Collection overhead
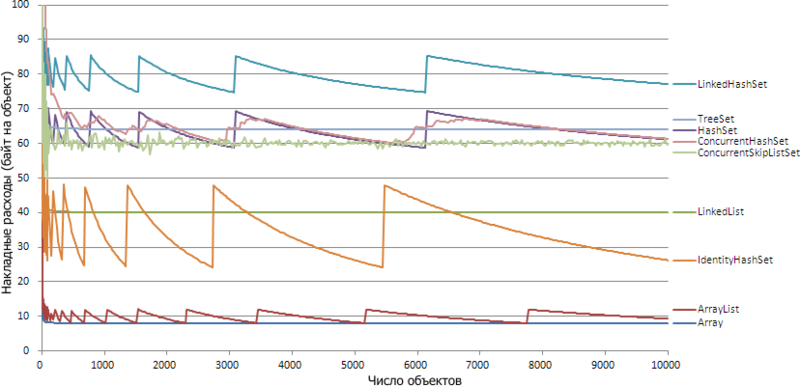
I was wondering how many collections eat up extra memory when storing objects. I carried out overhead measurements for popular collections involving the storage of the same type of elements (that is, lists and sets) and reduced the results to a common schedule. Here is the picture for the 64-bit Hotspot JVM (Java 1.6):
But for the 32 -bit Hotspot JVM :
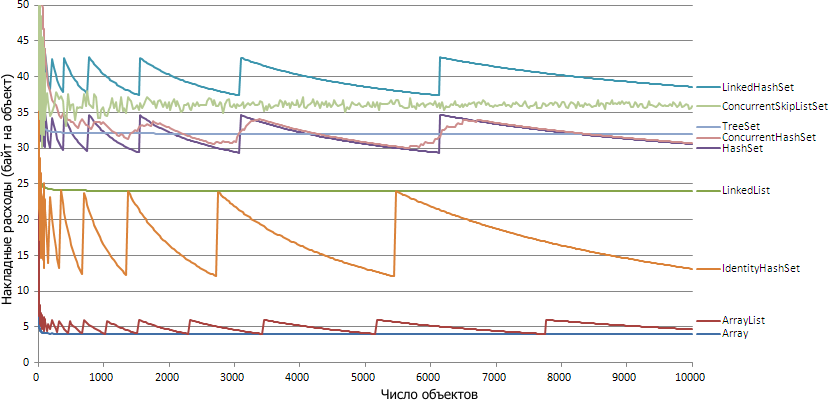
Below I will tell you how the measurements were made, and then try to figure out why the pictures look like this.
Measurements were taken for standard Java collections from java.util and java.util.concurrent, as well as for a regular Java array. The IdentityHashSet and ConcurrentHashSet collections are created from the corresponding Map using the Collections.newSetFromMap () method. All collections were initialized by default without first specifying the number of elements (well, except for the array, for which it is necessary), and then they were filled with test objects using the add method (and assignment was just performed for the array). About 500 collections of each type were created with a different number of elements from 1 to 10,000. As an element, 10,000 different strings of random length consisting of random letters were used. In principle, the elements themselves affect only the ConcurrentHashSet, and even then slightly, so the graphs will look similar for any data.
After filling in the arrays, a memory dump was taken from the process and analyzed using the Eclipse Memory Analyzer, which very correctly calculated the Retained set of each of the collections, not including the objects themselves, but including only the overhead. It looks, for example, like this:
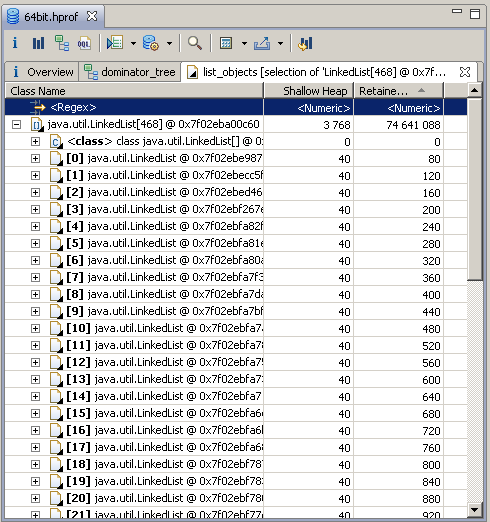
Well, then copying into Excel, simple mathematical operations and plotting with a little extra drawing in a graphical editor.
