How to build fraud protection across the corporation. Lecture at YaC 2018
May 29, was held Yet Another Conference 2018 - the annual and largest conference of Yandex. At YaC this year there were three sections: about marketing technologies, smart city and information security. Hot on the heels we publish one of the key reports of the third section - from Yury Leonychev tracer0tong from the Japanese company Rakuten.
- I work in an international corporation Rakuten. I want to talk about a few things: a little about yourself, about our company, about how to evaluate the cost of attacks and understand whether you need to do fraud prevention. I want to tell you how we collected our fraud prevention and which models we used gave good results in practice, how they worked and what can be done to prevent fraud attacks.

About me briefly. He worked at Yandex, was engaged in web application security, and in Yandex also once made a system to prevent fraud attacks. I can develop distributed services, I have a bit of a mathematical background, which helps with the use of machine learning in practice.
Rakuten is not very well known in the Russian Federation, but I think you all know it for two reasons. Of the more than 70 of our services in Russia, Rakuten Viber is known, and if there are football fans here, you may know that our company is the general sponsor of the Barcelona football club.
Since we have a lot of services, we have our own payment systems, our own credit cards, a lot of reward programs, we are constantly under attack by intruders. And of course, we always have a request from a business for fraud protection systems.
When a business asks us to make a fraud protection system, we are always faced with some dilemma. On the one hand, there is a request for a high conversion rate, so that the user can conveniently authenticate on services, make purchases. And from our side, on the part of the security men, I want to have fewer complaints, fewer accounts have been hacked. And we, for our part, want to make the attack price high.
If you buy the fraud prevention system or try to do it yourself, you first need to estimate the costs.

Do we think we need fraud prevention? We relied on the fact that we have some types of financial losses from fraud. These are direct losses - money that you will return to your customers if they have been stolen by intruders. These are the costs of technical support service, which will communicate with users, resolve conflict issues. This is a return of goods that are very often delivered to unreal addresses. And there is a direct cost to develop the system. If you made a fraud protection system, deployed it on some servers, you will pay for the infrastructure, for software development. And there is a third very important aspect of damage from the attackers - lost profits. It consists of several components.
According to our calculations, there is a very important parameter - lifetime value, LTV, that is, the money that the user spends in our services, is significantly reduced. Because in half of the fraud cases, users simply leave your service and do not return.
We also pay money for advertising, and if the user is gone, they are lost. This is customer acquisition cost, CAC. And if we have a lot of automated users who are not real people - we have false real numbers monthly active users, MAU, which also affect the business.
Let's look from the other side, from the side of the attackers.
Some speakers said that attackers are actively using botnets. But whatever method they use, they still need to invest money, pay for the attack, they also spend some money. Our task, when we make fraud prevention system, is to find such a balance so that the attacker spends too much money, and we spend less. This makes the attack on us unprofitable, and the attackers simply go to break another service.

For our damage services, we divided attacks into four types. These are targeted when they try to hack one account, one account. Attacks perpetrated by a single user or a small group of individuals. Or more dangerous for us, the attacks are massive and non-targeted, when the attackers attack a lot of accounts, credit cards, phone numbers, etc.

I'll tell you what is happening, how we are attacked. The main most obvious type of attack that everyone knows about is brute force. In our case, the attackers are trying to sort through phone numbers, trying to validate credit card numbers. Some variety is present.
Mass registration of accounts, for us it is obviously harmful. I will give an example later.
What is registered? Fake accounts, some non-existent goods, try to spam in feedback messages. I think this is relevant and similar for many commercial companies.
There are still not obvious problems for e-commerce, but problems obvious to Yandex - attacks on the advertising budget, click fraud. Well, or just the theft of personal data.

I will give an example. We had a rather interesting attack on a service that sells e-books, there was an opportunity for any user to register and start selling their electronic work, such an opportunity to support novice writers.
The attacker registered one legal account master, and several thousand unreal minion accounts. And generated a fake book, just from random sentences, there was no point in it. He put it on the marketplace, and we had a marketing company, each minion had, conditionally, 1 dollar, which he could spend on a book. And this fake book was worth $ 1.
A raid of minions was organized - fake accounts. They all bought this book, the book jumped in the ratings, became a bestseller, the attacker raised the price to a conditional 10 dollars. And since the book became a bestseller, ordinary people began to buy it, and complaints about the fact that we were selling some low-quality goods, a book with a meaningless set of words inside, began to fall on us. The attacker received a profit.
There is no ninth point; the police later arrested him. So the profit did not go in store.
The main goal of all intruders in our case is to spend as little of our money as possible and take ours as much as possible.

There are attackers, one person who is just trying to get around business logic. But I’ll note that we don’t consider such attacks to be a priority for us, because by the ratio of the number of hacked accounts and the stolen money they carry a low risk for us. And the main problem for us is botnets.

These are massive distributed systems, they attack our services from all over the world, from different continents, but they have some features that make it easier to fight them. As in any large distributed system, botnet nodes perform more or less the same tasks.
Another important thing is that now, as many colleagues have pointed out, botnets are spreading to all sorts of smart devices, home routers, smart speakers, etc. But these devices have low hardware specifications and cannot perform complex scripts.
On the other hand, for an intruder, renting a botnet for a simple DDoS is cheap enough for brute-force account credentials, too. But if you need to implement some kind of business logic specifically for your application or service, the development and support of a botnet becomes very expensive. Usually, the attacker simply rents a part of the finished botnet.
I always attack botnets associated with the parade of Pikachu in Yokohama. We have 95% of malicious traffic coming from botnets.
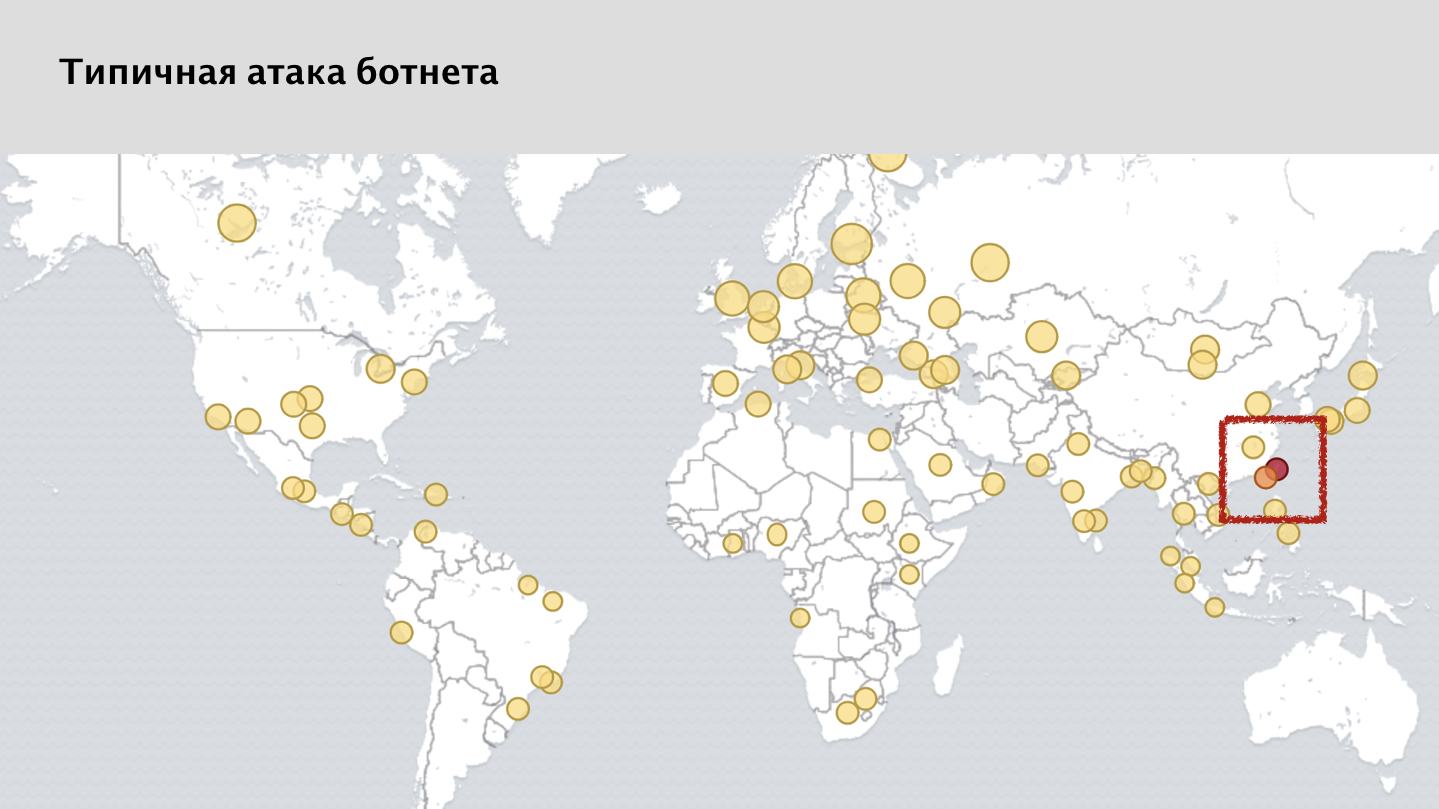
If you look at the screenshot of our monitoring system, you will see a lot of yellow spots - these are blocked requests from various nodes. And here the attentive person may notice that I kind of said that the attack is evenly distributed around the globe. But on the map there is a clear anomaly, a red spot in the area of Taiwan. This is a rather curious case.
