We teach the computer to distinguish sounds: familiarity with the DCASE competition and building your audio classifier in 30 minutes
Article written in collaboration with ananaskelly .
Introduction
Hello everyone, Habr! Working at the Center for Speech Technologies in St. Petersburg, we have gained a bit of experience in solving problems of classifying and detecting acoustic events and decided that we are ready to share it with you. The purpose of this article is to introduce you to some tasks and talk about the “DCASE 2018” automatic audio processing competition . Telling you about the competition, we will do without complex formulas and definitions related to machine learning, so the general meaning of the article will be understood by a wide audience .
For those who were attracted by the classifier assembly in the title , we prepared a small code in python, and from the link on the githaba you can find a notebook, where we use the example of the second track of the DCASE contest to create a simple convolutional network on keras for classifying audio files. There we talk a little about the network and the features used for training, and how to get a result close to the baseline using simple architecture ( MAP @ 3 = 0.6).
Additionally, there will be described basic approaches for solving problems (baseline) proposed by the organizers. Also in the future there will be several articles where we will talk in more detail and in detail both about our experience of participating in the competition, and about the solutions proposed by other participants in the competition. Links to these articles will gradually appear here.
Surely, many people have no idea of any kind of “DCASE” there , so let's see what kind of fruit it is and what it is eaten with. Competition “ DCASE”Takes place annually, and every year several tasks are laid out in it, dedicated to solving problems in the field of classification of audio recordings and the detection of acoustic events. Anyone can take part in the competition, it is free, it’s enough just to register on the site as a participant. Following the results of the competition, a conference dedicated to the same subject is held, but, unlike the competition itself, participation in it is already paid, and we will not talk about it anymore. Cash rewards for the best solutions usually do not rely, but there are exceptions (for example, the 3rd task in 2018). This year the organizers proposed the following 5 tasks:
- Classification of acoustic scenes (divided into 3 subtasks)
A. The training and verification data sets are recorded on the same device
B. The training and verification data sets are recorded on different devices
C. Training is allowed using data that was not offered by the organizers - Classification of acoustic events
- Detection of birds singing
- Detection of acoustic events in living conditions using a weakly-marked data set
- Classification of household activity in the room for multi-channel recording
About detection and classification
As we see, in the names of all tasks there is one of two words: “detection” or “classification”. Let's clarify the difference between these concepts so that there is no confusion.
Imagine that we have an audio recording in which a dog barks at one point in time and a cat meows at another, and there are simply no other events. Then if we want to understand exactly when these events occur, then we need to solve the problem of detecting an acoustic event. That is, we need to know the start and end times for each event. Having solved the detection problem, we will find out when exactly the events occur, but we do not know who exactly the sounds are found - then we need to solve the classification problem, that is, determine what exactly happened in a given time interval.
To understand the description of the tasks of the competition, these examples will be quite enough, which means that the introductory part is over, and we can proceed to a detailed description of the tasks themselves.
Track 1. Classification of acoustic scenes
The first task is to determine the environment (acoustic stage) in which the audio was recorded, for example, “Metro Station”, “Airport” or “Pedestrian Street”. Solving such a problem can be useful when assessing the environment by an artificial intelligence system, for example, in cars with autopilot.

In this task, TUT Urban Acoustic Scenes 2018 and TUT Urban Acoustic Scenes 2018 Mobile datasets were presented for training, which were prepared by the Tampere University of Technology (Finland). A detailed description of the process of preparing dataset, as well as the basic solution, is described in the article .
In total, 10 acoustic scenes were presented for the competition, which were to be predicted by the participants.
Subtask A
As we have said, the task is divided into 3 subtasks, each of which is distinguished by the quality of audio recordings. For example, in subtask A, special microphones were used for recording, which were located in human ears. Thus, the stereo recording was made closer to the human perception of sound. Participants had the opportunity to use this approach to recording to improve the quality of recognition of the acoustic scene.
Subtask B
In subtask B, other devices were also used for recording (for example, mobile phones). Data from subtask A has been converted to mono format, the sampling rate has been reduced, there is no imitation of the “audibility” of sound by a person in the data set for this task, but there is more data to learn.
Subtask C
The data set for subtask C is the same as in subtask A, but in solving this problem it is allowed to use any external data that the participant can find. The goal of this task is to find out whether it is possible to improve the result obtained in subtask A with the help of attracting third-party data.
The quality of decisions on this track was evaluated by the Accuracy metric .
