Chalk Cepstral Coefficients (MFCC) and Speech Recognition
I recently stumbled upon an interesting article published by rgen3 that describes the DTW speech recognition algorithm. In general terms, this is a comparison of speech sequences using dynamic programming.
Interested in the topic, I tried to put this algorithm into practice, but a number of rakes awaited me along the way. First of all, what exactly needs to be compared? Directly sound signals in the time domain are long and not very effective. Spectrograms are already faster, but not much more efficient. Finding the most rational view led me to the MFCCor Mel-frequency cepstral coefficients, which are often used as characteristics of speech signals. Here I will try to explain what they are.
The explanation will begin with the first word in the title. What is chalk? Wikipedia tells us that chalk is a unit of pitch based on the perception of this sound by our hearing organs. As you know, the frequency response of the human ear does not even remotely resemble a direct one, and amplitude is not quite an accurate measure of sound volume. Therefore, they introduced empirically selected units of volume, for example, background .
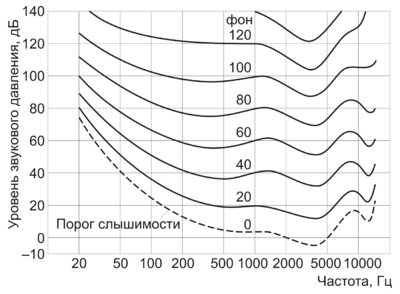
Similarly, the pitch of sound perceived by human hearing does not quite linearly depend on its frequency.
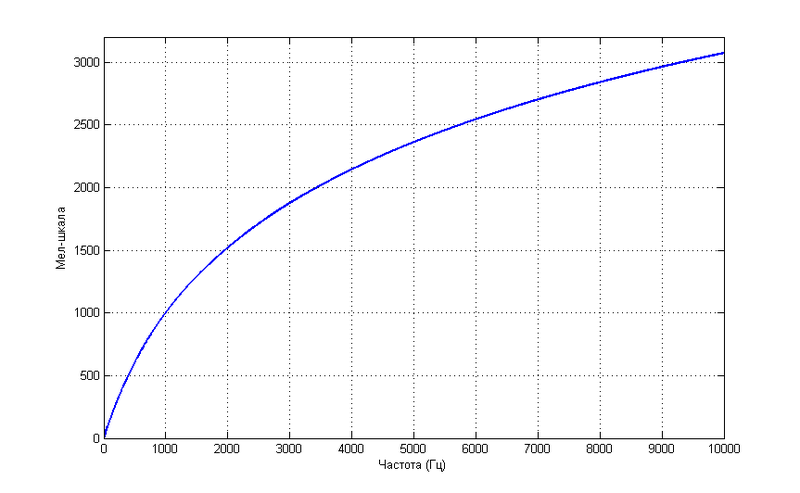
Such a dependence does not pretend to be more accurate, but is described by a simple formula.

Such units of measurement are often used in solving recognition problems, since they allow you to get closer to the mechanisms of human perception, which so far leads among well-known speech recognition systems.
You need to tell a little about the second word in the name - cepstrum .
In accordance with the theory of speech formation, speech is an acoustic wave that is emitted by a system of organs: lungs, bronchi and trachea, and then converted into the vocal tract. If we assume that the excitation sources and the form of the vocal tract are relatively independent, the human speech apparatus can be represented as a combination of tone and noise generators, as well as filters. Schematically, this can be represented as follows:

1. Pulse sequence generator (tones)
2. Random number generator (noise)
3. Digital filter coefficients (voice path parameters)
4. Non-stationary digital filter
The signal at the filter output (4) can be represented as a convolution

where s (t) is the initial form of the acoustic wave, and h (t) is the filter characteristic (depends on the parameters of the vocal tract)
In the frequency domain, it looks like this.

The product can be programmed to get the sum instead.

Now we need to convert this sum so that Get disjoint sets of characteristics of the source signal and filter. There are several options for this, for example, the inverse Fourier transform will give us this.