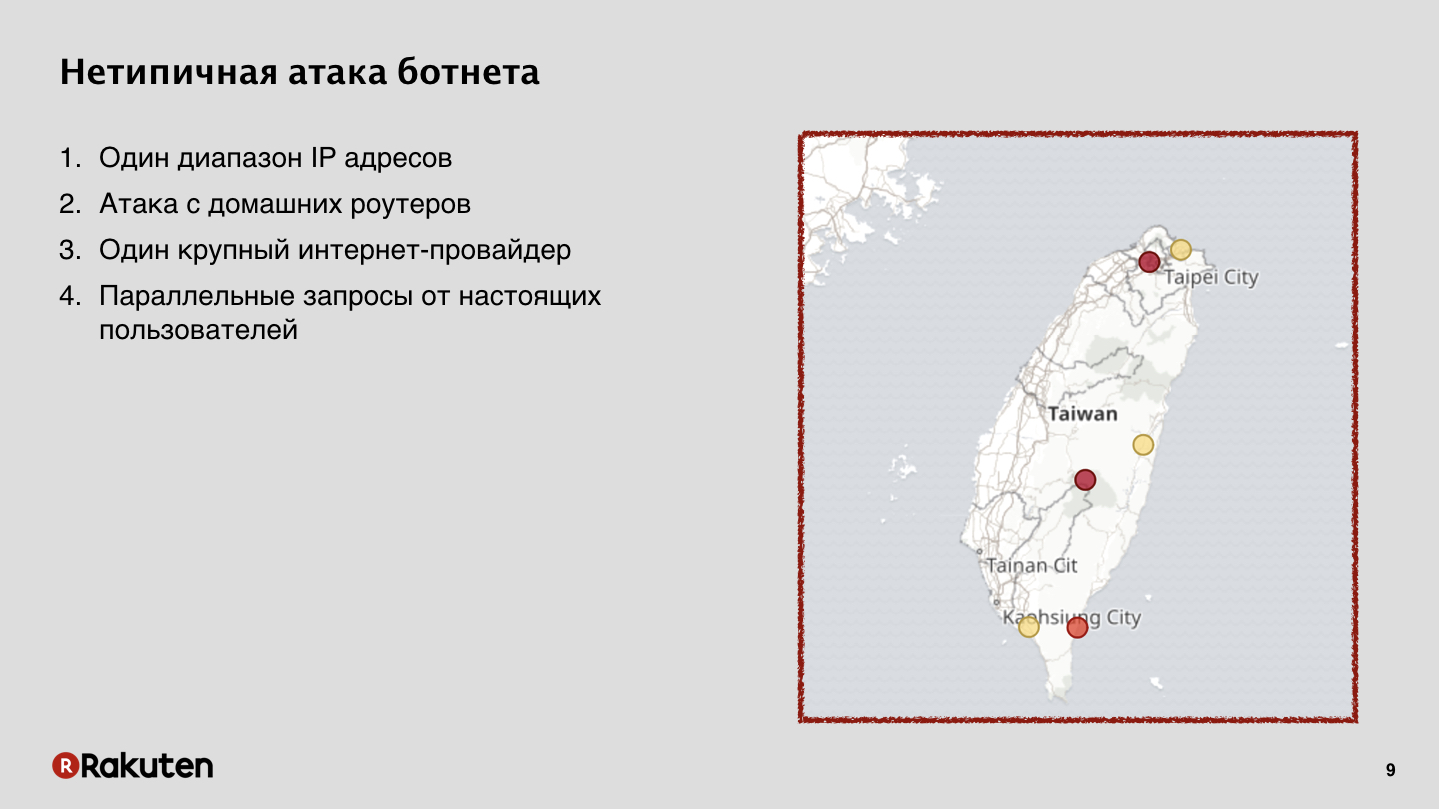
This attack came from home routers. In Taiwan, a major Internet provider was hacked, which provided Internet for most of the island’s inhabitants. And for us it was a very big problem, due to the fact that a lot of legal users at the same time when the attack occurred, from the same IP addresses went and worked with our services. We stopped this attack successfully, but it was very difficult.
If we talk about skoupe, about the surface, about what we protect. If you have a small e-commerce website or a small regional service, you have no particular problems. You have a server, maybe a few, or virtual machines in the cloud. Well, users, bad, good, who come to you. There is no particular problem to protect.
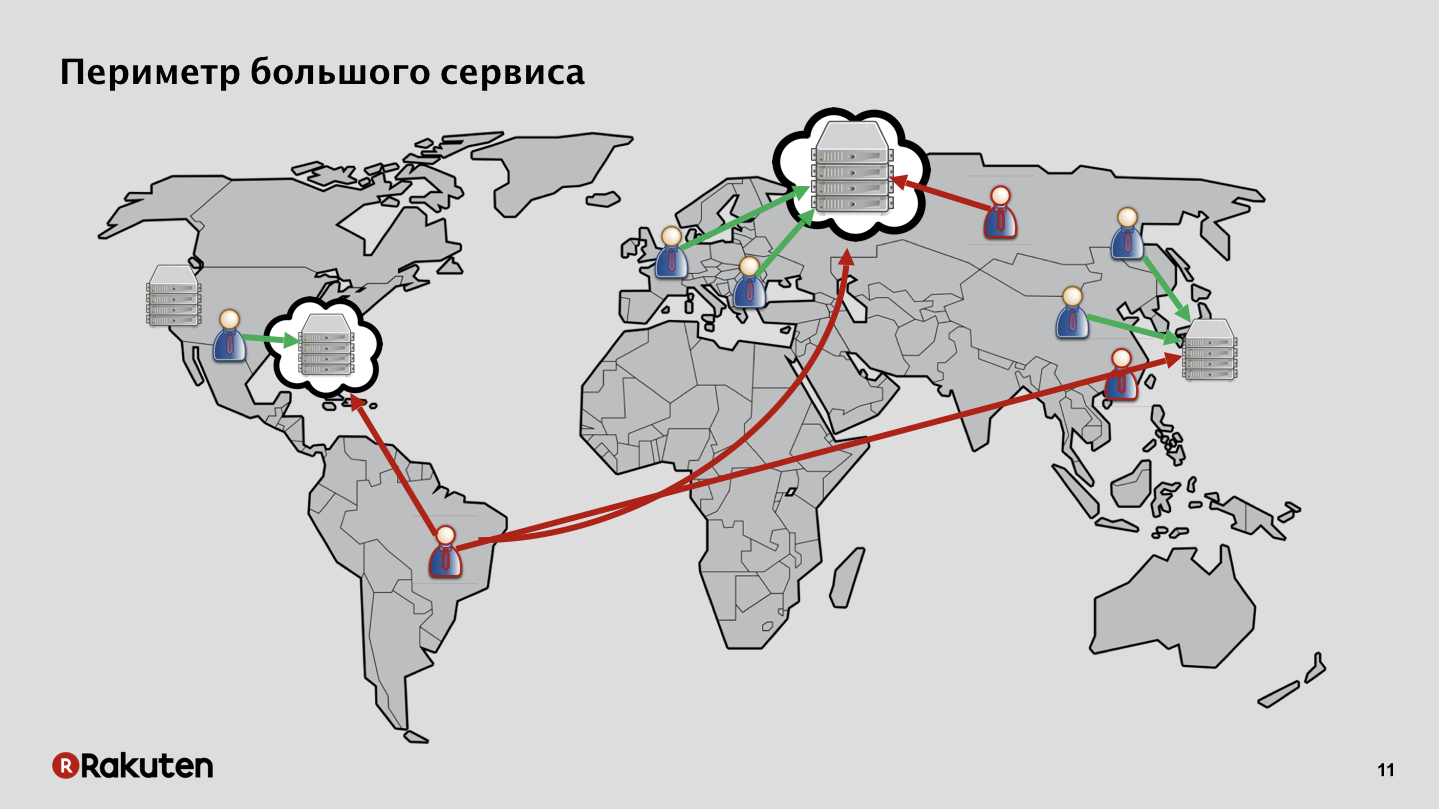
In our case, everything is more complicated, the attack surface is huge. We have services deployed in our own data centers, in Europe, in Southeast Asia, in the USA. We also have users on different continents, both good and bad. Plus, some services are deployed in the cloud infrastructure, and not our own.
With so many services and such an extensive infrastructure, it is very difficult to defend yourself. Plus, many of our services support various types of client applications and interfaces. For example, we have the service Rakuten TV, which runs on smart TVs, and for him the protection is completely special.

To sum up the problem, a huge number of users circulate in your system, like people at a store at a crossroads in Shibuya. And among this multitude of people it is necessary to identify and catch the attackers. And there are a lot of doors in your store, and even more people.
So, from what and how did we assemble our system?
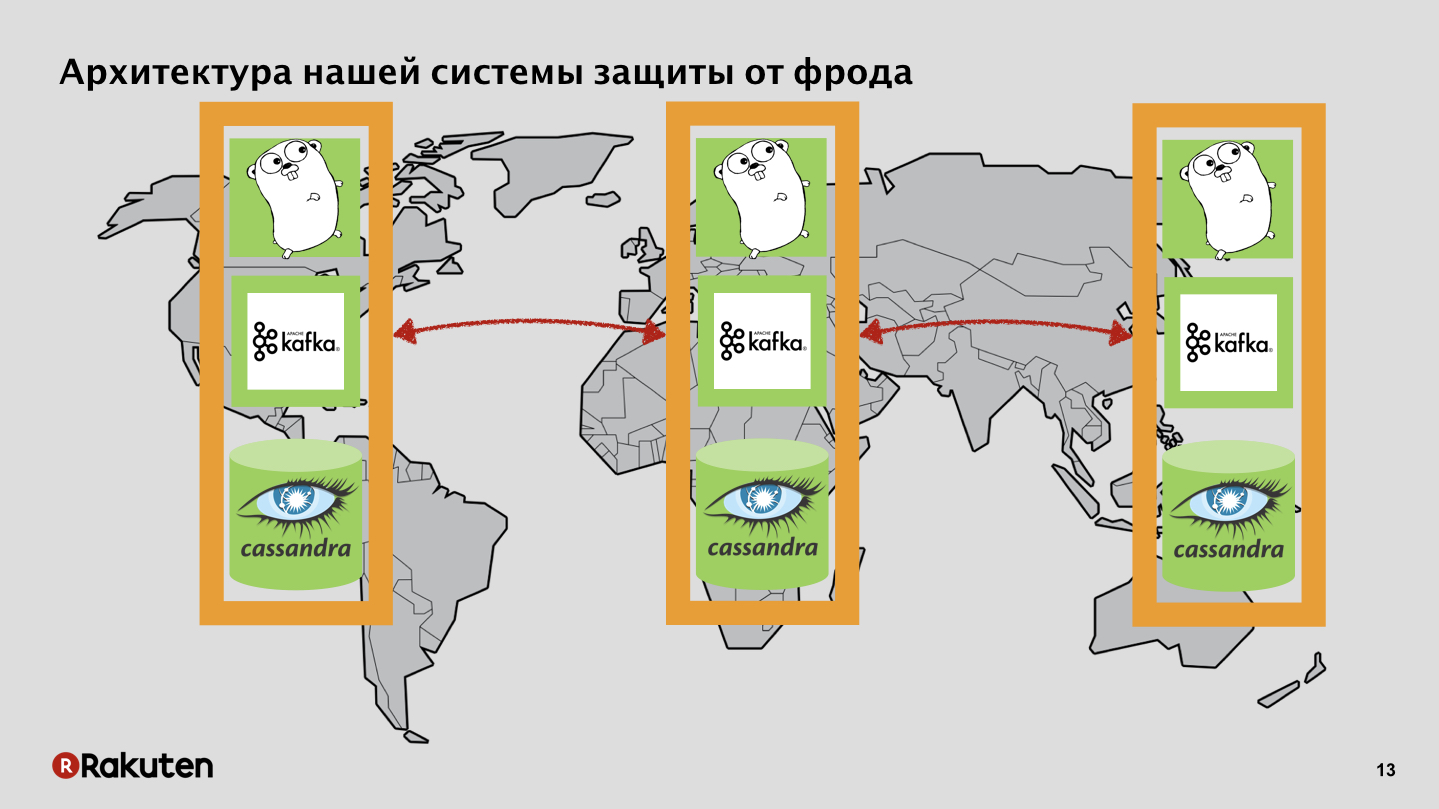
We managed to use only open source components, it was quite cheap. Used the power of many "gophers". Much of the software was written in Golang. Used message queues and databases. Why do we need it? We pursued two goals: collecting data on user behavior and calculating reputation, carrying out some actions to recognize whether a user is good or bad.
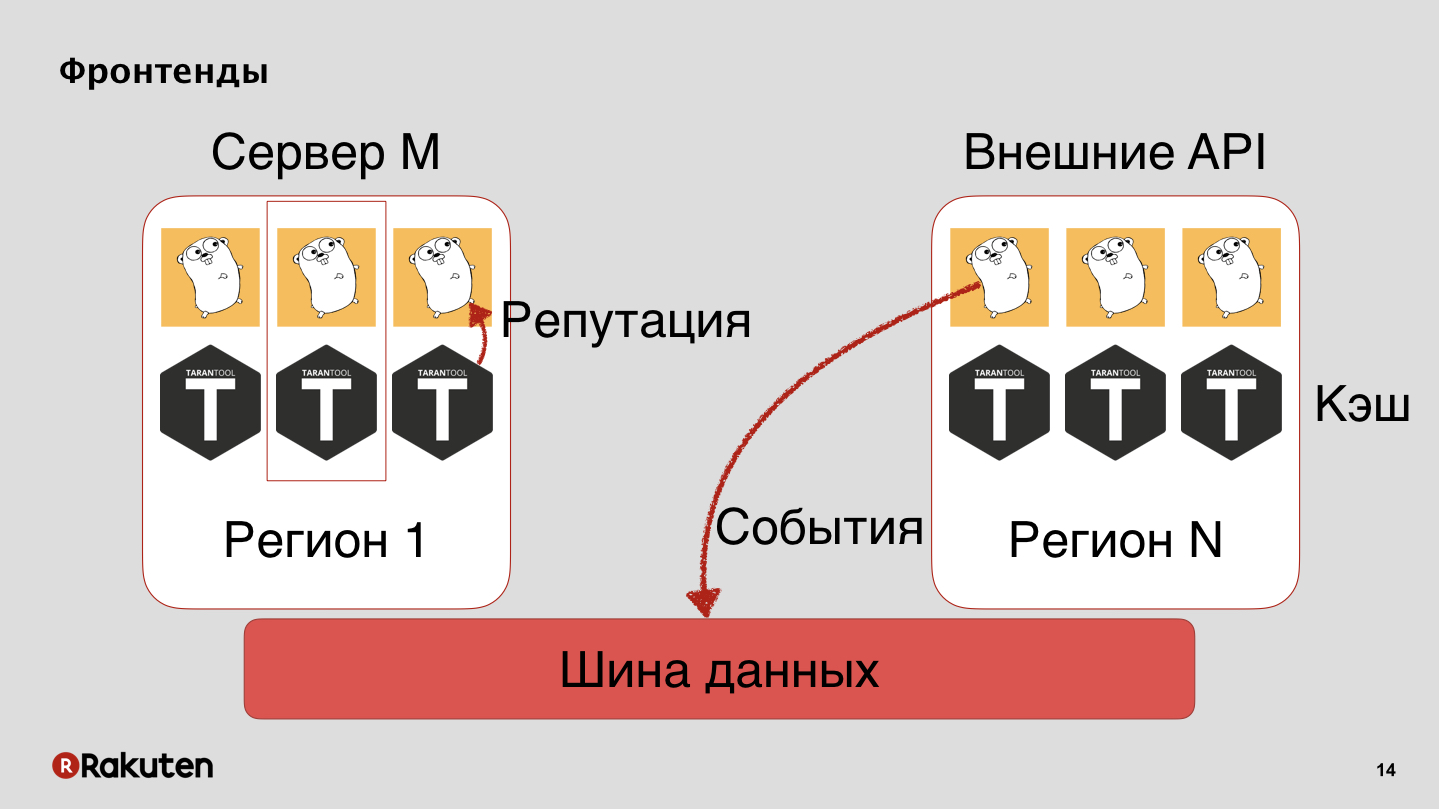
We have many levels in the system, we use frontends written in Golang, and Tarantool is our caching base. Our system is deployed in all regions where our businesses are located. Events we pass on the data bus, from it we get a reputation.
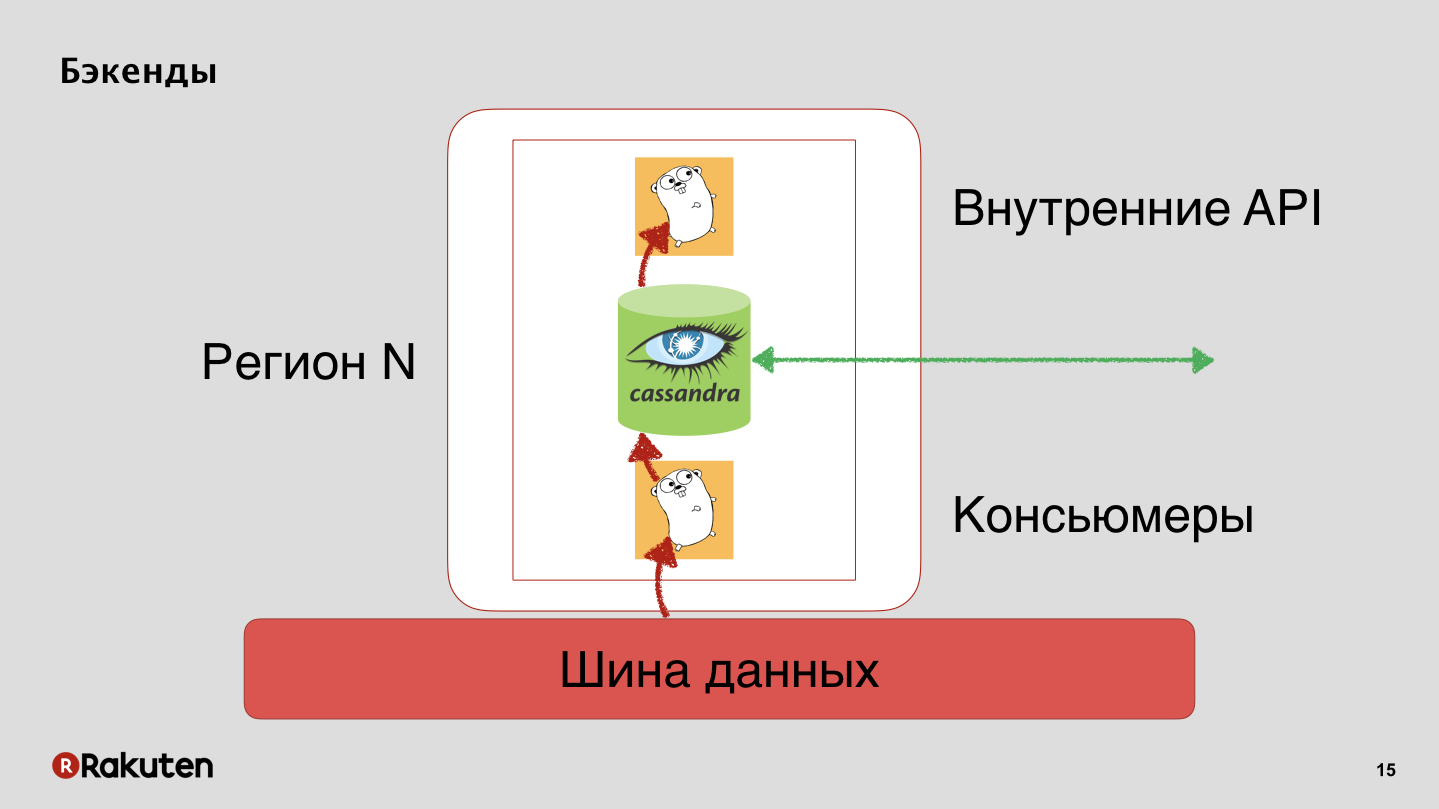
We have backends that also replicate user reputation with Cassandra.
Data Bus, Nothing Secret, Apache Kafka.
