Options for building highly available systems in AWS. Overcoming interruptions in work. Part 2
In this part, we will consider the following options for building highly accessible systems based on AWS:
Building a Highly Available System Between AWS Availability Zones
Amazon access zones are separate independent, isolated data centers within the same region. Availability zones have a stable network connection between themselves, but are designed in such a way that problems in one zone do not affect the availability of other zones (they have independent power supply, cooling and security systems). The diagram below shows the existing distribution of accessibility zones (indicated in purple) within the regions (indicated in blue).

Most high-level Amazon services, such as Amazon Simple Storage Service (S3), Amazon SimpleDB, Amazon Simple Queue Service (SQS), and Amazon Elastic Load Balancing (ELB) have built-in mechanisms for providing fault tolerance and high availability. Core infrastructure services such as Amazon Simple Storage Service (S3), Amazon SimpleDB, Amazon Simple Queue Service (SQS), and Amazon Elastic Load Balancing (ELB) provide features like Elastic IP, image snapshots, and availability zones. Each fault-tolerant and highly accessible system is required to use these features and use them correctly. In order for a system to be reliable and affordable, it is not enough just to deploy it in the AWS cloud, it must be designed so that the application works in several availability zones. Availability zones are located in different geographical areas, so using multiple zones can protect the application from problems in a specific area. The following diagram shows the different levels (with software examples) that should be designed using multiple availability zones.

In order for the application to continue to work without failures and data loss in another zone if one zone is inoperable, it is important to have application software stacks independent from each other in different zones (both within the same region and in different regions). At the stage of system design, you need to understand well what parts of the application are tied to the zone.
Example:
A typical Web application consists of such levels as DNS, Load Balancer, Web server, application server, cache, database. All these levels can be distributed and deployed in two or more access zones, as described below.
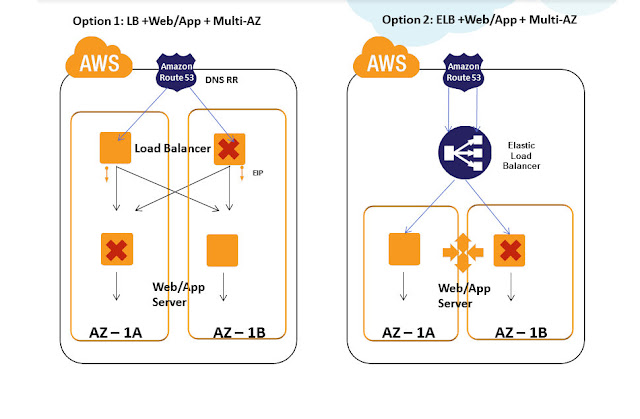
Also, most AWS embedded units are initially designed with multi-zone availability support. Architects and developers working with AWS units during the application design phase can use the built-in features to provide high availability.
Designing a Highly Available System Using AWS Embedded Units:
These blocks can be used as web services. These blocks are initially highly available, reliable, and scalable. They have built-in compatibility and the ability to work in multiple access zones. For example, S3 is designed to provide 99.999999999% safety and 99.99% accessibility of objects per year. You can work with these blocks through the API using simple calls. All of them have their advantages and disadvantages, which must be taken into account when building and operating the system. The proper use of these blocks can dramatically reduce the cost of developing and creating complex infrastructure and help the team focus on the product, rather than on creating and maintaining the infrastructure.
Building a highly accessible system between AWS regions
There are currently 7 AWS regions around the world, and their infrastructure is growing every day. The following diagram displays the current regional infrastructure:

Using AWS in several regions can be divided into the following categories: Cold, Warm, Hot Standby, and Hot Active.
Cold and Warm are more concerned with disaster recovery, while Hot Stanby and Hot Active can be considered for designing a highly accessible system between different regions. When designing a highly accessible system between different regions, the following problems must be considered:
The following diagram illustrates a simple, highly accessible system across multiple regions.

Now let's look at how to solve these problems:
Application migration.AMI images, both S3 and EBS, are available only within one region; accordingly, all necessary identical images must be created in all regions that are planned to be used. Each time you update the application code, relevant updates and changes must be made in all regions on all images. You can use automation scripts for this, but it is better to use such auto-configuration systems as Puppet or Chef, this can reduce and simplify the cost of deploying applications. It is worth noting that in addition to AMI images, there is such a service as Amazon Elastic IP, which also works only within one region.
Data migration.Each complex system contains data distributed between different data sources, such as relational databases, non-relational databases, caches, and file storage. Below are some of the technologies recommended for use when working with several regions:
Since all of the above technologies are asynchronous replications, you need to be careful about data loss and do not forget about the values of RPO (valid recovery point) and RTO (valid recovery time) to ensure high availability.
Network flow: the ability to provide network traffic flow between different regions. Consider the key points that need to be considered when working with a network stream:
Building a highly accessible system between different cloud and hosting providers
Many people talk about building a highly accessible system using several Cloud and hosting providers. You can name the following reasons why companies want to use these systems that are complex in terms of artefacture:

Most of the solutions described in the section for several AWS regions are suitable for this case.
When designing highly accessible systems between different Cloud providers or different data centers, you need to carefully determine the following key points:
Data synchronization. Usually this step is not a big problem if data warehouses can be installed, deployed for each of the Cloud providers used. The compatibility of database software, tools and utilities for working with databases, provided that they can be easily installed, will help solve problems with data synchronization between different providers.
Network stream.
Workload migration:
Amazon AMI images may not be available to other Cloud providers. New images for virtual machines must be created for each data center or provider, which may cause additional time and money costs.
Complex automation scripts using the Amazon API must be rewritten for each Cloud provider using the appropriate API. Some Cloud providers do not even provide their own infrastructure management APIs. This can lead to more complicated maintenance.
Types of operating systems, software, hardware compatibility, all this should be analyzed and taken into account in the design.
Unified infrastructure management can be a big problem when using different providers if you do not use tools such as RightScale.
Original article: harish11g.blogspot.in/2012/06/aws-high-availability-outage.html
Posted by Harish Ganesan
- Building a Highly Available System Between AWS Availability Zones
- Building a highly accessible system between AWS regions
- Building a highly accessible system between different cloud and hosting providers
Building a Highly Available System Between AWS Availability Zones
Amazon access zones are separate independent, isolated data centers within the same region. Availability zones have a stable network connection between themselves, but are designed in such a way that problems in one zone do not affect the availability of other zones (they have independent power supply, cooling and security systems). The diagram below shows the existing distribution of accessibility zones (indicated in purple) within the regions (indicated in blue).
Most high-level Amazon services, such as Amazon Simple Storage Service (S3), Amazon SimpleDB, Amazon Simple Queue Service (SQS), and Amazon Elastic Load Balancing (ELB) have built-in mechanisms for providing fault tolerance and high availability. Core infrastructure services such as Amazon Simple Storage Service (S3), Amazon SimpleDB, Amazon Simple Queue Service (SQS), and Amazon Elastic Load Balancing (ELB) provide features like Elastic IP, image snapshots, and availability zones. Each fault-tolerant and highly accessible system is required to use these features and use them correctly. In order for a system to be reliable and affordable, it is not enough just to deploy it in the AWS cloud, it must be designed so that the application works in several availability zones. Availability zones are located in different geographical areas, so using multiple zones can protect the application from problems in a specific area. The following diagram shows the different levels (with software examples) that should be designed using multiple availability zones.
In order for the application to continue to work without failures and data loss in another zone if one zone is inoperable, it is important to have application software stacks independent from each other in different zones (both within the same region and in different regions). At the stage of system design, you need to understand well what parts of the application are tied to the zone.
Example:
A typical Web application consists of such levels as DNS, Load Balancer, Web server, application server, cache, database. All these levels can be distributed and deployed in two or more access zones, as described below.
Also, most AWS embedded units are initially designed with multi-zone availability support. Architects and developers working with AWS units during the application design phase can use the built-in features to provide high availability.
Designing a Highly Available System Using AWS Embedded Units:
- Amazon S3 for object and file storage
- Amazon CloudFront for content delivery system
- Amazon ELB for load balancing
- Amazon AutoScaling to automatically scale EC2
- Amazon CloudWatch for monitoring
- Amazon SNS and SQS for messaging service
These blocks can be used as web services. These blocks are initially highly available, reliable, and scalable. They have built-in compatibility and the ability to work in multiple access zones. For example, S3 is designed to provide 99.999999999% safety and 99.99% accessibility of objects per year. You can work with these blocks through the API using simple calls. All of them have their advantages and disadvantages, which must be taken into account when building and operating the system. The proper use of these blocks can dramatically reduce the cost of developing and creating complex infrastructure and help the team focus on the product, rather than on creating and maintaining the infrastructure.
Building a highly accessible system between AWS regions
There are currently 7 AWS regions around the world, and their infrastructure is growing every day. The following diagram displays the current regional infrastructure:
Using AWS in several regions can be divided into the following categories: Cold, Warm, Hot Standby, and Hot Active.
Cold and Warm are more concerned with disaster recovery, while Hot Stanby and Hot Active can be considered for designing a highly accessible system between different regions. When designing a highly accessible system between different regions, the following problems must be considered:
- Application Migration - The ability to migrate an application environment between AWS regions
- Data synchronization - the ability to migrate real-time data between two or more regions
- Network traffic - the ability to control the flow of network traffic between regions
The following diagram illustrates a simple, highly accessible system across multiple regions.
Now let's look at how to solve these problems:
Application migration.AMI images, both S3 and EBS, are available only within one region; accordingly, all necessary identical images must be created in all regions that are planned to be used. Each time you update the application code, relevant updates and changes must be made in all regions on all images. You can use automation scripts for this, but it is better to use such auto-configuration systems as Puppet or Chef, this can reduce and simplify the cost of deploying applications. It is worth noting that in addition to AMI images, there is such a service as Amazon Elastic IP, which also works only within one region.
Data migration.Each complex system contains data distributed between different data sources, such as relational databases, non-relational databases, caches, and file storage. Below are some of the technologies recommended for use when working with several regions:
- Databases: MySQL Master-Slave replication, SQL Server 2012 HADR, SQL Server 2008, Programmatic RDS
- File Storage: GlusterFS Distributed Network File System, S3 Replication
- Cache: since replication for cache between regions is expensive in most cases, it is recommended to keep a separate heated cache in each region.
- For high-speed file transfers, services such as Aspera are recommended.
Since all of the above technologies are asynchronous replications, you need to be careful about data loss and do not forget about the values of RPO (valid recovery point) and RTO (valid recovery time) to ensure high availability.
Network flow: the ability to provide network traffic flow between different regions. Consider the key points that need to be considered when working with a network stream:
- Currently, the built-in ELB load balancer does not support load balancing between regions, so it is not suitable for distributing traffic between regions
- Reverse proxies and load balancers (such as HAProxy, Nginx) are suitable for this purpose. However, if the entire region is unavailable, then the servers that distribute the load may not be available or may not see servers located in other regions, which can lead to application errors.
- A common practice is to use distribution management at the DNS level. Using services such as UltraDNS, Akamai, or Route53 LBR (routing
- based on response time) you can redistribute traffic between regions
- Using Amazon Route53 LBR, you can switch traffic between different regions and redirect user requests to a region with less response time. As the endpoint for route53, the public IP address of the server, Elastic IP, ELB IP can be used.
- Amazon Elastic IP cannot switch between different regions. Such services, FTP and other IP-oriented services intended for communication between applications should be reconfigured to use domain names instead of IP addresses; this is a key point that must be considered when using multiple regions
Building a highly accessible system between different cloud and hosting providers
Many people talk about building a highly accessible system using several Cloud and hosting providers. You can name the following reasons why companies want to use these systems that are complex in terms of artefacture:
- Large enterprises that have already invested the bulk of their money in building their own data centers or leasing physical equipment in data centers of providers, want to use AWS for disaster recovery in case of problems with the main data center. Enterprises that already have their own private clouds based on Eucalyptus, Open Stack, Cloud Stack or vCloud installed in their own data centers and also want to use AWS for disaster recovery. Eucalyptus has maximum compatibility with AWS, as it has compatibility at the API level. Most workloads can be integrated between AWS and Eucalyptus. For example, suppose an enterprise has a set of developed scripts for Amazon EC2 using the AWS API in the Eucalyptus private cloud, this cloud can easily migrate to AWS if fault tolerance is needed. If the company uses OpenStack or another provider of a private cloud, the scripts will have to be rewritten, adapted to be able to work in the new environment. This can be economically disadvantageous for complex systems.
- Companies that see their infrastructure as not suitable for scalability or high availability can use AWS as their primary site and their data centers as secondary to disaster recovery.
- Companies that are not satisfied with the stability and reliability of their current public Cloud providers may want to use a lot of cloud structure. This case is the rarest now, but may become major in the future.
Most of the solutions described in the section for several AWS regions are suitable for this case.
When designing highly accessible systems between different Cloud providers or different data centers, you need to carefully determine the following key points:
Data synchronization. Usually this step is not a big problem if data warehouses can be installed, deployed for each of the Cloud providers used. The compatibility of database software, tools and utilities for working with databases, provided that they can be easily installed, will help solve problems with data synchronization between different providers.
Network stream.
- Switching between several providers can be achieved by using managed DNS services such as Akamai, Route53, UltraDNS. Since these solutions are independent of Cloud providers, regions and availability zones, they can be effectively used to switch network traffic between data centers and providers to ensure high availability.
- A fixed IP address can be provided by a data center or hosting provider, while some Cloud providers currently cannot provide a fixed IP for virtual machines. This can be a bottleneck while providing high availability between Cloud providers.
- Very often there is a need to establish a VPN connection between a data center, a Cloud provider to migrate sensitive data between the clouds. There may be a problem with the configuration, implementation and support of this service for some Cloud providers. This point should be considered when designing.
Workload migration:
Amazon AMI images may not be available to other Cloud providers. New images for virtual machines must be created for each data center or provider, which may cause additional time and money costs.
Complex automation scripts using the Amazon API must be rewritten for each Cloud provider using the appropriate API. Some Cloud providers do not even provide their own infrastructure management APIs. This can lead to more complicated maintenance.
Types of operating systems, software, hardware compatibility, all this should be analyzed and taken into account in the design.
Unified infrastructure management can be a big problem when using different providers if you do not use tools such as RightScale.
Original article: harish11g.blogspot.in/2012/06/aws-high-availability-outage.html
Posted by Harish Ganesan