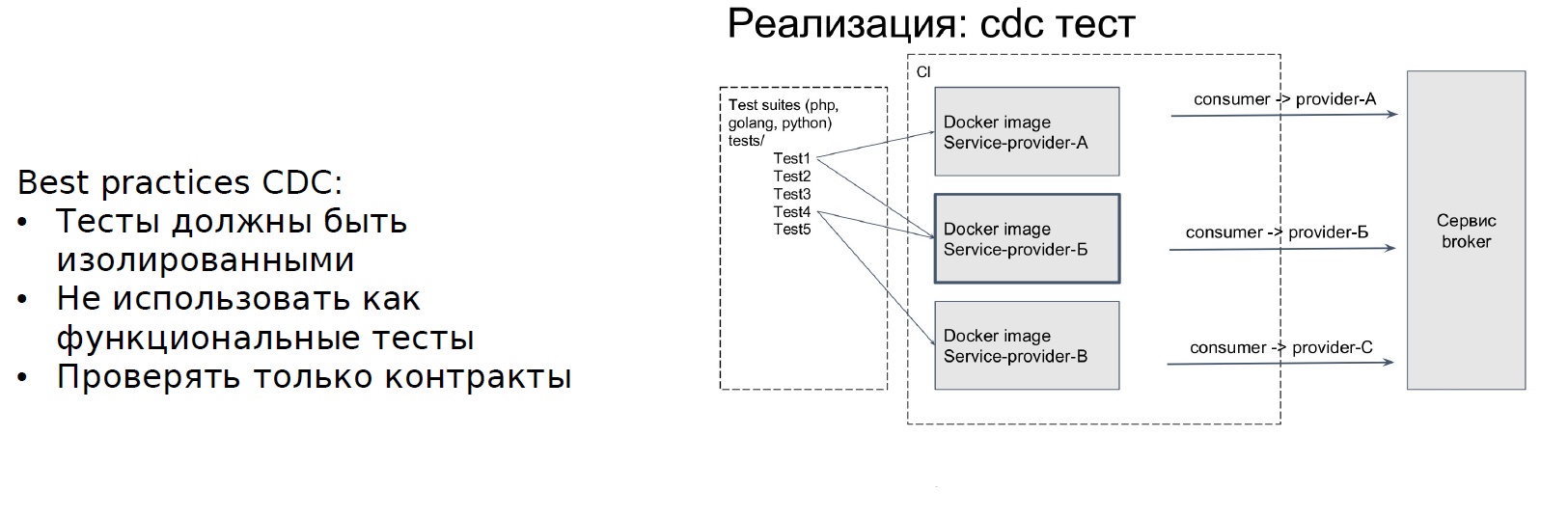
Frol Kryuchkov told RIT ++ about how the Avito implemented the CDC approach for testing microservices. Abstracts can be found on the website Backend.conf - I recommend to read.
Types of sagas
In order of function call
a) unordered - the functions of the saga are called in any order and do not wait for each other to complete;
b) ordered - the functions of the saga are called in the specified order, one after another, the next is not called until the previous one is completed;
c) mixed - for a part of the functions, an order is set, but for a part it is not, but it is set before or after what stages they are to be performed.
Consider a specific scenario. In the same scenario of buying a premium subscription, the first step is to reserve money. Now we can make changes to the user and creating bonus packages in parallel, and we will send notifications to the user only when these two steps end.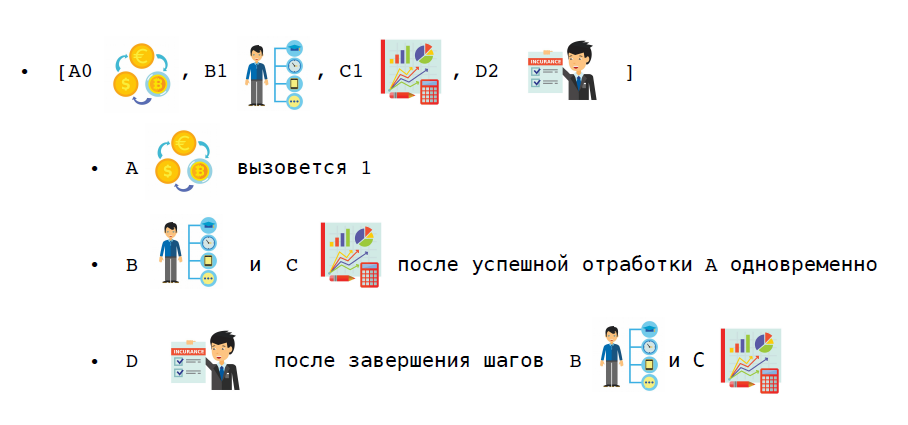
Upon receipt of the result of a function call
a) synchronous - the result of the function is known immediately;
b) asynchronous - the function returns immediately “OK”, and the result is returned later, via the callback API of the sagas service from the client service.