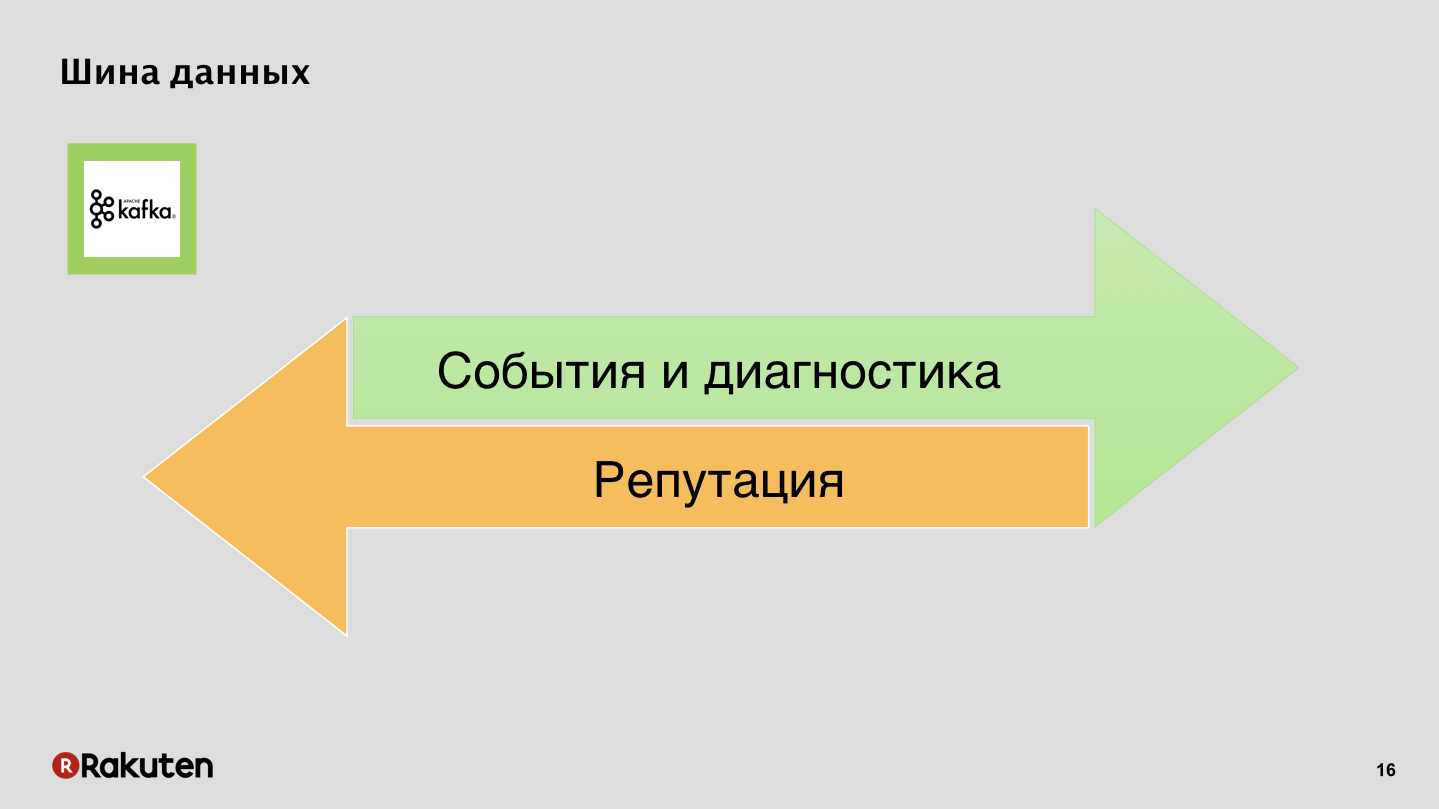
Events and logs in one direction, reputation in another.
And of course, the system has a brain that thinks a bad user or a good one, a bad one is activity or a good one. The brain is built on the Apache Storm, and the most interesting thing is what happens inside there.
But first I’ll tell you how we collect data and how we block intruders.
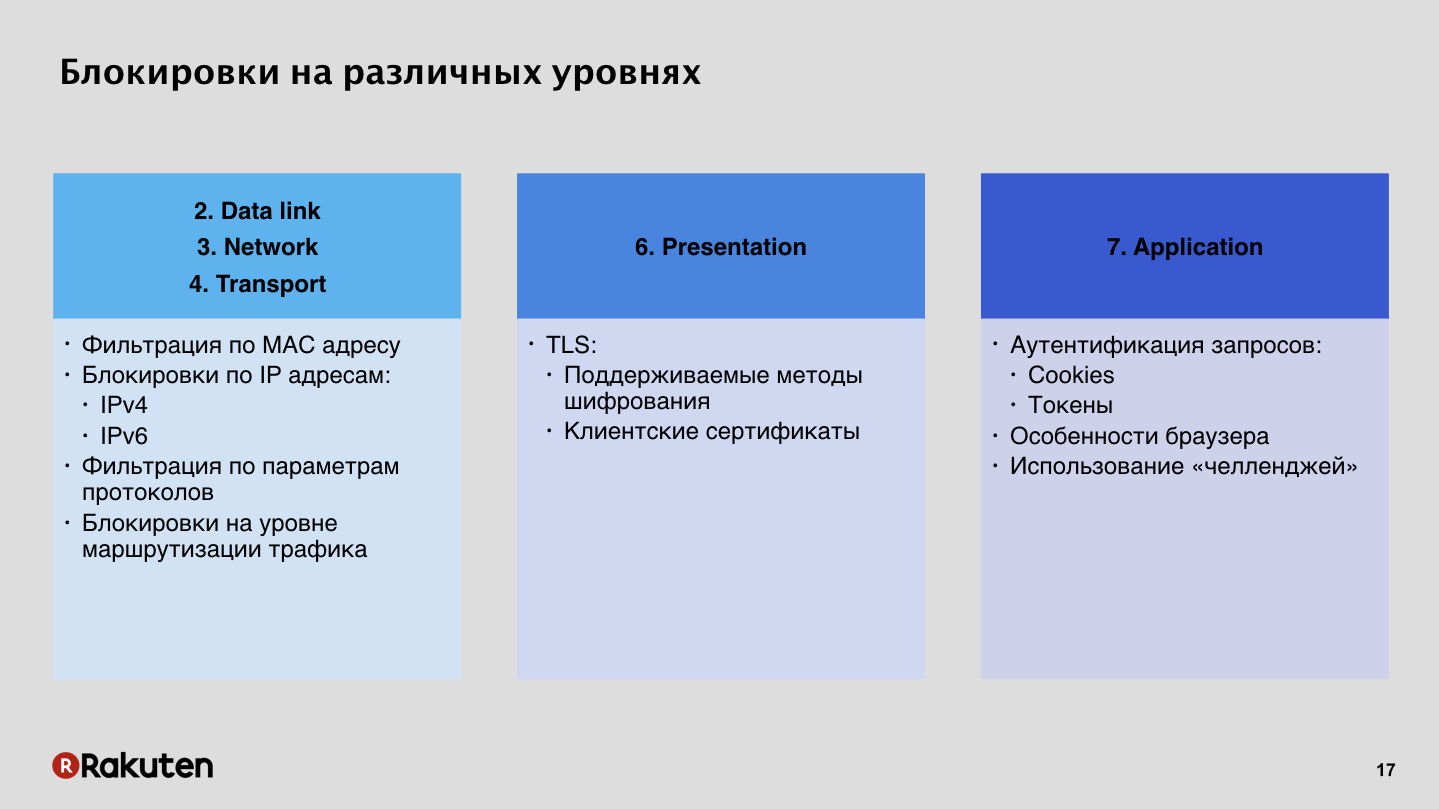
There are many approaches here. Some of them were already mentioned by colleagues from Yandex in their first report. How to block intruders? Anton Karpov said that firewalls are bad, we don’t like them. Indeed, it is possible to block by IP addresses, the topic for Russia is very relevant, but this method does not suit us at all. We prefer to use higher-level locks, at the seventh level, at the application level, using request authentication using tokens, session cookies.
Why? Let's look first at locks at a low level.
This is a cheap way, everyone knows how to use it, everyone has firewalls on the servers. A bunch of instructions on the Internet, there are no problems to block a user by IP. But when you block a user at a low level, he does not have the ability to somehow bypass your protection system, if it was a false positive. Modern browsers are more or less trying to show some beautiful error message to the user, but anyway, a person cannot get around your system, because an ordinary user cannot arbitrarily change their IP addresses. Therefore, we believe that this method is not very good and unfriendly. And plus IPv6 walks around the planet, if you have any tables blocked, then after a while the search for addresses on such tables will take a very long time, and there is no future for such locks.

Our method is locking at the top level. We prefer to authenticate requests, because for us this is an opportunity to adapt very flexibly to the business logic of our applications. Such methods have advantages and disadvantages. The disadvantage is the high cost of development, a large amount of resources that you have to invest in infrastructure, and the architecture of such systems, for all its apparent simplicity, is still complex.
You heard on previous reports about various methods based on biometrics, data collection. Naturally, we also think about this, but it’s very easy to break the user's privacy by collecting the wrong data that the user wants to entrust to you.