It can be seen that each collection has a lower border for overhead costs and the more elements, the more often it is close to it. However, for some collections it cannot be said that the overhead function converges to this boundary in the mathematical sense. For example, ArrayList, although it increasingly turns out to be at 8 bytes (for 64bit), but it continues to jump to 12 bytes with each new memory allocation.
Interestingly, the graphs for 32bit and 64bit are very similar: for most collections, the graphs differ by half except for two exceptions: ConcurrentSkipListSet and LinkedList. Consider each collection individually and see why the schedule for it is just that.
The simplest option is an array for which the number of elements is known in advance. In it, a reference is stored for each object: 4 (8) bytes (in brackets the value is for a 64-bit JVM), in addition, the length of the array is int, 4 bytes, and the object descriptor is 8 (16) bytes. In addition, each object is aligned by 8 bytes due to which arrays with an even number of elements per 32bit lose 4 bytes. Result: 4 (8) bytes per object plus a constant from 12 to 24 bytes.
An empty array occupies 16 (24) bytes.
Here it is almost the same with a slight difference: since the number of elements in the array is not known in advance, the array is allocated with a margin (by default 10 elements) and, if necessary, expands slightly more than one and a half times:
Therefore, the graph jumps to 6 (12) bytes. The constant is also slightly larger: 40 (64) bytes, since in addition to the array there is also an ArrayList object, which stores a reference to the array, the actual size of the list and the number of modifications (to throw a ConcurrentModificationException). Nevertheless, this is the most economical way to store the same type of data, if you do not know in advance how much there will be.
A default constructed ArrayList with no elements takes 80 (144) bytes.
For a linked list, a picture is like an array: tends to an asymptote for a hyperbole. One service object of the java.util.LinkedList.Entry type is created for each list item. Each of these objects contains three links (to the list item itself, to the previous and subsequent Entry), and due to alignment in 32bit, 4 bytes are lost, so in the end 24 (40) bytes are required for each Entry. The constant includes the handle of the LinkedList object, the head Entry and a link to it, the size of the list and the number of modifications is 48 (80) bytes. The empty list occupies the same amount, since of course no memory is allocated here.
In general, all used sets are based on Map. A separate implementation in some cases could be somewhat more compact, but the general code, of course, is more important.
The graph also looks like a LinkedList and an array. A java.util.TreeMap.Entry tree branch is created for each element, which contains five links: key, value, parent, left and right child. In addition to them, a Boolean variable is stored that indicates the color of the branch, red or black (see red-black tree ). A single Boolean variable takes 4 bytes, so the whole record takes 32 (64) bytes.
Permanent data in TreeMap is: a reference to the comparator, a reference to the root of the tree (unlike the celestial Entry in LinkedList, the root is used for its intended purpose - refers to the real element of the set), links to entrySet, navigableKeySet, descendingMap (these objects are created on demand), size and number of modifications. With the handle of the TreeMap object, 48 (80) bytes are obtained. TreeSet itself adds only its descriptor and a link to the TreeMap. In total, 64 (104) bytes are output. An empty set weighs the same. By the way, the memory consumption does not depend on the degree of balance of the tree.
HashSet is based on HashMap, which is a little trickier than TreeMap. For each element, a java.util.HashMap.Entry entry is made, containing links to the key, the value that follows Entry (if several entries fall into one cell of the hash table), as well as the hash value itself. Altogether, Entry weighs 24 (48) bytes.
In addition to Entry, there is also a hash table with links to Entry, which contains 16 elements initially and doubles when the number of elements exceeds 75% of its size (75% is the default loadFactor value, it can be specified in the constructor). That is, when constructing by default, the table grows when the number of elements exceeds 12, 24, 48, 96, etc. (2 n* 3, the last surge on the chart is 6144 elements). Immediately after the increase, the table is 2 / 0.75 = 2.67 times the number of elements, that is, the total consumption is about 34.67 (69.33) bytes per element (not counting the constant). Just before the increase, the table is only 1 / 0.75 = 1.33 times the number of elements, and the total consumption is 29.33 (58.67) bytes per element. Note that memory usage is completely independent of how often hash collisions occur.
Those who wish can calculate the constant component themselves, I’ll just say that the default initialized empty HashSet weighs 136 (240) bytes.
Almost the same as in HashSet. It uses java.util.LinkedHashMap.Entry, which inherits java.util.HashMap.Entry, adding two links to the previous and next elements, so the graph is 8 (16) bytes higher than for HashSet, reaching before table extension 37.33 (74.67) and after - a record 42.67 (85.33). The constant has also increased, since like LinkedList, the head Entry is stored, which does not refer to an element of the set. A freshly created LinkedHashSet weighs 176 (320) bytes.
