There will be no more free soup
Fundamental turn to parallelism in programming
Author: Herb Sutter
Translation: Alexander Kachanov
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
Link to the original article: www.gotw.ca/publications/concurrency-ddj.htm
Translator's note : This article provides an overview of current trends in the development of processors, as well as what exactly these trends mean for us programmers. The author believes that these trends are fundamental, and that every modern programmer will have to relearn something in order to keep up with life.
This article is quite old. She is already 7 years old, if you count from the moment of her first publication in early 2005. Remember this when you read the translation, as many of the things that have already become familiar to you were new to the author of the article in 2005 and were just appearing.
The biggest software development revolution has been knocking at your door since the OOP revolution, and its name is Parallelism.
This article was first published in the journal “Dr. Dobb's Journal, March 2005. A shorter version of this article was published in the C / C ++ Users Journal in February 2005 under the title “Concurrency Revolution.”
Update: The processor growth trend chart was updated in August 2009. New data has been added to it, which show that all the predictions of this article come true. The rest of the text of this article remained unchanged as it was published in December 2004.
Free soup will be gone soon. What will you do about this? What are you doing now about this?
The leading manufacturers of processors and architectures, from Intel and AMD to Sparc and PowerPC, for the most part have exhausted the traditional possibilities of increasing productivity. Instead of continuing to increase the frequency of processors and their linear bandwidth, they massively turn to hyper-threaded and multi-core architectures. Both of these architectures are already present in today's processors. In particular, modern PowerPC and Sparc IV processors are multi-core, and in 2005 Intel and AMD will join the current. By the way, the big topic of the In-Stat / MDR Fall Processor Forum, which took place in the fall of 2004, was just the topic of multi-core devices, since it was there that many companies presented their new and updated multi-core processors. It is no exaggeration to say that 2004 was a year of multicore.
So we are approaching a fundamental turning point in software development, at least a few years in advance, for applications designed for general-purpose desktop computers and for the lower segment of servers (which, by the way, in dollar terms make up a huge share of all programs sold now On the market). In this article, I will describe how hardware is changing, why these changes suddenly became important to us, how exactly the parallelization revolution will affect you, and how you will most likely write programs in the future.
Perhaps the free soup ended already a year or two ago. We just started to notice it.
You've probably heard such an interesting saying: “No matter how much Andy gives out, Bill will take everything” (“Andy giveth and Bill taketh away”)? (comment translator - This refers to Andy Grove - the head of Intel, and Bill Gates - the head of Microsoft). No matter how many processors increase their speed, programs will always figure out what to spend this speed on. Make the processor ten times faster, and the program will find ten times more work for it (or, in some cases, allow itself to perform the same work ten times less efficiently). Most applications have been running faster and faster for several decades, doing absolutely nothing for this, even without releasing new versions or fundamental changes to the code. Just manufacturers of processors (first of all) and manufacturers of memory and hard drives (second of all) each time created more and more new, ever faster computer systems. The processor clock speed is not the only criterion for evaluating its performance, and not even the most correct one, but nevertheless it says a lot: we saw how 500 MHz processors were replaced by processors with a clock frequency of 1 GHz, and after them - 2 GHz - new processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary. how to replace 500 MHz processors came processors with a clock frequency of 1 GHz, and behind them - 2 GHz processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary. how to replace 500 MHz processors came processors with a clock frequency of 1 GHz, and behind them - 2 GHz processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary.
Now we ask ourselves: When will this race end? Moore's Law predicts exponential growth. It is clear that such growth cannot continue forever, it will inevitably run into physical limits: after all, over the years the speed of light does not become faster. So, sooner or later, growth will slow down and even stop. (A small clarification: Yes, Moore's Law speaks mainly about the density of transistors, but we can say that exponential growth was also observed in such an area as the clock frequency. And in other areas, the growth was even greater, for example, the growth of storage capacities, but this topic of a separate article.)
If you are a software developer, most likely you have long been relaxed riding in the wake of increasing desktop performance. Does your program run slowly while performing some kind of operation? “Why worry?”, You say, “tomorrow even faster processors will be released, but in general programs work slowly not only because of a slow processor and slow memory (for example, because of slow I / O devices, because of calls to databases). ” The right train of thought?
Quite true. For yesterday. But absolutely wrong for the foreseeable future.
The good news is that processors will become more and more powerful. The bad news is that, at least in the near future, the growth in processor power will go in a direction that will not lead to automatic acceleration of the work of most existing programs.
Over the past 30 years, processor developers have been able to increase productivity in three main areas. The first two of them are related to the execution of program code:
An increase in clock speed means an increase in speed. If you increase the speed of the processor, this will more or less lead to the fact that it will execute the same code faster.
Optimizing program code execution means doing more work in one clock cycle. Today's processors are equipped with very powerful instructions, and they also perform various optimizations, from trivial to exotic, including pipelining code execution, branch predictions, executing several instructions in the same clock cycle, and even executing program instructions in a different order (instructions reordering). All these technologies were invented so that the code executes as best and / or as fast as possible in order to squeeze as much out of each clock cycle as possible, minimizing delays and performing more operations per cycle.
A small digression regarding the execution of instructions in a different order (instruction reordering) and memory models (memory models): I want to note that by the word “optimizations” I meant something really more. These “optimizations” can change the meaning of the program and lead to results that will contradict the programmer’s expectations. This is of great importance. Processor developers are not crazy, and in life they won’t offend flies, it would never occur to them to spoil your code ... in a normal situation. But over the past years, they have decided on aggressive optimizations for the sole purpose of squeezing even more out of each processor clock cycle. However, they are well aware that these aggressive optimizations endanger the semantics of your code. Well, are they doing this out of harm? Not at all. Their desire is a reaction to market pressure, which requires more and more fast processors. This pressure is so great that such an increase in the speed of your program jeopardizes its correctness and even its ability to work at all.
Let me give you two most striking examples: changing the order of data write operations (write reordering) and the order in which they are read (read reordering). Changing the order of data writing operations leads to such amazing consequences and confuses so many programmers that it is usually necessary to disable this function, since when it is turned on, it becomes too difficult to correctly judge how the written program will behave. The permutation of data reading operations can also lead to surprising results, but this function is usually left turned on, since programmers do not have particular difficulties here, and the performance requirements of operating systems and software products force programmers to make at least some compromise and reluctantly choose less of the "evils" of optimization.
Finally, increasing the size of the built-in cache means striving to access RAM as little as possible. Computer RAM is much slower than the processor, so it is best to place data as close to the processor as possible so as not to run after them in RAM. The closest thing is to store them on the same piece of silicon where the processor itself is located. The increase in cache sizes in recent years has been overwhelming. Today, one cannot surprise anyone with processors with built-in cache memory of the 2nd level (L2) of 2MB or more. (Of the three historical approaches to increasing processor performance, cache growth will be the only promising approach for the near future. I'll talk a little more about the importance of cache a little lower.)
Good. Why am I all this?
The main significance of this list is that all of the listed directions are in no way connected with parallelism. Breakthroughs in all of these areas will lead to acceleration of sequential (non-parallel, single-process) applications, as well as those applications that use parallelism. This conclusion is important because most of today's applications are single-threaded, I will talk about the reasons for this below.