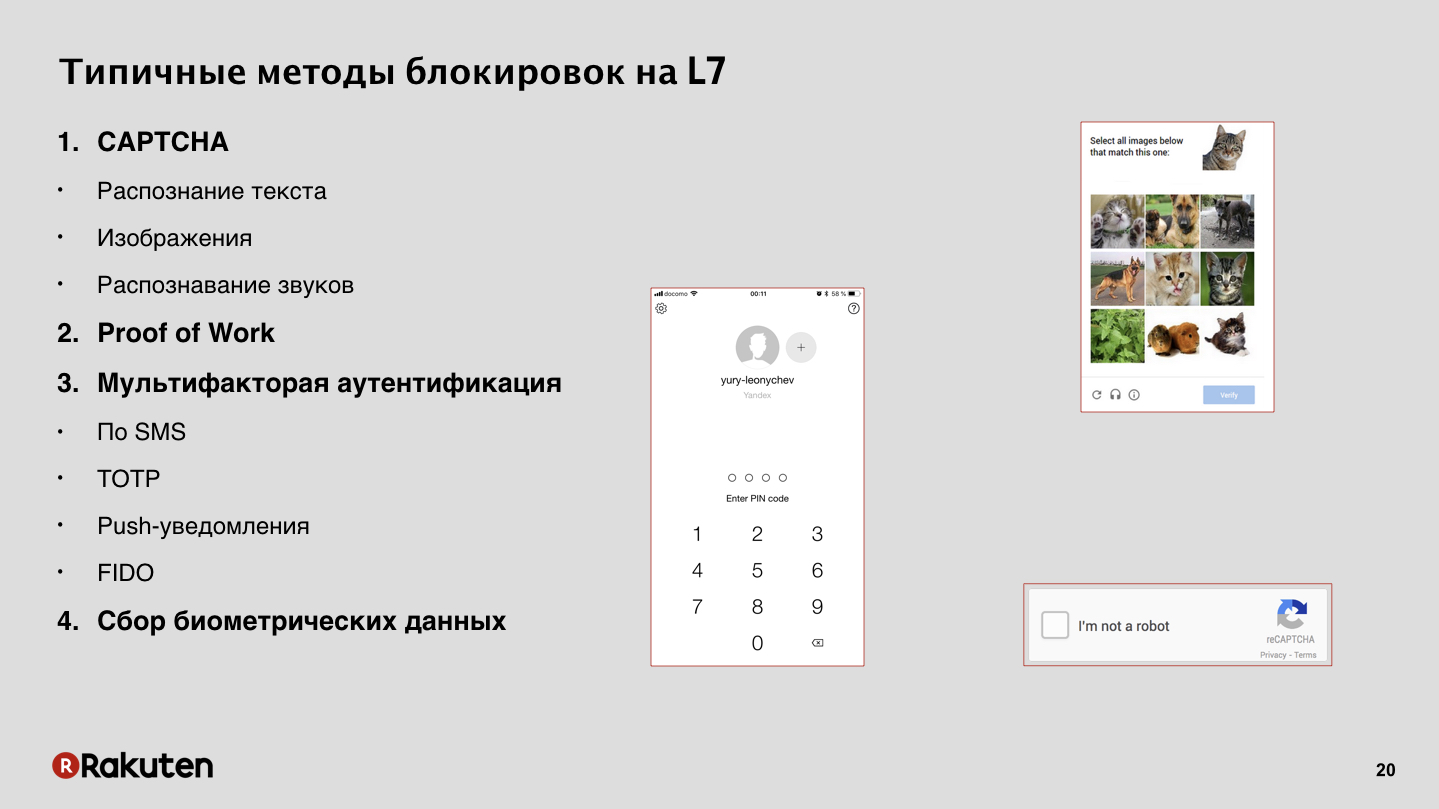
How do we authenticate? In our case, there is nothing extraordinary, but I want to mention one method. In addition to traditional types - captcha and one-time passwords - we use Proof of Work, PoW. No, we do not mine bitcoins on users' computers. We use PoW to slow down an attacker and sometimes even block completely, forcing him to solve a very difficult task, on which he spends a lot of time.
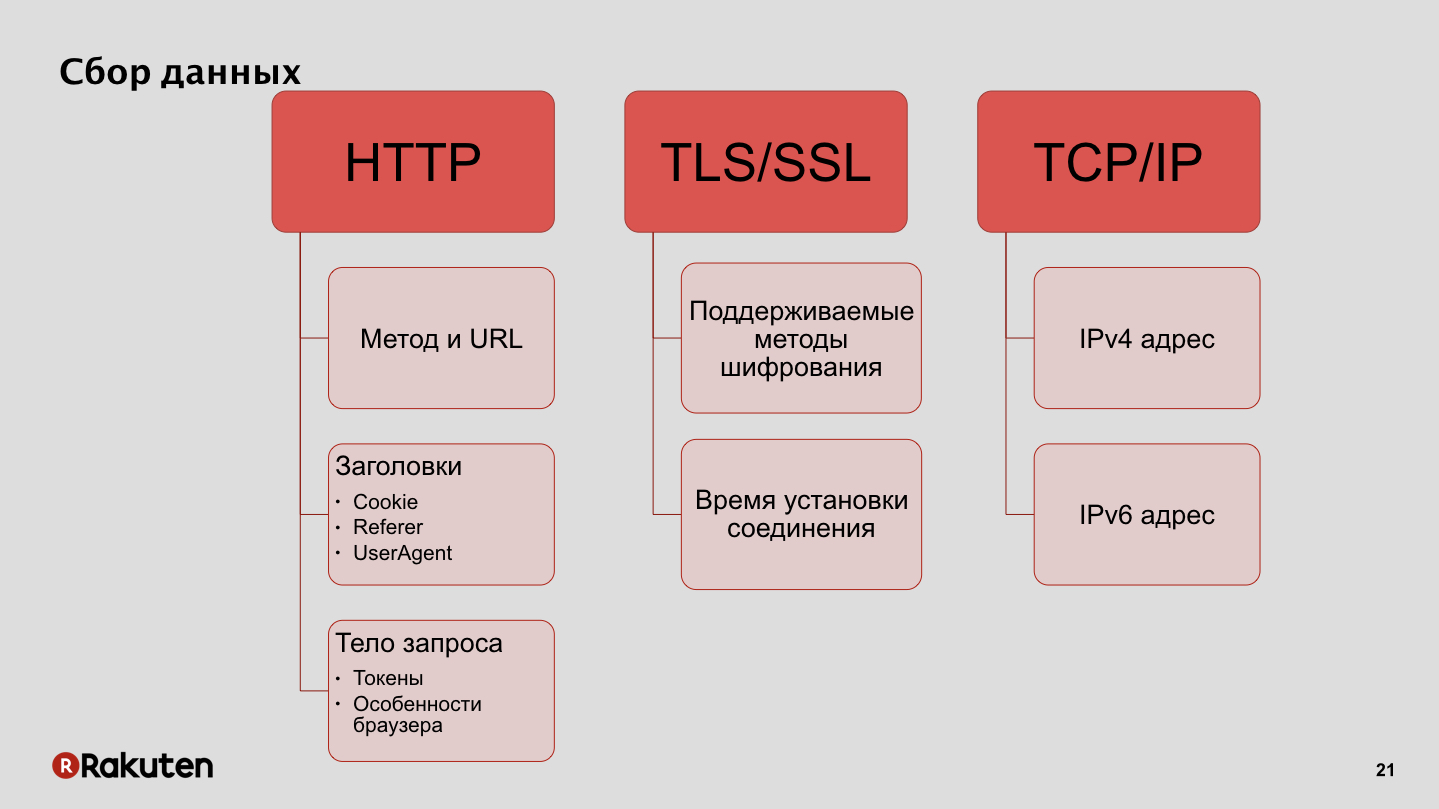
How do we collect data? We use IP addresses as one of the features, as well as one of the data sources for us are encryption protocols supported by clients and connection establishment time. Also, the data that we collect from user browsers, the features of these browsers, and of the tokens that we use to authenticate requests.
How to detect intruders? Probably, you expect me to say that we built a huge neural network and immediately caught everyone. Not really. We used a multi-level approach. This is due to the fact that we have a lot of services, very large volumes of traffic, and if you try to install a complex computing system for such volumes of traffic, it will most likely be very expensive and will slow down the work of services. Therefore, we started with a banal simple method: we began to consider how many requests come from different addresses, from different browsers.

This method is very primitive, but allows you to weed out stupid massive DDoS attacks, when you have pronounced anomalies appear in traffic. In this case, you are absolutely sure that this is an attacker, and you can block it. But this method is suitable only at the initial level, because it prevents only the roughest attacks.
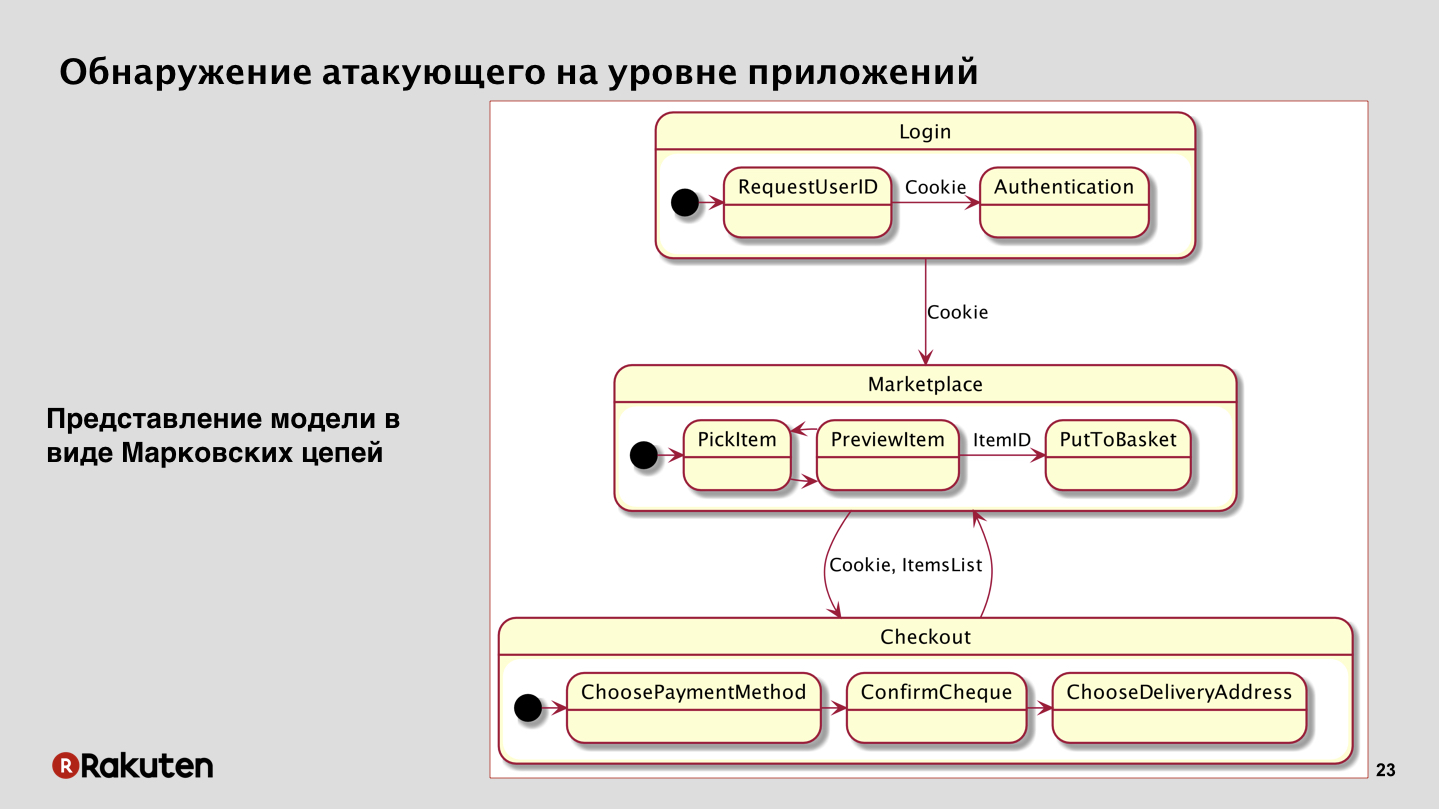
After that we come to the next method. We decided to focus on the fact that we have the business logic of applications, and the attacker can never just come to your service and steal money. If he didn't hack it, of course. In our case, if you look at the most simplified scheme of some abstract marketplace, we will see that the user must log in first, present his credentials, get session cookies, then go to the marketplace, search for products there, put them in the basket. After that, he proceeds to pay for the purchase, selects the address, payment method, and in the end he presses "pay", and finally the purchase of goods takes place.
