Perf and flamegraphs

The topic of increasing the productivity of operating systems and searching for bottlenecks is gaining tremendous popularity. In this article we will talk about a single tool for finding these very places using the example of block stack work in Linux and one case of the host shutdown.
Example 1. Test
Nothing works
Testing in our department is synthetics on grocery iron, and later - tests of application software. We received the Intel Optane CD for testing. We have already written about testing Optane disks in our blog earlier .
The disk was installed in the standard server, collected relatively long ago under one of the cloud projects.
During testing, the disc did not perform well: with a test with a queue depth of 1 request in 1 stream, blocks of 4 KB around ~ 70Kiops. And this means that the waiting time for an answer is huge: approximately 13 microseconds per request!
Strange, because the specification promises “Latency - Read 10 µs”, and we got 30% more, the difference is quite significant. The disk was rearranged to another platform, a more "fresh" assembly used in another project.
Why does it work?
It's funny, but the disk on the new platform has worked as it should. Performance increased, latency decreased, CPU per shelf, 1 stream per 1 request, 4K bytes in blocks, ~ 106Kiops for ~ 9 microseconds per request.
And then it's time to
- Take measurements of hardware counters: the number of instruction calls, cash misses, incorrectly predicted branches, etc. (PMU events)
- Remove information from static treyspoints, the number of entries
- Do dynamic tracing
For verification, we used CPU sampling.
The bottom line is that perf can collect the entire stack trace of a running program. Naturally, running perf will delay the operation of the entire system. But we have a -F # flag , where # is the sampling rate, measured in Hz.
Here it is important to understand that the higher the sampling rate, the more chances to catch the call of a particular function, but the more brakes the profiler brings into the system. The lower the frequency, the greater the chance that we will not see part of the stack.
When choosing a frequency, you need to be guided by common sense and one cunning - try not to set an even frequency, so as not to get into a situation when some work on a timer with this frequency gets into the samples.
Another point that is misleading at first is that the software should be assembled with the -fno-omit-frame-pointer flag , if this is possible, of course. Otherwise, in trace instead of function names, we will see solid values of unknown . For some software, the debugging symbols come as a separate package, for example, someutil-dbg . It is recommended to install them before running perf .
We performed the following actions:
- Taken fio from git: //git.kernel.dk/fio.git, tag fio-3.9
- Added option -fno-omit-frame-pointer to CPPFLAGS in the Makefile
- Launched make -j8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1GThe -g option is needed to capture the stack of traces.
You can view the result with the command:
perf report -g fractalThe option -g fractal is needed so that percentages reflecting the number of samples with this function and shown by perf are relative to the calling function, the number of calls to which is taken as 100%.
Toward the end of the long stack of calls to fio on the “fresh build” platform, we will see:
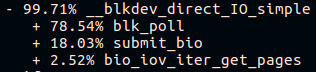
And on the “old build” platform:

Great! But I want beautiful flamegraphs.
Building Flamegraphs
To make it beautiful, there are two tools:
- Relatively more static flamegraph
- Flamescope , which allows you to select a specific period of time from the collected samples. This is very useful when the code you are looking for loads the CPU in short bursts.
These utilities accept the output perf script> result .
Download the result and send it through the pipe in svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svgOpen in the browser and enjoy the clickable image.
You can use another method:
- Add result to flamescope / example /
- Run python ./run.py
- We come through the browser on the 5000th port of a local host
What do we see in the end?
A good fio spends a lot of time in polling :

A bad fio spends time anywhere, but not in a pollingue:
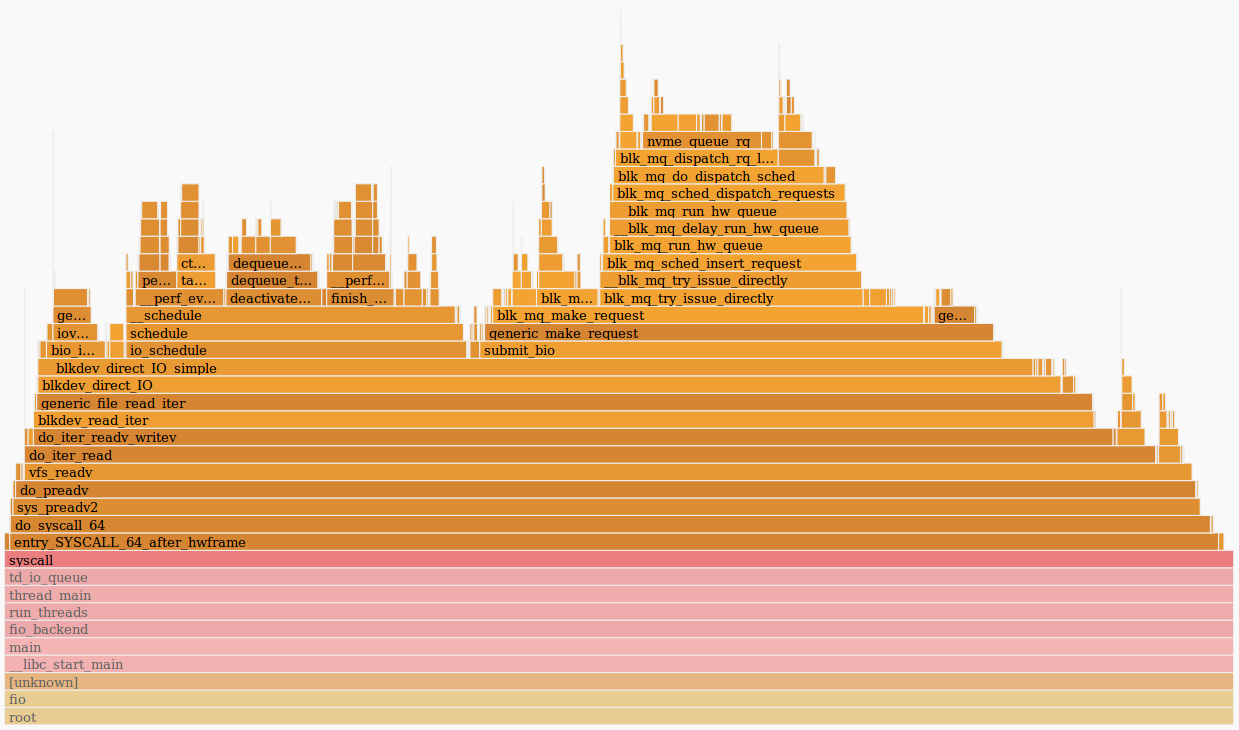
At first glance, it seems that polling does not work on the old host, but everywhere there is a 4.15 kernel of the same assembly and polling is enabled by default on NVMe disks. Check if polling is enabled in sysfs :
# cat /sys/class/block/nvme0n1/queue/io_poll
1During tests, preadv2 calls with the RWF_HIPRI flag are used - a necessary condition for polling to work. And, if you carefully study the flame (or the previous screenshot from the perf report output ), you can find it, but it takes a very short amount of time.
The second thing to be seen is the differing call stack for the submit_bio () function and the absence of io_schedule () calls. Let's take a closer look at the difference inside submit_bio ().
Slow “old build” platform:

Fast platform "fresh":

It seems that on a slow platform the request goes a long way to the device, at the same time getting into the kyber scheduler . You can read more about I / O schedulers in our article .
As soon as kyber was turned off, the same fio test showed an average wait time of about 10 microseconds, right as stated in the specification. Fine!
But where is the difference in one microsecond?
And if a little deeper?
As already mentioned, perf allows you to collect statistics from hardware counters. Let's try to see the number of cash misses and instructions for the cycle:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10

From the results, it can be seen that the fast platform executes more instructions per CPU cycle and has a smaller percentage of cache misses during execution. Of course, we will not go into the details of the work of different hardware platforms within the framework of this article.
Example 2. Grocery
Something is going wrong
In the work of a distributed storage system, an increase in the load on the CPU on one of the hosts was observed with an increase in incoming traffic. The hosts are equal, equivalent and have identical hardware and software.
Consider what the CPU load looks like:
~# pidstat -p 1441734 1
Linux 3.13.0-96-generic (lol) 10/10/2018 _x86_64_ (24 CPU)
09:23:30 PM UID PID %usr %system %guest %CPU CPU Command
09:23:44 PM 0 1441734 23.00 1.00 0.00 24.00 4 ceph-osd
09:23:45 PM 0 1441734 85.00 34.00 0.00 119.00 4 ceph-osd
09:23:46 PM 0 1441734 0.00 130.00 0.00 130.00 4 ceph-osd
09:23:47 PM 0 1441734 121.00 0.00 0.00 121.00 4 ceph-osd
09:23:48 PM 0 1441734 28.00 82.00 0.00 110.00 4 ceph-osd
09:23:49 PM 0 1441734 4.00 13.00 0.00 17.00 4 ceph-osd
09:23:50 PM 0 1441734 1.00 6.00 0.00 7.00 4 ceph-osdThe problem arose at 09:23:46 and we see that the process worked in kernel space exclusively for the entire second. Let's look at what was happening inside.
Why so slow?
In this case, we took samples from the entire system:
perf record -a -g -- sleep 22
perf script > perf.resultsThe -a option is needed here in order for perf to shoot traces from all CPUs.
Open perf.results with flamescope to track the moment of increased load on the CPU.
Heat map
Before us is a "heat map", both axes (X and Y) of which represent time.
On the X axis, the space is divided into seconds, and on the Y axis - into sections of 20 milliseconds within seconds X. Time passes from bottom to top and from left to right. The brightest squares have the largest number of samples. That is, the CPU at that time worked most actively.
Actually, we are interested in the red spot in the middle. Select it with the mouse, click and see what it hides:
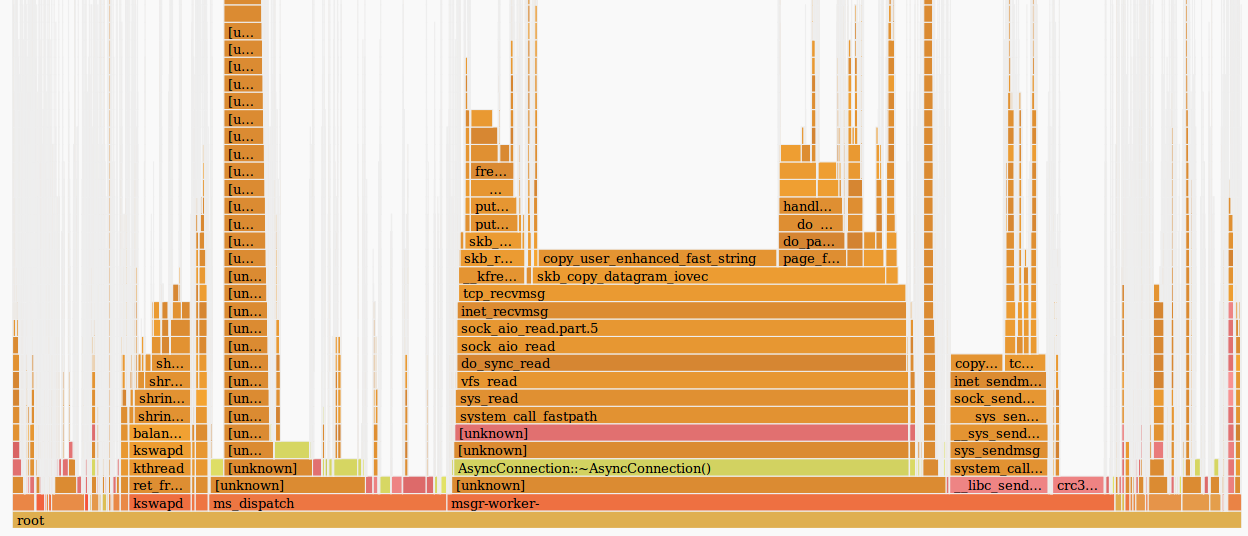
In general, it is already clear that the problem lies in the slow operation of tcp_recvmsg and skb_copy_datagram_iovec in it.
For clarity, compare with the samples of another host, on which the same amount of incoming traffic does not cause problems:
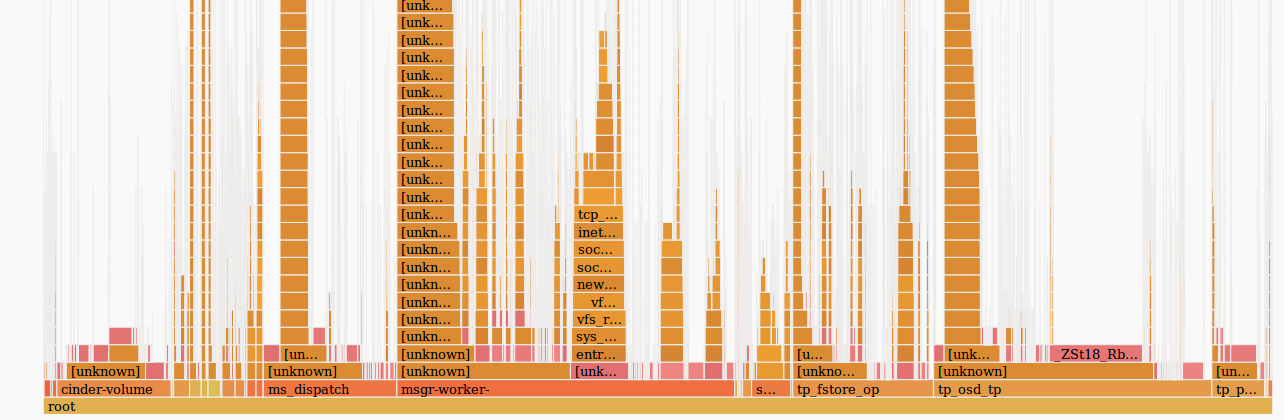
Based on the fact that we have the same amount of incoming traffic, identical platforms that have been operating for a long time without stopping, we can assume that problems arose on the side of the iron. The skb_copy_datagram_iovec function copies data from the kernel structure to a user-space structure to pass on to the application. There are probably problems with host memory. At the same time, there are no errors in the logs.
Restart the platform. When loading BIOS we see the message on a broken lath of memory. Replacement, the host starts and the problem with the overloaded CPU is no longer playing.
P.S
System performance with perf
Generally speaking, on a booted system, perf can delay the processing of requests. The size of these delays also depends on the load on the server.
Let's try to find this delay:
~# /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1 test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
fio-3.9-dirty
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=413MiB/s][r=106k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=109786: Wed Dec 12 17:25:56 2018
read: IOPS=106k, BW=414MiB/s (434MB/s)(4096MiB/9903msec)
clat (nsec): min=8161, max=84768, avg=9092.68, stdev=1866.73
lat (nsec): min=8195, max=92651, avg=9127.03, stdev=1867.13
…
~# perf record /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
fio-3.9-dirty
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=413MiB/s][r=106k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=109839: Wed Dec 12 17:27:50 2018
read: IOPS=106k, BW=413MiB/s (433MB/s)(4096MiB/9916msec)
clat (nsec): min=8259, max=55066, avg=9102.88, stdev=1903.37
lat (nsec): min=8293, max=55096, avg=9135.43, stdev=1904.01The difference is not very noticeable, only about ~ 8 nanoseconds.
Let's see what happens if we increase the load:
~# /root/fio/fio --clocksource=cpu --name=test --numjobs=4 --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
...
fio-3.9-dirty
Starting 4 processes
Jobs: 4 (f=4): [r(4)][100.0%][r=1608MiB/s][r=412k IOPS][eta 00m:00s]
~# perf record /root/fio/fio --clocksource=cpu --name=test --numjobs=4 --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1 test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
...
fio-3.9-dirty
Starting 4 processes
Jobs: 4 (f=4): [r(4)][100.0%][r=1584MiB/s][r=405k IOPS][eta 00m:00s]Here the difference is already becoming noticeable. It can be said that the system has slowed down by less than 1%, but essentially a loss of about 7Kiops on a highly loaded system can lead to problems.
It is clear that this example is synthetic, however, it is very significant.
Let's try to run another synthetic test that calculates prime numbers - sysbench :
~# sysbench --max-time=10 --test=cpu run --num-threads=10 --cpu-max-prime=100000
...
Test execution summary:
total time: 10.0140s
total number of events: 3540
total time taken by event execution: 100.1248
per-request statistics:
min: 28.26ms
avg: 28.28ms
max: 28.53ms
approx. 95 percentile: 28.31ms
Threads fairness:
events (avg/stddev): 354.0000/0.00
execution time (avg/stddev): 10.0125/0.00
~# perf record sysbench --max-time=10 --test=cpu run --num-threads=10 --cpu-max-prime=100000
…
Test execution summary:
total time: 10.0284s
total number of events: 3498
total time taken by event execution: 100.2164
per-request statistics:
min: 28.53ms
avg: 28.65ms
max: 28.89ms
approx. 95 percentile: 28.67ms
Threads fairness:
events (avg/stddev): 349.8000/0.40
execution time (avg/stddev): 10.0216/0.01Here you can see that even the minimum processing time increased by 270 microseconds.
Instead of conclusion
Perf is a very powerful tool for analyzing performance and debugging system operation. However, as with any other tool, you need to keep yourself in hand and remember that any loaded system under worse supervision works worse.
Related Links: