In-memory-data-grid. Scalable Data Warehouses
Recently, interest in cloud architectures has been growing every day, as this is one of the most effective ways to scale an application without applying much effort, and the data bottleneck, in particular a relational database, is the bottleneck of any highly loaded project. To combat the disadvantages of traditional databases, 2 approaches are mainly used:
1) Caching of query execution results
2) NoSQL solutions
Today I want to introduce you to a type of data warehouse that combines the advantages of both approaches and at the same time has several advantages over the solutions mentioned above: In-memory-data-grid (IMDG) .
This approach very quickly gained wide acceptance among experts in the field of designing cloud platforms, as well as any systems that have the need for virtually unlimited scalability of storage systems. Many well-known companies have launched systems of this type on the market:
Since I'm going to talk about solutions for Java, the nodes of the IMDG cluster will be the JVM, but this article will be interesting for those who are not related to Java, because firstly, some of the popular solutions have support for several languages, and firstly secondly, even IMDG in Java can be used to quickly access data through the REST API.
This is a cluster key-value storage, which is designed for high-load projects with large data volumes and increased requirements for scalability, speed and reliability.
The main parts of IMDGs are caches (called regions in GemFire).
The cache in IMDG is a distributed associative array (i.e., the cache implements the Java interface Map), which provides fast, competitive access to data from any node in the cluster.
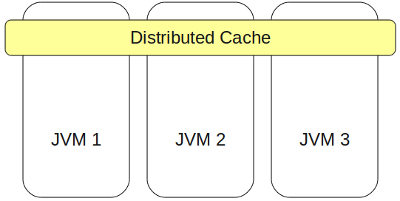
The cache also allows you to process this data in a distributed manner, i.e. modification of any data can be made from any node in the cluster, and it is not necessary to get data from the cache, change it, and then put it back.
In almost all IMDG caches, transactions are supported.
Data in caches is stored in serialized form (i.e. as an array of bytes).
All data is located in the cluster RAM, due to which access time is significantly reduced.
Because Since all data is serialized, the time it takes to retrieve an object from the cache = (the time it takes to move the object to a specific cluster node) + (the time to deserialize).
If the requested object is located on the same node on which the request is executed, then (time of receipt) = (time to deserialize). And here we see that data access could be completely free if the object did not need to be deserialized, for which the concept of near-cache was introduced into the IMDG concept.
Near-cache is a local cache of objects for quick access, all objects in it are stored ready for use. If near-cache is configured for this cache, then objects get there automatically when they get for the first time.
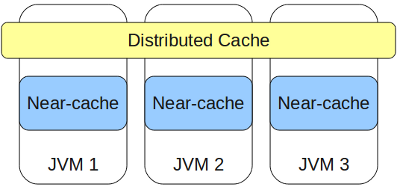
Because Since near-cache can grow to large sizes over time, as a result of which memory may run out, the following options are provided for limiting the growth in the number of cached objects:
If desired (as well as lack of memory) data can be stored in a file or in a database.
Data in the cluster is stored in partitions (parts), and these partitions are evenly distributed across the cluster, and each partition is replicated to a certain number of nodes (depending on the cluster configuration and on the requirements for reliable data storage). Hitting an object in a particular partition is uniquely determined by some hash function.
Since when working under high load, the output of an individual cluster node (or several nodes at once, if they were virtual machines within the same iron server) is not unbelievable, to ensure data safety in the cache configuration, the number of nodes is indicated, the loss of which the cluster should painlessly survive. This indicator determines the number of copies of each partition.

Those. if we indicate that the loss of 2 nodes should not lead to data loss, then each partition will be stored on 3 different nodes of the cluster, and if 2 nodes fall, the data will remain intact. If more than one node remains in the cluster, then 3 copies of all data will be created again, and the cluster will be ready for new troubles.
The composition of the cluster (the number of nodes) can change without stopping the operation of the entire cluster, and the correct operation of the cluster and the consistency and availability of data are monitored by the grid itself without any intervention by the programmer. Those. with an increasing load or volume of data, you can simply raise a few more configured nodes that will automatically join the cluster, and the data inside the cluster itself will be rebalanced to evenly distribute data among the nodes, while the amount of data transferred will be minimal so as not to create an extra load on the network .
When using IMDG, you always get the latest data. when put is executed, a notification is sent to all nodes of the cluster that objects with certain keys have received a new value. Each node updates its partitions containing these keys and removes old values from its near-cache.
IMDG can be used not only as a standalone storage, but also as a system node that unloads a difficult-to-scale relational database.

To read and write from / to the database, for each cache in the configuration, Loader is specified, which will be responsible for reading / writing objects to the database.
Several options for organizing data access are possible:
Options for writing to the database when changing the relevant data:
In the case of using IMDG as a node that takes all the burden of reading / writing / distributed data processing, we continue to have up-to-date data in the database, low load on the database itself and, which is very important, corporate applications that use databases to collect statistics, reporting, etc. continue to work in the same condition.
In-memory-data-grid is a relatively young, but well-established technology, the development of which is carried out by many large vendors. It combines the advantages of NoSQL and caching systems, eliminates some of their significant shortcomings and allows you to raise system performance to a new level. If this article seemed interesting to you, then I will be glad to tell you next time about a specific solution from the IMDG family, as well as touch upon the issues of building and using indexes, serialization mechanisms and interaction with other platforms in these systems.
UPD: next article
1) Caching of query execution results
- pluses: high speed data access
- cons: requires a compromise between the relevance of the data and the speed of access, because data in the cache may become outdated, and deleting old data from the cache and then caching new ones is additional delays and system load
2) NoSQL solutions
- pluses: good horizontal scalability, domain data model coincides with the data storage model
- cons: low speed of obtaining results in case of using a disk; it is practically impossible to ensure the operation of internal corporate software that is oriented to work with a specific relational database.
Today I want to introduce you to a type of data warehouse that combines the advantages of both approaches and at the same time has several advantages over the solutions mentioned above: In-memory-data-grid (IMDG) .
This approach very quickly gained wide acceptance among experts in the field of designing cloud platforms, as well as any systems that have the need for virtually unlimited scalability of storage systems. Many well-known companies have launched systems of this type on the market:
- Oracle Coherence - Java / C / .NET
- VMWare Gemfire - Java
- GigaSpaces - Java / C / .NET
- JBoss (RedHat) Infinispan - Java
- Terracota - Java
Since I'm going to talk about solutions for Java, the nodes of the IMDG cluster will be the JVM, but this article will be interesting for those who are not related to Java, because firstly, some of the popular solutions have support for several languages, and firstly secondly, even IMDG in Java can be used to quickly access data through the REST API.
So what is in-memory-data-grid?
This is a cluster key-value storage, which is designed for high-load projects with large data volumes and increased requirements for scalability, speed and reliability.
The main parts of IMDGs are caches (called regions in GemFire).
The cache in IMDG is a distributed associative array (i.e., the cache implements the Java interface Map), which provides fast, competitive access to data from any node in the cluster.
The cache also allows you to process this data in a distributed manner, i.e. modification of any data can be made from any node in the cluster, and it is not necessary to get data from the cache, change it, and then put it back.
In almost all IMDG caches, transactions are supported.
Data in caches is stored in serialized form (i.e. as an array of bytes).
1. Speed
All data is located in the cluster RAM, due to which access time is significantly reduced.
Because Since all data is serialized, the time it takes to retrieve an object from the cache = (the time it takes to move the object to a specific cluster node) + (the time to deserialize).
If the requested object is located on the same node on which the request is executed, then (time of receipt) = (time to deserialize). And here we see that data access could be completely free if the object did not need to be deserialized, for which the concept of near-cache was introduced into the IMDG concept.
Near-cache is a local cache of objects for quick access, all objects in it are stored ready for use. If near-cache is configured for this cache, then objects get there automatically when they get for the first time.
Because Since near-cache can grow to large sizes over time, as a result of which memory may run out, the following options are provided for limiting the growth in the number of cached objects:
- expiration - object lifetime in cache
- eviction - delete an object from the cache
- limit on the number of stored objects
If desired (as well as lack of memory) data can be stored in a file or in a database.
2. Reliability
Data in the cluster is stored in partitions (parts), and these partitions are evenly distributed across the cluster, and each partition is replicated to a certain number of nodes (depending on the cluster configuration and on the requirements for reliable data storage). Hitting an object in a particular partition is uniquely determined by some hash function.
Since when working under high load, the output of an individual cluster node (or several nodes at once, if they were virtual machines within the same iron server) is not unbelievable, to ensure data safety in the cache configuration, the number of nodes is indicated, the loss of which the cluster should painlessly survive. This indicator determines the number of copies of each partition.
Those. if we indicate that the loss of 2 nodes should not lead to data loss, then each partition will be stored on 3 different nodes of the cluster, and if 2 nodes fall, the data will remain intact. If more than one node remains in the cluster, then 3 copies of all data will be created again, and the cluster will be ready for new troubles.
3. Scalability
The composition of the cluster (the number of nodes) can change without stopping the operation of the entire cluster, and the correct operation of the cluster and the consistency and availability of data are monitored by the grid itself without any intervention by the programmer. Those. with an increasing load or volume of data, you can simply raise a few more configured nodes that will automatically join the cluster, and the data inside the cluster itself will be rebalanced to evenly distribute data among the nodes, while the amount of data transferred will be minimal so as not to create an extra load on the network .
4. Relevance of data
When using IMDG, you always get the latest data. when put is executed, a notification is sent to all nodes of the cluster that objects with certain keys have received a new value. Each node updates its partitions containing these keys and removes old values from its near-cache.
5. Reducing the load on the database
IMDG can be used not only as a standalone storage, but also as a system node that unloads a difficult-to-scale relational database.
To read and write from / to the database, for each cache in the configuration, Loader is specified, which will be responsible for reading / writing objects to the database.
Several options for organizing data access are possible:
- during application launch, suck all the necessary data from the database into the grid (the so-called preloading). Application up time is increasing, memory consumption is also, but the speed of work is growing
- while the application is running, pull the necessary data according to client requests (read-through). It is executed automatically using the Loader object for this cache. The application recovery time is short, the initial memory costs are also, but the additional time costs for processing requests that cause read-through
Options for writing to the database when changing the relevant data:
- with each put operation in the cache, the database is automatically written to the database using Loader (the so-called write-behind). Only suitable for systems whose main load is caused by reading.
- data waiting to be written to the database is accumulated, and then one request is made to write to the database. A signal to execute such a request can be a certain amount of data waiting for recording, or a timeout. Suitable for write-intensive systems, but more difficult to implement
In the case of using IMDG as a node that takes all the burden of reading / writing / distributed data processing, we continue to have up-to-date data in the database, low load on the database itself and, which is very important, corporate applications that use databases to collect statistics, reporting, etc. continue to work in the same condition.
Conclusion
In-memory-data-grid is a relatively young, but well-established technology, the development of which is carried out by many large vendors. It combines the advantages of NoSQL and caching systems, eliminates some of their significant shortcomings and allows you to raise system performance to a new level. If this article seemed interesting to you, then I will be glad to tell you next time about a specific solution from the IMDG family, as well as touch upon the issues of building and using indexes, serialization mechanisms and interaction with other platforms in these systems.
UPD: next article