AI, practical course. Modern deep neural network architectures for image classification
- Transfer
In the previous article, Overview of Neural Networks for image classification , we familiarized ourselves with the basic basic concepts of convolutional neural networks, as well as the underlying ideas. In this article, we will look at several architectures of deep neural networks with large computing power — such as AlexNet, ZFNet, VGG, GoogLeNet, and ResNet — and summarize the main advantages of each of these architectures. The structure of the article is based on a blog entry. Basic concepts of convolutional neural networks, part 3 .
Currently, the main incentive underlying the development of machine recognition and image classification systems is the ImageNet Challenge campaign . The campaign is a data contest, in which participants are provided with a large data set (over a million images). The task of the competition is to develop an algorithm that allows to classify the required images into objects in 1000 categories - such as dogs, cats, cars and others - with a minimum number of errors.
According to the official rules of the competition, the algorithms must generate a list of no more than five categories of objects in descending order of trust for each category of images. The quality of image marking is evaluated based on the label that best matches the ground truth property of the image. The idea is to allow the algorithm to identify several objects in the image and not charge penalty points if any of the objects found are actually present in the image, but were not included in the ground truth property.
In the first year of the competition, participants were provided with pre-selected signs of images for training the model. This could be, for example, signs of the algorithmSIFT , processed using vector quantization and suitable for use in the "bag of words" method or for representation in the form of a spatial pyramid. However, in 2012 there was a real breakthrough in this area: a group of scientists from the University of Toronto demonstrated that a deep neural network can achieve significantly better results compared to traditional models of machine learning, built on the basis of vectors from previously selected properties of images. In the following sections, the first innovative architecture proposed in 2012 will be reviewed, as well as the architecture being its followers until 2015.
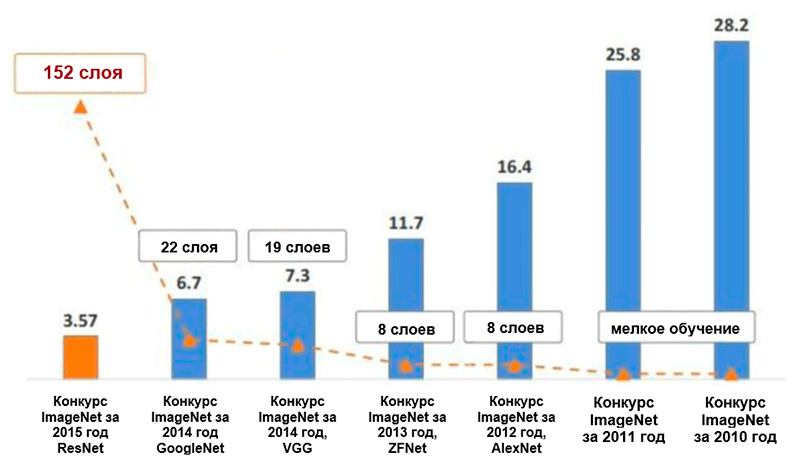
Chart of changing the number of errors (in percent) when classifying ImageNet * images for the five leading categories. Image taken from Kaiming He, Deep residual learning for image recognition.
AlexNet
AlexNet architecture was proposed in 2012 by a group of scientists (A. Krizhevsky, I. Satskever and J. Hinton) from the University of Toronto. It was an innovative work in which the authors first used (at that time) deep convolutional neural networks with a total depth of eight layers (five convolutional and three fully connected layers).
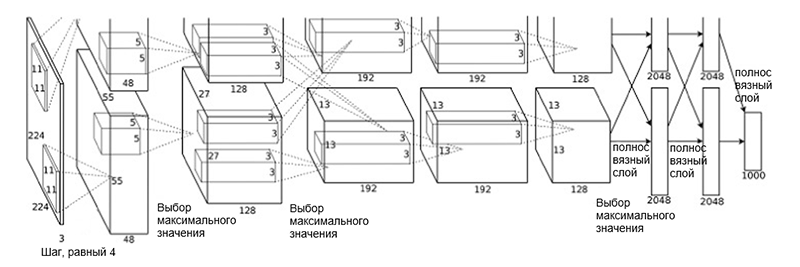
AlexNet
architecture The network architecture consists of the following layers:
- [Convolutional layer + selection of maximum value + normalization] x 2
- [Convolution layer] x 3
- [Select the maximum value]
- [Full Linked] x 3
Such a scheme may look slightly strange, because the learning process was divided between two graphics processors due to its high computational complexity. This division of work between graphics processors requires manual separation of the model into vertical blocks that interact with each other.