You can see that the attacker must take many steps. And these transitions between states, between services resemble one mathematical model - these are Markov chains, which can also be used here. In principle, in our case they showed very good results.

I can give a simplified example. Roughly speaking, there is a moment when a user is authenticated, when he selects purchases and makes a payment, and for example, it’s obvious how an attacker can behave abnormally himself, he may try several times to log in with different accounts. Or he may add the wrong items to the cart that regular users buy. Or performs some abnormally large number of actions.
In Markov chains, states are usually considered. We also decided to add time to these states. Malefactors and normal users in time behave completely differently, and it also helps to separate them.
Markov chains are a fairly simple mathematical model, they are very easy to read on the fly, so they allow you to add another level of protection, weed out some more traffic.
Next stage. We caught the intruders stupid, caught the intruders of the average mind. Now there are the most intelligent. For cunning intruders, additional features are needed. What we can do?
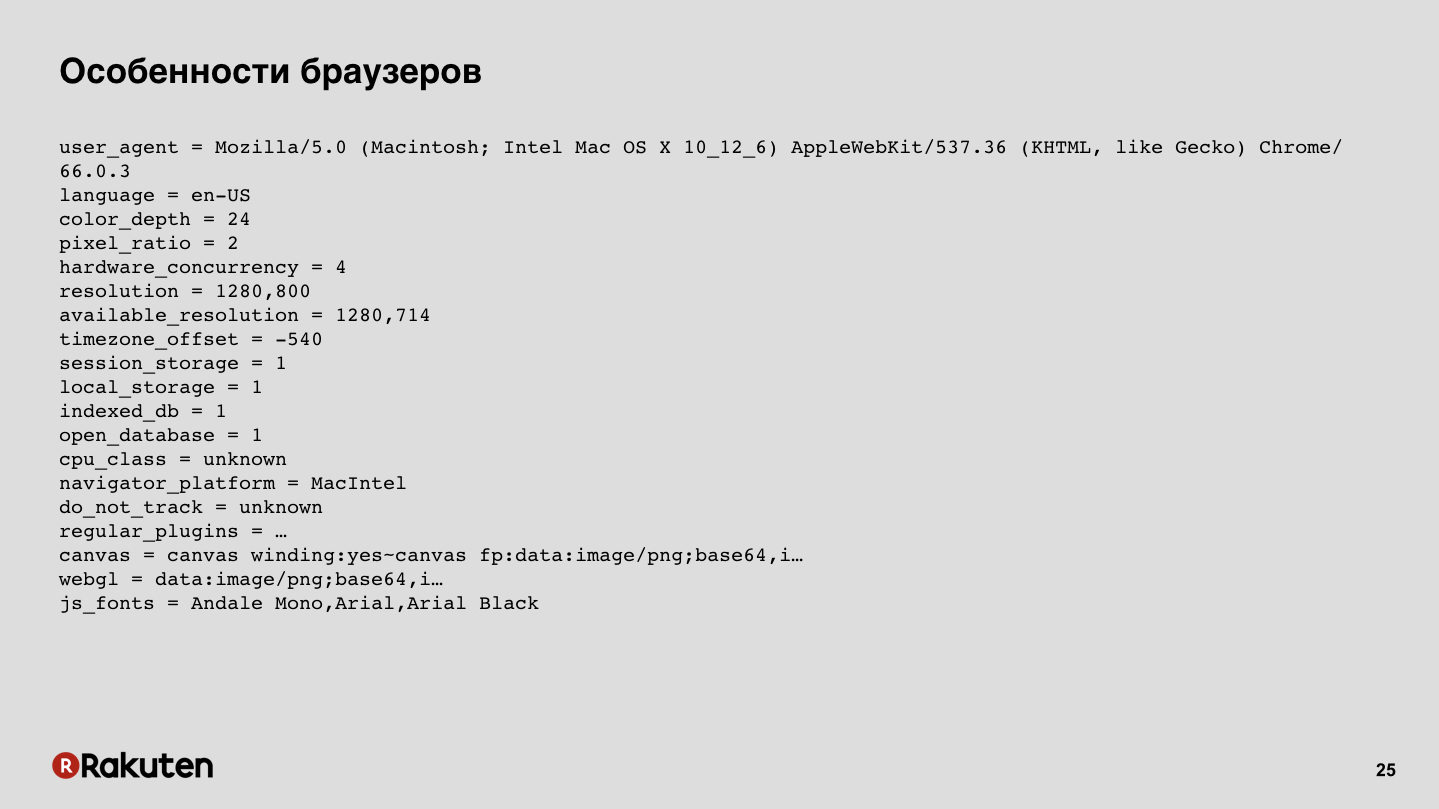
We can collect some prints from browsers. Now browsers are quite complex systems, they have a lot of supported features, they run JS, they have various low-level capabilities, and all this can be collected, all this data. The slide shows an example of the output of one of the open source libraries.
Plus, you can collect data on how the user interacts with your service, how it moves the mouse, how it touches the mobile device, how it scrolls the screen. Such things are collected, for example, Yandex. Metric. In our case, we came to the conclusion that we can compare the current behavior of the user with the behavior that we remember in advance.
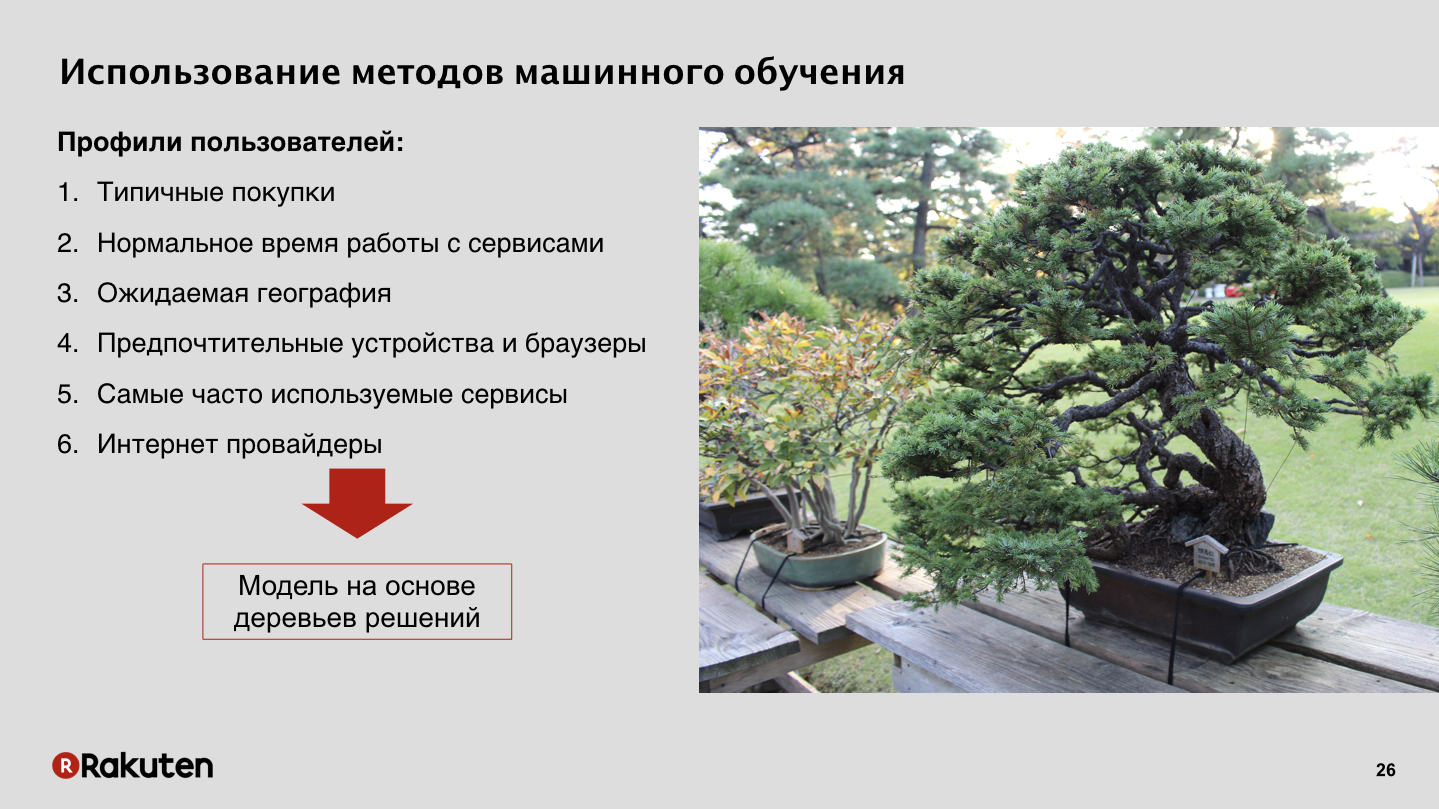
We have moved to comparing user actions with a profile that we already have. What is a profile? We know that people often buy and when, what kind of a home provider a person has, what regions he has been in when he travels. All this data is accumulated for a long time, and after that you can start using the profile. Here we have already applied machine learning, but used simple decision trees, since this is one of the most easily interpreted by human algorithms. Decision tree generates constructions like if-else, takes a small place in memory, and you can build trees for each user separately. They work quickly, you can compare user behavior with a profile almost in real time. If something is wrong, you can show the user some sort of challenge - for example,
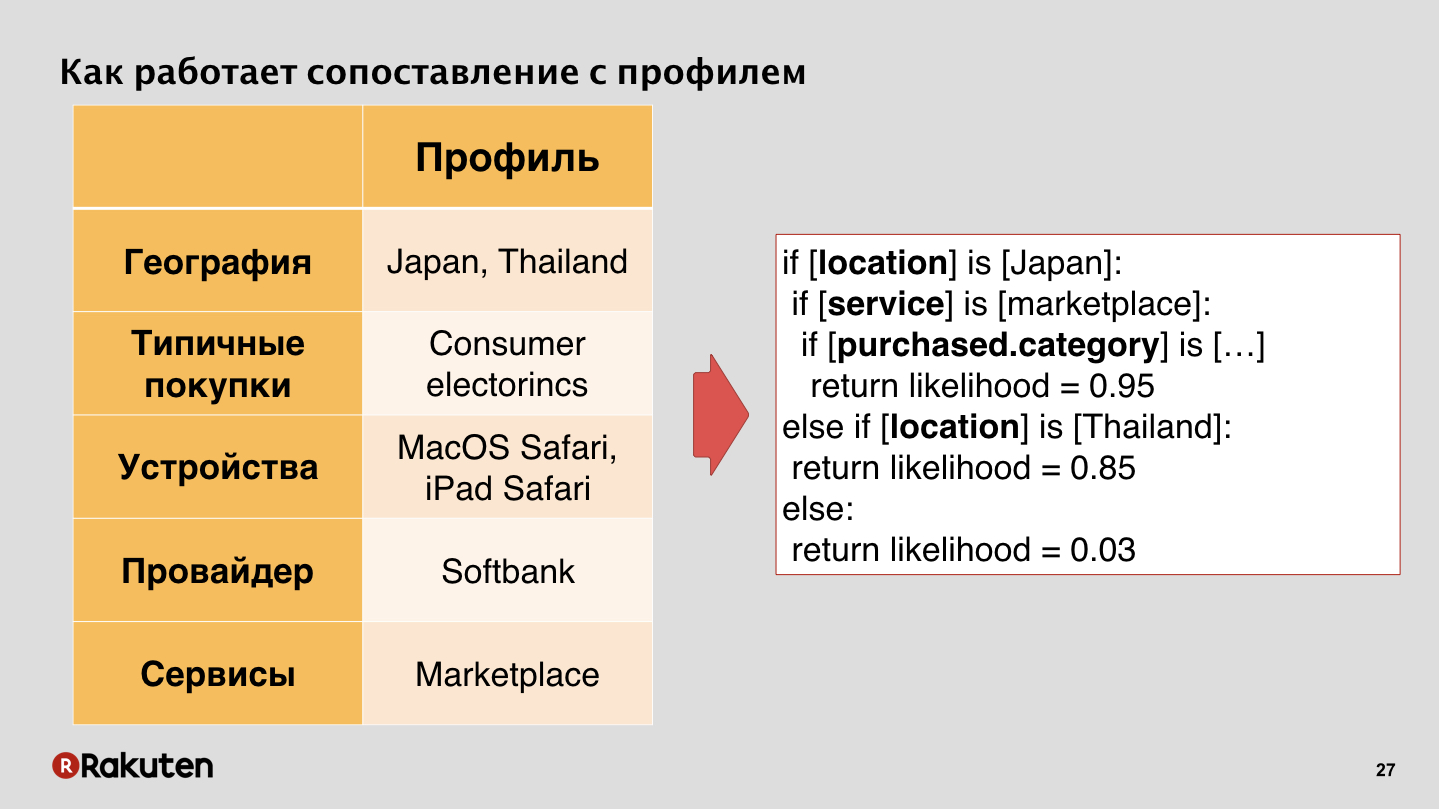
For example, we have a user who spends most of his time in Thailand and Japan, buys some kind of consumer electronics, uses, say, the Japanese provider Softbank, uses our marketplace. If we have such a tree, we can estimate on the current activity and see what the user is doing. If he again bought some kind of electronics while in Japan, there is nothing unusual in this, and we can ignore it.
But if a user suddenly comes in, for example, from Brazil and suddenly begins to buy prepaid iTunes cards in large numbers - we understand that this is some kind of anomalous activity, the person has never done so.
At this level of protection, we already understand very clearly that this is really an attacker, we can reject transactions and payments, make more active actions.

In general, I described the logic of the system. Do I think it works perfectly? To defeat intruders, we still have a long way to go. However, now we are blocking millions of malicious requests every day, and the size of botnets has increased to fairly large, to tens of thousands of nodes. For our part, we understand that for attackers it is already quite expensive to pay for such botnets.
In our system there is the possibility of flexible improvements. We are currently working on some options, we try to start blocking attacks as close to real time as possible. We try to adapt our system to different user interfaces. But here is my personal opinion: you should not rely only on the fraud protection system. It is also necessary to improve, add various authentication methods and thereby protect from different sides.
How do we authenticate? In our case, there is nothing extraordinary, but I want to mention one method. In addition to traditional types - captcha and one-time passwords - we use Proof of Work, PoW. No, we do not mine bitcoins on users' computers. We use PoW to slow down an attacker and sometimes even block completely, forcing him to solve a very difficult task, on which he spends a lot of time.