IdentityHashMap is a very interesting thing. It violates the standard Map contract by comparing keys with == rather than equals and using System.identityHashCode. It is also interesting because it does not create objects like Entry, but simply stores all the keys and values in one array (keys in even elements, values in odd ones). In the event of a collision, it does not create a list, but writes the object to the first free cell along the array. Thanks to this, record low overhead costs are achieved among all the sets.
IdentityHashMap doubles the size of the array each time it is more than 2/3 full (unlike HashMap, this coefficient is not configurable). By default, an array is created with 32 elements (that is, the size of the array is 64). Accordingly, expansion occurs when exceeding 21, 42, 85, 170, etc. ([2 n/ 3], the last surge on the chart - 5461). Before expansion, the array contains 3 times more elements than keys in IdentityHashMap, and after expansion - 6 times. Thus, the overhead is from 12 (24) to 24 (48) bytes per element. An empty set by default takes quite a lot - 344 (656) bytes, but already with nine elements it becomes more economical than all other sets.
ConcurrentHashMap is the first collection in which the chart depends on the elements themselves (or rather, on their hash functions). Roughly speaking, this is a set of a fixed number of segments (16 by default), each of which is a synchronous analogue of HashMap. Part of the bits from the modified hash code is used to select a segment, access to different segments can occur in parallel. In the limit, the overhead is the same as the overhead of the HashMap itself, because java.util.concurrent.ConcurrentHashMap.HashEntry is pretty much the same as java.util.HashMap.Entry. The increase in the size of segments occurs independently, because the graph does not rise simultaneously: first, the segments in which there are more elements increase.
This collection came out on top in terms of initial size - 1304 (2328) bytes, because 16 segments were immediately started, each of which has a table with 16 records and several auxiliary fields. However, for 10,000 elements, the ConcurrentHashSet is only 0.3% larger than the HashSet.
Implemented through ConcurrentSkipListMap and, in my opinion, the most complex of the described collections. The idea of the algorithm was described on Habr, so here I will not go into details. I only note that the resulting memory size here is independent of the data, but non-deterministic, since the collection is initiated by the pseudo-random number generator. Based on the next pseudo-random number, a decision is made whether to add an index record and how many levels. One java.util.concurrent.ConcurrentSkipListMap.Node object is necessarily created for each element, which contains references to the key, value and the next Node, forming a simply connected list. This gives 24 (40) bytes per element. In addition, approximately one index entry (java.util.concurrent.ConcurrentSkipListMap.Index) is created for every two elements (on the first level there is an index for every fourth record, on the second for every eighth, etc.). Each index entry weighs the same how many are Node (there are also three links there), so in total each element requires about 36 (60) bytes. There are head records for each level (HeadIndex), but there are few of them (approximately the logarithm of the number of elements), so they can be neglected.
In an empty ConcurrentSkipListSet, one HeadIndex and one empty Node are created; after construction by default, the collection takes 112 (200) bytes.
The results were largely unexpected and contradicted my intuitive ideas. So I thought that competitive collections should occupy much more than regular collections, and LinkedHashSet should be located somewhere between TreeSet and HashSet. It was also surprising that practically nowhere the memory consumption does not depend on the objects themselves: the degree of balance of the tree or the number of collisions in the hash tables do not affect anything and for non-competitive collections you can pre-determine the size of the overhead with an accuracy of up to a byte. It was interesting to delve into the internal structure of different collections. Is there any concrete practical benefit in this study? I don’t know, let everyone decide for himself.
But for the 32 -bit Hotspot JVM :
Below I will tell you how the measurements were made, and then try to figure out why the pictures look like this.
Materials and methods
Measurements were taken for standard Java collections from java.util and java.util.concurrent, as well as for a regular Java array. The IdentityHashSet and ConcurrentHashSet collections are created from the corresponding Map using the Collections.newSetFromMap () method. All collections were initialized by default without first specifying the number of elements (well, except for the array, for which it is necessary), and then they were filled with test objects using the add method (and assignment was just performed for the array). About 500 collections of each type were created with a different number of elements from 1 to 10,000. As an element, 10,000 different strings of random length consisting of random letters were used. In principle, the elements themselves affect only the ConcurrentHashSet, and even then slightly, so the graphs will look similar for any data.
