Silent revolution: flash memory in data centers
Flash memory is already revolutionizing data centers: transferring data to flash is the next step in the development of many centralized IT systems. Yes, it is quite expensive, it has its own characteristics - and yet today the question for data center administrators is not whether to use flash memory or not, but how and when to do it.

Here, in this topic , background information was already given, showing that the new type of drives is noticeably faster and more reliable for threshing machines, on which heavy databases are running. If it is possible to load the flash storage with work (that is, provide constant read-write operations), its contents are much cheaper than the contents of the HDD array, plus you get a bunch of additional bonuses.
Below are tips on how to determine if it's time to switch to this technology or not.

Violin VMA3205 PCI-e flash card and external flash storage capacity graph
Enterprise Applications
This is the first good use case. Flash memory improves two key metrics that are important to management and end users of IT systems: application availability and performance. Flash memory will perform in all its glory if two conditions are met:
On the other hand, some consider the transition to flash memory a panacea for all ills. This is not so, but the tool is really effective for increasing the productivity of enterprise applications, it really allows you to achieve this at the lowest price compared to other solutions that are on the market. Before making a decision, you need to look at the loading of your system specifically. As my practice shows, in 70-80% of cases the problem with the speed of the application is either directly related to the low speed of the disk subsystem, or the situation can be seriously improved by disk acceleration.
By the way, such a solution may not be obvious. For example, when the system shows that the CPU is 100% busy, it is not necessary to automatically assume that the problem will be solved by adding the CPU. You need to dig a level deeper and see what the processor is busy with. Often he is busy waiting for input-output (IOWAIT). Speeding up the disk system can offload the CPU and solve the problem.
In order to understand whether there is a problem with the disk subsystem or not, it is necessary to plot the response time of the disk subsystem. Each OS has its own tools that make it easy to do this - perfmon, iostat, sar, nmon and others.
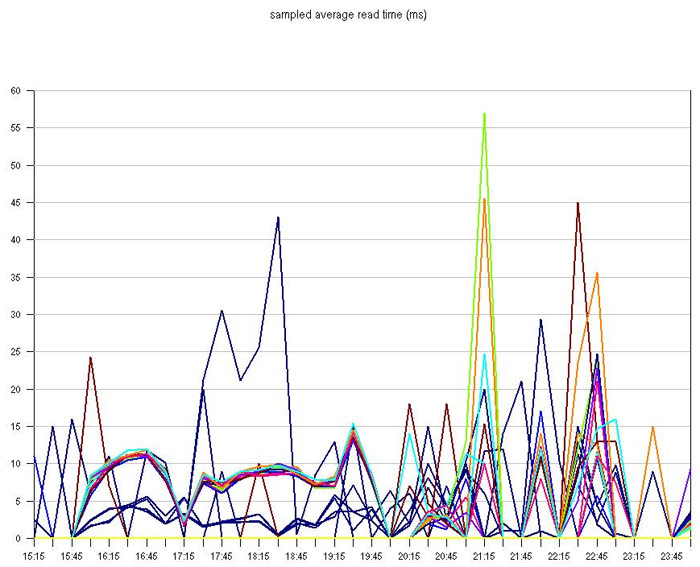
As a very general recommendation - if users complain about the insufficient speed and response time of the disk - tens of milliseconds - something needs to be done. For example, this is a graph of the response of volumes on which a fairly large processing system was located. At this speed, the storage system worked pretty badly for her, especially when people went to the ATMs after work, or when the system summed up the day:
It often happens that even if the system slows down, this is not always complained of. If the system slows down gradually, then people just get used to it. They cannot say whether it works well or poorly - it works like yesterday, and this is the main thing. Users begin to complain if everything was fine and it suddenly became bad. This applies to many enterprise applications that accumulate databases, information about orders and customers, and so on. The plus is that it works in the opposite direction. Therefore, if there is a quick and practical way to improve the user experience of the system, the IT specialist always looks like a magician in the eyes of management. In this regard, our profession is somewhat reminiscent of plumbing everyday life: it is easy to stand out when something has become bad, but it is very difficult to stand out because something has become better.
