DeepMind taught AI to play YouTube videos
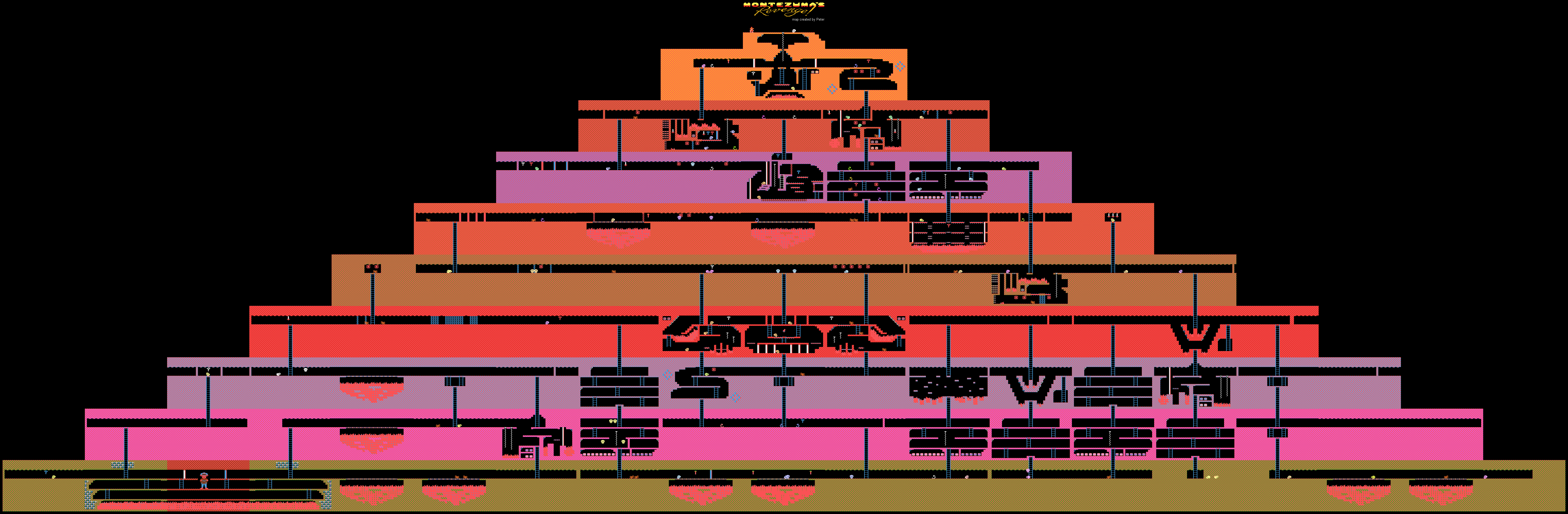
Montezuma's Revenge game levels at Atari
. DeepMind demonstrated the process of learning AI (a weak form) for playing games at Atari. The training was carried out by demonstrating the video game passing system from YouTube. This method is used by many human players who, for one reason or another, could not get through some kind of game.
Usually, to solve such a problem, it is necessary to use the so-called reinforcement learning method . This technique is quite popular because it allows you to train bots to perform various specific tasks. As soon as the system achieves any result, it receives a small reward.
Developers create algorithms and models that are able to evaluate the game environment, including possible rewards for passing (points, bonuses, etc.). Such systems study the game step by step, gradually moving towards the final.
The new method developed in DeepMind is different from all others. Specialists of the company were able to teach AI to run such games under Atari, like Montezuma's Revenge, Pitfall and Private Eye. At the same time, the emphasis on points and prizes was not made - the training went on tutorials from YouTube. And this made it possible to achieve unusual results for AI.
The fact is that games like the same Montezuma's Revenge are difficult for machines to “understand”. There is no clear assignment, it is not clear where to go, what items to collect and what to do with them in the future. The machine is simply lost, because in the process of advancement it does not receive awards and training with reinforcements here becomes useless or almost useless.
In the game in question, you need to control a character named Panama Joe. As a result, he must get to the treasury in the old temple. According to legend, these treasures belong to Montezuma. First you need to find the first critically important object for the passing game - the golden key. To find it you need to go about 100 steps. But this is if you know what to do. If not - there is a huge amount of opportunity. 100 18initial action. This is too much for any man-made AI. Well, you will not get a reward here, everything is very, very specific.
One of the ways to let the computer know what to do is to demonstrate passing scripts. Actually, not only cars, but also people learn to perform all sorts of tasks according to examples. Dancing, artist's actions, rations - all this is best to see 1 time, and not 100 times to hear how to do it.
In DeepMind came to the opinion that this is the best way to show the way to the computer task implicitly result. The technology created by the experts really helped. For example, two methods were used: TDC (temporal distance classification) and CDC (cross-modal temporal distance classification).
In the first case, the AI is trained to determine the distance in the gaming environment, to notice the difference between two different frames. The AI also “understands” what to do in order to move from one place to another. For learning on YouTube, videos are framed in random order.
In the second case, the “understanding” of the soundtrack is also added. Sounds in almost all games correspond to the performance of certain actions. For example, jumping, getting items, etc. Thus, the computer is trained to perceive sounds as important game elements. Video + sound allows the computer to move very well in the process of passing the game.
Here are the actions of the trained AI in Montezuma's Revenge. Passage of the other two games, mentioned at the very beginning - here .
True, it was not possible to completely reject the role of rewards - the AI still depends on the same points. But the usual method of teaching the system, which was used earlier, did not allow to reach at least the golden key, for which the first hundred points are given. So the AI, like a blind kitten, poked in all directions, not understanding what to do. True, the system of "reinforcement" is also modified.
In the process of passing, every 16th video frame of the recording of the passage of the AI game is compared with frames of the video of the passing game by people. If the comparison shows a high degree of similarity, then the AI receives an award. Over time, the AI begins to perform the same sequence of actions as the person in order to get a similar frame.
Moreover, AI in many cases shows better results than human players or other passing algorithms, including Rainbow, ApeX, and DQfD.
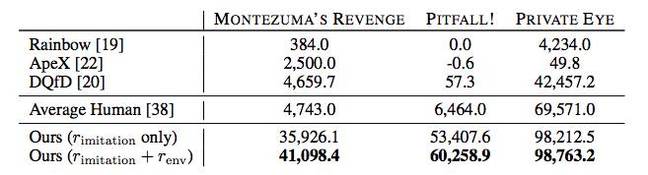
In principle, all this is impressive, but so far the practical benefits of the achievements of DeepMind are unclear. Is it possible to use the method of teaching AI proposed by the company somewhere other than passing old games? But knowing about the achievements of DeepMind in the field of AI, there is no doubt that one way or another, all this can be used for practical purposes - experts would hardly have started working on the issue for the “fan”.