Of course, compilers also had to keep up with the processors; from time to time you had to recompile your application, choosing a certain processor model as the minimum acceptable, in order to benefit from new instructions (for example, MMX, SSE), new functions and new features. But in general, even old programs always worked much faster on new processors than on old ones, even without any recompilation and use of the latest instructions from the latest processors.
How beautiful this world was. Unfortunately, this world no longer exists.
The usual increase in processor performance for us two years ago came across a wall. Most of us have already begun to notice this.
A similar graph can be created for other processors, but in this article I am going to use data on Intel processors. Figure 1 shows a graph showing when which Intel processor was introduced to the market, its clock frequency and the number of transistors. As you can see, the number of transistors continues to grow. But with the clock frequency we have problems.
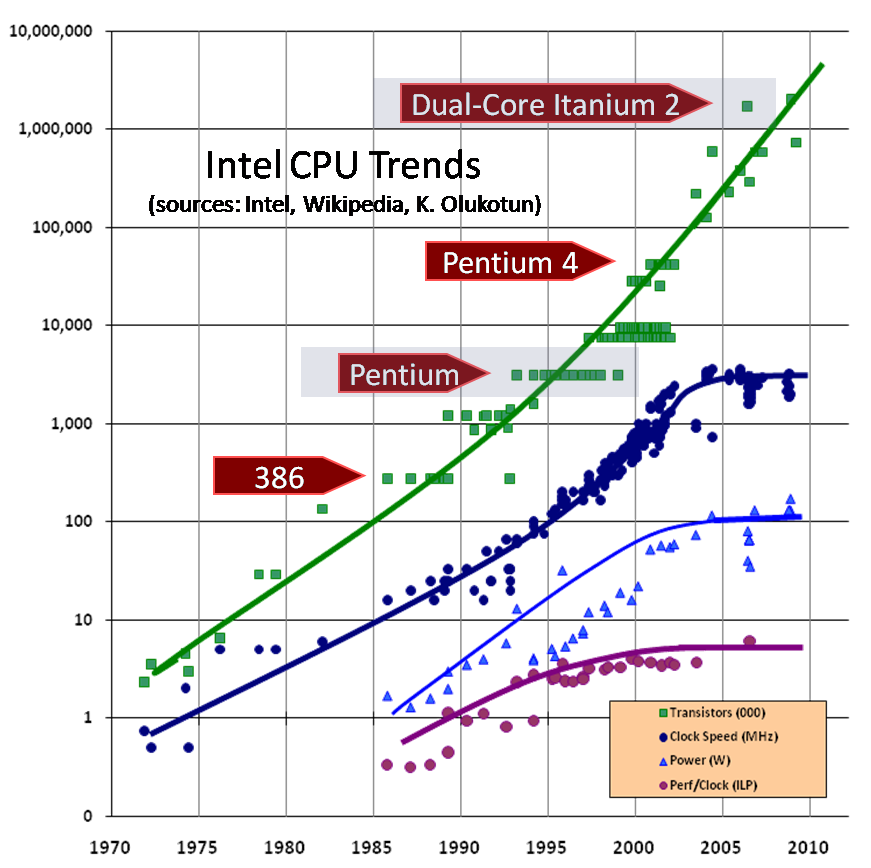
Please note that in the region of 2003, the clock graph sharply and strangely deviates from the usual trend of continuous growth. I drew lines between the points to make the trend more clear; instead of continuing to grow, the chart suddenly becomes horizontal. An increase in the clock frequency is given more and more, and there are not one, but many physical obstacles to the growth path, for example, heating processors (too much heat is generated and it is too difficult to dissipate it), energy consumption (too high) and stray current leakage.
A brief digression: look, what is the processor frequency on your computer? Maybe 10 GHz? Intel processors reached the 2 GHz level a long time ago (in August 2001), and if the growth trend of the clock frequency, which existed before 2003, continued, then now - at the beginning of 2005 - the first Pentium processors with a frequency of 10 GHz would have appeared. Look around, do you see them? Moreover, no one even has plans with such a clock speed, and we don’t even know when such plans will appear.
Well, what about the 4GHz processor? Already, there are processors with a frequency of 3.4 GHz, so 4 GHz is just around the corner? Alas, we cannot even reach 4 GHz. In mid-2004, you probably remember how Intel postponed the release of the 4GHz processor to 2005, and then in the fall of 2004 officially announced its complete rejection of these plans. At the time of writing this article, Intel plans to move forward a bit by launching a processor with a frequency of 3.73 GHz in early 2005 (in Fig. 1 it is the highest point in the frequency growth graph), but we can say that the race for hertz is over, at least by today's moment. In the future, Intel and most processor manufacturers will pursue growth in other ways: they all actively turned to multicore solutions.
Perhaps someday we will still see 4GHz processor in our desktop computers, but it will not be in 2005. Of course, Intel laboratories have prototypes that work at higher speeds, but these speeds are achieved by heroic efforts, for example, with the help of bulky cooling equipment. Do not expect such cooling equipment to ever appear in your office, and certainly not in an airplane where you would like to work on a laptop.
“There is no free soup (BSNB)” - R.A. Heinlein, “The Moon is a strict mistress”
Does this mean that Moore’s Law is no longer valid? The most interesting thing is that the answer is no. Of course, like any exponential progression, the Moore Law will one day cease to work, but apparently the Law is not in danger for the next few years. Despite the fact that the designers of processors can no longer increase the clock frequency, the number of transistors in their processors continues to grow at an explosive pace, and in the coming years, growth according to Moore's Law will continue.
The main difference from previous trends, for which this article was written, is that the performance gain of several future generations of processors will be achieved fundamentally in other ways. And most of the current applications on these new, more powerful processors will no longer automatically run faster, unless significant changes are made to their design.
In the near future, more precisely in the next few years, the performance gain in the new processors will be achieved in three main ways, only one of which has remained from the previous list. Namely:
Hyperthreading is the technology of executing two or more threads in parallel on the same processor. Hyper-threaded processors are already available on the market, and they do allow you to execute multiple instructions in parallel. However, despite the fact that the hyper-threaded processor has additional hardware, such as additional registers, to carry out this task, it still has only one cache, one computing unit for integer math, one unit for floating point operations, and generally one at a time what is available in any simple processor. It is believed that hyperthreading allows you to increase the performance of reasonably written multi-threaded programs by 5-15 percent, and the performance of well-written multithreaded programs under ideal conditions increases by as much as 40%. Not bad, but this is far from a doubling of productivity, and single-threaded programs here can not win anything.
Multicore (Multicore) is the technology of placing on the same chip two or more processors. Some processors, such as SPARC and PowerPC, are already available in multi-core versions. The first attempts by Intel and AMD, which should be implemented in 2005, differ from each other in the degree of integration of processors, but functionally they are very similar. The AMD processor will have several cores on a single chip, which will lead to a greater gain in performance, while the first Intel multi-core processor consists of only two conjugated Xeon processors on one large substrate. The gain from such a solution will be the same as from the presence of a dual-processor system (only cheaper, since the motherboard does not need two sockets for installing two chips and additional microcircuits for their coordination). Under ideal conditions, the speed of program execution will almost double, but only with fairly well-written multithreaded applications. Single-threaded applications will not receive any growth.
