How eight people scale a highload project. Unsplash experience
- Transfer

Photo: Alex Smith | Unsplash
Good afternoon!
My name is Victor Pryazhnikov, I work in the Features section of Badoo . The main task of our department is to develop the functionality that users of our site and applications see. When I caught sight of an article by Unsplash co-founder Luke Chesser, she intrigued me by the fact that they manage to develop a relatively large project with a very small team. The author’s approach appeals to me with his pragmatism and with something reminded “ You are not Google ”, so I decided to translate it.
One of the funniest things about developing Unsplash is the large scale and popularity of the product.
On a typical day, our API processes more than 10 million requests fromUnsplash.com and thousands of third-party applications, millions of events go through our pipeline data processing , 60 million updates are added to our tapes , and we serve 60 million images.
At the same time, our team is relatively small: two designers, three people working with the front-end, two with a backend, and one data engineer. We do not have a separate DevOps engineer, and each team member spends most of his time experimenting and developing new features to ensure further product development.
Although we have already achieved a lot with Unsplash, we are still at the very beginning of its path as a product and business. We still have something to prove, and this means that the whole team needs to focus on solving problems that are unique to Unsplash, and not those of any other company, such as organization of calculations, network security, infrastructure building, management dependencies, etc.
Over the past three years, we have developed a set of principles that allow us to focus on growth and avoid scaling problems. Unfortunately for those who are looking for a silver bullet, it will not be here: it is just common sense and a set of principles that we borrowed from others.
1. Use boring obvious solutions.
Or be pragmatic.
Before embarking on a new tool, a database (RethinkDB, RocksDB, etc.), a new pattern (“functional everything!”) Or a new architecture (“microservices, help!”), Try all the obvious options.
On the backend side, there are very few problems that cannot be solved quite effectively using standard, well-known tools and proven patterns like caching, batch processing, asynchronous processing, and preliminary preparation of the necessary data.
2. Focus on solving user problems, not technology.
Unsplash is a food company, not a technology company. We received a lot of money from investors to focus on solving the problems of our product and the market, rather than trying to achieve a three percent reduction in operating costs for the use of common technologies.
We spend our time on the use of ready-made technologies in a way that will help solve the problems of our users and increase the Unsplash community. These are tasks unique to Unsplash, and if we succeed in creating something new and valuable, we can postpone optimization to a later date, when these 3% optimization can become the main source of growth.
Our potential colleagues who have heard about the scale of Unsplash and a small team, the use of images and artificial intelligence, future features, can be confused by the fact that we use a lot of out-of-the-box technologies, services and frameworks. It makes us pay a little more right now, but it allows us to postpone the internal development of these technologies for a while and place it on the shoulders of our future colleagues.
The code layout process, server configuration, system dependencies, data processing and analysis, image processing and personalization are examples of areas that we chose not to focus our engineering resources on them, but instead use ready-made third-party services for each of them.
3. Spend money on solving technological problems.
The reverse side of the focus on product problems lies in the additional costs of access to ready-made technologies and third-party services.
It became a bit of a joke inside our team. They say that my first reaction to any problem will be the question: “Have you tried to solve it with money?”. But this is not a joke, but one of my favorite approaches to solving problems.
Optimizing infrastructure and technology costs is so common a problem with simple and repetitive solutions that no food company with investors should take care of it until it feels that the growth of the main metric is no longer its priority.
When we spend money on solving technological problems, we untie the hands of the team, allowing it to focus on non-recurring complex problems like finding a way to increase the size of the user base by 40% in the current quarter.
So these are three fairly simple, but abstract principles that we follow.
But how do they look in practice?
If you look at the Unsplash architecture, you will see that it is very simple and almost boring (at least according to 2017 standards). Simplified diagram of the main parts of which Unsplash consists. We use Heroku wherever possible in order to simplify the layout, configuration, testing, support and scaling of our main applications. Heroku is some kind of magic that separates the parts of the application and the development process so that our team members do not need to be familiar with it in order to develop and share experiments.