I want to warn you against an error: it is better not to take the synchronous steps of the sagas, especially when implementing an orchestrated saga. If you take simultaneous steps of the sagas, the saga service will wait until this step is completed. This is an extra burden, unnecessary problems in the service of the sagas, since it is one, and there are many participants in the sagas.
Scaling sagas
Scaling depends on the size of the system you are planning. Consider a single instance of the repository:
- one handler of steps saga, we process steps with batches;
- n handlers, we implement the "comb" - we take the steps of the remainder of the division: when each executor gets its steps.
- n handlers and skip locked - will be even more efficient and more flexible.
And only then, if you know in advance that you will run into the performance of a single server in a DBMS, you need to do a sharding - n instances of databases that will work with your data set. Sharding can be hidden behind the API service sagas.
More flexibility
In addition, in this pattern, at least in theory, the client service (performing the saga step) can access and fit into the saga service, and participation in the saga can also be optional. There may be another scenario: if you have already sent an email, it is impossible to compensate for the action - you cannot return the letter back. But you can send a new letter, that the previous one was wrong, and it looks like so-so. It is better to use the scenario when the saga will be played only forward, without any compensation. If it does not play forward, then it is necessary to inform the service owner of the saga about the problem.
When need lok
A small digression about the saga in general: if you can do your logic without a saga, then do it. Sagas are hard. With a lock, about the same thing: it is better to always avoid blocking.
When I came to the billing team to talk about the saga, they said that they needed a lock. I managed to explain to them why it is better to do without him and how to do it. But if you still need a lock, then it should be foreseen in advance. Before the saga service, we already implemented locks in the framework of a single DBMS. An example with defproc and asynchronous ad blocking script and synchronous account blocking, when we first do part of the operation synchronously and set the lock, and then finish the remaining work asynchronously in the background with batch files.
How to do it? Within one DBMS, you can make a certain table in which you will save records about the lock, and then in the trigger, when performing operations on the object of this lock, look at this table, and if someone tries to change it during the lock, generate exceptions . Approximately the same can be done in the service sagas. The main thing is to keep order. I propose the following approach: first we make a lock in the service of the sagas, if we want to implement the saga with the lock, and then we lower it to the client service using the above approach.
It is possible and in another way, but it is important that there is a correct order. And you need to understand that if you have a lock, then there will be deadlock. If deadlocks appear, then you need to do a deadlock detector. And locks can be exclusive and shared. But I do not advise planning a multi-level blocking - this is a rather complicated story, and the service should be simple, because it is the only point of failure of all your transactions.
ACID - without isolation
We have atomicity, since all steps are either completed or compensated. There is consistency due to the service of sagas and local storages in the service of sagas. And sustainability - thanks to local repositories and their durability mechanisms. We have no insulation. In the absence of isolation, we will have various anomalies. They will arise when we can lose updates. You will read some data, then someone else will write something, and your original transaction will take and rewrite these changes.

Dirty readings can happen - when you are in the process of doing some kind of saga, you have done one thing, you have written it down, someone has already read these changes, and your saga is not finished yet. You write again, change something, and someone reads the wrong state.

Non- recurring readings happen - when you get different states of your object during the same saga.

How to avoid it:
- Work with the object version, hold a certain version, for example, the user, and increment it with each change.
- Check that you are still working with her. Or look at the state you want to change, for example, the status, and make sure that you apply it to the same status that you previously wanted to change.
- You can line up locks and serialize all changes around the main object of the saga.
- Only transmit events to the payload saga and do not work with the state. This story is about eventual consistency - if you pass the ad state to the user service, it may have already changed by the time the event reaches the addressee. It is necessary to transfer information about what happened, for example, the registration of users or we have applied a premium service to the user.
Monitoring
It is necessary to monitor the implementation of the sagas with a breakdown by all steps and by all statuses. We collect all telemetry, including how long each step of the saga and the sagas themselves are executed. All the same we have to look for offsetting transactions. Also do not forget about checker. And it would be good to impose a metrics service on each step. Here are examples of graphs that we collect.
