ABBYY FlexiLayout Studio: training flexibility
 We continue to talk about ABBYY FlexiLayout Studio , a program for creating flexible descriptions in the ABBYY FlexiCapure data entry system . The last time I told you how to manually make the flexible description, and today we'll talk about how you can create them automatically - a new feature that appeared in the last, the tenth version of ABBYY FlexiLayout Studio.
We continue to talk about ABBYY FlexiLayout Studio , a program for creating flexible descriptions in the ABBYY FlexiCapure data entry system . The last time I told you how to manually make the flexible description, and today we'll talk about how you can create them automatically - a new feature that appeared in the last, the tenth version of ABBYY FlexiLayout Studio.Let's not be cunning, it was not so easy to create descriptions for loosely structured documents: even for a simple payment or invoice, creating a flexible description without prior training was very difficult. It was necessary to manually determine the mutual arrangement of the fields, the relationships between them and the like parameters, and then indicate them, and not clearly, directly on the image, but in the form of numbers. Now you can upload several images, “show” the program where static elements and data fields are located on them, and it will automatically create a description.
For ABBYY FlexiCapture users, this means that simple projects (where the relative positions of static elements and fields with data in different documents are not very different) can now be handled by an unprepared person - for example, an accountant Lena. Agree, this is convenient.
Now let's see how it works.
We will look at the same example of ATM checks of two banks as in the previous article . Then one sample of each check was enough for us (although, of course, the more the better). Now we will take three samples of the check of each bank for training the program and one for subsequent verification.
The learning process is as follows: we indicate to the program where the static elements (headers) and data fields are located on the example of one image. Next, we check how correctly the program "understood" us, trying to find the necessary fields in the second, third, etc. images. If errors occur in some image, we correct them and try the following. After training, we automatically generate a flexible description and check it on two control checks.
So, we launch the application, create a project, upload images of six selected receipts (not very clear, but not the most worn ones left for control). Automatically correct image orientation and perform pre-recognition. The figure shows the result. Automatically found words are highlighted:

Add images to the training set and go into training mode. Next, using a magic wand - a tool
 - specify fields and static elements (by double-clicking on the found word or by tracing several words with the mouse while holding the left button):
- specify fields and static elements (by double-clicking on the found word or by tracing several words with the mouse while holding the left button): 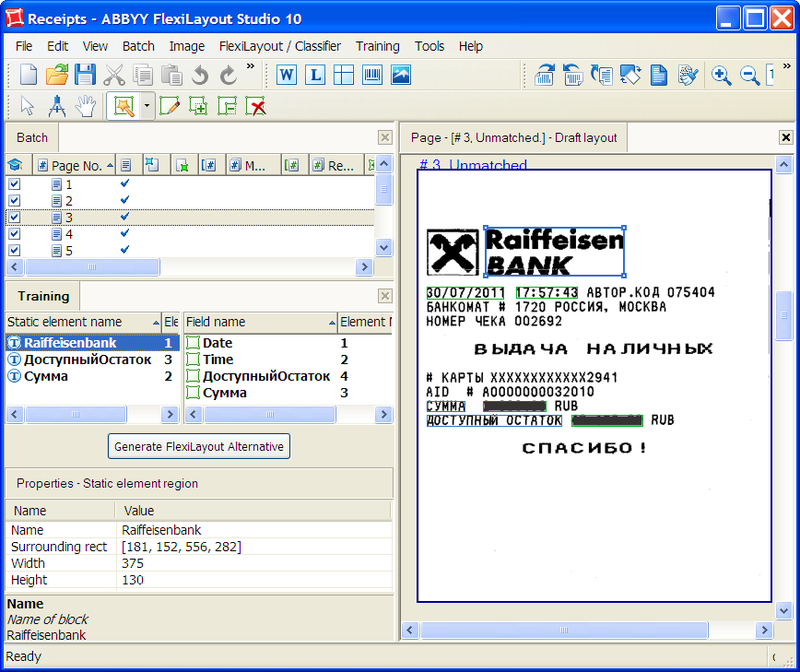
It can be seen that the interface is slightly different from the manual markup creation mode described earlier : instead of a panel with a FlexiLayout structure, Training panel . It contains a list of support elements (left) and data fields. On the right, as before, is the image. The blue frames highlight the static text, the green boxes indicate the fields from which to extract information.
Static items are displayed in the Training panel.in the left column, fields in the right. For static elements, the program determines the text to be searched, as well as some other parameters, for example, whether the text can be multi-line. Recognized text is used as the name of the element (for example, Accessible Residue ). For data fields, the program tries to find the header (static element) and names the field according to it. For the Date and Time fields, the program found the header incorrectly (since it does not exist), they had to be called manually.
So far, outwardly, everything is almost the same as it was before. But if we now create markup and see the properties of the elements, then in them, unlike the ninth version, the location of the element relative to others will be indicated. That is, everything that used to be long and dreary to calculate and manually specify for each static element or data field — its location in the document, its position relative to other objects, and possibly the distance from them — is now calculated and filled out automatically. Even in the simple case consideredin our last example, it took not so little time. And in real life, when the number of elements and fields is in the tens, if not hundreds, the development of the description may take not only days, but weeks. But the documents, in general, can be very similar and have a simple structure, that is, most of the time was occupied by the selection of the necessary values for the indentation and their adjustment.
And then the fun begins: we take a check from another bank and try to use the markup we created on it:
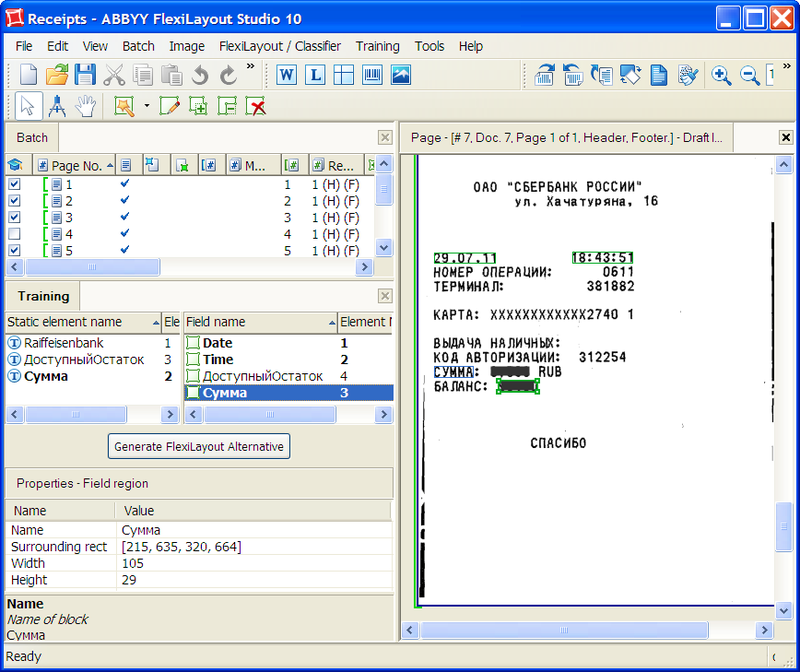
In the Training panel, the objects found are shown in bold, in the figure, as before, with blue and green frames.
Oops ... The result, at first glance, is discouraging. Two static elements (bank name and field heading with an account balance) were not found, three out of four fields were recognized, and besides, one is incorrect: the balance is selected instead of the amount. On the other hand, nothing surprising: a check from another bank, static elements are called differently, and the fields are searched for relative to them. We manually indicate the location of the necessary elements by moving and resizing the frames with the mouse, and for elements not found, by tracing the desired group of words with the cursor while holding the left mouse button. At the same time, the program will not only adjust the possible location of objects relative to each other, but also “understand” that the Raiffeisenbank and Available Balance static elements may contain other text:OJSC SBERBANK OF RUSSIA and BALANCE, respectively.

Then everything is simple: we repeat the operation for the remaining four checks: we test the markup and, if necessary, make adjustments. After the markup is checked on all test images (it is better, of course, that there are more of them, and they are more diverse), we create a flexible description and try to process the remaining two checks with it. The result in the figure:

As you can see, it turned out to be quite good. All elements were found correctly, despite the not very high quality of the Sberbank check. If necessary, you can edit the created markup later by correcting or adding properties or objects. But in general, the program coped with its work: checks are recognized correctly.
Of course, for complex multi-page projects, the fields on which are located in the most diverse ways, it is not yet possible to create descriptions in this way. On the other hand, for complex projects, you can find the time and energy to develop descriptions (or contact us at Professional Services). But for a large number of people who need to create relatively simple flexible descriptions, for example, accounts, payments, invoices, the new feature will be very useful: before it was necessary to study for a long time, and then adjust the description, but now it’s enough to train the program with a few (dozens ) examples - that's all.
Pavel Sokolov
Data Entry Product Department