- I work in an international corporation Rakuten. I want to talk about a few things: a little about yourself, about our company, about how to evaluate the cost of attacks and understand whether you need to do fraud prevention. I want to tell you how we collected our fraud prevention and which models we used gave good results in practice, how they worked and what can be done to prevent fraud attacks.
About me briefly. He worked at Yandex, was engaged in web application security, and in Yandex also once made a system to prevent fraud attacks. I can develop distributed services, I have a bit of a mathematical background, which helps with the use of machine learning in practice.
Rakuten is not very well known in the Russian Federation, but I think you all know it for two reasons. Of the more than 70 of our services in Russia, Rakuten Viber is known, and if there are football fans here, you may know that our company is the general sponsor of the Barcelona football club.
Since we have a lot of services, we have our own payment systems, our own credit cards, a lot of reward programs, we are constantly under attack by intruders. And of course, we always have a request from a business for fraud protection systems.
When a business asks us to make a fraud protection system, we are always faced with some dilemma. On the one hand, there is a request for a high conversion rate, so that the user can conveniently authenticate on services, make purchases. And from our side, on the part of the security men, I want to have fewer complaints, fewer accounts have been hacked. And we, for our part, want to make the attack price high.
If you buy the fraud prevention system or try to do it yourself, you first need to estimate the costs.
Do we think we need fraud prevention? We relied on the fact that we have some types of financial losses from fraud. These are direct losses - money that you will return to your customers if they have been stolen by intruders. These are the costs of technical support service, which will communicate with users, resolve conflict issues. This is a return of goods that are very often delivered to unreal addresses. And there is a direct cost to develop the system. If you made a fraud protection system, deployed it on some servers, you will pay for the infrastructure, for software development. And there is a third very important aspect of damage from the attackers - lost profits. It consists of several components.
According to our calculations, there is a very important parameter - lifetime value, LTV, that is, the money that the user spends in our services, is significantly reduced. Because in half of the fraud cases, users simply leave your service and do not return.
We also pay money for advertising, and if the user is gone, they are lost. This is customer acquisition cost, CAC. And if we have a lot of automated users who are not real people - we have false real numbers monthly active users, MAU, which also affect the business.
Let's look from the other side, from the side of the attackers.
Some speakers said that attackers are actively using botnets. But whatever method they use, they still need to invest money, pay for the attack, they also spend some money. Our task, when we make fraud prevention system, is to find such a balance so that the attacker spends too much money, and we spend less. This makes the attack on us unprofitable, and the attackers simply go to break another service.
For our damage services, we divided attacks into four types. These are targeted when they try to hack one account, one account. Attacks perpetrated by a single user or a small group of individuals. Or more dangerous for us, the attacks are massive and non-targeted, when the attackers attack a lot of accounts, credit cards, phone numbers, etc.
I'll tell you what is happening, how we are attacked. The main most obvious type of attack that everyone knows about is brute force. In our case, the attackers are trying to sort through phone numbers, trying to validate credit card numbers. Some variety is present.
Mass registration of accounts, for us it is obviously harmful. I will give an example later.
What is registered? Fake accounts, some non-existent goods, try to spam in feedback messages. I think this is relevant and similar for many commercial companies.
There are still not obvious problems for e-commerce, but problems obvious to Yandex - attacks on the advertising budget, click fraud. Well, or just the theft of personal data.
I will give an example. We had a rather interesting attack on a service that sells e-books, there was an opportunity for any user to register and start selling their electronic work, such an opportunity to support novice writers.
The attacker registered one legal account master, and several thousand unreal minion accounts. And generated a fake book, just from random sentences, there was no point in it. He put it on the marketplace, and we had a marketing company, each minion had, conditionally, 1 dollar, which he could spend on a book. And this fake book was worth $ 1.
A raid of minions was organized - fake accounts. They all bought this book, the book jumped in the ratings, became a bestseller, the attacker raised the price to a conditional 10 dollars. And since the book became a bestseller, ordinary people began to buy it, and complaints about the fact that we were selling some low-quality goods, a book with a meaningless set of words inside, began to fall on us. The attacker received a profit.
There is no ninth point; the police later arrested him. So the profit did not go in store.
The main goal of all intruders in our case is to spend as little of our money as possible and take ours as much as possible.
There are attackers, one person who is just trying to get around business logic. But I’ll note that we don’t consider such attacks to be a priority for us, because by the ratio of the number of hacked accounts and the stolen money they carry a low risk for us. And the main problem for us is botnets.
These are massive distributed systems, they attack our services from all over the world, from different continents, but they have some features that make it easier to fight them. As in any large distributed system, botnet nodes perform more or less the same tasks.
Another important thing is that now, as many colleagues have pointed out, botnets are spreading to all sorts of smart devices, home routers, smart speakers, etc. But these devices have low hardware specifications and cannot perform complex scripts.
On the other hand, for an intruder, renting a botnet for a simple DDoS is cheap enough for brute-force account credentials, too. But if you need to implement some kind of business logic specifically for your application or service, the development and support of a botnet becomes very expensive. Usually, the attacker simply rents a part of the finished botnet.
I always attack botnets associated with the parade of Pikachu in Yokohama. We have 95% of malicious traffic coming from botnets.
If you look at the screenshot of our monitoring system, you will see a lot of yellow spots - these are blocked requests from various nodes. And here the attentive person may notice that I kind of said that the attack is evenly distributed around the globe. But on the map there is a clear anomaly, a red spot in the area of Taiwan. This is a rather curious case.
This attack came from home routers. In Taiwan, a major Internet provider was hacked, which provided Internet for most of the island’s inhabitants. And for us it was a very big problem, due to the fact that a lot of legal users at the same time when the attack occurred, from the same IP addresses went and worked with our services. We stopped this attack successfully, but it was very difficult.
If we talk about skoupe, about the surface, about what we protect. If you have a small e-commerce website or a small regional service, you have no particular problems. You have a server, maybe a few, or virtual machines in the cloud. Well, users, bad, good, who come to you. There is no particular problem to protect.
In our case, everything is more complicated, the attack surface is huge. We have services deployed in our own data centers, in Europe, in Southeast Asia, in the USA. We also have users on different continents, both good and bad. Plus, some services are deployed in the cloud infrastructure, and not our own.
With so many services and such an extensive infrastructure, it is very difficult to defend yourself. Plus, many of our services support various types of client applications and interfaces. For example, we have the service Rakuten TV, which runs on smart TVs, and for him the protection is completely special.
To sum up the problem, a huge number of users circulate in your system, like people at a store at a crossroads in Shibuya. And among this multitude of people it is necessary to identify and catch the attackers. And there are a lot of doors in your store, and even more people.
So, from what and how did we assemble our system?
We managed to use only open source components, it was quite cheap. Used the power of many "gophers". Much of the software was written in Golang. Used message queues and databases. Why do we need it? We pursued two goals: collecting data on user behavior and calculating reputation, carrying out some actions to recognize whether a user is good or bad.
We have many levels in the system, we use frontends written in Golang, and Tarantool is our caching base. Our system is deployed in all regions where our businesses are located. Events we pass on the data bus, from it we get a reputation.
We have backends that also replicate user reputation with Cassandra.
Data Bus, Nothing Secret, Apache Kafka.
Events and logs in one direction, reputation in another.
And of course, the system has a brain that thinks a bad user or a good one, a bad one is activity or a good one. The brain is built on the Apache Storm, and the most interesting thing is what happens inside there.
But first I’ll tell you how we collect data and how we block intruders.
There are many approaches here. Some of them were already mentioned by colleagues from Yandex in their first report. How to block intruders? Anton Karpov said that firewalls are bad, we don’t like them. Indeed, it is possible to block by IP addresses, the topic for Russia is very relevant, but this method does not suit us at all. We prefer to use higher-level locks, at the seventh level, at the application level, using request authentication using tokens, session cookies.
Why? Let's look first at locks at a low level.
This is a cheap way, everyone knows how to use it, everyone has firewalls on the servers. A bunch of instructions on the Internet, there are no problems to block a user by IP. But when you block a user at a low level, he does not have the ability to somehow bypass your protection system, if it was a false positive. Modern browsers are more or less trying to show some beautiful error message to the user, but anyway, a person cannot get around your system, because an ordinary user cannot arbitrarily change their IP addresses. Therefore, we believe that this method is not very good and unfriendly. And plus IPv6 walks around the planet, if you have any tables blocked, then after a while the search for addresses on such tables will take a very long time, and there is no future for such locks.
Our method is locking at the top level. We prefer to authenticate requests, because for us this is an opportunity to adapt very flexibly to the business logic of our applications. Such methods have advantages and disadvantages. The disadvantage is the high cost of development, a large amount of resources that you have to invest in infrastructure, and the architecture of such systems, for all its apparent simplicity, is still complex.
You heard on previous reports about various methods based on biometrics, data collection. Naturally, we also think about this, but it’s very easy to break the user's privacy by collecting the wrong data that the user wants to entrust to you.
How do we authenticate? In our case, there is nothing extraordinary, but I want to mention one method. In addition to traditional types - captcha and one-time passwords - we use Proof of Work, PoW. No, we do not mine bitcoins on users' computers. We use PoW to slow down an attacker and sometimes even block completely, forcing him to solve a very difficult task, on which he spends a lot of time.
How do we collect data? We use IP addresses as one of the features, as well as one of the data sources for us are encryption protocols supported by clients and connection establishment time. Also, the data that we collect from user browsers, the features of these browsers, and of the tokens that we use to authenticate requests.
How to detect intruders? Probably, you expect me to say that we built a huge neural network and immediately caught everyone. Not really. We used a multi-level approach. This is due to the fact that we have a lot of services, very large volumes of traffic, and if you try to install a complex computing system for such volumes of traffic, it will most likely be very expensive and will slow down the work of services. Therefore, we started with a banal simple method: we began to consider how many requests come from different addresses, from different browsers.
This method is very primitive, but allows you to weed out stupid massive DDoS attacks, when you have pronounced anomalies appear in traffic. In this case, you are absolutely sure that this is an attacker, and you can block it. But this method is suitable only at the initial level, because it prevents only the roughest attacks.
After that we come to the next method. We decided to focus on the fact that we have the business logic of applications, and the attacker can never just come to your service and steal money. If he didn't hack it, of course. In our case, if you look at the most simplified scheme of some abstract marketplace, we will see that the user must log in first, present his credentials, get session cookies, then go to the marketplace, search for products there, put them in the basket. After that, he proceeds to pay for the purchase, selects the address, payment method, and in the end he presses "pay", and finally the purchase of goods takes place.
You can see that the attacker must take many steps. And these transitions between states, between services resemble one mathematical model - these are Markov chains, which can also be used here. In principle, in our case they showed very good results.
I can give a simplified example. Roughly speaking, there is a moment when a user is authenticated, when he selects purchases and makes a payment, and for example, it’s obvious how an attacker can behave abnormally himself, he may try several times to log in with different accounts. Or he may add the wrong items to the cart that regular users buy. Or performs some abnormally large number of actions.
In Markov chains, states are usually considered. We also decided to add time to these states. Malefactors and normal users in time behave completely differently, and it also helps to separate them.
Markov chains are a fairly simple mathematical model, they are very easy to read on the fly, so they allow you to add another level of protection, weed out some more traffic.
Next stage. We caught the intruders stupid, caught the intruders of the average mind. Now there are the most intelligent. For cunning intruders, additional features are needed. What we can do?
We can collect some prints from browsers. Now browsers are quite complex systems, they have a lot of supported features, they run JS, they have various low-level capabilities, and all this can be collected, all this data. The slide shows an example of the output of one of the open source libraries.
Plus, you can collect data on how the user interacts with your service, how it moves the mouse, how it touches the mobile device, how it scrolls the screen. Such things are collected, for example, Yandex. Metric. In our case, we came to the conclusion that we can compare the current behavior of the user with the behavior that we remember in advance.
We have moved to comparing user actions with a profile that we already have. What is a profile? We know that people often buy and when, what kind of a home provider a person has, what regions he has been in when he travels. All this data is accumulated for a long time, and after that you can start using the profile. Here we have already applied machine learning, but used simple decision trees, since this is one of the most easily interpreted by human algorithms. Decision tree generates constructions like if-else, takes a small place in memory, and you can build trees for each user separately. They work quickly, you can compare user behavior with a profile almost in real time. If something is wrong, you can show the user some sort of challenge - for example,
For example, we have a user who spends most of his time in Thailand and Japan, buys some kind of consumer electronics, uses, say, the Japanese provider Softbank, uses our marketplace. If we have such a tree, we can estimate on the current activity and see what the user is doing. If he again bought some kind of electronics while in Japan, there is nothing unusual in this, and we can ignore it.
But if a user suddenly comes in, for example, from Brazil and suddenly begins to buy prepaid iTunes cards in large numbers - we understand that this is some kind of anomalous activity, the person has never done so.
At this level of protection, we already understand very clearly that this is really an attacker, we can reject transactions and payments, make more active actions.
In general, I described the logic of the system. Do I think it works perfectly? To defeat intruders, we still have a long way to go. However, now we are blocking millions of malicious requests every day, and the size of botnets has increased to fairly large, to tens of thousands of nodes. For our part, we understand that for attackers it is already quite expensive to pay for such botnets.
In our system there is the possibility of flexible improvements. We are currently working on some options, we try to start blocking attacks as close to real time as possible. We try to adapt our system to different user interfaces. But here is my personal opinion: you should not rely only on the fraud protection system. It is also necessary to improve, add various authentication methods and thereby protect from different sides.