A Simple Huffman Text String Encoding Example
- Transfer
You've probably heard of David Huffman and his popular compression algorithm. If not, I suggest you search the Internet yourself - in this article I will not pester you with the lessons of history or mathematics. I will try to show you in practice how to apply this algorithm to a text string. Our application will simply generate code values for characters from the entered string and set from - it will recreate the original string from the presented code.
The idea of Huffman coding is based on using the frequency of the use of characters in a string. The most frequently encountered character should be given the shortest code value possible, and the least frequently encountered character should be given as long as possible. Due to the fact that during archiving the most frequently occurring characters should take up less space than before, and the least frequently encountered characters can take up more space - since there are few of them, this will not greatly affect the result.
For our example, I decided to make the character 8-bit, i.e. type char. With the same success, it was possible to choose a length of sixteen, ten or twenty bits. The character length should be selected depending on the expected input data. For example, to encode video files, I would choose a character of the same size as the pixel. Keep in mind that increasing or decreasing the length of a character affects the code length for each character - after all, the longer the length, the more characters of this length can exist: there are much fewer ways to write ones and zeros to eight bits than to sixteen. Therefore, the length of the symbol must be adjusted depending on the task.
Huffman algorithm actively uses binary trees and queues with priority, so if you are not familiar with them, you will first have to fill in the knowledge gaps.
Let us have the line “beep boop beer!”, Which takes 15 * 8 = 120 bits in memory. After Huffman encoding, this size can be reduced to 40 bits. If you find fault with the details, we will display on the screen a string consisting of 40 elements of type char (zeros and ones), and so that it occupies exactly 40 bits in memory, this string must be converted to bits using binary arithmetic operations, which we will not here consider in detail.
So, consider the line “beep boop beer!”. To construct code values for all elements depending on their frequency, you need to build a binary tree in which each sheet contains a character from a given string. We will build the tree from leaves to the root, so that the elements with a lower frequency are farther from the root, and the more frequent ones are closer to it. You will soon find out why.
To build such a tree, we will use the priority queue, but slightly modified - invert the priorities so that the element with the lowest priority is the most important. It turns out that the queue will first return the elements with the lowest frequency. This modification will help us build a tree starting with leaves.
First, let's calculate the frequency of each character:
After that, we will create binary tree elements for each symbol and represent them as a priority queue, for which we will use the frequency.
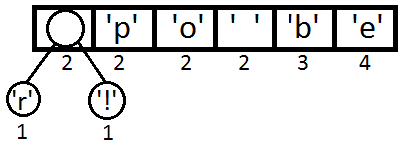
Now take the first two elements from the queue and create a third that will be their parent. We place this new element in a queue with a priority equal to the sum of the priorities of its two descendants. In other words, equal to the sum of their frequencies.
Next, we will repeat steps similar to the previous one:
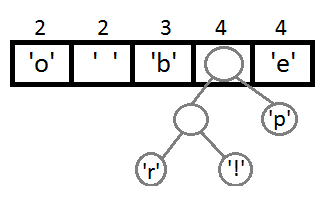
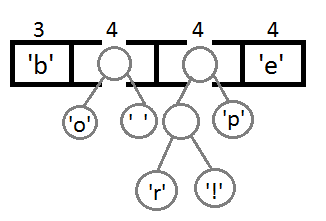
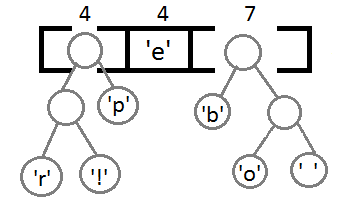
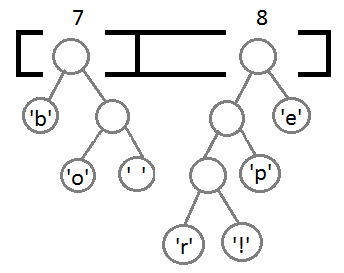
Now, after combining the last two elements using their new parent, we get the final binary tree: It
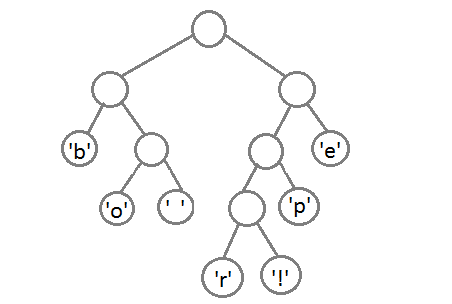
remains to assign each character its code. To do this, we start a walk in depth and each time, considering the right subtree, we will write it in code 1, and considering the left subtree - 0.
