Features PCI-E SSD Intel 910
For a long time, we used intel 320 series for caching random IO. This was moderately fast, in principle, allowed to reduce the number of spindles. At the same time, ensuring high write performance required, to put it mildly, an unreasonable amount of SSDs.
Finally, at the end of summer, Intel 910 came to us. To say that I am deeply impressed is to say nothing. All my previous skepticism about the effectiveness of SSDs on recording is dispelled.
However, first things first.
Intel 910 is a PCI-E format card, which has a pretty solid size (similar to discrete graphics cards). However, I do not like unpack posts, so let's move on to the most important thing - performance.

The numbers are real, yes, it's a hundred thousand IOPS'ov for arbitrary recording. Details under the cut.
But first, we'll play Alchemy Classic, in which if you drag one LSI over 4 Hitachi, you get Intel.
The device is a specially adapted LSI 2008, to each port of which one SSD device with a capacity of 100 GB is “connected”. In fact, all the connections are made on the board itself, so the connection is visible only when analyzing device relationships.
An approximate scheme is this:
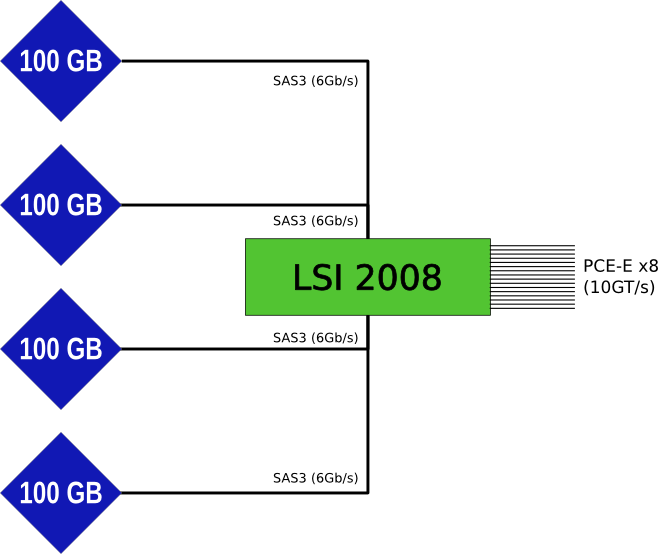
Note, the LSI'y controller is sawed very much - it does not have its own BIOS, it does not know how to be bootable. In lspci, it looks like this:
The structure of the device (4 SSDs of 100 GB each) implies that the user will decide how to use the device - raid0 or raid1 (for thin connoisseurs - raid5, although with high probability this will be the biggest stupidity that can be done with a device of this class) .
It is served by the mpt2sas driver.
It connects 4 scsi devices that declare themselves hitachi:
They do not support any extended sata commands (just like most of the extended SAS service commands) - only the minimum necessary to fully function as a block device. Although, fortunately, it supports sg_format with the resize option, which makes it possible to make full backups for less housekeeping impact when recording is active.
In total, we did 5 different tests to evaluate the characteristics of the device:
In general, these tests are of little interest to anyone; HDDs are much better for providing a “stream”; they have higher capacity, lower price and very decent linear speed. A simple server with 8-10 SAS disks (or even fast SATA) in raid0 is quite capable of clogging a ten-gigabyte channel.
But, nevertheless, here are the indicators:
For maximum performance, we set 2 streams of 256k per device. Final performance: 1680MB / s, without hesitation (the deviation was only 40 μs). At the same time, Lantency was 1.2ms (for a 256k block, this is more than good).
In fact, this means that this read-only device is capable of completely hammering a 10 Gbit / s channel into the ceiling and showing more than impressive results on a 20 Gbit / s channel. At the same time, it will show a constant speed of work, regardless of the load. Note that Intel itself promises up to 2GB / s.
To get the highest recording numbers, we had to lower the queue depth - one stream per recording per device. The remaining parameters were similar (block 256k).