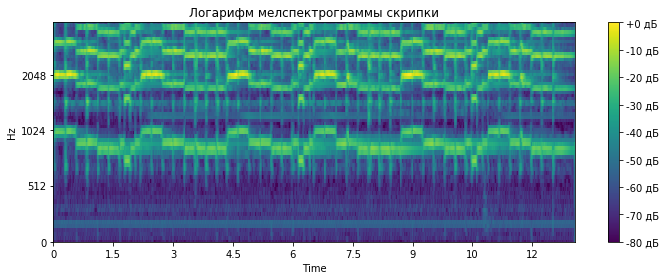
The baseline for this task is a two-layer convolutional neural network that learns on logarithms of the melting data of the original audio data. The proposed architecture uses the standard BatchNormalization and Dropout techniques. The code on GitHub can be viewed here .
Track 2. Classification of acoustic events
In this task, it is proposed to create a system that performs the classification of acoustic events. Such a system can be an addition to “smart” homes, increase safety in crowded places or make life easier for people with hearing impairments.

The data set for this task consists of files taken from the Freesound data set and tagged using tags from Google ’s AudioSet . In more detail the process of preparing dataset is described in an article prepared by the organizers of the competition.
Let's return to the task itself, which has several features.
First, the participants had to create a model capable of identifying differences between acoustic events of a very different nature. The data set is divided into 41 classes, it presents various musical instruments, sounds made by humans, animals, household sounds, and so on.
Secondly, besides the usual data markup, there is also additional information about manually checking the tag. That is, participants know which files from the data set were checked by a person for compliance with the label, and which are not. As practice has shown, the participants who in one way or another used this additional information occupied prizes in solving this problem.
Additionally, it must be said that the length of records in a data set varies greatly: from 0.3 seconds to 30 seconds. In this task, the amount of data per class also varies greatly, for which you need to train the model. It is best to depict it in the form of a histogram, the code for which is taken from here .
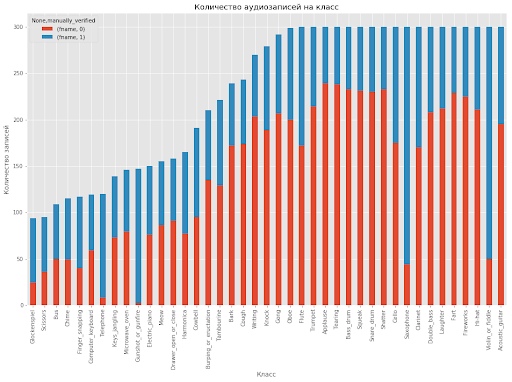
As can be seen from the histogram, manual marking for the classes presented is also unbalanced, which adds difficulty if you wish to use this information when training models.
The results in this track were estimated by the average accuracy metric (Mean Mean Precision, MAP @ 3), a fairly simple demonstration of the calculation of this metric with examples and code can be found here .
Track 3. Detection of bird singing
The next track is the detection of birds singing. A similar problem arises, for example, in various systems of automatic monitoring of wildlife - this is the first step in data processing before, for example, classification. Such systems often need to be tuned, they are unstable to new acoustic conditions, so the goal of this track is to invoke the power of machine learning to solve such problems.
This track is an extended version of the “Bird Audio Detection challenge” competition , organized by the University of London St. Mary's, held in 2017/2018. For those interested , you can familiarize yourself with the article from the authors of the competition, which provides details about the formation of data, the organization of the competition itself and the analysis of the solutions obtained.
However, back to the DCASE problem. The organizers provided six data sets - three for training, three for testing - all of them are very different - recorded in different acoustic conditions, using different recording devices, there are different noises in the background. Thus, the main message is that the model should not depend on the environment or be able to adapt to it. Despite the fact that the name means “detection”, the task is not to define the boundaries of the event, but to simple classification - the final solution is a kind of binary classifier that receives a short audio recording at the input and makes a decision whether there is a bird singing on it or not . AUC metric was used to assess accuracy.
Basically, participants tried to generalize and adapt by varying augmentation of data. One of the commands describes the use of various techniques - changing the frequency resolution in the extracted features, preliminary noise purification, adaptation method based on the alignment of second-order statistics for different data sets. However, such methods, as well as different types of augmentation, give a very small increase over the basic solution, as many participants note.
As a basic solution, the authors prepared a modification of the most successful solution from the original competition “Bird Audio Detection challenge”. The code, as usual, is available on github .
Track 4. Detection of acoustic events in living conditions using a weakly labeled data set.
In the fourth track, the detection problem is solved directly. The participants were given a relatively small dataset of tagged data - a total of 1578 audio recordings of 10 seconds each, having only markup by class: it is known that the file contains one or several events of the indicated classes, but the time markup is completely absent. In addition, two large datasets of unallocated data were provided - 14412 files containing target events of the same classes as in the training and test sample, as well as 39999 files containing arbitrary events that are not included in the targetgroups. All data is a subset of the huge dataset audioset collected by Google .
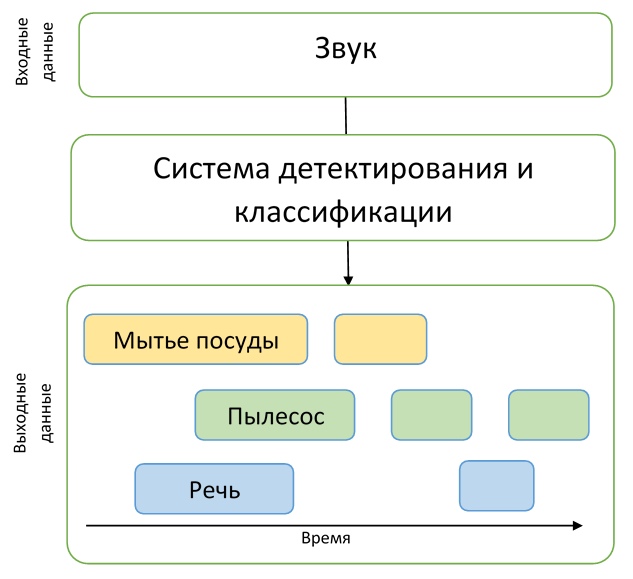
Thus, it was necessary for participants to create a model capable of learning from weakly marked data to find the time marks of the beginning and end of events (events can be intersecting) and try to improve it with a large amount of unmarked additional data. In addition, it is worth noting that a fairly rigid metric was used in this track - it was necessary to predict the timestamps of events with an accuracy of 200 ms. In general, the participants had to solve a rather complicated task of creating an adequate model, while practically having no good data for training.
Most of the solutions were based on convolutional recurrent networks — a rather popular architecture in the field of detecting acoustic events lately (an example can be found at the link ).
The basic solution from the authors, also on convolutional recurrent networks, is based on two models. The models have almost the same architecture: three convolutional and one recurrent layer. The only difference is in the output of networks. The first model is trained to mark up unallocated data to extend the source dataset - so, at the output, we have classes of events present in the file. The second is to directly solve the problem of detection, that is, at the output we obtain the time markup for the file. Code by reference .
Track 5. Classification of household activity in the room for multi-channel recording.
The last track was different from the rest in the first place because the participants were offered multichannel recordings. The task itself was in the classification: it is necessary to predict the class of the event that occurred on the record. Unlike the previous track, the task is somewhat simpler - it is known that there is only one event in the recording.
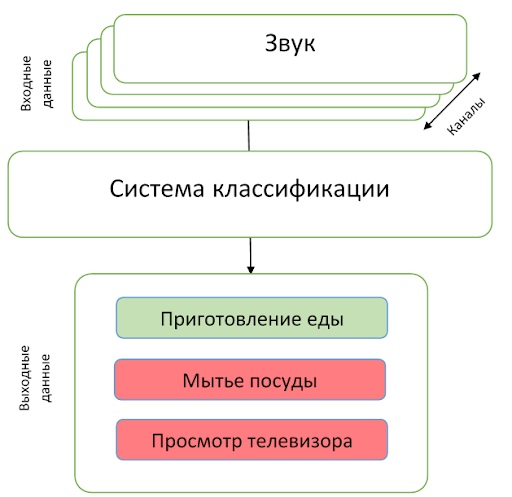
Dataset is represented by approximately 200 hours of recordings on a linear microphone array of 4 microphones. Events are all sorts of domestic activities - cooking, washing dishes, social activity (talking on the phone, visit and personal conversation), etc., also highlighted the absence of any class of events.
The authors of the track emphasize that the conditions of the problem are relatively simple so that the participants focus directly on the use of spatial information from multi-channel records. Participants were also given the opportunity to use additional data and pre-trained models. Quality was evaluated by F1-measure.
As a basic solution, the authors of the track proposed a simple convolutional network with two convolutional layers. In their solution, spatial information was not used - data from four microphones was used for learning independently, and when testing, predictions were averaged. Description and code are available here .
Conclusion
In the article we tried to briefly talk about the detection of acoustic events and about such a competition as DCASE. Perhaps, we were able to interest someone to participate in 2019 - the competition starts in March.