Infrastructure Planning for Instant VM Recovery: Instant VM Recovery: Part 2
We continue the topic, which began to be considered in the first part . Today we will talk about network connections and target servers, present possible options and options for infrastructure planning for optimal recovery of Instant VM Recovery. So, welcome under cat.
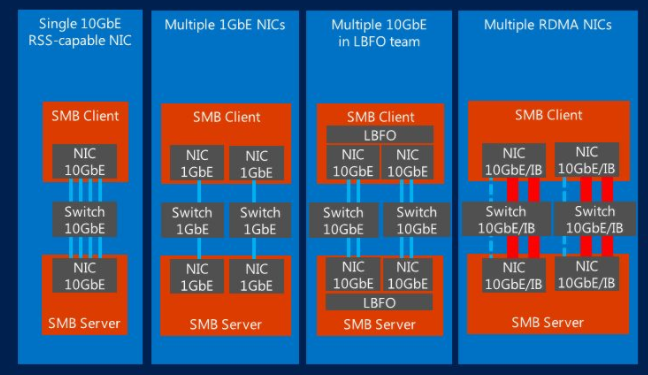
Of course, it’s good to have a channel with a bandwidth of 10 Gbit / s over which data is transferred during backup. However, the channel is more modest to restore from backup, but it is recommended to use NIC teaming with LACP or SMB Multichannel, or some other option with bandwidth aggregation. You can use, for example, LOM ports in the 4x1 Gbit / s version. This configuration is recommended for connecting “multiple source devices - 1 target backup device”, that is, when connecting “many to one”. (Similarly, parallel recovery from one backup storage to target devices — as a rule, these are the same source files from which backups were performed — is a one-to-many connection.)
For example, you can configure multiple backup jobs from multiple Hyper-V / LUNs hosts to save backups to the same target repository. If you have 10 such hosts with a total bandwidth of 4x1 Gbit / s, then with a 10 Gbit / s pipe on the target device, this is an adequate configuration.
In the case where backup storage is SMB share, multi-channeling works very well (it can be supplemented by SMB Direct if you have configured RDMA NICs). These features are now supported in many Hyper-V cluster deployments. However, the data mover component of the Veeam solution is able to use SMB Multichannel and SMB Direct (again, with configured RDMA-enabled NICs) only in the scenario where you use VMB File Share to backup VM shares. off-host proxy. These Veeam Data Movers work, respectively, on the off-host backup proxy and on the repository. Such a scenario is described in detail here .
Another important point: when using Windows NIC teaming in Switch independent modedata transfer is allowed from all participants, and receiving from only one. If you want optimal bandwidth in both directions for the same process, then LACP is not necessary. But in this version, you need to ensure that multiple restorations are performed on the same host.
As you can see, bandwidth aggregation carries with it a number of limitations and is not completely identical to having one good channel. In any case, you need to build on the planned use cases.
Summarizing: depending on your infrastructure, you can use Windows NIC teaming in LACP or Switch Independent mode / SMB Multichannel mode. The latter option is useful if you are working with SMB file share and want to use SMB Direct (do not forget about the features of work mentioned above).
High throughput and low latency are needed to provide the best performance during the Instant VM Recovery when mounting virtual disks, accessing data and copying them.
You can perform several recovery operations at the same time without stopping the backup jobs. That is, again, in the presence of a decent channel, the main role is played by the computational resource and storage system. If all this is correctly calculated for backup, then recovery will be effective.
Consider several options from which, quite possibly, you will choose the best for yourself.
Even if you have a high-performance storage system with read / write caching or level 1 is configured, then, as mentioned in the previous post , you need to be careful to prevent overflow. Otherwise, production VMs will be affected. And this can happen, for example, if you try to write large amounts of data to the storage system as quickly as possible - this happens during the migration of storage systems. In such operations, we try to avoid using storage tier 1. Similar considerations apply to the restoration of large VMs.
It can be recommended to recover on separate LUNs with different profiles. The recovered VMs can then be taken slowly to migrate to production CSVs. To ensure high availability, you can enable a cluster using Storage live migration (live migration migration functionality). Naturally, you need to focus on the performance of your storage array.