The peak speed (second counts) was 1800MB / s, the minimum was about 600MB / s. The average write speed of 100% was 1228MB / s. A sudden drop in recording speed is a generic trauma to the SSD due to housekeeping. In this case, the drop was up to 600MB / s (about three times), which is better than in older generations of SSD, where degradation could reach up to 10-15 times. Intel promises a speed of about 1.6GB / s for linear recording.
Of course, nobody cares about linear performance. Everyone is interested in performance under heavy load. And what could be the hardest for an SSD? Recording 100% of the volume, in small blocks, in many streams, without interruption for several hours. On the 320th series, this led to a drop in performance from 2000 IOPS to 300.
Test parameters: raid0 from 4 parts of the device, linux-raid (3.2), 64-bit is done. Each task with randread or randwrite mode, for a mixed load, 2 tasks are described.
Note, unlike many utilities that correlate the number of read and write operations in a fixed percentage, we run two independent streams, one of which reads all the time, the other writes all the time (this allows you to load the equipment more fully - if the device has write problems , it can still continue to serve reading). Other parameters: direct = 1, buffered = 0, io mode - libaio, 4k block.
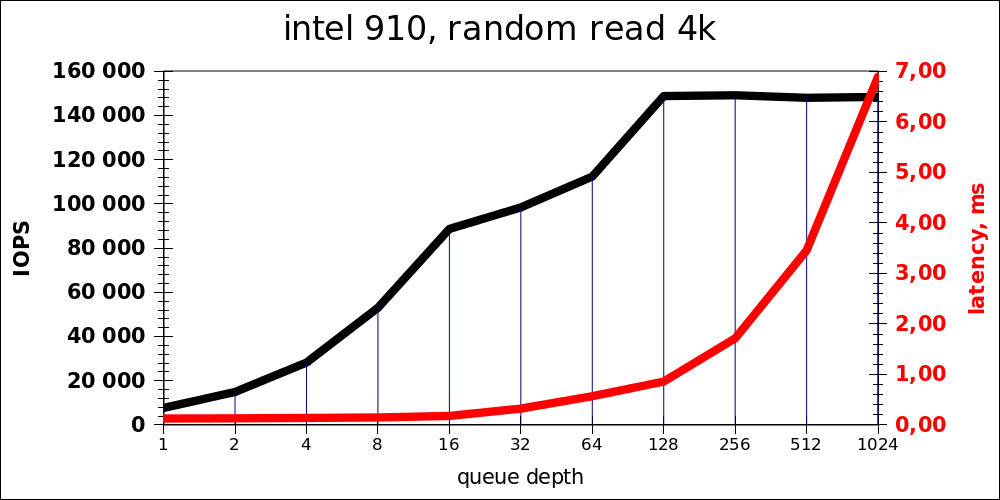
It is noticeable that the optimal load is something of the order of 16-32 operations simultaneously. The long queue of 1024 was added out of sports interest, of course, this is not an adequate indicator for the product (but even in this case the latency is obtained at the level of a rather fast HDD).
You can also notice that the point at which the speed practically ceases to grow is 128. Given that there are 4 pieces inside, this is the usual queue depth of 32 for each controller.
Similarly, the optimum is in the region of 16-32 simultaneous operations, by a very significant (10-fold increase) latency, you can squeeze another 10k IOPS.