Virtualization
The second area of application for flash storage is virtualization, which almost everyone now has. Most companies implement server virtualization, then workstations, and then go to the "clouds". From my practice, most large customers are completing the first stage, this year is marked by a serious increase in workstation virtualization projects. But, as we saw in the examples of several customers, often when consolidating a huge number of tasks for a small amount of iron, the storage space again becomes a bottleneck.
When you try to put hundreds of machines in the data center on one large storage (where often only vertical scaling is possible, rather than installing a dozen more of them), it often becomes the place that determines the speed of the entire system. This is very noticeable in projects for virtualization of workstations: often there are problems at the beginning of the working day, when everyone comes in, at lunch and at the end of the day. If before the computer booted up for 5 minutes, now it’s 15, and at the same time the user is also told that this is the most advanced technology, it becomes clear his displeasure. Moreover, the authorities are also dissatisfied: tens and hundreds of thousands of dollars were spent, and, judging by their appearance, it only got worse. Here you can again act as a good wizard.
Still worth immediately voicing such a moment: objectively, the storage space that is suitable for virtualization is much more expensive than conventional hard drives on servers. Just taking the amount that each user had and copying it to a large, good storage system will fail, you need to somehow optimize the space.
A popular optimization technology when switching to storage is called the "golden image". For example, when you need 1000 computers with Windows 7, you do not need to install 1000 distributions and occupy several terabytes of operating system files. The virtualization system will create one so-called “golden image” of the operating system. At the same time, all users will read from it, and only files other than those stored in the image will be stored on their virtual machines. It is clear that in doing so, a huge amount of read operations crashes on a small amount of disk space. In the event that the reference image somehow changes seriously (patches are installed, for example), thousands of workstations are updated. Of course, this will also give a huge load on storage.
Above, I have already given an example with 100% CPU utilization while waiting for a read-write operation. If you reduce the time during which the processor is idle, waiting for the disk subsystem, you may need fewer processors to solve the main problem. This can help delay the upgrade of the server.
In addition, most corporate software such as Oracle, SAP, VMware and so on is licensed either for physical processors or for their cores. Accordingly, the customer, scaling horizontally, pays several tens of thousands for the processor (these are the prices in high-end servers), and then pays even more for software. But for the acceleration of their storage, which will give no less effect, software manufacturers do not need to pay anything.
If you have a highly loaded system, make an analysis of how much the existing storage system suffices for it. If you need to optimize the storage of information, you should definitely at least try flash storage. A bunch of superstitions are connected with the flash, as with any new technology, uncertainty as to whether the solution is suitable or not, plus understandable conservatism. You can solve it most often only in practice. Just try: ask a flash system or several SSD disks in your array for a test from a friendly vendor or system integrator, calculate the result and evaluate how much you really need it.
In the near future, the Violin Memory demo array is coming to us, now a small queue is already being built. If you are interested in this (and you have tasks that require high storage capacity), you can write to me at dd@croc.ru.
Here, in this topic , background information was already given, showing that the new type of drives is noticeably faster and more reliable for threshing machines, on which heavy databases are running. If it is possible to load the flash storage with work (that is, provide constant read-write operations), its contents are much cheaper than the contents of the HDD array, plus you get a bunch of additional bonuses.
Below are tips on how to determine if it's time to switch to this technology or not.
Let's start with simple facts.
- Flash memory is very expensive. Yes, the cost of storing a gigabyte of information on flash drives and flash storage is several times more expensive than mechanical HDDs. However, for applications that create a load on storage systems of thousands of IOPS and are sensitive to the response time of the disk subsystem, it becomes cheaper and more reliable (of course, such applications should be placed on specialized storage systems, and not on one SSD-drive or PCI-e card for which theoretical performance of hundreds of thousands of IOPS is claimed).
- Flash memory is unreliable. Many still consider the technology “damp” and attribute the problems of the first prototypes to modern flash drives. As part of SSD-drives, and even more so, in specialized storage systems, modern flash memory shows reliability indicators higher than HDD. Moreover, I believe that any storage system that runs serious services should be supported by the supplier or manufacturer. In this case, the failure of the HDD or SSD does not bother you at all; replacing it is a routine of the support service. Many modern storage systems can themselves report a failure to the service center. Often faster than you yourself find the refusal, they already call you to agree on the time of the visit.
- The number of write cycles is limited.It’s true, now - SLC is about 100,000 rewrite cycles, MLC is 10,000. The problem is solved by uniform loading of blocks, and this is provided by the controller. It is impossible for only reading to be in one section, and constant changes in the other. The mechanism responsible for this is called wear leveling. So, for Violin Memory systems, this algorithm uniformly “wears out” the entire storage space. In other systems, the controller of each SSD is responsible for the wear leveling, which is less efficient. At the same time, part of the flash memory space (up to 30%) is reserved for the remap of such worn blocks. If we assume that the database will write to a 10TB system around the clock and 365 days a year with 25,000 IOPS in 4Kb blocks (approximately 100 MB / s), then 1% of the SLC system will wear out in 3 years and 4 months, 1% of the MLC array in 4 months.
- Flash memory is suitable for reading, but not very good for writing.This is due to the recording processing mechanism. In order to write to a cell, it must first be cleaned. Erasing occurs not with one cell, but with the whole block, in which from 64 to 128 and more Kb are combined. And while the erasing process is in progress, all other operations are stopped for a rather long time, measured in milliseconds. Given that the block is usually larger than what is required for the transaction, a lot depends on the "firmware" and the algorithms of the controller. If there is only one drive, then the process is really slow. But the situation changes if the storage system is large. Then the controllers can redistribute the load so that the effect of blocking the system before recording will not greatly affect the operation of the system, and it will be able to give almost the same performance for writing as for reading.
- Errors increase with the number of read cycles per block. Yes, it is a fact. Like previous problems, the issue is decided by the controller. First of all, it should decommission obsolete cells. But even if this mechanism suddenly failed, no one canceled the RAID protection that works on storage controllers or servers.
- Speed drops as the media fills. Yes, performance is ideal when the memory is almost not used, but as the data is overwritten, blocks remain where some of the cells contain the necessary data and some are not. The controller starts the garbage collection process by transferring the necessary data from the unfilled cells and erasing them on the disk. To understand the true speed of a 400 GB drive, you need to write at least 1 TB on it in different transactions to get practical data. Here is an illustration of two graphs. Of course, the larger the amount of data on the storage system, the greater the space for maneuvering and smoothing this effect.
Violin VMA3205 PCI-e flash card and external flash storage capacity graph
Why use?
Enterprise Applications
This is the first good use case. Flash memory improves two key metrics that are important to management and end users of IT systems: application availability and performance. Flash memory will perform in all its glory if two conditions are met:
- A fairly loaded application. Big Oracle, SAP, CRM, ERP, enterprise portals are excellent candidates.
- Using external storage with duplicated controllers and server connections.
On the other hand, some consider the transition to flash memory a panacea for all ills. This is not so, but the tool is really effective for increasing the productivity of enterprise applications, it really allows you to achieve this at the lowest price compared to other solutions that are on the market. Before making a decision, you need to look at the loading of your system specifically. As my practice shows, in 70-80% of cases the problem with the speed of the application is either directly related to the low speed of the disk subsystem, or the situation can be seriously improved by disk acceleration.
By the way, such a solution may not be obvious. For example, when the system shows that the CPU is 100% busy, it is not necessary to automatically assume that the problem will be solved by adding the CPU. You need to dig a level deeper and see what the processor is busy with. Often he is busy waiting for input-output (IOWAIT). Speeding up the disk system can offload the CPU and solve the problem.
In order to understand whether there is a problem with the disk subsystem or not, it is necessary to plot the response time of the disk subsystem. Each OS has its own tools that make it easy to do this - perfmon, iostat, sar, nmon and others.
