High loads of the World Cup 2018

The past FIFA World Cup 2018 in Russia brought heavy workloads not only to the country's transportation hubs, but also to the IT infrastructure of the largest Russian broadcaster, which made the matches available in the online broadcast format. We took up with interest the new challenge that came to the serviced servers along with the football fever.
Preface: high loads?
Talk about highload often begins with thinking about what loads can be rightly considered “high”: thousands of requests per second for dynamics? Or even a small number of requests in relation to the available resources? Millions of visitors per day? Hundreds of nodes in the cluster loaded with work? ..
To get an idea of the “scale of disaster”, the fact that we are talking about users simultaneously viewing the broadcast, whose number reached 2 million , should be sufficient . What happened, if you look at the broadcast of matches "from the inside", and how did you manage to cope with the unprecedented traffic?
Three whales
1. Site architecture and broadcast system
The general scheme of the end-user interaction with the broadcast system is reduced to the following scheme:
- The user comes to the site where the player is launched to view the video. The player itself is written in JavaScript and loading it leads to a multitude of static requests, as well as various APIs related to broadcasts.
- Among other things, the balancer is asked to play a playlist.
- A playlist is a constantly updated set of short video fragments that are cached on CDN servers.
- While watching a video from the user, various statistics are collected in real time, which, in particular, is taken into account for load distribution across the CDN (along with the actual bandwidth).
The architecture for the direct distribution of the video was designed and implemented by the internal forces of the customer’s engineers even before the start of our cooperation. Later, in addition to the actual service, we were engaged in designing and commissioning the infrastructure for some of its components, as well as the site itself, which plays an important role in the overall scheme.
The site, launched in production a few years ago, is focused on horizontal scalability - including a lot of data centers:

The scheme presented here is simplified and is intended to demonstrate the nature of site scalability, the components of which are distributed across different data centers.
2. CDN
Returning to the actual viewing of the video, it is obvious that the main burden falls on the CDN-servers. In the figures for the last World Cup, we are talking about constant traffic, which is measured by terabits per second . And in many respects, the success of the work of peaks with peak loads is due to caching on CDN everything that can be carried out on them, and minimizing resource (network, CPU, RAM, ...) costs for other operations.
In addition, an important point in working with CDNs is the interaction with their API to obtain up-to-date information on total and available bandwidth. In the broadcast system, these data are used to distribute new viewers and redistribute the current ones.
So, if CDN servers are able to provide enough bandwidth for millions of Internet viewers, when can problems occur at all? During the championship, we observed two main scenarios:
- For some reason, there is a lag in the broadcast.
For example, the settings of the system “played” in one of the championship matches, that the DDoS protection service, which did not expect a sudden load, began to regard what was happening as an attack, blocking the availability of CDN servers one by one ... until he was notified that some sense is extreme, but still regular (the necessary conclusions were made - the situation did not repeat in the next broadcasts).
At such moments, all users who have been overtaken by a massive problem begin to update the page with the player. - A goal scored (especially the first), as a rule, provokes a huge influx of spectators in a limited period of time.
If we talk about more specific numbers, then such an influx amounted to hundreds of thousands of users in 1-1.5 minutes.
Both of these cases generated sharp bursts of requests for dynamic site content that needed to be processed with available resources. How are such problems generally tracked and solved?
3. Real-time monitoring and statistics
It is possible to joke with a considerable amount of truth that during the whole championship we had a special position, the duties of which included a close look at football in the workplace. Of course, it was not so much football as such, but rather a quick reaction to any incidents provoked by the course of matches or other circumstances ...
What kind of "other circumstances"? At such events, even the influence of the weather is noticeable. Here are two examples of the championship that we encountered:
- When a thunderstorm began during one of the matches, satellite TV providers had problems with equipment (it was impossible to send a signal). This led to a noticeable increase in traffic (by about 10%) in a short time, because in search of an urgent alternative solution, viewers began to massively surf the Internet and continue watching there.
- When it started to rain during the final match, a small (about 3%) jump of disconnection and repeated (about 5 minutes) user connections was noticeable. No problems in the broadcast itself were observed, that is, the reasons for the jump did not have a technical basis. The assumption is that viewers who watched football on the street (as I myself did), because of the rain, went into the room, and for a short time they disconnected from the broadcast.
Returning to the topic of monitoring itself - at the time of the entire championship, the practice of regular (after each peak broadcast) meetings with developers, which analyzed all critical situations (or close to those) and their consequences, was taken as the norm , in order to minimize potential problems in next time. What servers / services were at the limit? What requests were particularly demanding? What queries can I remove (transfer to CDN to cache for a few seconds)? What queries can be cached longer (every 3 minutes, not per minute)? What will happen with a projected increase in the number of viewers, because Russia will play? ..
By the wayAbout Russia. It is easy to guess that, on average, there were several times more people on matches with the participation of the Russian national team than others. And the further our team moved along the tournament grid, the more difficult it was to combine their joy in this regard with the performance of their direct duties - after all, everything was complicated by the tireless growth of the audience. Despite the fact that the system was designed to withstand huge loads, they do not happen as often in the normal work schedule (less than 10 times a year) ... and in the case of the World Cup we observed almost daily highload peaks throughout the month. The advantage of such a regime, however, was ample opportunities to detect current bottlenecks, which are detected only in moments of such loads.