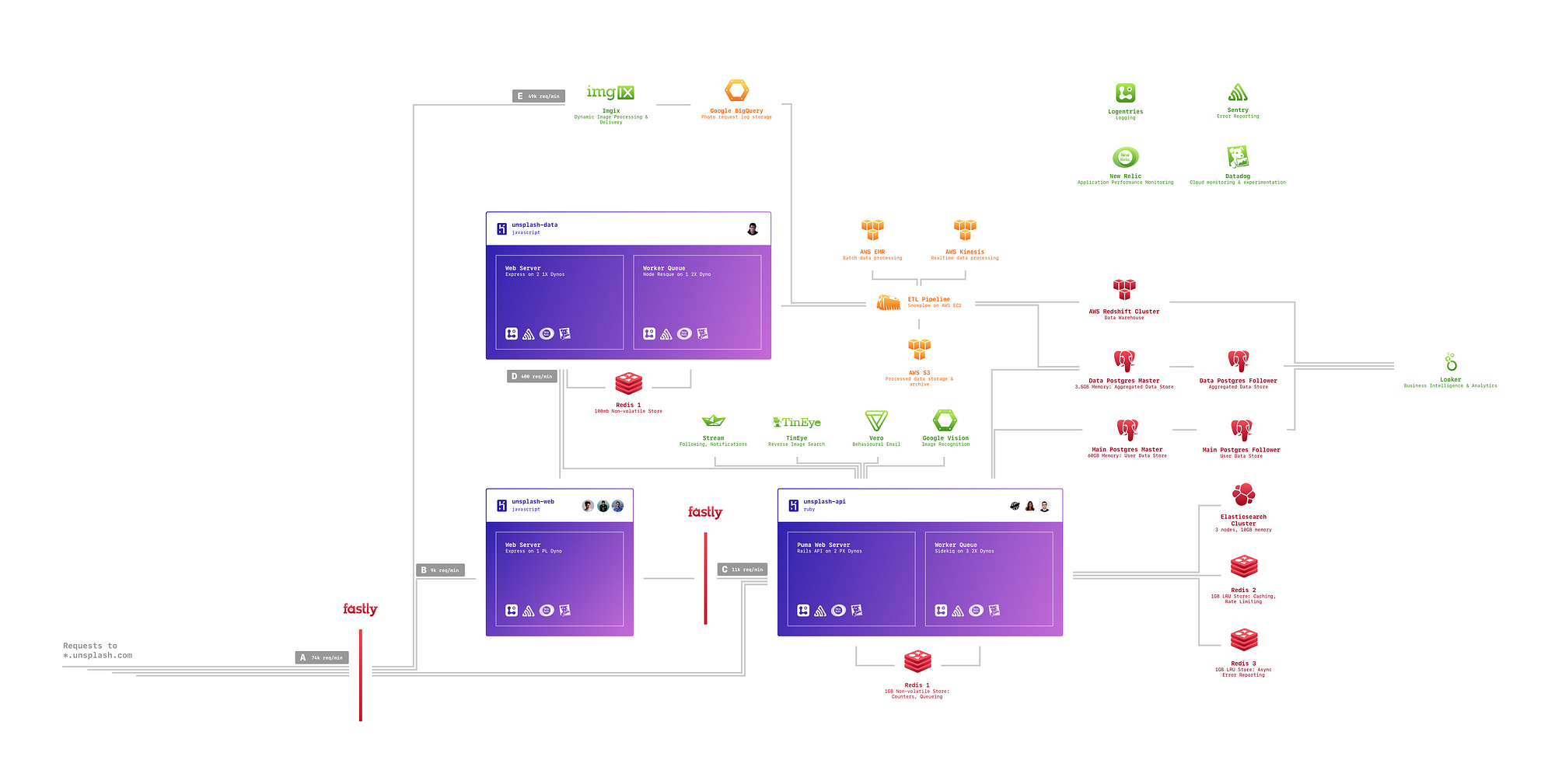
We aggressively minimize the amount of code that we write for the business logic of the application (the purple areas in the picture). While writing it, we actively use frameworks created by other people, who, being experts in their fields, have developed solutions that successfully work in 95% of our usage scenarios.
We are actively using in production Redis, Elasticsearch and Postgres. In the past, we tried other databases, but always returned to these three, as we are sure that we understand how they behave under load.
We also actively use task queues, asynchronously processing many operations, such as updating, aggregating and synchronizing data between different sources.
We use Snowplow to process the data ., an open integrated framework written in Scala, which saves our team from having to think about the organization of entry and exit, and not about the processing itself.