As a very general recommendation - if users complain about the insufficient speed and response time of the disk - tens of milliseconds - something needs to be done. For example, this is a graph of the response of volumes on which a fairly large processing system was located. At this speed, the storage system worked pretty badly for her, especially when people went to the ATMs after work, or when the system summed up the day:
It often happens that even if the system slows down, this is not always complained of. If the system slows down gradually, then people just get used to it. They cannot say whether it works well or poorly - it works like yesterday, and this is the main thing. Users begin to complain if everything was fine and it suddenly became bad. This applies to many enterprise applications that accumulate databases, information about orders and customers, and so on. The plus is that it works in the opposite direction. Therefore, if there is a quick and practical way to improve the user experience of the system, the IT specialist always looks like a magician in the eyes of management. In this regard, our profession is somewhat reminiscent of plumbing everyday life: it is easy to stand out when something has become bad, but it is very difficult to stand out because something has become better.
Virtualization
The second area of application for flash storage is virtualization, which almost everyone now has. Most companies implement server virtualization, then workstations, and then go to the "clouds". From my practice, most large customers are completing the first stage, this year is marked by a serious increase in workstation virtualization projects. But, as we saw in the examples of several customers, often when consolidating a huge number of tasks for a small amount of iron, the storage space again becomes a bottleneck.
When you try to put hundreds of machines in the data center on one large storage (where often only vertical scaling is possible, rather than installing a dozen more of them), it often becomes the place that determines the speed of the entire system. This is very noticeable in projects for virtualization of workstations: often there are problems at the beginning of the working day, when everyone comes in, at lunch and at the end of the day. If before the computer booted up for 5 minutes, now it’s 15, and at the same time the user is also told that this is the most advanced technology, it becomes clear his displeasure. Moreover, the authorities are also dissatisfied: tens and hundreds of thousands of dollars were spent, and, judging by their appearance, it only got worse. Here you can again act as a good wizard.
Still worth immediately voicing such a moment: objectively, the storage space that is suitable for virtualization is much more expensive than conventional hard drives on servers. Just taking the amount that each user had and copying it to a large, good storage system will fail, you need to somehow optimize the space.
A popular optimization technology when switching to storage is called the "golden image". For example, when you need 1000 computers with Windows 7, you do not need to install 1000 distributions and occupy several terabytes of operating system files. The virtualization system will create one so-called “golden image” of the operating system. At the same time, all users will read from it, and only files other than those stored in the image will be stored on their virtual machines. It is clear that in doing so, a huge amount of read operations crashes on a small amount of disk space. In the event that the reference image somehow changes seriously (patches are installed, for example), thousands of workstations are updated. Of course, this will also give a huge load on storage.
Savings: Bonuses
Above, I have already given an example with 100% CPU utilization while waiting for a read-write operation. If you reduce the time during which the processor is idle, waiting for the disk subsystem, you may need fewer processors to solve the main problem. This can help delay the upgrade of the server.
In addition, most corporate software such as Oracle, SAP, VMware and so on is licensed either for physical processors or for their cores. Accordingly, the customer, scaling horizontally, pays several tens of thousands for the processor (these are the prices in high-end servers), and then pays even more for software. But for the acceleration of their storage, which will give no less effect, software manufacturers do not need to pay anything.
Summary
If you have a highly loaded system, make an analysis of how much the existing storage system suffices for it. If you need to optimize the storage of information, you should definitely at least try flash storage. A bunch of superstitions are connected with the flash, as with any new technology, uncertainty as to whether the solution is suitable or not, plus understandable conservatism. You can solve it most often only in practice. Just try: ask a flash system or several SSD disks in your array for a test from a friendly vendor or system integrator, calculate the result and evaluate how much you really need it.
In the near future, the Violin Memory demo array is coming to us, now a small queue is already being built. If you are interested in this (and you have tasks that require high storage capacity), you can write to me at dd@croc.ru.