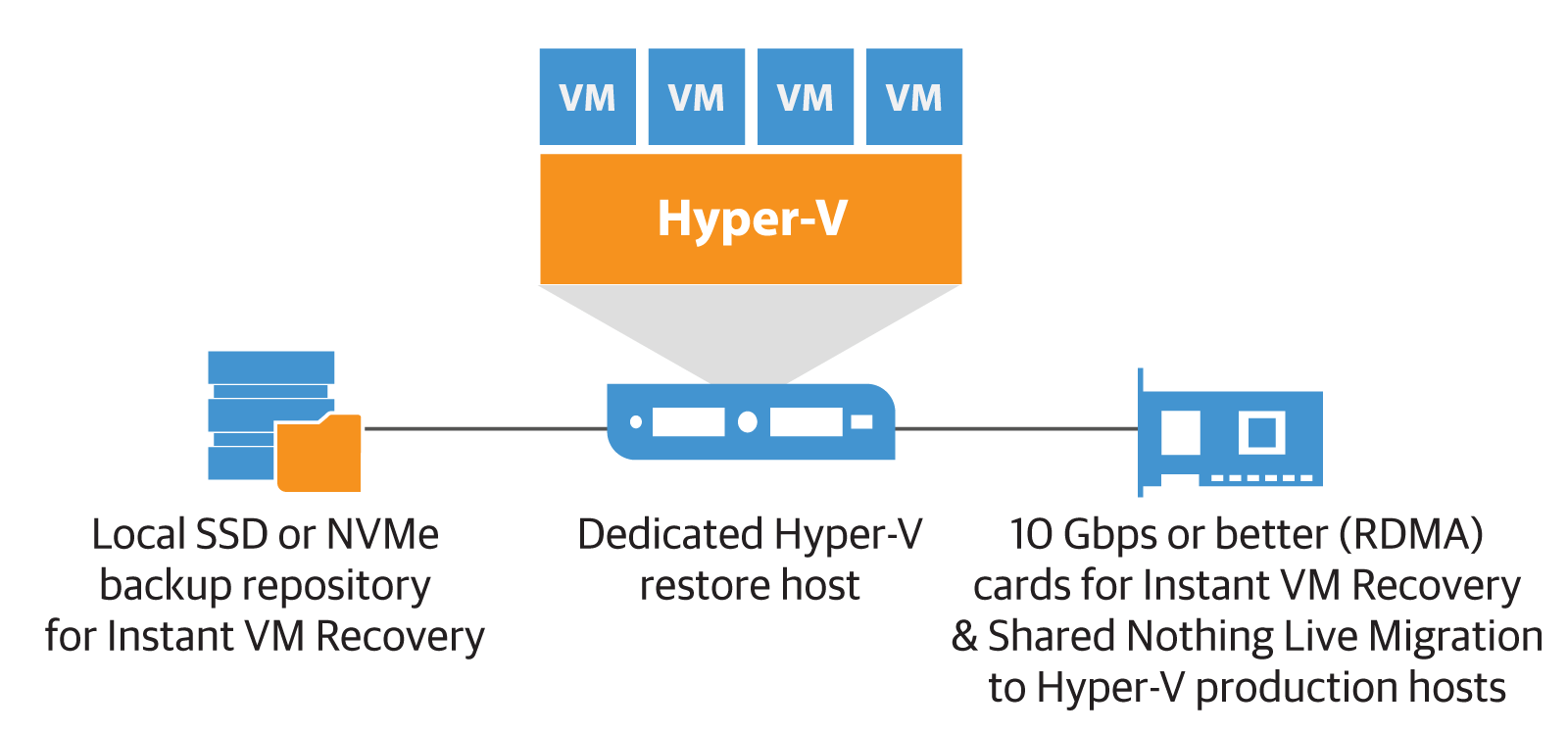
Another recovery scenario in production is quite effective: using a Hyper-V host from a local storage system on an SSD or NVMe. The size of disk space depends on how many VMs you want to recover over a certain period of time and how large these VMs are.
In theory, you hardly need to restore everyone and everything, so this configuration should be quite economical in cost. For example, you can use one SSD in each of the cluster nodes, or only a few, or only one at all. The more SSD / NVMe you use, the more budget they can be, while maintaining a fairly efficient load distribution among the hosts. At the final stage of the instant recovery procedure, virtual machines can be safely transferred to production CSVs, enabling the same functionality of Storage live migration.