Finally, an increase in the on-die cache is expected, at least in the near future. Of all three trends, only this will lead to an increase in the productivity of most existing applications. Growing the size of the built-in cache for all applications is important simply because size means speed. Access to RAM is too expensive, and by and large I want to access RAM as little as possible. In the event of a cache miss, it will take 10-50 times longer to extract data from RAM than to extract it from the cache. This is still surprising to people, since it was commonly believed that RAM works very quickly. Yes, fast compared to drives and network, but the cache is even faster. If the entire amount of data that the application is to work with is cached, we are in chocolate, and if not, then in something else. That is why the growing size of the cache will save some of today's programs and breathe in them a little more life for several years to come without any significant alterations on their part. As they said during the time of the Great Depression: “There is little cache.” ("Cache is king")
(A brief digression: here is the story that happened to our compiler, as a demonstration of the statement “size means speed.” The 32-bit and 64-bit versions of our compiler are created from the same source code, just when compiling we indicate which process you need to create: 32-bit or 64-bit.It was expected that the 64-bit compiler should run faster on a 64-bit processor, if only because the 64-bit processor had a lot more registers, and there were also optimizing functions for faster code execution. Sun e is just fine. And what about the data? Switching to 64 bits did not change the size of most data structures in memory, except, of course, pointers, which became twice as large. It turned out that our compiler uses pointers much more often than some or another application. Since the size of the pointers has now become 8 bytes, instead of 4 bytes, the total data size that the compiler had to work with has increased. The increase in data volume degraded performance just as much as it improved due to the faster processor and the availability of additional registers. At the time of this writing, our 64-bit compiler is running at the same speed as its 32-bit counterpart, despite the fact that both compilers are assembled from the same source code, and a 64-bit processor is more powerful than 32-bit. Size means speed!) At the time of this writing, our 64-bit compiler is running at the same speed as its 32-bit counterpart, despite the fact that both compilers are assembled from the same source code, and a 64-bit processor is more powerful than 32-bit. Size means speed!) At the time of this writing, our 64-bit compiler is running at the same speed as its 32-bit counterpart, despite the fact that both compilers are assembled from the same source code, and a 64-bit processor is more powerful than 32-bit. Size means speed!)
Truly, the cache will rule the ball. Since neither hyperthreading nor multicore will increase the speed of most of today's programs.
So what do these changes in hardware mean for us programmers? You probably already understood what the answer will be, so let's discuss it and draw conclusions.
If a dual-core processor consists of two 3GHz cores, then we get the performance of a 6GHz processor. Right?
Not! If two threads are executed on two physically separate processors, this does not mean at all that the overall performance of the program doubles. Similarly, a multi-threaded program will not work twice as fast on dual-core processors. Yes, it will work faster than on a single-core processor, but the speed will not grow linearly.
Why not? Firstly, we have the costs of matching the contents of the caches (cache coherency) of the two processors (the consistent state of the caches and shared memory), as well as the costs of other interactions. Today, two- or four-processor machines do not outperform their single-processor counterparts in speed two or four times, even when performing multi-threaded applications. The problems remain essentially the same in those cases when, instead of several separate processors, we have several cores on the same chip.
Secondly, several cores are fully used only if they execute two different processes, or two different threads of the same process, which are written so that they are able to work independently of each other and never wait for each other.
(Confronting my previous statement, I can imagine a real situation when a single-threaded application for an ordinary user will run faster on a dual-core processor. This will not happen at all because the second core will be occupied with something useful. On the contrary, it will execute some kind of trojan or virus that has previously eaten up computing resources from a uniprocessor machine. I leave it to you to decide whether to purchase another processor in addition to the first one in order to turn viruses and viruses on it oyan.)
If your application is single-threaded, you use only one processor core. Of course, there will be some acceleration, since the operating system or background application will run on other kernels, but as a rule, operating systems do not load processors by 100%, so the neighboring core will mostly be idle. (Or, again, a trojan or virus will spin on it)
In the late 90s, we learned to work with objects. In programming, there has been a transition from structural programming to object-oriented programming, which has become the most significant revolution in programming over the past 20, or maybe even 30 years. There have been other revolutions, including the recent emergence of web services, but over the course of our careers we have not seen a revolution more fundamental and significant in consequences than the object revolution.
Up to this day.
Starting today, you will have to pay for the “soup”. Of course, you can get some performance boost for free, mainly due to the increase in cache size. But if you want your program to benefit from the exponential growth in power of new processors, it will have to become a correctly written parallelized (usually multi-threaded) application. It is easy to say, but difficult to do, because not all tasks can be easily parallelized, and also because writing parallel programs is very difficult.
I hear cries of indignation: "Concurrency? What news is this !? People have been writing parallel programs for a long time. ” Right. But this is only an insignificant share of programmers.
Remember that people have been involved in object-oriented programming since the end of the 60s, when the Simula language was released. At that time, OOP did not cause any revolution and did not dominate among programmers. Until the onset of the 90s. Why then? The revolution occurred mainly because there was a need for even more complex programs that solved even more complex problems and used more and more processor and memory resources. For economical, reliable, and predictable development of large programs, OOP's strengths — abstractions and modularity — have come in handy.
Similarly with concurrency. We know about it from time immemorial, when they wrote coroutines and monitors and other similar tricky utilities. And over the past ten years, more and more programmers began to create parallel (multi-process or multi-threaded) systems. But it was still too early to talk about revolution, about a turning point. Therefore, today most programs are single-threaded.
By the way, about the hype: how many times have they announced to us that we are "on the verge of another revolution in the field of software development." As a rule, those who said this simply advertised their new product. Do not believe them. New technologies are always interesting and even sometimes prove useful, but the largest programming revolutions produce those technologies that have been on the market for several years, quietly gaining strength, until one fine moment there is an explosive growth. This is inevitable: the revolution can only be based on sufficiently mature technology (which already has support from many companies and tools). Usually seven years pass before the new programming technology becomes reliable enough to be widely applied without stepping on a rake and glitches. As a result true programming revolutions, such as OOP, produce technologies that have been honed for years, if not decades. Even in Hollywood, every actor who became a superstar in one night, before that it turns out he had been playing a movie for several years.
Concurrency is the next great revolution in programming. There are different opinions of experts on whether it will be compared with the PLO revolution, but let us leave these disputes to pundits. For us engineers, it is important that parallelism is comparable to OOP in scale (which was expected), as well as in the complexity and difficulty of mastering this new technology.
There are two reasons why concurrency and especially multithreading are already used in the bulk of programs. Firstly, in order to separate the execution of independent operations; for example, in my database replication server, it was natural to put each replication session in its own stream, since they worked completely independently of each other (unless they worked on the same record on the same database). Secondly, in order for the programs to work faster, either due to its execution on several physical processors, or due to the alternation of the execution of one procedure at a time when the other is idle. In my database replication program, this principle was also used, so the program scaled well on multiprocessor machines.
However, concurrency has to be paid. Some obvious difficulties are not. For example, yes, blocking slows down the program, but if you use it wisely and correctly, you get more from accelerating the work of a multi-threaded program than you lose by using blocking. To do this, you need to parallelize the operations in your program and minimize the data exchange between them or completely abandon it.