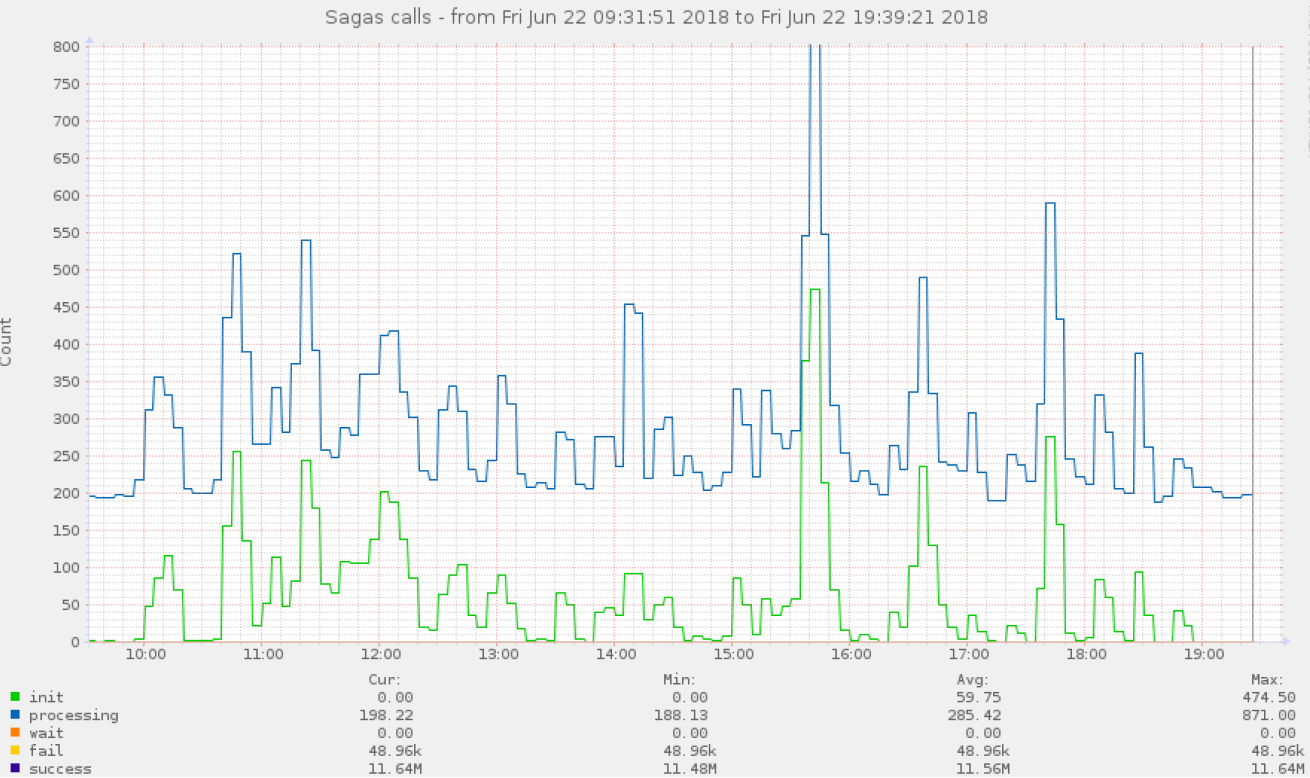
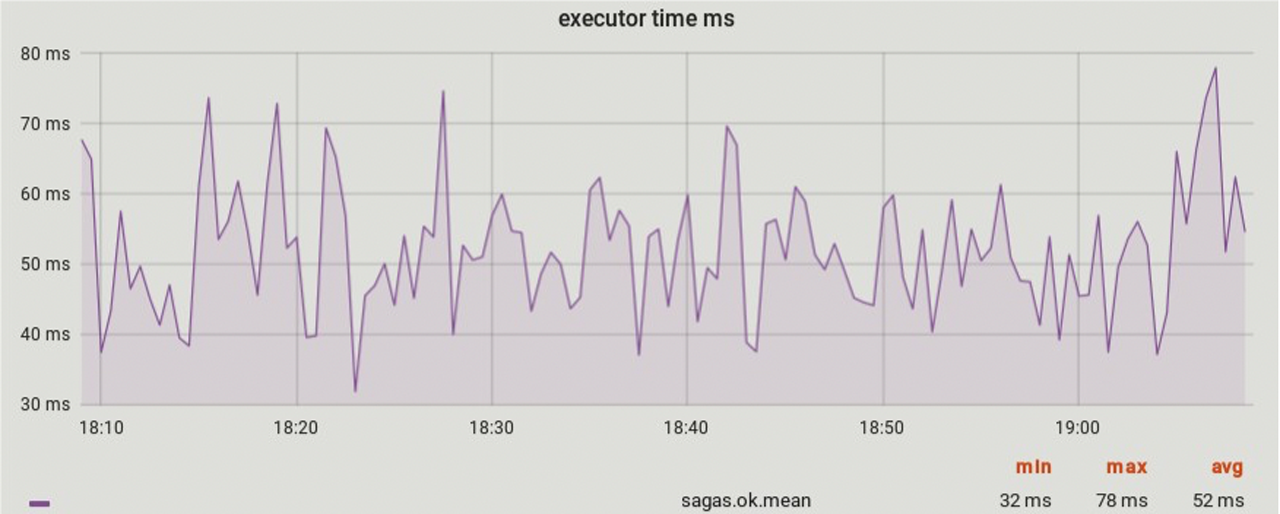
First of all, we look at percentiles (50%, 75%, 95%, 99%), because you will know them first if something went wrong.