So, if part of the purely technical issues were removed by standard graphics from the monitoring systems, then the solutions of the more complex and / or business-oriented problems of the project played an important role under the internal name “Real-time statistics”.
Real time statistics
This important component of the Internet broadcasting infrastructure was designed and implemented by our efforts to provide a business intelligence tool with technical data collected from players in which users view videos. At its core, this is a logging system that:
- collects all sorts of available data about users (browser, IP, etc. - for simplicity, we can say that these are the characteristics that we are used to look at in statistics on the audience of the site);
- supplements them with technical data about the broadcast (bitrate, etc.) and the events / problems that occurred (CDN switching, crashing while watching ...);
- provides the balancer with data for optimal distribution of the load among CDN servers (in accordance with the characteristics of each user);
- sends necessary alerts to engineers on duty and creates graphics useful for business.
The last point is the most interesting, because:
- Alerts of this statistical system are a key component of monitoring, which allows you to “keep abreast of” practical indicators during broadcasts. Analyzing them (where there is not enough automation), the duty officer makes the appropriate decisions to improve the quality of service in real time. For example:
- Did many users switch from the same CDN server? It is necessary to temporarily disable it from the rotation (or contact the provider for prompt response).
- Have users started experiencing massive problems while watching a video? Time for an urgent analysis of the causes.
- Charts are real-time generated business statistics that allow you to answer key questions such as:
- How many users watched the last minute broadcast?
- What percentage of users had problems in the last minute and what character were they?
Since similar events have the same profile of graphs, the graph itself allows predicting an increase in the number of users for the next few minutes and take proactive actions if necessary.
Since these statistics work in real time and are critical for the quality of the entire service, even the simple nature of watching videos by millions of users is not limited to distributing content to them via a CDN. To achieve fast recording of new data from numerous players (we are talking about tens of thousands of requests per second to write to each server), ClickHouse helps with graphs, and the usual Grafana is used for graphs.
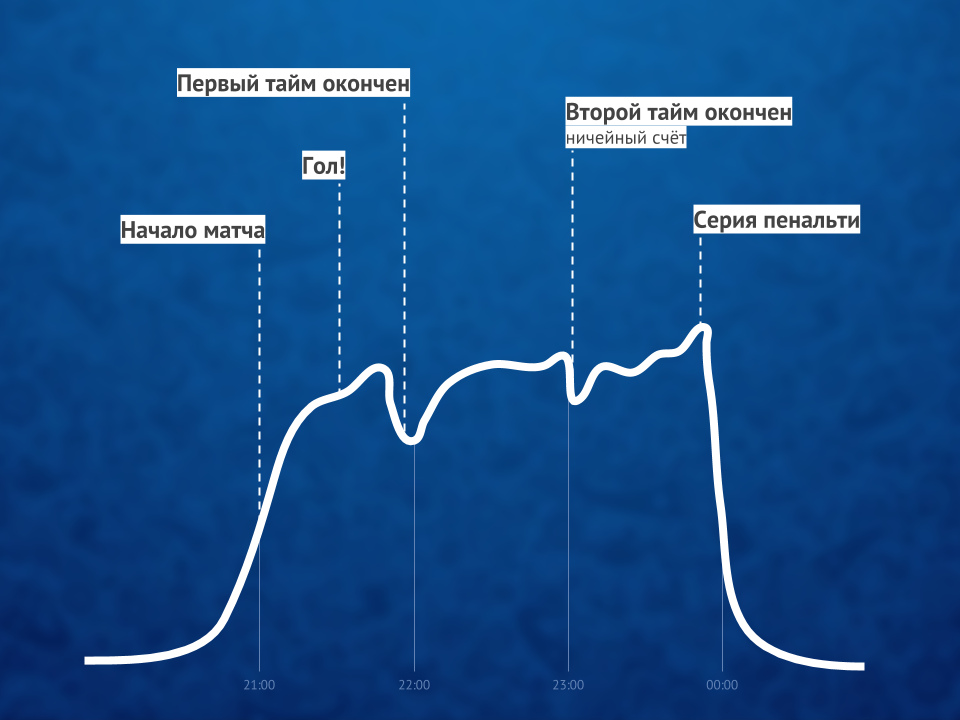
Illustration of the ratio of the number of viewers of online video before, during and after the match.
By the way : An interesting workaround during peak loads was disabling HTTPS (in favor of HTTP) for requests from the statistics system, which led to a two-fold decrease in CPU load on some of the servers. .
Results
The success of online broadcasts of such a large-scale event (and even YouTube TV did not always cope with the loads !) Was ensured by three key factors:
- competent architecture (for the broadcast system and the site), which even without the use of modern systems like Kubernetes was initially focused on high loads, scalability and readiness for significant surges;
- CDN servers with sufficient bandwidth;
- specialized monitoring, which allowed: a) to track problems in real time, b) to provide the necessary information in order to avoid them in the future.
Although there were actually more factors ... and one of them, perhaps, is capable of surpassing all the technical ones - the human one. The most important role was played by specialists, who not only could make and tie everything technically necessary, but also tirelessly to achieve results, in which I especially want to note the merits of the customer’s management.
PS about the mentioned Kubernetes ... a story about which many readers of our blog might have expected to see. The migration process of the broadcast system has already begun, but during the World Cup, these developments were not yet involved.
Pps
Read also in our blog: