What are hidden Markov models
- Transfer
In the field of signal recognition, it is often thought of as a product of multiplication, which act statistically. Thus, the goal of the analysis of such signals is to model the static properties of signal sources as accurately as possible. The basis of such a model is a simple study of the data and a possible degree of limitation of the deviations that arise. However, the model to be determined should not only repeat the production of certain data as accurately as possible, but also provide useful information about some significant units for signal segmentation.
Hidden Markov models are able to handle both of the above aspects of modeling. In a two-stage stochastic process, information for segmentation can be obtained from the internal states of the model, while the generation of the data signal itself occurs in the second stage.
This modeling technology gained great popularity as a result of successful application and further development in the field of automatic speech recognition. Studies of hidden Markov models have surpassed all competing approaches, and are the dominant processing paradigm. Their ability to describe processes or signals has been successfully studied for a long time. The reason for this, in particular, is that the technology for constructing artificial neural networks is rarely used for speech recognition and similar segmentation problems. However, there are a number of hybrid systems consisting of a combination of hidden Markov models and artificial neural networks that take advantage of both modeling methods (see Section 5.8.2).
Hidden Markov Models (SMM) describe a two-stage stochastic process. The first stage consists of a discrete stochastic process that is static, causative, and simple. The state space is considered as finite. Thus, the process probabilistically describes the state of transition to discreteness, the finite state space. This can be visualized as a finite state machine with differences between any pairs of states that are labeled with the probability of transition. The behavior of the process at a given time t depends only on the immediate state of the preceding element and can be characterized as follows:
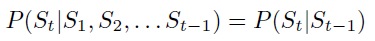
At the second stage, for each moment of time t, Ot is additionally generated by output or output. The distribution of associative probability depends only on the current state of St, and not on any previous states or output.
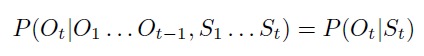
This sequence of output data is the only thing that can be observed in the behavior of the model. On the other hand, the sequence state adopted during data generation cannot be investigated. This is the so-called “stealth” from which the definition of hidden Markov models is derived. If you look at the model externally - that is, observe its behavior - quite often there are references to the sequence of output states Oi, O2 ... OT, as the reason for observing the sequence. Further, the individual elements of this sequence will be called the result of observation.
In the literature, patterns of recognizing the behavior of SMMs are always considered at a certain time interval T. To initialize the model at the beginning of this period, additional probabilities are used to describe the probability of the distribution of states at time t = 1. An equivalent criterion for the final state is usually absent. Thus, the actions of the model come to the final state as soon as an arbitrary state is reached at time T. Neither static nor declarative criteria are used to more accurately mark the end of the states.
Nevertheless, the hidden first-order Markov models, which are usually denoted by A, are completely described:
• by establishing a finite set of states {s | 1
• state of transition probabilities, matrix A
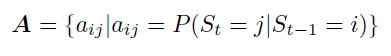
• state vector π
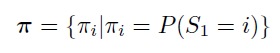
• state of a specific probability distribution
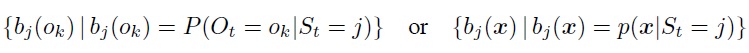 f for model derivation
f for model derivation
However, the distribution of the derivation must be distinguished depending on the type of output data during generation. In the simplest case, the output is generated from discrete probability distributions {O1, O2 ... OM}, and therefore are of symbolic type. The parameter bj (ok) represents the discrete probability of the distribution, which can be grouped into the matrix of probabilities of the output data:
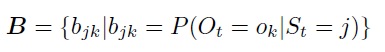
With this choice of simulation output, the so-called discrete SMMs are obtained.
If, when, a vector of xe IRn sequence values is observed, rather than the output of the distribution data described on the basis of the continuous probability distribution function: The
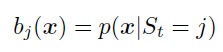
modern application of SMM for signal analysis tasks uses exclusively the so-called continuous SMM, although the need to model a continuous distribution significantly increases the complexity of the analysis.
Chapter 5 translation (1 paragraph) of
Gernot A. Fink “Markov Models for Pattern Recognition From Theory to Applications”
Hidden Markov models are able to handle both of the above aspects of modeling. In a two-stage stochastic process, information for segmentation can be obtained from the internal states of the model, while the generation of the data signal itself occurs in the second stage.
This modeling technology gained great popularity as a result of successful application and further development in the field of automatic speech recognition. Studies of hidden Markov models have surpassed all competing approaches, and are the dominant processing paradigm. Their ability to describe processes or signals has been successfully studied for a long time. The reason for this, in particular, is that the technology for constructing artificial neural networks is rarely used for speech recognition and similar segmentation problems. However, there are a number of hybrid systems consisting of a combination of hidden Markov models and artificial neural networks that take advantage of both modeling methods (see Section 5.8.2).
Definition
Hidden Markov Models (SMM) describe a two-stage stochastic process. The first stage consists of a discrete stochastic process that is static, causative, and simple. The state space is considered as finite. Thus, the process probabilistically describes the state of transition to discreteness, the finite state space. This can be visualized as a finite state machine with differences between any pairs of states that are labeled with the probability of transition. The behavior of the process at a given time t depends only on the immediate state of the preceding element and can be characterized as follows:
At the second stage, for each moment of time t, Ot is additionally generated by output or output. The distribution of associative probability depends only on the current state of St, and not on any previous states or output.
This sequence of output data is the only thing that can be observed in the behavior of the model. On the other hand, the sequence state adopted during data generation cannot be investigated. This is the so-called “stealth” from which the definition of hidden Markov models is derived. If you look at the model externally - that is, observe its behavior - quite often there are references to the sequence of output states Oi, O2 ... OT, as the reason for observing the sequence. Further, the individual elements of this sequence will be called the result of observation.
In the literature, patterns of recognizing the behavior of SMMs are always considered at a certain time interval T. To initialize the model at the beginning of this period, additional probabilities are used to describe the probability of the distribution of states at time t = 1. An equivalent criterion for the final state is usually absent. Thus, the actions of the model come to the final state as soon as an arbitrary state is reached at time T. Neither static nor declarative criteria are used to more accurately mark the end of the states.
Nevertheless, the hidden first-order Markov models, which are usually denoted by A, are completely described:
• by establishing a finite set of states {s | 1
• state of transition probabilities, matrix A
• state vector π
• state of a specific probability distribution
f for model derivation However, the distribution of the derivation must be distinguished depending on the type of output data during generation. In the simplest case, the output is generated from discrete probability distributions {O1, O2 ... OM}, and therefore are of symbolic type. The parameter bj (ok) represents the discrete probability of the distribution, which can be grouped into the matrix of probabilities of the output data:
With this choice of simulation output, the so-called discrete SMMs are obtained.
If, when, a vector of xe IRn sequence values is observed, rather than the output of the distribution data described on the basis of the continuous probability distribution function: The
modern application of SMM for signal analysis tasks uses exclusively the so-called continuous SMM, although the need to model a continuous distribution significantly increases the complexity of the analysis.
Chapter 5 translation (1 paragraph) of
Gernot A. Fink “Markov Models for Pattern Recognition From Theory to Applications”