Perhaps the second major difficulty on the path to parallelizing applications is the fact that not all programs can be parallelized. I will say more about this below.
And yet the main difficulty of parallelism lies in itself. Parallel programming model, i.e. the model of images that develops in the head of the programmer, and with the help of which he judges the behavior of his program, is much more complicated than the model of sequential code execution.
Anyone who undertakes the study of parallelism at some point believes that he understood it completely. Then, faced with inexplicable race conditions, he suddenly realizes that it’s too early to talk about full understanding. Further, as the programmer learns to work with parallel code, he will find that unusual race conditions can be avoided if the code is carefully tested, and moves on to the second level of imaginary knowledge and understanding. But during testing, those parallel programming errors that only occur on real multiprocessor systems, where threads are executed not just by switching context on a single processor, but where they are executed really simultaneously, causing a new class of errors, usually slip away. So a programmer who thought that now he knows for sure how parallel programs are written gets a new blow. I met a lot of teams whose applications worked perfectly during a long intensive testing and worked perfectly for clients, until one day one of the clients installed the program on a multiprocessor machine, and here and there inexplicable race conditions and data corruption began to crawl out .
So, in the context of modern processors, converting an application into a multi-threaded one for working on a multi-core machine is akin to trying to learn how to swim by jumping from the side to the deep part of the pool: you find yourself in an unforgiving truly parallel environment that will immediately show you all your programming errors. But, even if your team really knows how to write the correct parallel code, there are other tricks: for example, your code may be absolutely correct from the point of view of parallel programming, but it will not work faster than the single-threaded version. Usually this happens because the streams in the new version are not sufficiently independent of each other, or access some shared resource, as a result of which the program execution becomes sequential rather than parallel. The subtleties are becoming more and more.
When switching from structural programming to object-oriented programming, programmers had exactly the same difficulties (what is an object? What is a virtual function? Why do we need inheritance? And besides all these “what” and “why”, the most important thing is why the correct program constructs are they really correct?), which is still the case when switching from sequential to parallel programming (what is a “race”? what is a “deadlock”? what does it come from and how do I avoid it? what software consoles ruktsii make my parallel program consistent why we must make friends with the message queue (message queue) And besides all these "what" and "why", the most important thing -? why correct programming constructs are indeed correct)?
Most of today's programmers are not versed in concurrency. Similarly, 15 years ago, most programmers did not understand OOP. But parallel programming models can be learned, especially if we have a good understanding of the concepts of message and lock-based programming. After that, parallel programming will be no more difficult than OOP, and, I hope, it will become quite familiar. Just get ready that you and your team will have to spend some time retraining.
(I intentionally reduced parallel programming to the concepts of message passing and locking. There is a way to write parallel programs without locks (concurrent lock-free programming), and this method is supported at the language level best in Java 5 and at least in one of the compilers I know C ++. But parallel programming without locks is much more difficult to learn than programming with locks, for the most part it will be needed only by developers of system and library software, although each programmer will have to understand how Such systems and libraries work in order to benefit from them for their applications. Honestly, programming with locks is also not so easy and simple.)
OK. Let's get back to what all this means for us programmers.
1. The first main consequence that we have already covered is that applications should become parallel if you want to use the growing bandwidth of processors that have already begun to appear on the market and will correct the score on it in the next few years. For example, Intel claims that in the near future it will create a processor of 100 cores; a single-threaded application will be able to use only 1/100 of the power of this processor.
Yes, not all applications (or, more precisely, the important operations performed by the application) can be parallelized. Yes, for some tasks, such as compilation, concurrency is almost perfect. But for others, no. Usually, as a counter-example, one recalls the common phrase that if one woman takes 9 months to have a baby, this does not mean that 9 women will be able to give birth to a baby in 1 month. You probably often met this analogy. But have you noticed the deceitfulness of this analogy? When you are once again mentioned about it, ask a simple question: “is it possible to conclude from this analogy that the task of giving birth to a child cannot be parallelized by definition?” Usually, people think in response, and then quickly come to the conclusion that “yes, this task cannot be parallelized,” but this is not entirely true. Of course it cannot be parallelized if our goal is to give birth to one single child. But it is perfectly parallelizable if we set ourselves the goal of giving birth to as many children as possible (one child per month)! So, knowing the real goal can turn everything upside down. Remember this principle of purpose when deciding whether to change your program and how to do it.
2. Perhaps the less obvious consequence is that most likely applications will slow down more and more due to processors (CPU-bound). Of course, this will not happen with all applications, and those with which this may happen will not slow down literally tomorrow. Nevertheless, we probably reached the border when applications were slowed down due to I / O systems, or due to access to the network or databases. In these areas, speeds are getting higher and higher (have you heard about gigabit Wi-Fi?). And all the traditional methods of accelerating processors have exhausted themselves. Just think: we are now firmly stuck at 3 GHz. Therefore, single-threaded programs will not work faster, well, except by increasing the size of the processor cache (at least some good news). Other progress in this direction will not be as big as we used to be. For example, it is unlikely that circuit engineers will find a new way to fill the processor pipeline with work and prevent it from being idle. Here, all the obvious solutions have long been found and implemented. The market will constantly demand more functionality from programs; in addition, new applications will have to process more and more data. The more functionality we begin to introduce into programs, the sooner we will notice that programs lack processor power because they are not parallel. The market will constantly demand more functionality from programs; in addition, new applications will have to process more and more data. The more functionality we begin to introduce into programs, the sooner we will notice that programs lack processor power because they are not parallel. The market will constantly demand more functionality from programs; in addition, new applications will have to process more and more data. The more functionality we begin to introduce into programs, the sooner we will notice that programs lack processor power because they are not parallel.
And here you will have two options. First, remake your application in parallel, as mentioned above. Or, for the laziest, rewrite the code so that it becomes more efficient and less wasteful. Which leads us to the third conclusion:
3. The importance of an efficient and optimized code will only grow, not decrease. Languages that allow you to achieve a high level of code optimization will get a second life, and those languages that do not allow this will have to figure out how to survive in the new conditions of competition and become more effective and more optimizable. I believe that for a long time there will be a high demand for high-performance languages and systems.
4. And finally, programming languages and software systems will have to support concurrency well. The Java language, for example, supports concurrency from its very birth, although errors were made in this support, which then had to be fixed over several releases in order for multi-threaded Java programs to work correctly and efficiently. C ++ has long been used to write powerful multi-threaded applications. However, parallelism in this language is not reduced to standards (in all ISO-standards of the C ++ language, flows are not even mentioned, and this was done intentionally), so for its implementation you have to resort to various platform-dependent libraries. (In addition, concurrency support is far from complete, for example, static variables should only be initialized once, why the compiler is required to indicate initialization with locks, and many C ++ compilers do not). Finally, there are several concurrency standards in C ++, including pthreads and OpenMP, and some of them support even two types of concurrency: implicit and explicit. It’s great if such a compiler, working with your single-threaded code, manages to turn it into parallel, finding pieces in it that can be parallelized. However, this automated approach has its limits and does not always give a good result compared to code where parallelism is explicitly set by the programmer. The main secret of mastery is programming using locks, which is quite difficult to master. We urgently need a more advanced parallel programming model than the one what modern languages offer. I will speak more about this in another article.
