Pitch-tracking, or determining the pitch frequency in speech, using the examples of Praat, YAAPT and YIN algorithms

In the field of emotion recognition, the voice is the second most important source of emotional data after a face. The voice can be characterized by several parameters. The pitch of the voice is one of the main characteristics, but in the field of acoustic technologies it is more correct to call this parameter the pitch frequency.
The pitch frequency is directly related to what we call intonation. And intonation, for example, is associated with emotional and expressive characteristics of the voice.
However, determining the frequency of the fundamental tone is not an entirely trivial task with interesting nuances. In this article, we will discuss the features of the algorithms for its definition and compare existing solutions with examples of specific audio recordings.
Introduction
First, let us remember what, in essence, is the frequency of the fundamental tone and in which tasks it may be needed. The pitch frequency , which is also designated as CHOT, Fundamental Frequency, or F0 is the frequency of oscillation of the vocal cords when pronouncing tonal sounds (voiced). When uttering non-tonal sounds (unvoiced), for example, speaking in a whisper or pronouncing hissing and whistling sounds, the ligaments do not fluctuate, which means that this characteristic is not relevant for them.
* Note that the division into tonal and non-tonal sounds is not equivalent to the division into vowels and consonants.
The pitch frequency variability is quite large, and it can be very different not only between people (for lower average male voices, the frequency is 70-200 Hz, and for female voices it can reach 400 Hz), but also for one person, especially in emotional speech .
Determining the pitch frequency is used to solve a wide range of tasks:
- Recognition of emotions, as we said above;
- Sex determination;
- In solving the problem of segmentation of audio with several voices or the division of speech into phrases;
- In medicine, to determine the pathological characteristics of the voice (for example, using the acoustic parameters of Jitter and Shimmer). For example, the definition of signs of Parkinson's disease [ 1 ]. Jitter and Shimmer can also be used to recognize emotions [ 2 ].
However, there are a number of difficulties in determining F0. For example, you can often confuse F0 with harmonics, which can lead to so-called pitch doubling / pitch halving effects [ 3 ]. And in a poor quality audio recording, it is quite difficult to calculate the F0, since the necessary peak at low frequencies almost disappears.
By the way, remember the story about Laurel and Yanny? Differences in what words people hear when listening to the same audio recordings arose precisely because of the difference in the perception of F0, which is influenced by many factors: the age of the listener, the degree of fatigue, the playback device. So, when listening to the recording in speakers with high-quality reproduction of low frequencies, you will hear Laurel, and in audio systems where low frequencies are reproduced poorly, Yanny. The transition effect can be seen on one device, for example, here . And in this article , the neural network acts as a listener. In another article you can read, as explained by the phenomenon of Yanny / Laurel from the standpoint of speech formation.
Since a detailed analysis of all the methods for determining F0 would be too voluminous, the article is an overview and can help orient oneself in the topic.
Methods for determining F0
Methods for determining F0 can be divided into three categories: based on the temporal dynamics of the signal, or time-domain; based on the frequency structure, or frequency-domain, as well as combined methods. We suggest to get acquainted with the review article on the topic, where the designated methods of extracting F0 are described in detail.
Note that any of the discussed algorithms consists of 3 main steps:
Preprocessing (filtering a signal, dividing it into frames)
Searching for possible values of F0 (candidates)
Tracking is the choice of the most probable trajectory F0 (since for each moment in time we have several competing candidates, we need to find the most probable track among them)
Time-domain
Let us outline several general moments. Before using the methods of time-domain signal pre-filtered, leaving only the low frequencies. Thresholds are set - the minimum and maximum frequencies, for example, from 75 to 500 Hz. The definition of F0 is made only for sections with harmonic speech, since for pauses or noise sounds this is not only meaningless, but it can also introduce errors into neighboring frames when applying interpolation and / or smoothing. The frame length is chosen so that it contains at least three periods.
The main method, on the basis of which subsequently appeared a whole family of algorithms - autocorrelation. The approach is quite simple - it is necessary to calculate the autocorrelation function and take its first maximum. It will display the most pronounced frequency component in the signal. What could be the difficulty in the case of using autocorrelation, and why not always the first maximum will correspond to the desired frequency? Even in close to ideal conditions on high quality recordings, the method may be mistaken due to the complex structure of the signal. In conditions close to real, where, among other things, we may encounter the disappearance of the desired peak on noisy recordings or recordings of initially poor quality, the number of errors increases dramatically.