How to determine the location of the breakdown, if the saga is broken - as I said, we collect metrics broken down by steps and further. On all these steps sagas we can hang alerts. If certain steps of the saga are piling up, then something has gone wrong. But it is possible that the saga has not broken at all yet - there simply was a surge in the load in one of the services of the performers of the saga steps.
Another situation. How to determine that some step of the saga (the service has failed) does not work at all. In this case, healthchecker checks all endpoint info (keep-alive) client services.
Well, the third example. There may be an accident from the business scenario. The responsibility of the business scenario that your business transaction is being carried out correctly is already entirely on the team of the owner of the saga and the teams of the owners of the services executing the steps of the saga. In this situation, the owner of a single saga, when he designs it, must cover it with tests, including the end-to-end. Next, you need monitoring for various business metrics of the saga. The team that generated this saga should keep track of metrics in its own hands - this is its area of responsibility.
The saga service itself is also closely monitored. It would also be good to implement auto-file for local storage of the sagas service.
What you should pay attention to:
Avoid parasitic loads
Above, I have already said that you need to build a healthchecker, and if a certain node has failed, you should stop performing these sagas. Because the saga service is one, and there are many customers. You just unnecessarily overload your service sagas.
Avoid complex logic of redundant functionality in the saga service.
Once you get involved in this story, the saga service becomes the most critical point of your infrastructure. If he refuses, the consequences can be exactly the kind of functionality you wrap on him. And we want to tie the most critical functionality on it. Therefore, the choreography of the sag pattern looks more profitable - there the sag service is involved only when something went wrong. In general, even if your sag service in the choreography pattern fails, everything will continue to work for you. The saga service in choreography is critical, for example, when performing rollback. If we make an orchestrated saga, then with the failure of the saga service, everything will fail. Accordingly, the less logic you put in there, the easier and faster it will work, and the more reliable the whole system will be.
Integrate with customers
Teach all your teams to work with the saga service. This layer of the theory must be read, since it may not be obvious to all how to work correctly with persistent systems in the context of sagas. Think about how to make convenient work with local storage + work with different languages in the context of the sagas and how to hide it all in client libraries.
Versioning API
In our implementation, when we want to change something in the service provider of the client's step (new version of the service API), we create a new saga in which we use the new version of the API. After that, we transfer everyone to the new saga and the old saga can be deleted and then the old API method can also be deleted. Here you need to be careful - changes, among other things, may implicitly affect the logic of compensation. Including before removing the old classes of sagas and the API methods of the steps of the sagas, you need to wait for the time interval when 100% of the old methods cannot be compensated.
And of course, if you have to change the service of the sagas, and the changes will be backward incompatible, you will need to fix all the services that interact with the service of the sagas. There is no silver bullet - it all depends on how big the nature of the changes you are going to make. But we have not had such cases so far.
Accident compensation
When designing compensation transactions, in the event of various accidents, when it is impossible to perform a saga, carefully study the likely scenarios with the product representative and describe them. It is important to seek a compromise between automating the solution of incidents (the preferred option) and passing them on to analysis and decision making by humans.
Lack of insulation
It is better to study different scenarios in advance, who works with one or another object of your saga or part of the saga, of a specific step, and what can go wrong if he reads the data in the process of the saga.
Locks
Better to avoid them. Most likely, if you can't do it, you need another tool.
Saga call id tracing
We have all the states stored in the storage service of the sagas. There is an API in the saga service that, by identifier of a particular instance of the saga, returns the current state of the saga.
Outcome - what to choose
We use the Saga orchestrator to refactor legacy code. But if there was a possibility of writing everything from scratch, we would use a choreographic saga (including in the plans the implementation of the choreographer pattern and transferring some of the functionality to it, but this is another story and there are some nuances). What is the “narrow neck”? If you want to somehow change the saga, you need to go to the team that owns this saga, agree that you are going to change something, because it may have tests, including. But in any case, you, at a minimum, need to agree with them or sign into their service the code that will now generate the saga with your additional step. And so it turns out that this is a “narrow neck”, because it scales very poorly, if you have a lot of teams and different business logic. This is a minus. Plus is the convenience of migrating current functionality. All because we can test in advance harder and guarantee the order of execution.
I am for a pragmatic approach to development, therefore, in order to write a saga service, an investment in writing such a service should be justified. Moreover, most likely, many need only a part of what I have described, and this part will solve current needs. The main thing is to understand in advance what exactly this is needed from. And how many resources you have.
If you have questions or are interested in learning more about the saga, write in the comments. I am happy to answer.