If you haven’t done this yet, do it now: look carefully at the design of your application, determine which operations require or will require more processing power from the processor later, and decide how these operations can be parallelized. In addition, right now you and your team need to master parallel programming, all its secrets, styles and idioms.
Only a small part of the applications can be parallelized without any effort, most - alas, no. Even if you know exactly where your program squeezes the last juices from the processor, it may turn out that this operation will be very difficult to turn into a parallel one; the more reasons to start thinking about it now. Compilers with implicit parallelization can only partially help you, do not expect a miracle from them; they cannot turn a single-threaded application into a parallel one better than you do it yourself.
Due to the increase in cache size and even a few improvements in optimizing code execution, a free soup will be available for some time, but starting today it will contain only one vermicelli and carrot. All rich pieces of meat will be in the soup only for an additional fee - additional programmer efforts, additional code complexity, additional testing. It is reassuring that for most applications, these efforts will not be in vain, because they will make it possible to fully use the exponential increase in power of modern processors.
Author: Herb Sutter
Translation: Alexander Kachanov
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
Link to the original article: www.gotw.ca/publications/concurrency-ddj.htm
Translator's note : This article provides an overview of current trends in the development of processors, as well as what exactly these trends mean for us programmers. The author believes that these trends are fundamental, and that every modern programmer will have to relearn something in order to keep up with life.
This article is quite old. She is already 7 years old, if you count from the moment of her first publication in early 2005. Remember this when you read the translation, as many of the things that have already become familiar to you were new to the author of the article in 2005 and were just appearing.
The biggest software development revolution has been knocking at your door since the OOP revolution, and its name is Parallelism.
This article was first published in the journal “Dr. Dobb's Journal, March 2005. A shorter version of this article was published in the C / C ++ Users Journal in February 2005 under the title “Concurrency Revolution.”
Update: The processor growth trend chart was updated in August 2009. New data has been added to it, which show that all the predictions of this article come true. The rest of the text of this article remained unchanged as it was published in December 2004.
Free soup will be gone soon. What will you do about this? What are you doing now about this?
The leading manufacturers of processors and architectures, from Intel and AMD to Sparc and PowerPC, for the most part have exhausted the traditional possibilities of increasing productivity. Instead of continuing to increase the frequency of processors and their linear bandwidth, they massively turn to hyper-threaded and multi-core architectures. Both of these architectures are already present in today's processors. In particular, modern PowerPC and Sparc IV processors are multi-core, and in 2005 Intel and AMD will join the current. By the way, the big topic of the In-Stat / MDR Fall Processor Forum, which took place in the fall of 2004, was just the topic of multi-core devices, since it was there that many companies presented their new and updated multi-core processors. It is no exaggeration to say that 2004 was a year of multicore.
So we are approaching a fundamental turning point in software development, at least a few years in advance, for applications designed for general-purpose desktop computers and for the lower segment of servers (which, by the way, in dollar terms make up a huge share of all programs sold now On the market). In this article, I will describe how hardware is changing, why these changes suddenly became important to us, how exactly the parallelization revolution will affect you, and how you will most likely write programs in the future.
Perhaps the free soup ended already a year or two ago. We just started to notice it.
Free performance soup
You've probably heard such an interesting saying: “No matter how much Andy gives out, Bill will take everything” (“Andy giveth and Bill taketh away”)? (comment translator - This refers to Andy Grove - the head of Intel, and Bill Gates - the head of Microsoft). No matter how many processors increase their speed, programs will always figure out what to spend this speed on. Make the processor ten times faster, and the program will find ten times more work for it (or, in some cases, allow itself to perform the same work ten times less efficiently). Most applications have been running faster and faster for several decades, doing absolutely nothing for this, even without releasing new versions or fundamental changes to the code. Just manufacturers of processors (first of all) and manufacturers of memory and hard drives (second of all) each time created more and more new, ever faster computer systems. The processor clock speed is not the only criterion for evaluating its performance, and not even the most correct one, but nevertheless it says a lot: we saw how 500 MHz processors were replaced by processors with a clock frequency of 1 GHz, and after them - 2 GHz - new processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary. how to replace 500 MHz processors came processors with a clock frequency of 1 GHz, and behind them - 2 GHz processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary. how to replace 500 MHz processors came processors with a clock frequency of 1 GHz, and behind them - 2 GHz processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary.
Now we ask ourselves: When will this race end? Moore's Law predicts exponential growth. It is clear that such growth cannot continue forever, it will inevitably run into physical limits: after all, over the years the speed of light does not become faster. So, sooner or later, growth will slow down and even stop. (A small clarification: Yes, Moore's Law speaks mainly about the density of transistors, but we can say that exponential growth was also observed in such an area as the clock frequency. And in other areas, the growth was even greater, for example, the growth of storage capacities, but this topic of a separate article.)
If you are a software developer, most likely you have long been relaxed riding in the wake of increasing desktop performance. Does your program run slowly while performing some kind of operation? “Why worry?”, You say, “tomorrow even faster processors will be released, but in general programs work slowly not only because of a slow processor and slow memory (for example, because of slow I / O devices, because of calls to databases). ” The right train of thought?
Quite true. For yesterday. But absolutely wrong for the foreseeable future.
The good news is that processors will become more and more powerful. The bad news is that, at least in the near future, the growth in processor power will go in a direction that will not lead to automatic acceleration of the work of most existing programs.
Over the past 30 years, processor developers have been able to increase productivity in three main areas. The first two of them are related to the execution of program code:
- processor speed
- code execution optimization
- cache
An increase in clock speed means an increase in speed. If you increase the speed of the processor, this will more or less lead to the fact that it will execute the same code faster.
Optimizing program code execution means doing more work in one clock cycle. Today's processors are equipped with very powerful instructions, and they also perform various optimizations, from trivial to exotic, including pipelining code execution, branch predictions, executing several instructions in the same clock cycle, and even executing program instructions in a different order (instructions reordering). All these technologies were invented so that the code executes as best and / or as fast as possible in order to squeeze as much out of each clock cycle as possible, minimizing delays and performing more operations per cycle.
A small digression regarding the execution of instructions in a different order (instruction reordering) and memory models (memory models): I want to note that by the word “optimizations” I meant something really more. These “optimizations” can change the meaning of the program and lead to results that will contradict the programmer’s expectations. This is of great importance. Processor developers are not crazy, and in life they won’t offend flies, it would never occur to them to spoil your code ... in a normal situation. But over the past years, they have decided on aggressive optimizations for the sole purpose of squeezing even more out of each processor clock cycle. However, they are well aware that these aggressive optimizations endanger the semantics of your code. Well, are they doing this out of harm? Not at all. Their desire is a reaction to market pressure, which requires more and more fast processors. This pressure is so great that such an increase in the speed of your program jeopardizes its correctness and even its ability to work at all.
Let me give you two most striking examples: changing the order of data write operations (write reordering) and the order in which they are read (read reordering). Changing the order of data writing operations leads to such amazing consequences and confuses so many programmers that it is usually necessary to disable this function, since when it is turned on, it becomes too difficult to correctly judge how the written program will behave. The permutation of data reading operations can also lead to surprising results, but this function is usually left turned on, since programmers do not have particular difficulties here, and the performance requirements of operating systems and software products force programmers to make at least some compromise and reluctantly choose less of the "evils" of optimization.
Finally, increasing the size of the built-in cache means striving to access RAM as little as possible. Computer RAM is much slower than the processor, so it is best to place data as close to the processor as possible so as not to run after them in RAM. The closest thing is to store them on the same piece of silicon where the processor itself is located. The increase in cache sizes in recent years has been overwhelming. Today, one cannot surprise anyone with processors with built-in cache memory of the 2nd level (L2) of 2MB or more. (Of the three historical approaches to increasing processor performance, cache growth will be the only promising approach for the near future. I'll talk a little more about the importance of cache a little lower.)
Good. Why am I all this?
The main significance of this list is that all of the listed directions are in no way connected with parallelism. Breakthroughs in all of these areas will lead to acceleration of sequential (non-parallel, single-process) applications, as well as those applications that use parallelism. This conclusion is important because most of today's applications are single-threaded, I will talk about the reasons for this below.
Of course, compilers also had to keep up with the processors; from time to time you had to recompile your application, choosing a certain processor model as the minimum acceptable, in order to benefit from new instructions (for example, MMX, SSE), new functions and new features. But in general, even old programs always worked much faster on new processors than on old ones, even without any recompilation and use of the latest instructions from the latest processors.
How beautiful this world was. Unfortunately, this world no longer exists.
Obstacles, or why we do not see 10 GHz processors
The usual increase in processor performance for us two years ago came across a wall. Most of us have already begun to notice this.
A similar graph can be created for other processors, but in this article I am going to use data on Intel processors. Figure 1 shows a graph showing when which Intel processor was introduced to the market, its clock frequency and the number of transistors. As you can see, the number of transistors continues to grow. But with the clock frequency we have problems.
Please note that in the region of 2003, the clock graph sharply and strangely deviates from the usual trend of continuous growth. I drew lines between the points to make the trend more clear; instead of continuing to grow, the chart suddenly becomes horizontal. An increase in the clock frequency is given more and more, and there are not one, but many physical obstacles to the growth path, for example, heating processors (too much heat is generated and it is too difficult to dissipate it), energy consumption (too high) and stray current leakage.
A brief digression: look, what is the processor frequency on your computer? Maybe 10 GHz? Intel processors reached the 2 GHz level a long time ago (in August 2001), and if the growth trend of the clock frequency, which existed before 2003, continued, then now - at the beginning of 2005 - the first Pentium processors with a frequency of 10 GHz would have appeared. Look around, do you see them? Moreover, no one even has plans with such a clock speed, and we don’t even know when such plans will appear.
Well, what about the 4GHz processor? Already, there are processors with a frequency of 3.4 GHz, so 4 GHz is just around the corner? Alas, we cannot even reach 4 GHz. In mid-2004, you probably remember how Intel postponed the release of the 4GHz processor to 2005, and then in the fall of 2004 officially announced its complete rejection of these plans. At the time of writing this article, Intel plans to move forward a bit by launching a processor with a frequency of 3.73 GHz in early 2005 (in Fig. 1 it is the highest point in the frequency growth graph), but we can say that the race for hertz is over, at least by today's moment. In the future, Intel and most processor manufacturers will pursue growth in other ways: they all actively turned to multicore solutions.
Perhaps someday we will still see 4GHz processor in our desktop computers, but it will not be in 2005. Of course, Intel laboratories have prototypes that work at higher speeds, but these speeds are achieved by heroic efforts, for example, with the help of bulky cooling equipment. Do not expect such cooling equipment to ever appear in your office, and certainly not in an airplane where you would like to work on a laptop.
BSNB: Moore's Law and the next generation of processors
“There is no free soup (BSNB)” - R.A. Heinlein, “The Moon is a strict mistress”
Does this mean that Moore’s Law is no longer valid? The most interesting thing is that the answer is no. Of course, like any exponential progression, the Moore Law will one day cease to work, but apparently the Law is not in danger for the next few years. Despite the fact that the designers of processors can no longer increase the clock frequency, the number of transistors in their processors continues to grow at an explosive pace, and in the coming years, growth according to Moore's Law will continue.
The main difference from previous trends, for which this article was written, is that the performance gain of several future generations of processors will be achieved fundamentally in other ways. And most of the current applications on these new, more powerful processors will no longer automatically run faster, unless significant changes are made to their design.
In the near future, more precisely in the next few years, the performance gain in the new processors will be achieved in three main ways, only one of which has remained from the previous list. Namely:
- hyperthreading
- multicore
- cache
Hyperthreading is the technology of executing two or more threads in parallel on the same processor. Hyper-threaded processors are already available on the market, and they do allow you to execute multiple instructions in parallel. However, despite the fact that the hyper-threaded processor has additional hardware, such as additional registers, to carry out this task, it still has only one cache, one computing unit for integer math, one unit for floating point operations, and generally one at a time what is available in any simple processor. It is believed that hyperthreading allows you to increase the performance of reasonably written multi-threaded programs by 5-15 percent, and the performance of well-written multithreaded programs under ideal conditions increases by as much as 40%. Not bad, but this is far from a doubling of productivity, and single-threaded programs here can not win anything.
Multicore (Multicore) is the technology of placing on the same chip two or more processors. Some processors, such as SPARC and PowerPC, are already available in multi-core versions. The first attempts by Intel and AMD, which should be implemented in 2005, differ from each other in the degree of integration of processors, but functionally they are very similar. The AMD processor will have several cores on a single chip, which will lead to a greater gain in performance, while the first Intel multi-core processor consists of only two conjugated Xeon processors on one large substrate. The gain from such a solution will be the same as from the presence of a dual-processor system (only cheaper, since the motherboard does not need two sockets for installing two chips and additional microcircuits for their coordination). Under ideal conditions, the speed of program execution will almost double, but only with fairly well-written multithreaded applications. Single-threaded applications will not receive any growth.
Finally, an increase in the on-die cache is expected, at least in the near future. Of all three trends, only this will lead to an increase in the productivity of most existing applications. Growing the size of the built-in cache for all applications is important simply because size means speed. Access to RAM is too expensive, and by and large I want to access RAM as little as possible. In the event of a cache miss, it will take 10-50 times longer to extract data from RAM than to extract it from the cache. This is still surprising to people, since it was commonly believed that RAM works very quickly. Yes, fast compared to drives and network, but the cache is even faster. If the entire amount of data that the application is to work with is cached, we are in chocolate, and if not, then in something else. That is why the growing size of the cache will save some of today's programs and breathe in them a little more life for several years to come without any significant alterations on their part. As they said during the time of the Great Depression: “There is little cache.” ("Cache is king")
(A brief digression: here is the story that happened to our compiler, as a demonstration of the statement “size means speed.” The 32-bit and 64-bit versions of our compiler are created from the same source code, just when compiling we indicate which process you need to create: 32-bit or 64-bit.It was expected that the 64-bit compiler should run faster on a 64-bit processor, if only because the 64-bit processor had a lot more registers, and there were also optimizing functions for faster code execution. Sun e is just fine. And what about the data? Switching to 64 bits did not change the size of most data structures in memory, except, of course, pointers, which became twice as large. It turned out that our compiler uses pointers much more often than some or another application. Since the size of the pointers has now become 8 bytes, instead of 4 bytes, the total data size that the compiler had to work with has increased. The increase in data volume degraded performance just as much as it improved due to the faster processor and the availability of additional registers. At the time of this writing, our 64-bit compiler is running at the same speed as its 32-bit counterpart, despite the fact that both compilers are assembled from the same source code, and a 64-bit processor is more powerful than 32-bit. Size means speed!) At the time of this writing, our 64-bit compiler is running at the same speed as its 32-bit counterpart, despite the fact that both compilers are assembled from the same source code, and a 64-bit processor is more powerful than 32-bit. Size means speed!) At the time of this writing, our 64-bit compiler is running at the same speed as its 32-bit counterpart, despite the fact that both compilers are assembled from the same source code, and a 64-bit processor is more powerful than 32-bit. Size means speed!)
Truly, the cache will rule the ball. Since neither hyperthreading nor multicore will increase the speed of most of today's programs.
So what do these changes in hardware mean for us programmers? You probably already understood what the answer will be, so let's discuss it and draw conclusions.
Myths and realities: 2 x 3GHz <6GHz
If a dual-core processor consists of two 3GHz cores, then we get the performance of a 6GHz processor. Right?
Not! If two threads are executed on two physically separate processors, this does not mean at all that the overall performance of the program doubles. Similarly, a multi-threaded program will not work twice as fast on dual-core processors. Yes, it will work faster than on a single-core processor, but the speed will not grow linearly.
Why not? Firstly, we have the costs of matching the contents of the caches (cache coherency) of the two processors (the consistent state of the caches and shared memory), as well as the costs of other interactions. Today, two- or four-processor machines do not outperform their single-processor counterparts in speed two or four times, even when performing multi-threaded applications. The problems remain essentially the same in those cases when, instead of several separate processors, we have several cores on the same chip.
Secondly, several cores are fully used only if they execute two different processes, or two different threads of the same process, which are written so that they are able to work independently of each other and never wait for each other.
(Confronting my previous statement, I can imagine a real situation when a single-threaded application for an ordinary user will run faster on a dual-core processor. This will not happen at all because the second core will be occupied with something useful. On the contrary, it will execute some kind of trojan or virus that has previously eaten up computing resources from a uniprocessor machine. I leave it to you to decide whether to purchase another processor in addition to the first one in order to turn viruses and viruses on it oyan.)
If your application is single-threaded, you use only one processor core. Of course, there will be some acceleration, since the operating system or background application will run on other kernels, but as a rule, operating systems do not load processors by 100%, so the neighboring core will mostly be idle. (Or, again, a trojan or virus will spin on it)
Importance for software: Another revolution
In the late 90s, we learned to work with objects. In programming, there has been a transition from structural programming to object-oriented programming, which has become the most significant revolution in programming over the past 20, or maybe even 30 years. There have been other revolutions, including the recent emergence of web services, but over the course of our careers we have not seen a revolution more fundamental and significant in consequences than the object revolution.
Up to this day.
Starting today, you will have to pay for the “soup”. Of course, you can get some performance boost for free, mainly due to the increase in cache size. But if you want your program to benefit from the exponential growth in power of new processors, it will have to become a correctly written parallelized (usually multi-threaded) application. It is easy to say, but difficult to do, because not all tasks can be easily parallelized, and also because writing parallel programs is very difficult.
I hear cries of indignation: "Concurrency? What news is this !? People have been writing parallel programs for a long time. ” Right. But this is only an insignificant share of programmers.
Remember that people have been involved in object-oriented programming since the end of the 60s, when the Simula language was released. At that time, OOP did not cause any revolution and did not dominate among programmers. Until the onset of the 90s. Why then? The revolution occurred mainly because there was a need for even more complex programs that solved even more complex problems and used more and more processor and memory resources. For economical, reliable, and predictable development of large programs, OOP's strengths — abstractions and modularity — have come in handy.
Similarly with concurrency. We know about it from time immemorial, when they wrote coroutines and monitors and other similar tricky utilities. And over the past ten years, more and more programmers began to create parallel (multi-process or multi-threaded) systems. But it was still too early to talk about revolution, about a turning point. Therefore, today most programs are single-threaded.
By the way, about the hype: how many times have they announced to us that we are "on the verge of another revolution in the field of software development." As a rule, those who said this simply advertised their new product. Do not believe them. New technologies are always interesting and even sometimes prove useful, but the largest programming revolutions produce those technologies that have been on the market for several years, quietly gaining strength, until one fine moment there is an explosive growth. This is inevitable: the revolution can only be based on sufficiently mature technology (which already has support from many companies and tools). Usually seven years pass before the new programming technology becomes reliable enough to be widely applied without stepping on a rake and glitches. As a result true programming revolutions, such as OOP, produce technologies that have been honed for years, if not decades. Even in Hollywood, every actor who became a superstar in one night, before that it turns out he had been playing a movie for several years.
Concurrency is the next great revolution in programming. There are different opinions of experts on whether it will be compared with the PLO revolution, but let us leave these disputes to pundits. For us engineers, it is important that parallelism is comparable to OOP in scale (which was expected), as well as in the complexity and difficulty of mastering this new technology.
The benefits of concurrency and how much it will cost us
There are two reasons why concurrency and especially multithreading are already used in the bulk of programs. Firstly, in order to separate the execution of independent operations; for example, in my database replication server, it was natural to put each replication session in its own stream, since they worked completely independently of each other (unless they worked on the same record on the same database). Secondly, in order for the programs to work faster, either due to its execution on several physical processors, or due to the alternation of the execution of one procedure at a time when the other is idle. In my database replication program, this principle was also used, so the program scaled well on multiprocessor machines.
However, concurrency has to be paid. Some obvious difficulties are not. For example, yes, blocking slows down the program, but if you use it wisely and correctly, you get more from accelerating the work of a multi-threaded program than you lose by using blocking. To do this, you need to parallelize the operations in your program and minimize the data exchange between them or completely abandon it.
Perhaps the second major difficulty on the path to parallelizing applications is the fact that not all programs can be parallelized. I will say more about this below.
And yet the main difficulty of parallelism lies in itself. Parallel programming model, i.e. the model of images that develops in the head of the programmer, and with the help of which he judges the behavior of his program, is much more complicated than the model of sequential code execution.
Anyone who undertakes the study of parallelism at some point believes that he understood it completely. Then, faced with inexplicable race conditions, he suddenly realizes that it’s too early to talk about full understanding. Further, as the programmer learns to work with parallel code, he will find that unusual race conditions can be avoided if the code is carefully tested, and moves on to the second level of imaginary knowledge and understanding. But during testing, those parallel programming errors that only occur on real multiprocessor systems, where threads are executed not just by switching context on a single processor, but where they are executed really simultaneously, causing a new class of errors, usually slip away. So a programmer who thought that now he knows for sure how parallel programs are written gets a new blow. I met a lot of teams whose applications worked perfectly during a long intensive testing and worked perfectly for clients, until one day one of the clients installed the program on a multiprocessor machine, and here and there inexplicable race conditions and data corruption began to crawl out .