Despite the errors, the autocorrelation method is quite convenient and attractive with its basic simplicity and logic, therefore, it is used as the basis for many algorithms, including YIN (Yin). Even the name of the algorithm refers us to the balance between the convenience and inaccuracy of the autocorrelation method: “It’s true.” [ 4 ]
The creators of YIN tried to correct the weak points of the autocorrelation approach. The first change is the use of the Cumulative Mean Normalized Difference function, which should reduce the sensitivity to amplitude modulation, make the peaks more explicit:
d ′ t ( τ ) ={ 1 , τ = 0 d t ( τ ) / [ 1τ τ ∑ j=1dt(j)],otherwise YIN also tries to avoid errors that occur when the length of the window function is not completely divisible by the oscillation period. For this, parabolic interpolation of the minimum is used. At the last audio processing step, the Best Local Estimate function is performed to prevent sudden changes in values (good or bad - a moot point). Frequency-domain
If we talk about the frequency domain, then the harmonic structure of the signal, that is, the presence of spectral peaks at frequencies that are multiples of F0, comes to the fore. The “collapse” of this periodic pattern to a clear peak can be made by means of a cepstral analysis. Kepstrum - Fourier transform of the logarithm of the power spectrum; The cepstral peak corresponds to the most periodic component of the spectrum (one can read about it here and here ).
Hybrid methods for determining F0
The following algorithm, which should be discussed in more detail, has the talking name YAAPT - Yet Another Algorithm of Pitch Tracking - and is actually a hybrid, because it uses both frequency and time information. Full description is in the article., here we describe only the main stages.

Figure 1. YAAPTalgo algorithm diagram ( reference ) .
YAAPT consists of several basic steps, the first of which is preprocessing. At this stage, the values of the original signal are squared, get the second version of the signal. This step has the same goal as the Cumulative Mean Normalized Difference Function in YIN - to enhance and restore “erased” autocorrelation peaks. Both versions of the signal filter - usually take the range of 50-1500 Hz, sometimes 50-900 Hz.
Then, the base path F0 is calculated from the spectrum of the converted signal. F0 candidates are determined using the Spectral Harmonics Correlation (SHC) function.
S H C ( t , f) = W L / 2 ∑ f ′ = - W L / 2 N H + 1 ∏ r = 1 S ( t , r f + f ′ ) where S (t, f) is the magnitude spectrum for the frame t and frequency f, WL is the window length in Hz, NH is the number of harmonics (the authors recommend using the first three harmonics). Also, spectral power is used to determine voiced-unvoiced frames, after which the most optimal trajectory is searched, taking into account the possibility of pitch doubling / pitch halving [3
, Section II, C].
Further, for both the initial signal and the transformed one, the candidates for F0 are determined, and the Normalized Cross Correlation (NCCF) is used here instead of the autocorrelation function.
N C C F ( m ) = N - m - 1 Σ n = 0 x ( n ) * x ( n + m )√N - m - 1 Σ n=0x2(n)* N - m - 1 Σ n=0x2(n+m),0 < m < M 0 The next stage is the evaluation of all possible candidates and the calculation of their significance, or weight (merit). The weight of candidates received from an audio signal depends not only on the amplitude of the NCCF peak, but also on their proximity to the F0 trajectory determined from the spectrum. That is, the frequency domain is considered to be rude in terms of accuracy, but stable [3, Section II, D]. Then, for all pairs of the remaining candidates, the Transition Cost matrix is calculated - the transition prices, which ultimately determine the optimal trajectory [3, Section II, E]. Examples Now apply all the above algorithms to specific audio recordings. Praatwill be used as a starting point.
- A tool that is essential for many speech researchers. And then in Python we will look at the implementation of YIN and YAAPT and compare the results obtained.
You can use any available audio as audio material. We took several excerpts from our RAMAS database - a multimodal dataset created with the participation of actors from the VGIK. You can also use material from other open bases, such as LibriSpeech or RAVDESS .
For illustrative example, we took excerpts from several recordings with male and female voices, both neutral and emotionally-colored, and for clarity, we combined them into one recording.. Let's look at our signal, its spectrogram, intensity (orange), and F0 (blue). In Praat, this can be done using Ctrl + O (Open - Read from file) and then the View & Edit buttons.

Figure 2. Spectrogram, intensity (orange), F0 (blue) in Praat.
The audio shows quite clearly that with emotional speech, the pitch of the voice increases in both men and women. At the same time, F0 for emotional male speech can be compared with F0 of a female voice.
Tracking
In the Praat menu, select the Analyze periodicity - to Pitch (ac) tab, that is, the definition of F0 using autocorrelation. A window will appear to specify the parameters, in which you can set 3 parameters to determine candidates for F0 and another 6 parameters for the path-finder algorithm (path-finder), which builds the most likely trajectory F0 among all candidates.
Many parameters (in Praat, their description is also on the Help button)
- Silence threshold - the threshold of the relative amplitude of the signal to determine silence, the standard value of 0.03.