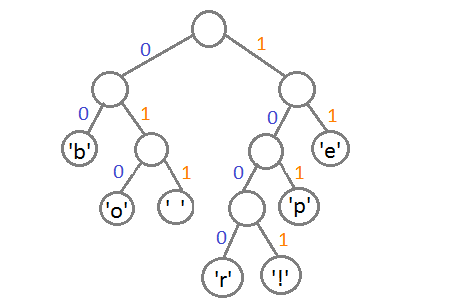
As a result, the correspondence of characters to code values is as follows:
Decoding a sequence of bits is very simple: you need to traverse the tree, discarding the left subtree if one is found and the right if it is 0. It is necessary to continue traversing until we meet a leaf, i.e. The desired value of the encoded character. For example, the encoded line "101 11 101 11" and our decoding tree corresponds to the line "pepe".
It is important to note here that no code value is a prefix of any other. In our example, 00 is the character code "b". This means that 000 can no longer be a code for any other character, because otherwise it would lead to a conflict in decoding. After all, if after going through 00 we came to sheet “b”, then by the code value of 000 we will no longer find any other character.
In practice, after generating the Huffman tree, you also need to construct the Huffman table. A table (in the form of a linked list or an array) will make the encoding procedure more efficient, because it is unreasonably time-consuming to search for a character in a tree and simultaneously write its code. Since we do not know for sure where this symbol is located, in the worst case, we will have to sort through the whole tree in search of it. Typically, a Huffman table is used for encoding, and a Huffman tree is used for decoding.
Input line: beep boop beer!
Binary input string: 0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 0001
Coded string: 0011 1110 1011 0001 0010 1010 1100 1111 1000 1001
It is easy to notice a significant difference between the ASCII encoding of a string and its appearance in the Huffman code.
It should be noted that the article only explains only the principle of the algorithm. For practical use, you have to add a Huffman tree to the beginning or end of the encoded sequence. The recipient of the message must know how to separate the tree from the content and how to restore it from the text view. A good way to do this is to traverse the tree in any preselected order, writing down 0 for each met item that is not a sheet, and 1 for each sheet. Following the unit, you can write the original character (in our case, type char, 8 bits in ASCII encoding). A tree written in this form can be placed at the beginning of the encoded sequence - then the recipient, having built the tree at the very beginning of the parsing, will already know how to decode the message recorded below and get the original from it.
You can read about a more advanced version of the algorithm in the article " Adaptive Huffman coding ".
PS (the interpreter)
Thank bobuk for being given the link to the original article in its linkbloge .
The idea of Huffman coding is based on using the frequency of the use of characters in a string. The most frequently encountered character should be given the shortest code value possible, and the least frequently encountered character should be given as long as possible. Due to the fact that during archiving the most frequently occurring characters should take up less space than before, and the least frequently encountered characters can take up more space - since there are few of them, this will not greatly affect the result.
For our example, I decided to make the character 8-bit, i.e. type char. With the same success, it was possible to choose a length of sixteen, ten or twenty bits. The character length should be selected depending on the expected input data. For example, to encode video files, I would choose a character of the same size as the pixel. Keep in mind that increasing or decreasing the length of a character affects the code length for each character - after all, the longer the length, the more characters of this length can exist: there are much fewer ways to write ones and zeros to eight bits than to sixteen. Therefore, the length of the symbol must be adjusted depending on the task.
Huffman algorithm actively uses binary trees and queues with priority, so if you are not familiar with them, you will first have to fill in the knowledge gaps.