After filling in the arrays, a memory dump was taken from the process and analyzed using the Eclipse Memory Analyzer, which very correctly calculated the Retained set of each of the collections, not including the objects themselves, but including only the overhead. It looks, for example, like this:
Well, then copying into Excel, simple mathematical operations and plotting with a little extra drawing in a graphical editor.
The discussion of the results
It can be seen that each collection has a lower border for overhead costs and the more elements, the more often it is close to it. However, for some collections it cannot be said that the overhead function converges to this boundary in the mathematical sense. For example, ArrayList, although it increasingly turns out to be at 8 bytes (for 64bit), but it continues to jump to 12 bytes with each new memory allocation.
Interestingly, the graphs for 32bit and 64bit are very similar: for most collections, the graphs differ by half except for two exceptions: ConcurrentSkipListSet and LinkedList. Consider each collection individually and see why the schedule for it is just that.
Array
The simplest option is an array for which the number of elements is known in advance. In it, a reference is stored for each object: 4 (8) bytes (in brackets the value is for a 64-bit JVM), in addition, the length of the array is int, 4 bytes, and the object descriptor is 8 (16) bytes. In addition, each object is aligned by 8 bytes due to which arrays with an even number of elements per 32bit lose 4 bytes. Result: 4 (8) bytes per object plus a constant from 12 to 24 bytes.
An empty array occupies 16 (24) bytes.
Arraylist
Here it is almost the same with a slight difference: since the number of elements in the array is not known in advance, the array is allocated with a margin (by default 10 elements) and, if necessary, expands slightly more than one and a half times:
int newCapacity = (oldCapacity * 3)/2 + 1;
Therefore, the graph jumps to 6 (12) bytes. The constant is also slightly larger: 40 (64) bytes, since in addition to the array there is also an ArrayList object, which stores a reference to the array, the actual size of the list and the number of modifications (to throw a ConcurrentModificationException). Nevertheless, this is the most economical way to store the same type of data, if you do not know in advance how much there will be.
A default constructed ArrayList with no elements takes 80 (144) bytes.
LinkedList
For a linked list, a picture is like an array: tends to an asymptote for a hyperbole. One service object of the java.util.LinkedList.Entry type is created for each list item. Each of these objects contains three links (to the list item itself, to the previous and subsequent Entry), and due to alignment in 32bit, 4 bytes are lost, so in the end 24 (40) bytes are required for each Entry. The constant includes the handle of the LinkedList object, the head Entry and a link to it, the size of the list and the number of modifications is 48 (80) bytes. The empty list occupies the same amount, since of course no memory is allocated here.
Treeset
In general, all used sets are based on Map. A separate implementation in some cases could be somewhat more compact, but the general code, of course, is more important.
The graph also looks like a LinkedList and an array. A java.util.TreeMap.Entry tree branch is created for each element, which contains five links: key, value, parent, left and right child. In addition to them, a Boolean variable is stored that indicates the color of the branch, red or black (see red-black tree ). A single Boolean variable takes 4 bytes, so the whole record takes 32 (64) bytes.
Permanent data in TreeMap is: a reference to the comparator, a reference to the root of the tree (unlike the celestial Entry in LinkedList, the root is used for its intended purpose - refers to the real element of the set), links to entrySet, navigableKeySet, descendingMap (these objects are created on demand), size and number of modifications. With the handle of the TreeMap object, 48 (80) bytes are obtained. TreeSet itself adds only its descriptor and a link to the TreeMap. In total, 64 (104) bytes are output. An empty set weighs the same. By the way, the memory consumption does not depend on the degree of balance of the tree.
Hashset
HashSet is based on HashMap, which is a little trickier than TreeMap. For each element, a java.util.HashMap.Entry entry is made, containing links to the key, the value that follows Entry (if several entries fall into one cell of the hash table), as well as the hash value itself. Altogether, Entry weighs 24 (48) bytes.
In addition to Entry, there is also a hash table with links to Entry, which contains 16 elements initially and doubles when the number of elements exceeds 75% of its size (75% is the default loadFactor value, it can be specified in the constructor). That is, when constructing by default, the table grows when the number of elements exceeds 12, 24, 48, 96, etc. (2 n* 3, the last surge on the chart is 6144 elements). Immediately after the increase, the table is 2 / 0.75 = 2.67 times the number of elements, that is, the total consumption is about 34.67 (69.33) bytes per element (not counting the constant). Just before the increase, the table is only 1 / 0.75 = 1.33 times the number of elements, and the total consumption is 29.33 (58.67) bytes per element. Note that memory usage is completely independent of how often hash collisions occur.