We also use a whole set of cloud services for monitoring, such as Datadog , New Relic , Sentry and Logentries , instead of deploying and maintaining our own StatsD or ELK stack.
We transferred the hosting and infrastructure for the return of our images to outsource to imgix , a leading company working with dynamic images. If they add some kind of new functionality, our team makes one change in the URL - and our users also get access to this functionality.
We record all the actions of our users in the service of Stream , using their experience in building and optimizing high-loaded personal tapes. Stream makes it easy for us to process billions of actions and provide a simple API for entering and exiting that works with the kind of performance that our team would spend months or even years to create.
We do not train image recognition algorithms ourselves, but instead use TinEye for reverse image search and Google Vision to recognize and classify images.
We record all behavioral events in Vero, a platform for working with notifications and mailings, which allows you to transfer the work with them into the hands of our non-developer colleagues. They themselves can create letters with a high level of personalization based on the complex use of existing data on user behavior.
At the same time, we focus on those parts of Unsplash that can improve our core competencies.
Over the past year, we have divided our single application, written in Ruby on Rails , into the Rails API, the web application on Node.js + React, and created a separate data application that collects and processes all of our internal and product metrics.
This allowed our team to create functionality that seemed almost impossible on our old stack consisting only of Rails. Dividing the problems and technologies of our applications, our team also had the opportunity to use the best tools in each of the areas:
- On the front end, we use React and Webpack along with a small server on Express to support server rendering and proxying API requests. We deliberately did not bind the tools of our frontend team to the backend by temporary hacks like react-rails or webpacker . The JavaScript community, without a doubt, releases the best tools for working with the front-end, so working directly with JavaScript allows our team to quickly deliver high-quality functionality to users.
- On the backend, our team continues to use the best framework for developing simple web applications: Rails. The Ruby on Rails ecosystem provides the best tools for backend functionality, and since this framework is widely used, any problem with it has already been found, documented, and with a high degree of probability it already has a solution.
- On the data side, our team uses a small server on Express to collect and organize data processing. The processing itself takes place in Snowplow, which works in an AWS cluster, where there are ready-made images for it that simplify configuration and deployment. This allows our only data engineer, Tim, to spend most of his time transferring data to Snowplow and getting results from there in a way that makes it easy for the rest of the team to understand and get insights.
We are actively engaged in writing tests , measuring performance using tools such as Scientist and Datadog, unfolding changes in the form of experiments and automating the work with our infrastructure as much as possible .
We are developing a new internal API based on GraphQL to speed up iterative experiments, new features and products, because we realized that our REST based API breaks down without a high level of coordination between data, design, frontend and backend teams - better we will spend this time on features, not JSON changes.
Although it is interesting to work on these changes, we do them not because we want to satisfy our programmer's itch, but because it solves our real problems that prevent us from quickly delivering functionality to users and developing.
I think that most people who have read this far have one of three conclusions in their head:
- Unsplash is very simple, so you can use this approach. What I do is much more complicated, so we have to do everything differently.
- I am a developer. It sounds very boring - I want to create a new system of recognition of images with high loads!
- Cool! I don't care, just give me beautiful free photos that I can use.
People with conclusion No. 1, you are right: there are companies that do much more complicated things than we do. But they are not so many. We all create the same systems, but focused on a few other things, and this is the reason why the solutions used can be abstracted as frameworks and reused in different projects (therefore most hiring posts are so similar to each other).
People with conclusion number 2, it depends on what you find interesting. If you want to push the boundaries of technology, then go to work for a company whose mission is to do it. There are not many of them, but most other companies simply do not do this.
To people with conclusion No. 3, I will say: “Yes, quite right!” In the end, this is what we are doing all this for.
We are close to the principles in Badoo, about which the author tells. The main difference is that our project is much larger and using external services for us is often very expensive. At the same time, many of our solutions are very simple and we try to carefully approach their changes by comparing the cost of introducing and operating a new technology with the benefits we receive from it. Some of our solutions are rather old-fashioned, since they were created quite a long time ago, but switching to similar new ones just for the sake of fashion will not pay for the resources spent on it. At the same time, we are ready to introduce new technologies if we understand that they can bring real benefits (for example, PHP 7 , Go , Cassandra , Tarantool , Exasol ).
Only registered users can participate in the survey. Sign in , please.