- Voicing threshold — вес unvoiced candidate, максимальное значение равно 1. Чем выше этот параметр, тем больше фреймов будут определены как unvoiced, то есть не содержащие тоновых звуков. В этих фреймах F0 определяться не будет. Значение этого параметра — пороговое для пиков автокорреляционной функции. Значение по умолчанию — 0.45
- Octave cost — определяет, насколько больший вес имеют высокочастотные кандидаты по отношению к низкочастотным. Чем выше значение, тем большее предпочтение отдается высокочастотным кандидатом. Стандартное значение — 0.01 на октаву.
- Octave-jump cost — при увеличении этого коэффициента уменьшается количество резких скачкообразных переходов между последовательными значениями F0. Значение по умолчанию — 0.35.
- Voiced/Unvoiced cost — при увеличении этого коэффициента уменьшается количество Voiced/Unvoiced переходов. Значение по умолчанию — 0.14.
- Pitch ceiling (Hz) — кандидаты выше этой частоты не рассматриваются. Стандартное значение — 600 Гц.
A detailed description of the algorithm can be found in the article in 1993.
You can see the result of the tracker (path-finder) by clicking OK and then viewing (View & Edit) the resulting Pitch file. It can be seen that in addition to the chosen trajectory there were still quite significant candidates with a frequency below.
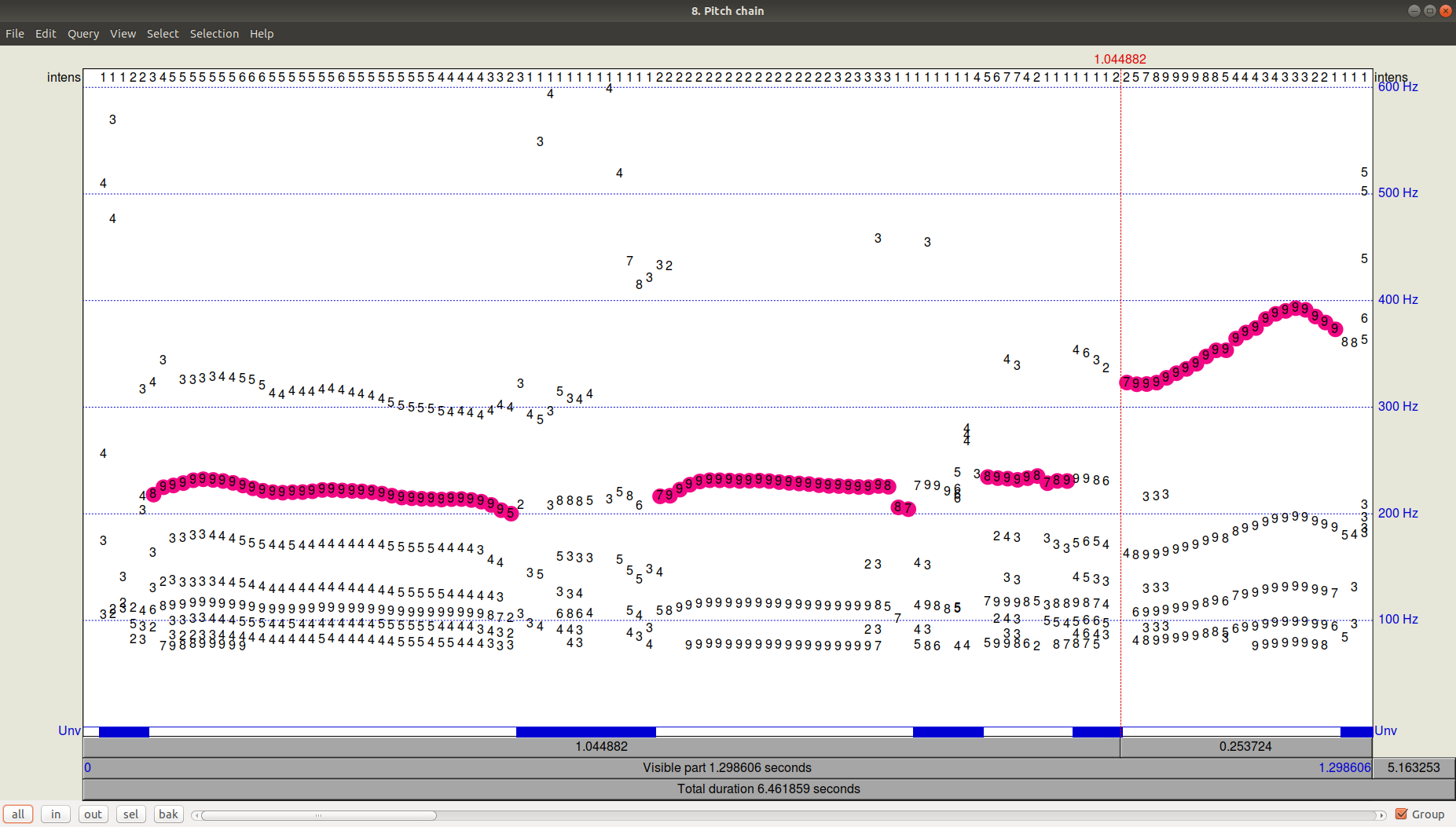
Figure 3. PitchPath for the first 1.3 seconds of audio recording.