Those who wish can calculate the constant component themselves, I’ll just say that the default initialized empty HashSet weighs 136 (240) bytes.
LinkedHashSet
Almost the same as in HashSet. It uses java.util.LinkedHashMap.Entry, which inherits java.util.HashMap.Entry, adding two links to the previous and next elements, so the graph is 8 (16) bytes higher than for HashSet, reaching before table extension 37.33 (74.67) and after - a record 42.67 (85.33). The constant has also increased, since like LinkedList, the head Entry is stored, which does not refer to an element of the set. A freshly created LinkedHashSet weighs 176 (320) bytes.
IdentityHashSet (via newSetFromMap)
IdentityHashMap is a very interesting thing. It violates the standard Map contract by comparing keys with == rather than equals and using System.identityHashCode. It is also interesting because it does not create objects like Entry, but simply stores all the keys and values in one array (keys in even elements, values in odd ones). In the event of a collision, it does not create a list, but writes the object to the first free cell along the array. Thanks to this, record low overhead costs are achieved among all the sets.
IdentityHashMap doubles the size of the array each time it is more than 2/3 full (unlike HashMap, this coefficient is not configurable). By default, an array is created with 32 elements (that is, the size of the array is 64). Accordingly, expansion occurs when exceeding 21, 42, 85, 170, etc. ([2 n/ 3], the last surge on the chart - 5461). Before expansion, the array contains 3 times more elements than keys in IdentityHashMap, and after expansion - 6 times. Thus, the overhead is from 12 (24) to 24 (48) bytes per element. An empty set by default takes quite a lot - 344 (656) bytes, but already with nine elements it becomes more economical than all other sets.
ConcurrentHashSet (via newSetFromMap)
ConcurrentHashMap is the first collection in which the chart depends on the elements themselves (or rather, on their hash functions). Roughly speaking, this is a set of a fixed number of segments (16 by default), each of which is a synchronous analogue of HashMap. Part of the bits from the modified hash code is used to select a segment, access to different segments can occur in parallel. In the limit, the overhead is the same as the overhead of the HashMap itself, because java.util.concurrent.ConcurrentHashMap.HashEntry is pretty much the same as java.util.HashMap.Entry. The increase in the size of segments occurs independently, because the graph does not rise simultaneously: first, the segments in which there are more elements increase.
This collection came out on top in terms of initial size - 1304 (2328) bytes, because 16 segments were immediately started, each of which has a table with 16 records and several auxiliary fields. However, for 10,000 elements, the ConcurrentHashSet is only 0.3% larger than the HashSet.
ConcurrentSkipListSet
Implemented through ConcurrentSkipListMap and, in my opinion, the most complex of the described collections. The idea of the algorithm was described on Habr, so here I will not go into details. I only note that the resulting memory size here is independent of the data, but non-deterministic, since the collection is initiated by the pseudo-random number generator. Based on the next pseudo-random number, a decision is made whether to add an index record and how many levels. One java.util.concurrent.ConcurrentSkipListMap.Node object is necessarily created for each element, which contains references to the key, value and the next Node, forming a simply connected list. This gives 24 (40) bytes per element. In addition, approximately one index entry (java.util.concurrent.ConcurrentSkipListMap.Index) is created for every two elements (on the first level there is an index for every fourth record, on the second for every eighth, etc.). Each index entry weighs the same how many are Node (there are also three links there), so in total each element requires about 36 (60) bytes. There are head records for each level (HeadIndex), but there are few of them (approximately the logarithm of the number of elements), so they can be neglected.
In an empty ConcurrentSkipListSet, one HeadIndex and one empty Node are created; after construction by default, the collection takes 112 (200) bytes.
Why all this?
The results were largely unexpected and contradicted my intuitive ideas. So I thought that competitive collections should occupy much more than regular collections, and LinkedHashSet should be located somewhere between TreeSet and HashSet. It was also surprising that practically nowhere the memory consumption does not depend on the objects themselves: the degree of balance of the tree or the number of collisions in the hash tables do not affect anything and for non-competitive collections you can pre-determine the size of the overhead with an accuracy of up to a byte. It was interesting to delve into the internal structure of different collections. Is there any concrete practical benefit in this study? I don’t know, let everyone decide for himself.