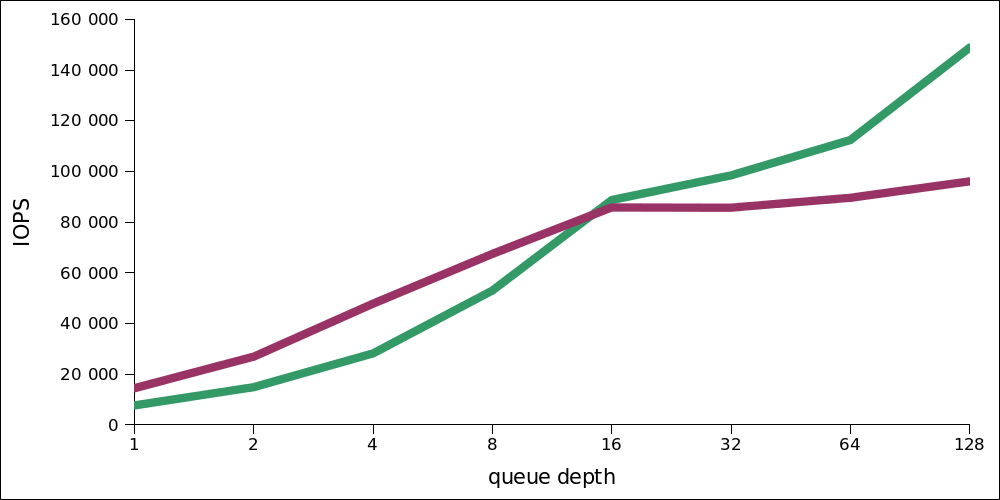
Interestingly, at low load, write performance is higher. Here is a comparison of two graphs - reading and writing on the same scale (reading - in green):
The heaviest type of load, which can be considered obviously exceeding any practical load in the product environment (including OLAP).
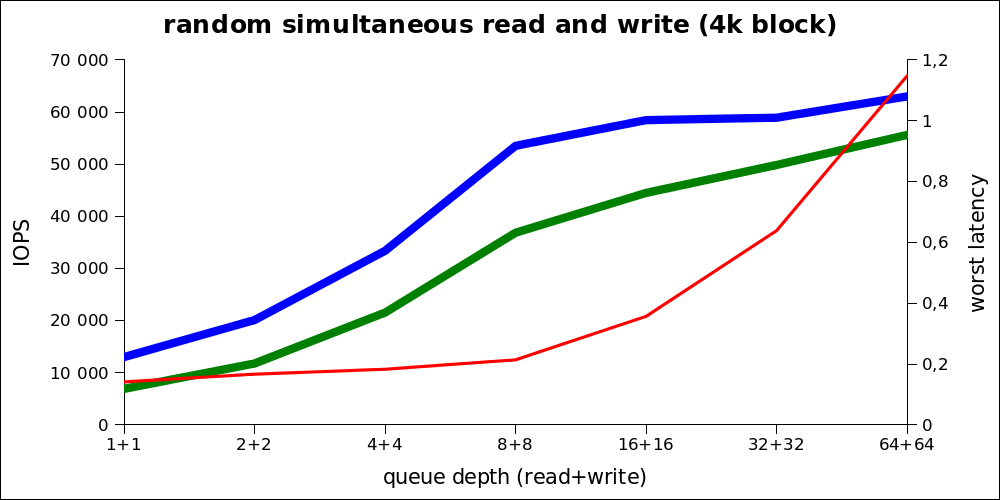
Since the real performance cannot be understood from this graph, here are the same numbers in cumulative form:
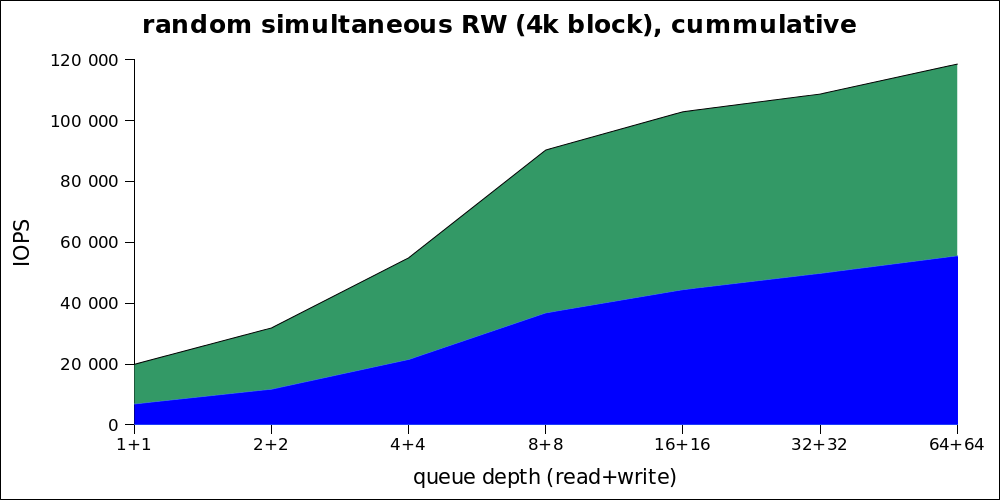
It can be seen that the optimal load is also in the region from 8 + 8 (that is 16) to 32. Thus, despite the very high maximum performance, we need to talk about a maximum of ~ 80k IOPS under normal load.