AlexNet architecture has reduced the number of errors for the five leading categories to 16.4 percent - almost doubled compared with previous advanced developments! Also within the framework of this architecture, an activation function such as a linear rectification unit ( ReLU ), which is currently the industry standard, was introduced . The following is a brief summary of the other basic properties of the AlexNet architecture and its learning process:
- Intensive data augmentation
- Exclusion method
- Optimization using SGD torque (see optimization guide “Overview of Gradient Descent Optimization Algorithms”)
- Manual setting of the learning speed (decrease of this coefficient by 10 with stabilization of accuracy)
- The resulting model is a collection of seven convolutional neural networks.
- The training was conducted on two NVIDIA * GeForce GTX * 580 GPUs with a total of 3 GB of video memory on each of them.
ZFNet
The ZFNet network architecture proposed by the researchers M. Zeiler and R. Fergus from New York University is almost identical to the architecture of AlexNet. The only significant differences between them are as follows:
- The filter size and pitch in the first convolutional layer (in AlexNet, the filter size is 11 × 11, and the pitch is 4; in ZFNet, it is 7 × 7 and 2, respectively)
- The number of filters in pure convolutional layers (3, 4, 5).

ZFNet Architecture
Thanks to the ZFNet architecture, the number of errors for the five leading categories dropped to 11.4 percent. Perhaps the main role in this is played by the fine tuning of the hyperparameters (size and number of filters, packet size, learning rate, etc.). However, it is also likely that the ideas of ZFNet architecture have become a very significant contribution to the development of convolutional neural networks. Zieler and Fergus proposed a system of visualization of nuclei, weights, and hidden presentation of images, called DeconvNet. Thanks to it, a better understanding and further development of convolutional neural networks has become possible.
VGG Net
In 2014, K. Simonyan and E. Zisserman (A. Zisserman) from Oxford University proposed an architecture called VGG . The basic and distinctive idea of this structure is to keep the filters as simple as possible . Therefore, all convolution operations are performed using a filter with a size of 3 and a step of 1, and all subsampling operations with a filter of 2 and a step of 2. However, this is not all. At the same time with the simplicity of convolutional modules, the network has grown significantly in depth - now it has 19 layers! The most important idea, first proposed in this paper, is to overlay convolutional layers without sub-sampling layers.. The underlying idea is that such an overlay still provides a fairly large receptive field (for example, three superimposed 3 × 3 convolutional layers with a step of 1 have a receptive field similar to one 7 × 7 convolutional layer) however, the number of parameters is significantly less than in networks with large filters (serves as a regularizer). In addition, it becomes possible to introduce additional nonlinear transformations.
Essentially, the authors have demonstrated that even with very simple standard blocks one can achieve excellent quality results in the ImageNet competition. The number of errors for the top five categories dropped to 7.3 percent.

Архитектура VGG. Обратите внимание, что количество фильтров обратно пропорционально пространственному размеру изображения
GoogLeNet
Previously, the entire development of the architecture was to simplify the filters and increase the depth of the network. In 2014, C. Segedi (C. Szegedy), together with other participants, proposed a completely different approach and created the most complex architecture at that time, called GoogLeNet.
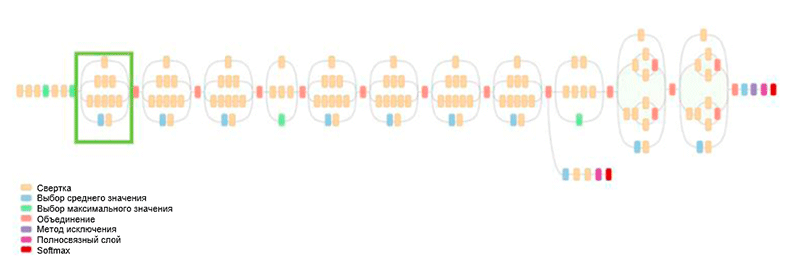
Architecture GoogLeNet. It uses the Inception module, highlighted in green in the figure; the network is built on the basis of these modules.
One of the main achievements of this work is the so-called Inception module, which is shown in the figure below. Networks of other architectures process the input data sequentially, layer by layer, while using the Inception module, the input data is processed in parallel mode. This allows you to speed up the receipt of output, as well as minimize the total number of parameters .