And what about Python?
Let's take two libraries offering pitch-tracking - aubio , in which the default algorithm is YIN, and the AMFM_decompsition library , in which there is a realization of the YAAPT algorithm. In a separate file (file PraatPitch.txt) insert the F0 values from Praat (this can be done manually: select the audio file, click View & Edit, select the entire file and select Pitch-Pitch listing in the top menu).
Now compare the results for all three algorithms (YIN, YAAPT, Praat).
Lot of code
import amfm_decompy.basic_tools as basic
import amfm_decompy.pYAAPT as pYAAPT
import matplotlib.pyplot as plt
import numpy as np
import sys
from aubio import source, pitch
# load audio
signal = basic.SignalObj('/home/eva/Documents/papers/habr/media/audio.wav')
filename = '/home/eva/Documents/papers/habr/media/audio.wav'# YAAPT pitches
pitchY = pYAAPT.yaapt(signal, frame_length=40, tda_frame_length=40, f0_min=75, f0_max=600)
# YIN pitches
downsample = 1
samplerate = 0
win_s = 1764 // downsample # fft size
hop_s = 441 // downsample # hop size
s = source(filename, samplerate, hop_s)
samplerate = s.samplerate
tolerance = 0.8
pitch_o = pitch("yin", win_s, hop_s, samplerate)
pitch_o.set_unit("midi")
pitch_o.set_tolerance(tolerance)
pitchesYIN = []
confidences = []
total_frames = 0whileTrue:
samples, read = s()
pitch = pitch_o(samples)[0]
pitch = int(round(pitch))
confidence = pitch_o.get_confidence()
pitchesYIN += [pitch]
confidences += [confidence]
total_frames += read
if read < hop_s:
break# load PRAAT pitches
praat = np.genfromtxt('/home/eva/Documents/papers/habr/PraatPitch.txt', filling_values=0)
praat = praat[:,1]
# plot
fig, (ax1,ax2,ax3) = plt.subplots(3, 1, sharex=True, sharey=True, figsize=(12, 8))
ax1.plot(np.asarray(pitchesYIN), label='YIN', color='green')
ax1.legend(loc="upper right")
ax2.plot(pitchY.samp_values, label='YAAPT', color='blue')
ax2.legend(loc="upper right")
ax3.plot(praat, label='Praat', color='red')
ax3.legend(loc="upper right")
plt.show()

Figure 4. Comparison of the work of the algorithms YIN, YAAPT and Praat.
We see that, with the default parameters, YIN is quite distracting, getting a very flat trajectory with understated Praat values and completely losing transitions between a male and a female voice, as well as between emotional and non-emotional speech.
YAAPT stabbed a very high tone with emotional female speech, but in general, clearly managed better. Due to its specific features, YAAPT works better - it is impossible to answer right away, of course, but it can be assumed that the role is played by receiving candidates from three sources and a more thorough calculation of their weight than in YIN.
Conclusion
Since the question of determining the frequency of the fundamental tone (F0) in one form or another is confronting almost everyone who works with sound, there are many ways to solve it. The question of the required accuracy and the specifics of the audio material in each particular case determine how carefully it is necessary to select the parameters, or otherwise you can restrict yourself to a basic solution like YAAPT. Taking Praat as a benchmark for speech processing (yet a huge number of researchers use it), we can conclude that YAAPT is, in the first approximation, more reliable and accurate than YIN, although our example turned out to be more complicated for it.
Author: Eva Kazimirova , Researcher, Neurodata Lab, Speech Processing Specialist.
Offtop: Do you like this article? In fact, we have a lot of similar interesting tasks on ML, mathematics and programming, and we need brains. Are you interested in this? Come to us! E-mail: hr@neurodatalab.com
Links
- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Quantitative acoustic measurements for characterization of speech and voice disorders in early untreated Parkinson’s disease. The Journal of the Acoustical Society of America, vol. 129, issue 1 (2011), pp. 350-367. Access
- Farrús, M., Hernando, J., Ejarque, P. Jitter and Shimmer Measurements for Speaker Recognition. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, vol. 2 (2007), pp. 1153-1156. Access
- Zahorian, S., Hu, HA. Spectral/temporal method for robust fundamental frequency tracking. The Journal of the Acoustical Society of America, vol. 123, issue 6 (2008), pp. 4559-4571. Access
- De Cheveigné, A., Kawahara, H. YIN, a fundamental frequency estimator for speech and music. The Journal of the Acoustical Society of America, vol. 111, issue 4 (2002), pp. 1917-1930. Access