Let us have the line “beep boop beer!”, Which takes 15 * 8 = 120 bits in memory. After Huffman encoding, this size can be reduced to 40 bits. If you find fault with the details, we will display on the screen a string consisting of 40 elements of type char (zeros and ones), and so that it occupies exactly 40 bits in memory, this string must be converted to bits using binary arithmetic operations, which we will not here consider in detail.
So, consider the line “beep boop beer!”. To construct code values for all elements depending on their frequency, you need to build a binary tree in which each sheet contains a character from a given string. We will build the tree from leaves to the root, so that the elements with a lower frequency are farther from the root, and the more frequent ones are closer to it. You will soon find out why.
To build such a tree, we will use the priority queue, but slightly modified - invert the priorities so that the element with the lowest priority is the most important. It turns out that the queue will first return the elements with the lowest frequency. This modification will help us build a tree starting with leaves.
First, let's calculate the frequency of each character:
| Symbol | Frequency |
|---|---|
| 'b' | 3 |
| 'e' | 4 |
| 'p' | 2 |
| '' | 2 |
| 'o' | 2 |
| 'r' | 1 |
| '!' | 1 |
After that, we will create binary tree elements for each symbol and represent them as a priority queue, for which we will use the frequency.
Now take the first two elements from the queue and create a third that will be their parent. We place this new element in a queue with a priority equal to the sum of the priorities of its two descendants. In other words, equal to the sum of their frequencies.
Next, we will repeat steps similar to the previous one:
Now, after combining the last two elements using their new parent, we get the final binary tree: It
remains to assign each character its code. To do this, we start a walk in depth and each time, considering the right subtree, we will write it in code 1, and considering the left subtree - 0.
As a result, the correspondence of characters to code values is as follows:
| Sivol | Code value |
|---|---|
| 'b' | 00 |
| 'e' | eleven |
| 'p' | 101 |
| '' | 011 |
| 'o' | 010 |
| 'r' | 1000 |
| '!' | 1001 |
Decoding a sequence of bits is very simple: you need to traverse the tree, discarding the left subtree if one is found and the right if it is 0. It is necessary to continue traversing until we meet a leaf, i.e. The desired value of the encoded character. For example, the encoded line "101 11 101 11" and our decoding tree corresponds to the line "pepe".
It is important to note here that no code value is a prefix of any other. In our example, 00 is the character code "b". This means that 000 can no longer be a code for any other character, because otherwise it would lead to a conflict in decoding. After all, if after going through 00 we came to sheet “b”, then by the code value of 000 we will no longer find any other character.
In practice, after generating the Huffman tree, you also need to construct the Huffman table. A table (in the form of a linked list or an array) will make the encoding procedure more efficient, because it is unreasonably time-consuming to search for a character in a tree and simultaneously write its code. Since we do not know for sure where this symbol is located, in the worst case, we will have to sort through the whole tree in search of it. Typically, a Huffman table is used for encoding, and a Huffman tree is used for decoding.
Input line: beep boop beer!
Binary input string: 0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 0001
Coded string: 0011 1110 1011 0001 0010 1010 1100 1111 1000 1001
It is easy to notice a significant difference between the ASCII encoding of a string and its appearance in the Huffman code.
It should be noted that the article only explains only the principle of the algorithm. For practical use, you have to add a Huffman tree to the beginning or end of the encoded sequence. The recipient of the message must know how to separate the tree from the content and how to restore it from the text view. A good way to do this is to traverse the tree in any preselected order, writing down 0 for each met item that is not a sheet, and 1 for each sheet. Following the unit, you can write the original character (in our case, type char, 8 bits in ASCII encoding). A tree written in this form can be placed at the beginning of the encoded sequence - then the recipient, having built the tree at the very beginning of the parsing, will already know how to decode the message recorded below and get the original from it.
You can read about a more advanced version of the algorithm in the article " Adaptive Huffman coding ".
PS (the interpreter)
Thank bobuk for being given the link to the original article in its linkbloge .