Note that the resulting numbers are more than Intel promises. On the site, they claim that this model is capable of 35 kIOPS for recording, which roughly corresponds (on the performance graph) to a point with iodepth of about 6. Also, perhaps this figure corresponds to the worst case for housekeeping.
The only drawback of this device is certain problems with hot swapping - PCI-E devices require to disconnect the server before replacing.
Finally, at the end of summer, Intel 910 came to us. To say that I am deeply impressed is to say nothing. All my previous skepticism about the effectiveness of SSDs on recording is dispelled.
However, first things first.
Intel 910 is a PCI-E format card, which has a pretty solid size (similar to discrete graphics cards). However, I do not like unpack posts, so let's move on to the most important thing - performance.
A picture to attract attention
The numbers are real, yes, it's a hundred thousand IOPS'ov for arbitrary recording. Details under the cut.
Device description
But first, we'll play Alchemy Classic, in which if you drag one LSI over 4 Hitachi, you get Intel.
The device is a specially adapted LSI 2008, to each port of which one SSD device with a capacity of 100 GB is “connected”. In fact, all the connections are made on the board itself, so the connection is visible only when analyzing device relationships.
An approximate scheme is this:
Note, the LSI'y controller is sawed very much - it does not have its own BIOS, it does not know how to be bootable. In lspci, it looks like this:
04: 00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03)
Subsystem: Intel Corporation Device 3700
The structure of the device (4 SSDs of 100 GB each) implies that the user will decide how to use the device - raid0 or raid1 (for thin connoisseurs - raid5, although with high probability this will be the biggest stupidity that can be done with a device of this class) .
It is served by the mpt2sas driver.
It connects 4 scsi devices that declare themselves hitachi:
sg_inq / dev / sdo Vendor identification: HITACHI Product identification: HUSSL4010ASS600
They do not support any extended sata commands (just like most of the extended SAS service commands) - only the minimum necessary to fully function as a block device. Although, fortunately, it supports sg_format with the resize option, which makes it possible to make full backups for less housekeeping impact when recording is active.
Testing
In total, we did 5 different tests to evaluate the characteristics of the device:
- random read test
- random write test
- mixed parallel read / write test (note, we don’t have to talk about the “read / write” proportions, because each thread thrashed separately from each other, competing for resources, as is most often the case in real life).
- maximum linear read performance test
- maximum linear write performance test
Linear read and write tests
In general, these tests are of little interest to anyone; HDDs are much better for providing a “stream”; they have higher capacity, lower price and very decent linear speed. A simple server with 8-10 SAS disks (or even fast SATA) in raid0 is quite capable of clogging a ten-gigabyte channel.
But, nevertheless, here are the indicators:
Linear reading
For maximum performance, we set 2 streams of 256k per device. Final performance: 1680MB / s, without hesitation (the deviation was only 40 μs). At the same time, Lantency was 1.2ms (for a 256k block, this is more than good).
In fact, this means that this read-only device is capable of completely hammering a 10 Gbit / s channel into the ceiling and showing more than impressive results on a 20 Gbit / s channel. At the same time, it will show a constant speed of work, regardless of the load. Note that Intel itself promises up to 2GB / s.
Line recording
To get the highest recording numbers, we had to lower the queue depth - one stream per recording per device. The remaining parameters were similar (block 256k).