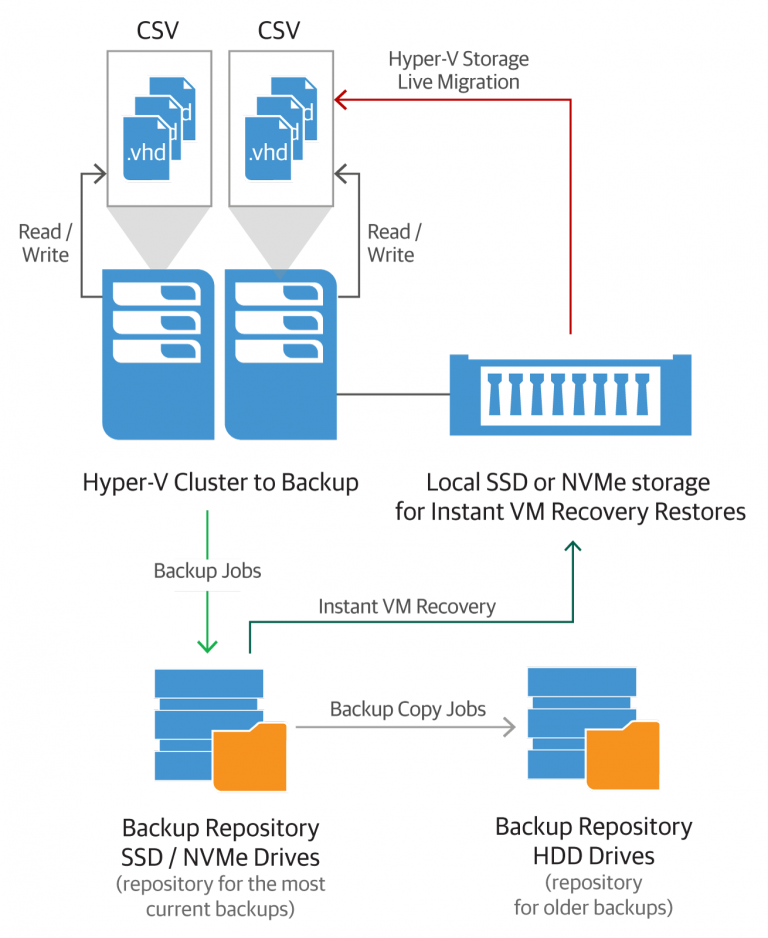
The diagram shows an infrastructure planning option. Of course, you can combine the above approaches at your discretion.
In this embodiment, we allocate one or more hosts specifically to support recovery. This avoids a possible shortage of resources and the impact on the work of production hosts in the cluster. You can use NVMe drives. We recommend that you pre-test the recovery options in this configuration in order to understand how much resources are available.
If you plan to increase their consumption, then for the final migration of the restored machines to production, you can use the so-called migration without sharing resources Shared Nothing Live Migration. (For this, you will need to specify additional security settings.) As for network resources, you can use, for example, SMB Multichannel and SMB Direct capabilities for migration to CSV / Live Migration / S2D Hyper-V.
Yes, storage live migration is not the fastest process, it is a minus. But there is a plus - your virtual machines are restored and continue to work during this process.
Of course, everyone chooses the preferred options depending on what is the bottleneck in the particular infrastructure (source server, target server, network resources). Moreover, it is quite possible that careful study will be required only for planning the restoration of the most critical VMs or for those consumers who pay for such a service.
In any case, the main goal will always be the fastest possible recovery.
After that, you can safely perform migration to the storage cluster, ensuring high availability and fault tolerance. And, of course, virtual machines should be protected in the form of backup / replication in case they need to be restored again at some point.
Pro network connections
Of course, it’s good to have a channel with a bandwidth of 10 Gbit / s over which data is transferred during backup. However, the channel is more modest to restore from backup, but it is recommended to use NIC teaming with LACP or SMB Multichannel, or some other option with bandwidth aggregation. You can use, for example, LOM ports in the 4x1 Gbit / s version. This configuration is recommended for connecting “multiple source devices - 1 target backup device”, that is, when connecting “many to one”. (Similarly, parallel recovery from one backup storage to target devices — as a rule, these are the same source files from which backups were performed — is a one-to-many connection.)
For example, you can configure multiple backup jobs from multiple Hyper-V / LUNs hosts to save backups to the same target repository. If you have 10 such hosts with a total bandwidth of 4x1 Gbit / s, then with a 10 Gbit / s pipe on the target device, this is an adequate configuration.
In the case where backup storage is SMB share, multi-channeling works very well (it can be supplemented by SMB Direct if you have configured RDMA NICs). These features are now supported in many Hyper-V cluster deployments. However, the data mover component of the Veeam solution is able to use SMB Multichannel and SMB Direct (again, with configured RDMA-enabled NICs) only in the scenario where you use VMB File Share to backup VM shares. off-host proxy. These Veeam Data Movers work, respectively, on the off-host backup proxy and on the repository. Such a scenario is described in detail here .
Another important point: when using Windows NIC teaming in Switch independent modedata transfer is allowed from all participants, and receiving from only one. If you want optimal bandwidth in both directions for the same process, then LACP is not necessary. But in this version, you need to ensure that multiple restorations are performed on the same host.
As you can see, bandwidth aggregation carries with it a number of limitations and is not completely identical to having one good channel. In any case, you need to build on the planned use cases.
Summarizing: depending on your infrastructure, you can use Windows NIC teaming in LACP or Switch Independent mode / SMB Multichannel mode. The latter option is useful if you are working with SMB file share and want to use SMB Direct (do not forget about the features of work mentioned above).
High throughput and low latency are needed to provide the best performance during the Instant VM Recovery when mounting virtual disks, accessing data and copying them.
You can perform several recovery operations at the same time without stopping the backup jobs. That is, again, in the presence of a decent channel, the main role is played by the computational resource and storage system. If all this is correctly calculated for backup, then recovery will be effective.
Recommendations for target devices
Consider several options from which, quite possibly, you will choose the best for yourself.
Option 1: Restore to Hyper-V hosts and directly to LUNs in the production infrastructure
Even if you have a high-performance storage system with read / write caching or level 1 is configured, then, as mentioned in the previous post , you need to be careful to prevent overflow. Otherwise, production VMs will be affected. And this can happen, for example, if you try to write large amounts of data to the storage system as quickly as possible - this happens during the migration of storage systems. In such operations, we try to avoid using storage tier 1. Similar considerations apply to the restoration of large VMs.
It can be recommended to recover on separate LUNs with different profiles. The recovered VMs can then be taken slowly to migrate to production CSVs. To ensure high availability, you can enable a cluster using Storage live migration (live migration migration functionality). Naturally, you need to focus on the performance of your storage array.
Option 2: Restore to Hyper-V hosts with local SSD / NMVe drives
Another recovery scenario in production is quite effective: using a Hyper-V host from a local storage system on an SSD or NVMe. The size of disk space depends on how many VMs you want to recover over a certain period of time and how large these VMs are.
In theory, you hardly need to restore everyone and everything, so this configuration should be quite economical in cost. For example, you can use one SSD in each of the cluster nodes, or only a few, or only one at all. The more SSD / NVMe you use, the more budget they can be, while maintaining a fairly efficient load distribution among the hosts. At the final stage of the instant recovery procedure, virtual machines can be safely transferred to production CSVs, enabling the same functionality of Storage live migration.
The diagram shows an infrastructure planning option. Of course, you can combine the above approaches at your discretion.
Option 3: Restore to dedicated Hyper-V hosts with local SSD / NVMe drives
In this embodiment, we allocate one or more hosts specifically to support recovery. This avoids a possible shortage of resources and the impact on the work of production hosts in the cluster. You can use NVMe drives. We recommend that you pre-test the recovery options in this configuration in order to understand how much resources are available.
If you plan to increase their consumption, then for the final migration of the restored machines to production, you can use the so-called migration without sharing resources Shared Nothing Live Migration. (For this, you will need to specify additional security settings.) As for network resources, you can use, for example, SMB Multichannel and SMB Direct capabilities for migration to CSV / Live Migration / S2D Hyper-V.
Yes, storage live migration is not the fastest process, it is a minus. But there is a plus - your virtual machines are restored and continue to work during this process.
Finally
Of course, everyone chooses the preferred options depending on what is the bottleneck in the particular infrastructure (source server, target server, network resources). Moreover, it is quite possible that careful study will be required only for planning the restoration of the most critical VMs or for those consumers who pay for such a service.
In any case, the main goal will always be the fastest possible recovery.
After that, you can safely perform migration to the storage cluster, ensuring high availability and fault tolerance. And, of course, virtual machines should be protected in the form of backup / replication in case they need to be restored again at some point.