RabbitMQ tutorial 2 - Task Queue
- Transfer
- Tutorial
In continuation of the first lesson on the study of the basics, RabbitMQ will publish a translation of the second lesson from the official site . All examples, as before, are in python, but you can still implement them on most popular languages .
Task queues
In the first lesson, we wrote two programs: one sent messages, the second received them. In this lesson, we will create a queue that will be used to distribute resource-intensive tasks between multiple subscribers.
The main goal of such a queue is not to start the task right now and not wait until it is completed. Instead, tasks are delayed. Each message corresponds to one task. A handler program running in the background will accept the task for processing, and after a while it will be completed. When you run several handlers, tasks will be divided between them.
This principle of operation is especially useful for use in web applications where it is impossible to handle a resource-intensive task during an HTTP request.
Training
In the previous lesson, we sent a message with the text “Hello World!”. And now we will send messages corresponding to resource-intensive tasks. We will not perform real tasks, such as resizing an image or rendering a pdf file, let's just make a stub using the time.sleep () function . The complexity of the task will be determined by the number of points in the message line. Each point will “run” for one second. For example, a task with the message “Hello ...” will run for 3 seconds.
We will slightly modify the send.py program code from the previous example so that it is possible to send arbitrary messages from the command line. This program will send messages in our turn, planning new tasks. Let's call hernew_task.py :
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print " [x] Sent %r" % (message,)
The receive.py program from the previous example should also be changed: it is necessary to simulate the performance of useful work, one second for each point in the message text. The program will receive a message from the queue and complete the task. Call it worker.py :
import time
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
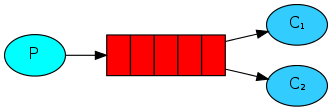
Cyclic distribution
One of the advantages of using the task queue is the ability to do work in parallel with several programs. If we do not have time to complete all incoming tasks, then we can simply add the number of handlers.
First, let's run two worker.py programs at once . Both of them will receive messages from the queue, but how exactly? We will see now.
You need to open three terminal windows. In two of them, the worker.py program will be launched . These will be two subscribers - C1 and C2.
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
In the third window we will publish new tasks. After the subscribers are started, you can send any number of messages:
shell3$ python new_task.py First message.
shell3$ python new_task.py Second message..
shell3$ python new_task.py Third message...
shell3$ python new_task.py Fourth message....
shell3$ python new_task.py Fifth message.....
Let's see what was delivered to subscribers:
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'First message.'
[x] Received 'Third message...'
[x] Received 'Fifth message.....'
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'Second message..'
[x] Received 'Fourth message....'
By default, RabbitMQ will forward each new message to the next subscriber. Thus, all subscribers will receive the same number of messages. This way of distributing messages is called cyclic [ round-robin algorithm ] . Try the same with three or more subscribers.
Message confirmation
These tasks take a few seconds to complete. Perhaps you have already wondered what would happen if the handler started the task, but unexpectedly stopped working, completing it only partially. In the current implementation of our programs, the message is deleted as soon as RabbitMQ delivered it to the subscriber. Therefore, if you stop the handler during operation, the task will not be completed, and the message will be lost. Delivered messages that have not yet been processed will also be lost.
But we do not want to lose any tasks. We need that in the event of an emergency exit of one handler, the message is transmitted to another.
So that we can be sure that there are no lost messages, RabbitMQ supports message confirmation. Confirmation ( ack) is sent by the subscriber to inform RabbitMQ that the received message has been processed and RabbitMQ can delete it.
If the subscriber stopped working and did not send a confirmation, RabbitMQ will understand that the message has not been processed and will transfer it to another subscriber. So you can be sure that not a single message will be lost, even if the execution of the handler program unexpectedly stopped.
There is no timeout to process messages. RabbitMQ will transfer them to another subscriber only if the connection to the first is closed, so there are no restrictions on the processing time of the message.
By default, manual confirmation of messages is used. In the previous example, we forced the automatic confirmation of messages by specifying no_ack = True. Now we will remove this flag and will send a confirmation from the handler immediately after the task is completed.
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
Now, even if you stop the handler by pressing Ctrl + C while processing the message, nothing will be lost. After the handler stops, RabbitMQ will resubmit the unconfirmed messages.
Do not forget to confirm messages
Sometimes developers forget to add basic_ack to the code . The consequences of this small error can be significant. The message will be retransmitted only when the handler program is stopped, but RabbitMQ will consume more and more memory, because will not delete unconfirmed messages.
To debug these kinds of errors, you can use rabbitmqctl to display the messages_unacknowledged field (unacknowledged messages):
$ sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Listing queues ...
hello 0 0
...done.
[or use the more convenient monitoring script, which I cited in the first part ]
Message Stability
We figured out how not to lose tasks if the subscriber unexpectedly stopped working. But the tasks will be lost if the RabbitMQ server stops working.
By default, when a RabbitMQ server stops or crashes, all queues and messages are lost, but this behavior can be changed. In order for messages to remain in the queue after the server is restarted, it is necessary to make both queues and messages stable.
First, make sure that the queue is not lost. To do this, you must declare it as sustainable ( durable ):
channel.queue_declare(queue='hello', durable=True)
Although this command is correct in itself, it will not work now because the hello queue has already been declared unstable. RabbitMQ does not allow overriding the parameters for an existing queue and will return an error when trying to do this. But there is a simple workaround - let's declare a queue with a different name, for example, task_queue :
channel.queue_declare(queue='task_queue', durable=True)
This code needs to be fixed for both the provider program and the subscriber program.
This way we can be sure that the task_queue queue will not be lost when the RabbitMQ server restarts. Now you need to mark messages as resilient. To do this, pass the delivery_mode property with a value of 2 :
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
A Note About Message Stability
Marking a message as sustainable does not guarantee that the message will not be lost. Despite the fact that this forces RabbitMQ to save the message to disk, there is a short period of time when RabbitMQ confirmed the acceptance of the message, but has not yet written it. Also, RabbitMQ does not do fsync (2) for each message, so some of them can be cached, but not yet written to disk. The message stability guarantee is not complete, but it is more than enough for our task queue. If you require higher reliability, you can wrap transactions in transactions.
Uniform distribution of messages
You may have noticed that message distribution is still not working as we need. For example, when two subscribers work, if all the odd messages contain complex tasks [require a lot of time to complete] , and even ones require simple tasks , then the first handler will be constantly busy, and the second most of the time will be free. But RabbitMQ does not know anything about it and anyway will transmit messages to subscribers in turn.
This is because RabbitMQ distributes messages the moment they get into the queue and does not take into account the number of unconfirmed messages from subscribers. RabbitMQ simply sends every nth message to the nth subscriber.
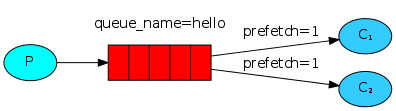
In order to change this behavior, we can use the basic_qos method with the optionprefetch_count = 1 . This will cause RabbitMQ not to send more than one message to the subscriber at a time. In other words, the subscriber will not receive a new message until he processes and confirms the previous one. RabbitMQ will send the message to the first free subscriber.
channel.basic_qos(prefetch_count=1)
Queue size note
If all subscribers are busy, then the queue size may increase. You should pay attention to this and, possibly, increase the number of subscribers.
Well, now all together
The full code for new_task.py is :
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print " [x] Sent %r" % (message,)
connection.close()
Full code for worker.py :
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
Using message acknowledgment and prefetch_count , you can create a task queue. Configuring resilience will allow tasks to persist even after restarting the RabbitMQ server.
In the third lesson, we will look at how you can send a single message to several subscribers.