Also, depending on the goals, you can use the direct Fourier transform or the discrete cosine transform.
I hope I have clarified the basic concepts a bit. It remains to understand how to convert a speech signal into a set of MFCC coefficients.
As a test, we take a simple figure 1, here is its temporary representation
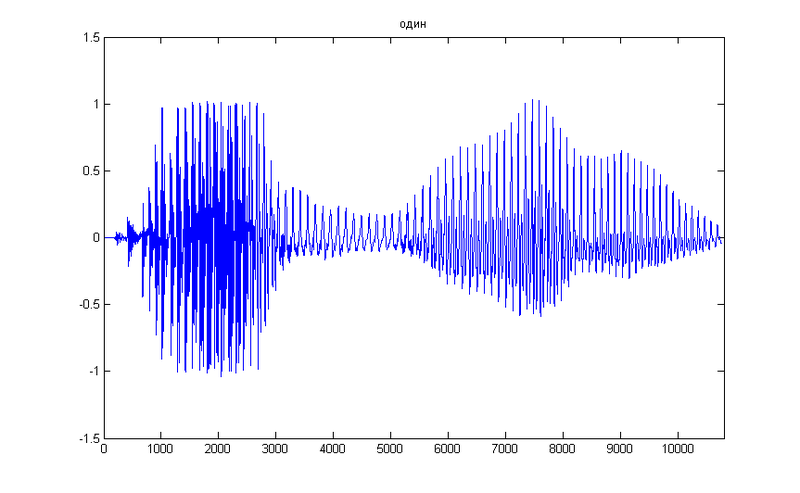
First of all, we need the spectrum of the original signal, which we obtain using the Fourier transform . For simplicity of the example, we will not split the signal into parts, so we take the spectrum along the entire time axis.

Now the most interesting part begins, we need to place the resulting spectrum on the chalk scale. To do this, we use windows evenly spaced on the chalk axis.

If you translate this graph into the frequency scale, you can see such a picture.

On this graph it is noticeable that the windows “gather” in the low-frequency region, providing a higher “resolution” where it is necessary for recognition.
By simply multiplying the vectors of the signal spectrum and the window function, we find the signal energy that falls into each of the analysis windows. We got some set of coefficients, but these are not the MFCCs we are looking for. So far, they could be called Mel-frequency spectral coefficients. We square them and logarithm. All that remains for us is to obtain from them a cepstral, or “spectrum spectrum.” To do this, we could once again apply the Fourier transform, but it is better to use the discrete cosine transform .
As a result, we get a sequence of approximately the following type:

Thus, we have a very small set of values that, when recognized, successfully replaces thousands of samples of the speech signal. The books write that for the word recognition problem it is possible to take the first 13 out of 24 calculated coefficients, but any suitable results in my case started with 16. In any case, this is a much smaller amount of data than a spectrogram or a temporal representation of a signal.
For a better result, you can split the source word into segments of short duration, and calculate the coefficients for each of them. Weighting window functions can also help. It all depends on the recognition algorithm to which you feed the result.
I don’t want to load the main part of the article with a large number of formulas, but suddenly they will be of interest to someone. Therefore, I will bring them here.
We write the initial speech signal in discrete form as
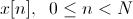
Applying the Fourier transform to it. We
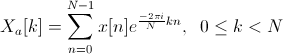
compose a filter comb using the window function.

For which the frequencies f [m] are obtained from the equality

B (b) —transformation of the frequency value into a chalk scale, respectively, We