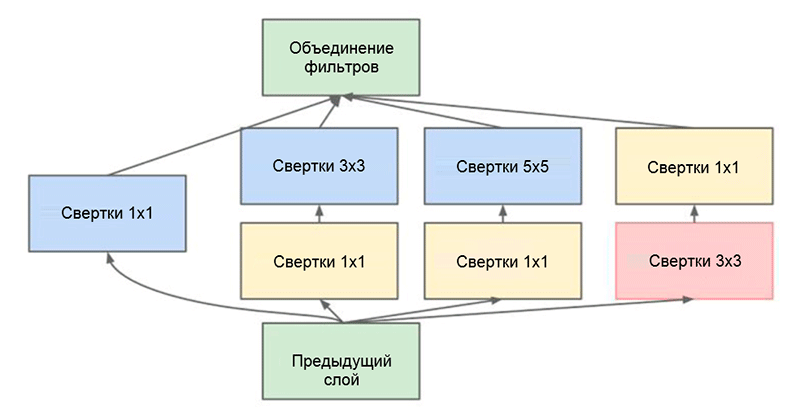
Inception module. Note that the module uses several parallel branches that calculate different properties based on the same input data, and then combine the results.
Another interesting technique used in the Inception module is the use of 1 × 1 convolutional layers. seem meaningless until we remember the fact that the filter covers the entire dimension of depth. Thus, a 1 × 1 convolution is a simple way to reduce the dimension of the property map. This type of convolutional layers was first introduced in the work Network in the networkM. Lin and his co-authors, an exhaustive and understandable explanation can also be found in the blog post Rollover [1 × 1] - usefulness contrary to the intuition for the authorship of A. Prakash.
Ultimately, this architecture reduced the number of errors for the five leading categories by another half a percent - to a value of 6.7 percent.
ResNet
In 2015, a group of researchers (Kaiming Hee and others) from Microsoft Research Asia came up with an idea that is currently considered by the majority of the community to be one of the most important stages in the development of in-depth training.
One of the main problems of deep neural networks is the problem of a vanishing gradient. In a nutshell, this is a technical problem that arises when using the method of back-propagation of error for the gradient calculation algorithm. When working with back propagation of errors, a chain rule is used. Moreover, if the gradient has a small value at the end of the network, then it can take an infinitely small value by the time it reaches the beginning of the network. This can lead to problems of completely different properties, including the impossibility of network training in principle (for more information, see R. Kapur's blog entry (R. Kapur) The problem of a vanishing gradient ).
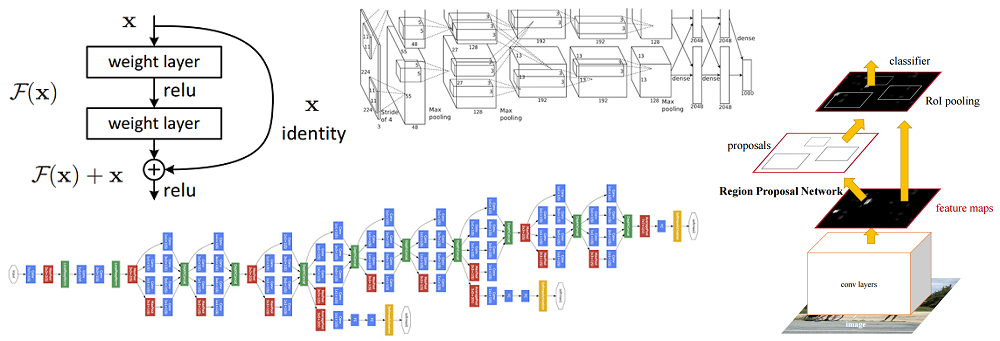
To solve this problem, Kaiming Hee and his group proposed the following idea - to allow the network to study the residual mapping (the element that should be added to the input data) instead of the mapping itself. Technically, this is done using the bypass connection shown in the figure.

The schematic diagram of the residual block: the input data is transmitted via a reduced connection bypassing the conversion layers and added to the result. Please note that the “identical” connection does not add additional parameters to the network, so its structure is not complicated
This idea is extremely simple, but at the same time extremely effective. It solves the problem of a vanishing gradient, allowing it to move without any changes from the upper to the lower layers by means of “identical” connections. Thanks to this idea, it is possible to train very deep, extremely deep networks.
The network that won the ImageNet Challenge competition in 2015 contained 152 layers (the authors were able to train the network that contained 1001 layers, but it produced approximately the same result, so they stopped working with it). In addition, this idea has reduced the number of errors for the five leading categories literally twice - to a value of 3.6 percent. According to the study What I learned by competing with a convolutional neural network in the competition ImageNetconducted by A. Karpati, a person’s productivity for this task is approximately 5 percent. This means that the ResNet architecture is capable of surpassing human results, at least in this task of image classification.