The peak speed (second counts) was 1800MB / s, the minimum was about 600MB / s. The average write speed of 100% was 1228MB / s. A sudden drop in recording speed is a generic trauma to the SSD due to housekeeping. In this case, the drop was up to 600MB / s (about three times), which is better than in older generations of SSD, where degradation could reach up to 10-15 times. Intel promises a speed of about 1.6GB / s for linear recording.
random IO
Of course, nobody cares about linear performance. Everyone is interested in performance under heavy load. And what could be the hardest for an SSD? Recording 100% of the volume, in small blocks, in many streams, without interruption for several hours. On the 320th series, this led to a drop in performance from 2000 IOPS to 300.
Test parameters: raid0 from 4 parts of the device, linux-raid (3.2), 64-bit is done. Each task with randread or randwrite mode, for a mixed load, 2 tasks are described.
Note, unlike many utilities that correlate the number of read and write operations in a fixed percentage, we run two independent streams, one of which reads all the time, the other writes all the time (this allows you to load the equipment more fully - if the device has write problems , it can still continue to serve reading). Other parameters: direct = 1, buffered = 0, io mode - libaio, 4k block.
Random read
| iodepth | IOPS | avg.latency |
|---|---|---|
| 1 | 7681 | 0.127 |
| 2 | 14893 | 0.131 |
| 4 | 28203 | 0.139 |
| 8 | 53011 | 0.148 |
| 16 | 88700 | 0.178 |
| 32 | 98419 | 0.323 |
| 64 | 112378 | 0.568 |
| 128 | 148845 | 0.858 |
| 256 | 149196 | 1,714 |
| 512 | 148067 | 3,456 |
| 1024 | 148445 | 6,895 |
It is noticeable that the optimal load is something of the order of 16-32 operations simultaneously. The long queue of 1024 was added out of sports interest, of course, this is not an adequate indicator for the product (but even in this case the latency is obtained at the level of a rather fast HDD).
You can also notice that the point at which the speed practically ceases to grow is 128. Given that there are 4 pieces inside, this is the usual queue depth of 32 for each controller.
Random write
| iodepth | IOPS | avg.latency |
|---|---|---|
| 1 | 14480 | 0,066 |
| 2 | 26930 | 0,072 |
| 4 | 47827 | 0,081 |
| 8 | 67451 | 0.116 |
| 16 | 85790 | 0.184 |
| 32 | 85692 | 0.371 |
| 64 | 89589 | 0.763 |
| 128 | 96076 | 1,330 |
| 256 | 102496 | 2,495 |
| 512 | 96658 | 5,294 |
| 1024 | 97243 | 10.52 |
Similarly, the optimum is in the region of 16-32 simultaneous operations, by a very significant (10-fold increase) latency, you can squeeze another 10k IOPS.
Interestingly, at low load, write performance is higher. Here is a comparison of two graphs - reading and writing on the same scale (reading - in green):
Mixed load
The heaviest type of load, which can be considered obviously exceeding any practical load in the product environment (including OLAP).
Since the real performance cannot be understood from this graph, here are the same numbers in cumulative form:
| iodepth | IOPS read | IOPS write | avg.latency |
|---|---|---|---|
| 1 + 1 | 6920 | 13015 | 0.141 |
| 2 + 2 | 11777 | 20110 | 0.166 |
| 4 + 4 | 21541 | 33392 | 0.18 |
| 8 + 8 | 36865 | 53522 | 0.21 |
| 16 + 16 | 44495 | 58457 | 0.35 |
| 32 + 32 | 49852 | 58918 | 0.63 |
| 64 + 64 | 55622 | 63001 | 1.14 |
It can be seen that the optimal load is also in the region from 8 + 8 (that is 16) to 32. Thus, despite the very high maximum performance, we need to talk about a maximum of ~ 80k IOPS under normal load.
Note that the resulting numbers are more than Intel promises. On the site, they claim that this model is capable of 35 kIOPS for recording, which roughly corresponds (on the performance graph) to a point with iodepth of about 6. Also, perhaps this figure corresponds to the worst case for housekeeping.
The only drawback of this device is certain problems with hot swapping - PCI-E devices require to disconnect the server before replacing.