calculate the energy for each window

Apply DCT

Get a set of MFCC
[1] Wikipedia
[2] Xuedong Huang, Alex Acero, Hsiao-Wuen Hon, Spoken Language Processing: A Guide to Theory, Algorithm, and System Development, Prentice Hall, 2001, ISBN: 0130226165
Interested in the topic, I tried to put this algorithm into practice, but a number of rakes awaited me along the way. First of all, what exactly needs to be compared? Directly sound signals in the time domain are long and not very effective. Spectrograms are already faster, but not much more efficient. Finding the most rational view led me to the MFCCor Mel-frequency cepstral coefficients, which are often used as characteristics of speech signals. Here I will try to explain what they are.
Basic concepts
The explanation will begin with the first word in the title. What is chalk? Wikipedia tells us that chalk is a unit of pitch based on the perception of this sound by our hearing organs. As you know, the frequency response of the human ear does not even remotely resemble a direct one, and amplitude is not quite an accurate measure of sound volume. Therefore, they introduced empirically selected units of volume, for example, background .
Similarly, the pitch of sound perceived by human hearing does not quite linearly depend on its frequency.
Such a dependence does not pretend to be more accurate, but is described by a simple formula.
Such units of measurement are often used in solving recognition problems, since they allow you to get closer to the mechanisms of human perception, which so far leads among well-known speech recognition systems.
You need to tell a little about the second word in the name - cepstrum .
In accordance with the theory of speech formation, speech is an acoustic wave that is emitted by a system of organs: lungs, bronchi and trachea, and then converted into the vocal tract. If we assume that the excitation sources and the form of the vocal tract are relatively independent, the human speech apparatus can be represented as a combination of tone and noise generators, as well as filters. Schematically, this can be represented as follows:
1. Pulse sequence generator (tones)
2. Random number generator (noise)
3. Digital filter coefficients (voice path parameters)
4. Non-stationary digital filter
The signal at the filter output (4) can be represented as a convolution
where s (t) is the initial form of the acoustic wave, and h (t) is the filter characteristic (depends on the parameters of the vocal tract)
In the frequency domain, it looks like this.
The product can be programmed to get the sum instead.
Now we need to convert this sum so that Get disjoint sets of characteristics of the source signal and filter. There are several options for this, for example, the inverse Fourier transform will give us this.
Also, depending on the goals, you can use the direct Fourier transform or the discrete cosine transform.
I hope I have clarified the basic concepts a bit. It remains to understand how to convert a speech signal into a set of MFCC coefficients.
Example
As a test, we take a simple figure 1, here is its temporary representation
First of all, we need the spectrum of the original signal, which we obtain using the Fourier transform . For simplicity of the example, we will not split the signal into parts, so we take the spectrum along the entire time axis.
Now the most interesting part begins, we need to place the resulting spectrum on the chalk scale. To do this, we use windows evenly spaced on the chalk axis.
If you translate this graph into the frequency scale, you can see such a picture.
On this graph it is noticeable that the windows “gather” in the low-frequency region, providing a higher “resolution” where it is necessary for recognition.
By simply multiplying the vectors of the signal spectrum and the window function, we find the signal energy that falls into each of the analysis windows. We got some set of coefficients, but these are not the MFCCs we are looking for. So far, they could be called Mel-frequency spectral coefficients. We square them and logarithm. All that remains for us is to obtain from them a cepstral, or “spectrum spectrum.” To do this, we could once again apply the Fourier transform, but it is better to use the discrete cosine transform .
As a result, we get a sequence of approximately the following type:
Conclusion
Thus, we have a very small set of values that, when recognized, successfully replaces thousands of samples of the speech signal. The books write that for the word recognition problem it is possible to take the first 13 out of 24 calculated coefficients, but any suitable results in my case started with 16. In any case, this is a much smaller amount of data than a spectrogram or a temporal representation of a signal.
For a better result, you can split the source word into segments of short duration, and calculate the coefficients for each of them. Weighting window functions can also help. It all depends on the recognition algorithm to which you feed the result.
Formulas
I don’t want to load the main part of the article with a large number of formulas, but suddenly they will be of interest to someone. Therefore, I will bring them here.
We write the initial speech signal in discrete form as
Applying the Fourier transform to it. We
compose a filter comb using the window function.
For which the frequencies f [m] are obtained from the equality
B (b) —transformation of the frequency value into a chalk scale, respectively, We
calculate the energy for each window
Apply DCT
Get a set of MFCC
Sources
[1] Wikipedia
[2] Xuedong Huang, Alex Acero, Hsiao-Wuen Hon, Spoken Language Processing: A Guide to Theory, Algorithm, and System Development, Prentice Hall, 2001, ISBN: 0130226165