So, in the context of modern processors, converting an application into a multi-threaded one for working on a multi-core machine is akin to trying to learn how to swim by jumping from the side to the deep part of the pool: you find yourself in an unforgiving truly parallel environment that will immediately show you all your programming errors. But, even if your team really knows how to write the correct parallel code, there are other tricks: for example, your code may be absolutely correct from the point of view of parallel programming, but it will not work faster than the single-threaded version. Usually this happens because the streams in the new version are not sufficiently independent of each other, or access some shared resource, as a result of which the program execution becomes sequential rather than parallel. The subtleties are becoming more and more.
When switching from structural programming to object-oriented programming, programmers had exactly the same difficulties (what is an object? What is a virtual function? Why do we need inheritance? And besides all these “what” and “why”, the most important thing is why the correct program constructs are they really correct?), which is still the case when switching from sequential to parallel programming (what is a “race”? what is a “deadlock”? what does it come from and how do I avoid it? what software consoles ruktsii make my parallel program consistent why we must make friends with the message queue (message queue) And besides all these "what" and "why", the most important thing -? why correct programming constructs are indeed correct)?
Most of today's programmers are not versed in concurrency. Similarly, 15 years ago, most programmers did not understand OOP. But parallel programming models can be learned, especially if we have a good understanding of the concepts of message and lock-based programming. After that, parallel programming will be no more difficult than OOP, and, I hope, it will become quite familiar. Just get ready that you and your team will have to spend some time retraining.
(I intentionally reduced parallel programming to the concepts of message passing and locking. There is a way to write parallel programs without locks (concurrent lock-free programming), and this method is supported at the language level best in Java 5 and at least in one of the compilers I know C ++. But parallel programming without locks is much more difficult to learn than programming with locks, for the most part it will be needed only by developers of system and library software, although each programmer will have to understand how Such systems and libraries work in order to benefit from them for their applications. Honestly, programming with locks is also not so easy and simple.)
What does all this mean for us?
OK. Let's get back to what all this means for us programmers.
1. The first main consequence that we have already covered is that applications should become parallel if you want to use the growing bandwidth of processors that have already begun to appear on the market and will correct the score on it in the next few years. For example, Intel claims that in the near future it will create a processor of 100 cores; a single-threaded application will be able to use only 1/100 of the power of this processor.
Yes, not all applications (or, more precisely, the important operations performed by the application) can be parallelized. Yes, for some tasks, such as compilation, concurrency is almost perfect. But for others, no. Usually, as a counter-example, one recalls the common phrase that if one woman takes 9 months to have a baby, this does not mean that 9 women will be able to give birth to a baby in 1 month. You probably often met this analogy. But have you noticed the deceitfulness of this analogy? When you are once again mentioned about it, ask a simple question: “is it possible to conclude from this analogy that the task of giving birth to a child cannot be parallelized by definition?” Usually, people think in response, and then quickly come to the conclusion that “yes, this task cannot be parallelized,” but this is not entirely true. Of course it cannot be parallelized if our goal is to give birth to one single child. But it is perfectly parallelizable if we set ourselves the goal of giving birth to as many children as possible (one child per month)! So, knowing the real goal can turn everything upside down. Remember this principle of purpose when deciding whether to change your program and how to do it.
2. Perhaps the less obvious consequence is that most likely applications will slow down more and more due to processors (CPU-bound). Of course, this will not happen with all applications, and those with which this may happen will not slow down literally tomorrow. Nevertheless, we probably reached the border when applications were slowed down due to I / O systems, or due to access to the network or databases. In these areas, speeds are getting higher and higher (have you heard about gigabit Wi-Fi?). And all the traditional methods of accelerating processors have exhausted themselves. Just think: we are now firmly stuck at 3 GHz. Therefore, single-threaded programs will not work faster, well, except by increasing the size of the processor cache (at least some good news). Other progress in this direction will not be as big as we used to be. For example, it is unlikely that circuit engineers will find a new way to fill the processor pipeline with work and prevent it from being idle. Here, all the obvious solutions have long been found and implemented. The market will constantly demand more functionality from programs; in addition, new applications will have to process more and more data. The more functionality we begin to introduce into programs, the sooner we will notice that programs lack processor power because they are not parallel. The market will constantly demand more functionality from programs; in addition, new applications will have to process more and more data. The more functionality we begin to introduce into programs, the sooner we will notice that programs lack processor power because they are not parallel. The market will constantly demand more functionality from programs; in addition, new applications will have to process more and more data. The more functionality we begin to introduce into programs, the sooner we will notice that programs lack processor power because they are not parallel.
And here you will have two options. First, remake your application in parallel, as mentioned above. Or, for the laziest, rewrite the code so that it becomes more efficient and less wasteful. Which leads us to the third conclusion:
3. The importance of an efficient and optimized code will only grow, not decrease. Languages that allow you to achieve a high level of code optimization will get a second life, and those languages that do not allow this will have to figure out how to survive in the new conditions of competition and become more effective and more optimizable. I believe that for a long time there will be a high demand for high-performance languages and systems.
4. And finally, programming languages and software systems will have to support concurrency well. The Java language, for example, supports concurrency from its very birth, although errors were made in this support, which then had to be fixed over several releases in order for multi-threaded Java programs to work correctly and efficiently. C ++ has long been used to write powerful multi-threaded applications. However, parallelism in this language is not reduced to standards (in all ISO-standards of the C ++ language, flows are not even mentioned, and this was done intentionally), so for its implementation you have to resort to various platform-dependent libraries. (In addition, concurrency support is far from complete, for example, static variables should only be initialized once, why the compiler is required to indicate initialization with locks, and many C ++ compilers do not). Finally, there are several concurrency standards in C ++, including pthreads and OpenMP, and some of them support even two types of concurrency: implicit and explicit. It’s great if such a compiler, working with your single-threaded code, manages to turn it into parallel, finding pieces in it that can be parallelized. However, this automated approach has its limits and does not always give a good result compared to code where parallelism is explicitly set by the programmer. The main secret of mastery is programming using locks, which is quite difficult to master. We urgently need a more advanced parallel programming model than the one what modern languages offer. I will speak more about this in another article.
Finally
If you haven’t done this yet, do it now: look carefully at the design of your application, determine which operations require or will require more processing power from the processor later, and decide how these operations can be parallelized. In addition, right now you and your team need to master parallel programming, all its secrets, styles and idioms.
Only a small part of the applications can be parallelized without any effort, most - alas, no. Even if you know exactly where your program squeezes the last juices from the processor, it may turn out that this operation will be very difficult to turn into a parallel one; the more reasons to start thinking about it now. Compilers with implicit parallelization can only partially help you, do not expect a miracle from them; they cannot turn a single-threaded application into a parallel one better than you do it yourself.
Due to the increase in cache size and even a few improvements in optimizing code execution, a free soup will be available for some time, but starting today it will contain only one vermicelli and carrot. All rich pieces of meat will be in the soup only for an additional fee - additional programmer efforts, additional code complexity, additional testing. It is reassuring that for most applications, these efforts will not be in vain, because they will make it possible to fully use the exponential increase in power of modern processors.