GNMT, epic fail or machine translation subtleties
After reading the article " Neural machine translation of Google ", I recalled the latest epic-fail of Google's machine translation plying the Internet recently. Who strongly can not wait immediately shake the bottom of the article.
GNMT is Google's neural machine translation system ( NMT ), which uses a neural network ( ANN ) to improve accuracy and speed of translation, and in particular to create better, more natural options for translating text into Google Translate.
In the case of GNMT, this is the so-called example-based translation method ( EBMT ), i.e. The ANN underlying the method is trained in millions of translation examples, and, unlike other systems, this method allows performing the so-called zero-shot translation , i.e. translating from one language to another, without having explicit examples for this pair of specific languages in the process of learning (in the training set).
Fig. 1. Zero-Shot Translation
Moreover, GNMT is designed primarily to improve the translation of phrases and sentences, since it is impossible to use the literal version of the translation in contextual translation and often the sentence is translated completely differently.
In addition, returning to the zero-shot translation, Google is trying to select some common component that is valid for several languages at once (both when searching for dependencies and when building links for sentences and phrases).
For example, in Figure 2, such interlingua “commonality” is shown among all possible pairs for Japanese, Korean and English.

Fig. 2. Interlingua. 3-D view of network data for Japanese, Korean and English .
Part (a) shows the general “geometry” of such translations, where the points are colored in meaning (and the same color for the same meaning in several pairs of languages).
Part (b) shows an increase in one of the groups, part © in the colors of the original language.
GNMT uses a great deep-learning ANN ( DNN ), which, learned from millions of examples, should improve the quality of translation by applying contextual abstract approximation for the most appropriate translation option. Roughly speaking, it chooses the best, in the sense of the most appropriate grammar of the human language, the result, while taking into account the generality of building links, phrases and sentences for several languages (ie, separately highlighting and teaching the interlingua model or layers).
However, DNN, both in the process of learning and in the process of work, usually relies on statistical (probabilistic) inference and is rarely associated with additional non-probabilistic algorithms. Those. to evaluate the best possible result that came out of the variator, the statistically most best (likely) option will be chosen.
All this, naturally, additionally depends on the quality of the training sample (and / or the quality of the algorithms in the case of a self-learning model).
Considering the cross-cutting (zero-shot) method of translation and remembering some common (interlingua) component, if there is some positive logical deep connection for one language, and no negative components for other languages, some abstract error got out of the learning process and, accordingly, translation of a phrase for one language is likely to be repeated for other languages or even language pairs.
All images are clickable (as proof to the corresponding Google Translate page).
German: English: Dutch: Danish: French: Etc.
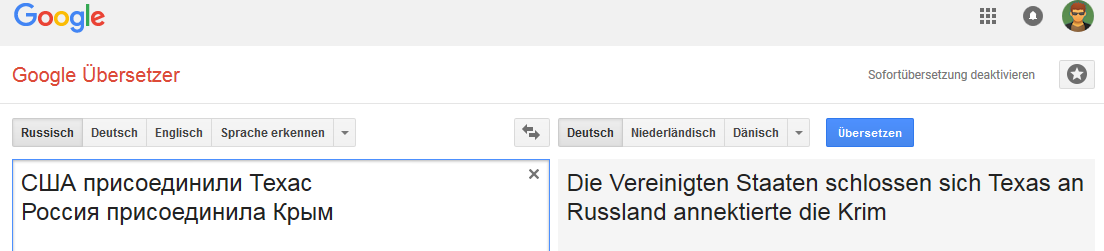
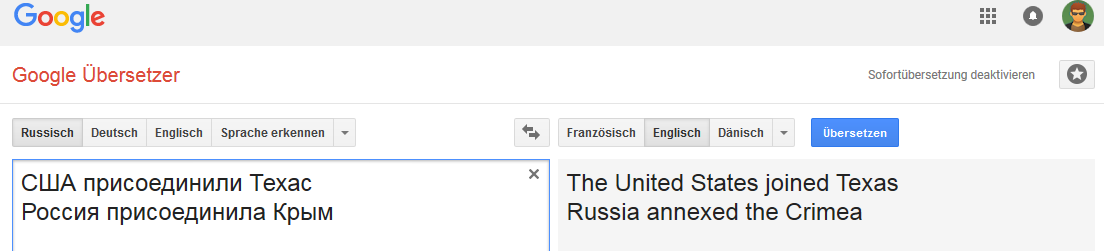



The connection is stable for the word Russia (in the sense that when Russia is replaced, for example, with the Russian empire, the “translation” variant changes).
And it is not very stable with some changes in phrases that are not typical for translation into English, but are common for example for Russian, German and Dutch.
This is unfortunately not the only case and the Internet is replete with all sorts of errors Google Translate.
And I think that a considerable part of the existing errors manifests itself due to a combination of several factors, ranging from the actual quality of the training sample to the quality of the algorithms of semantic and morphological analysis for a particular language (and the learning model in particular).
Once, one colleague offered to participate in Google's Text Normalization Challenge (for Russian and English) on kaggle ...
Before agreeing, I then made a small analysis of the quality of the training test sample for all classes of tokens for both languages ... and as a result He refused to participate at all, for the more I dug, the stronger the feeling was that the competition would be like a lottery or that one who would be most accurate in repeating all the mistakes made in the semi-manual creation of a Google training sample would win.
I even wanted to write an article on the topic “How to easily throw away 50K ...”, and yes, time - be it not good.
If anyone is interested, I will try to carve out a little bit.
[UPD]Why is it actually a file? Without being distracted by the lyrics, the “political” subtext and every attempt to justify “a man would translate this way,” and so on, would be thematic.
1. This is a wrong translation. Point.
2. On this illustrative case, GNMT shows a complete lack of any classification model (in the sense of CADM , in which Google should shine, because they have a lot of data from everywhere). Just insofar as the subject in both cases are countries / states, and the additions are geographical entities (territory).
Even the dumbest plausibility-rule of some fuzzy K-nn classification would never have made such a mistake. Let's keep silent about modern algorithms for the classification and construction of (semantic) links.
As the saying goes, nothing personal, simple math ... Well, if Google decided to feed its network with clippings from the tabloid press, then I have bad news for him.
PS However, as one professor, whom I respected once, once told me, “It is sometimes difficult to prove to a woodpecker that he is a woodpecker, especially if he is sure that he is smarter than a professor”.
Well, for starters, a little theory:
GNMT is Google's neural machine translation system ( NMT ), which uses a neural network ( ANN ) to improve accuracy and speed of translation, and in particular to create better, more natural options for translating text into Google Translate.
In the case of GNMT, this is the so-called example-based translation method ( EBMT ), i.e. The ANN underlying the method is trained in millions of translation examples, and, unlike other systems, this method allows performing the so-called zero-shot translation , i.e. translating from one language to another, without having explicit examples for this pair of specific languages in the process of learning (in the training set).
Fig. 1. Zero-Shot Translation
Moreover, GNMT is designed primarily to improve the translation of phrases and sentences, since it is impossible to use the literal version of the translation in contextual translation and often the sentence is translated completely differently.
In addition, returning to the zero-shot translation, Google is trying to select some common component that is valid for several languages at once (both when searching for dependencies and when building links for sentences and phrases).
For example, in Figure 2, such interlingua “commonality” is shown among all possible pairs for Japanese, Korean and English.
Fig. 2. Interlingua. 3-D view of network data for Japanese, Korean and English .
Part (a) shows the general “geometry” of such translations, where the points are colored in meaning (and the same color for the same meaning in several pairs of languages).
Part (b) shows an increase in one of the groups, part © in the colors of the original language.
GNMT uses a great deep-learning ANN ( DNN ), which, learned from millions of examples, should improve the quality of translation by applying contextual abstract approximation for the most appropriate translation option. Roughly speaking, it chooses the best, in the sense of the most appropriate grammar of the human language, the result, while taking into account the generality of building links, phrases and sentences for several languages (ie, separately highlighting and teaching the interlingua model or layers).
However, DNN, both in the process of learning and in the process of work, usually relies on statistical (probabilistic) inference and is rarely associated with additional non-probabilistic algorithms. Those. to evaluate the best possible result that came out of the variator, the statistically most best (likely) option will be chosen.
All this, naturally, additionally depends on the quality of the training sample (and / or the quality of the algorithms in the case of a self-learning model).
Considering the cross-cutting (zero-shot) method of translation and remembering some common (interlingua) component, if there is some positive logical deep connection for one language, and no negative components for other languages, some abstract error got out of the learning process and, accordingly, translation of a phrase for one language is likely to be repeated for other languages or even language pairs.
Actually fresh epic fail
All images are clickable (as proof to the corresponding Google Translate page).
German: English: Dutch: Danish: French: Etc.
Instead of conclusion
The connection is stable for the word Russia (in the sense that when Russia is replaced, for example, with the Russian empire, the “translation” variant changes).
And it is not very stable with some changes in phrases that are not typical for translation into English, but are common for example for Russian, German and Dutch.
This is unfortunately not the only case and the Internet is replete with all sorts of errors Google Translate.
And I think that a considerable part of the existing errors manifests itself due to a combination of several factors, ranging from the actual quality of the training sample to the quality of the algorithms of semantic and morphological analysis for a particular language (and the learning model in particular).
Once, one colleague offered to participate in Google's Text Normalization Challenge (for Russian and English) on kaggle ...
Before agreeing, I then made a small analysis of the quality of the training test sample for all classes of tokens for both languages ... and as a result He refused to participate at all, for the more I dug, the stronger the feeling was that the competition would be like a lottery or that one who would be most accurate in repeating all the mistakes made in the semi-manual creation of a Google training sample would win.
I even wanted to write an article on the topic “How to easily throw away 50K ...”, and yes, time - be it not good.
If anyone is interested, I will try to carve out a little bit.
[UPD]Why is it actually a file? Without being distracted by the lyrics, the “political” subtext and every attempt to justify “a man would translate this way,” and so on, would be thematic.
1. This is a wrong translation. Point.
2. On this illustrative case, GNMT shows a complete lack of any classification model (in the sense of CADM , in which Google should shine, because they have a lot of data from everywhere). Just insofar as the subject in both cases are countries / states, and the additions are geographical entities (territory).
Even the dumbest plausibility-rule of some fuzzy K-nn classification would never have made such a mistake. Let's keep silent about modern algorithms for the classification and construction of (semantic) links.
As the saying goes, nothing personal, simple math ... Well, if Google decided to feed its network with clippings from the tabloid press, then I have bad news for him.
PS However, as one professor, whom I respected once, once told me, “It is sometimes difficult to prove to a woodpecker that he is a woodpecker, especially if he is sure that he is smarter than a professor”.