PostSharp Logging and audit tasks
- Transfer
 Hello again! Last time when discussing AOP, we talked about solving caching problems. Today we’ll talk about an equally common task - the task of logging and auditing. We often have to deal with situations such as, for example, analysis of someone else's code. Imagine being given the task of integrating with a third-party library. The main tools of almost every developer - .net reflector, ILSpy, dotPeek give an excellent idea of the program code. About its algorithms, structure, possible places of errors. And they cover a large percentage of questions to the software product. However, this happens until you begin to actively use it. There may arise both performance problems and incomprehensible "bugs" inside a third-party product, which, if you don’t have a disassembler with a debugger function, it’s not so easy to find. Or, for example, you just need to monitor the values of variables without stopping the product at breakpoints, real-time. Such places often need urgent and quick fix. But how to correct this code if you don’t write a program that will then be in the top of the sitegovnokod.ru ? We will talk about such situations now.
Hello again! Last time when discussing AOP, we talked about solving caching problems. Today we’ll talk about an equally common task - the task of logging and auditing. We often have to deal with situations such as, for example, analysis of someone else's code. Imagine being given the task of integrating with a third-party library. The main tools of almost every developer - .net reflector, ILSpy, dotPeek give an excellent idea of the program code. About its algorithms, structure, possible places of errors. And they cover a large percentage of questions to the software product. However, this happens until you begin to actively use it. There may arise both performance problems and incomprehensible "bugs" inside a third-party product, which, if you don’t have a disassembler with a debugger function, it’s not so easy to find. Or, for example, you just need to monitor the values of variables without stopping the product at breakpoints, real-time. Such places often need urgent and quick fix. But how to correct this code if you don’t write a program that will then be in the top of the sitegovnokod.ru ? We will talk about such situations now. 
Logging and auditing are features in which PostSharp is one of the best. This is one of the fundamental examples showing the principle of cross-cutting. Indeed, instead of injecting the logging code into every place where this should be done, you enter logging at only one point, automatically distributing the code to all the necessary methods. And, of course, you can do this selectively, on several methods, fields or properties. You can write a lot of very useful information to the log, however, during the existence of the framework and the practice of working with it, I will highlight the following popular categories:
- Information about the executable code: function name, class name, parameter values, and so on. This can help you greatly in reducing the various scenarios that could lead to the result;
- Performance information: you can find out how long it took to execute the methods;
- Exceptions: it is possible to catch an exception, save information about it to the log and regenerate this exception so as not to violate the logic of the operation of the original application.
In addition to logging / tracing, which are actually more technical issues, you can also audit the application, which is very similar to logging / tracing, except that auditing is tracking information that carries more “business” activity. For example, you can take the logging of the values of a parameter when searching for an error, or you or your manager want to find out how often and how long the operations with the deposit are performed. You can enter all the information in a report file or in the tables of your database and display it on the corporate website in the form of beautiful graphs.
Let's use some bank teller program. And let's assume that this application can use bill counters, and is also written using WinForms. Also (in our very naive and simplified model), let the bank have only one client (for example, the president), and let us only have one static class that provides all the business logic.
public class BankAccount
{
static BankAccount()
{
Balance = 0;
}
public static decimal Balance { get; private set; }
public static void Deposit(decimal amount)
{
Balance += amount;
}
public static void Withdrawl(decimal amount)
{
Balance -= amount;
}
public static void Credit(decimal amount)
{
Balance += amount;
}
public static void Fee(decimal amount)
{
Balance -= amount;
}
}
* This source code was highlighted with Source Code Highlighter.Of course, in a real application, you will use a specialized layer of services, dependency injection and other architectural solutions instead of just a static class. And maybe you would even want to use the “lazy loading” of dependencies, however, let's drop all unnecessary and concentrate on the main thing - logging and auditing.
The application works great all the time, as long as the company has honest employees and customers. However, the financial director of this bank is at the dismissal stage, as millions of dollars suddenly went missing and no one can understand why. She hires you, a humble postsharp specialist, to figure out what’s going on with your help. She wants you to change the program in such a way as to keep track of all operations and transactions (yes, there is a record, but she wants to do this at the level of the program’s methods to find out the actual number, and not what appears in the reports). In such a situation, you could be patient and introduce business logic programs into each method (in our example, these will be only 4 methods, but in a real application there could be several thousand). Or, you can write just one method, and apply it to all methods of a certain group of classes or methods, immediately, without monotonous monkey work. Moreover, placing the code throughout the program, you set traps for yourself, because you will need to delete it later (or take additional steps so that it is not in the release build). And the second reason for the inconvenience of this approach is that you can make mistakes while writing it. Let's look at the code we will write usingPostSharp :
[Serializable]
public class TransactionAuditAttribute : OnMethodBoundaryAspect
{
private string _methodName;
private Type _className;
private int _amountParameterIndex = -1;
public override bool CompileTimeValidate(MethodBase method)
{
if(_amountParameterIndex == -1)
{
Message.Write(SeverityType.Warning, "999",
"TransactionAudit was unable to find an audit 'amount' in {0}.{1}",
_className, _methodName);
return false;
}
return true;
}
public override void CompileTimeInitialize(MethodBase method, AspectInfo aspectInfo)
{
_methodName = method.Name;
_className = method.DeclaringType;
var parameters = method.GetParameters();
for(int i=0;i
{
if(parameters[i].Name == "amount")
{
_amountParameterIndex = i;
}
}
}
public override void OnEntry(MethodExecutionArgs args)
{
if (_amountParameterIndex != -1)
{
Logger.Write(_className + "." + _methodName + ", amount: "
+ args.Arguments[_amountParameterIndex]);
}
}
}
* This source code was highlighted with Source Code Highlighter. Let me remind you that CompileTimeInitialize is used to get the name of methods and parameters during compilation, to minimize the amount of reflection used during application operation (by the way, the use of reflection can be reduced to zero using the build-time code) and to make sure that the amount parameter exists, for which we will follow. If we do not find it, then we notify the developer about this using warning.
Using this aspect and some kind of storage to store the collected data, you can create some analytical information for your CFO.
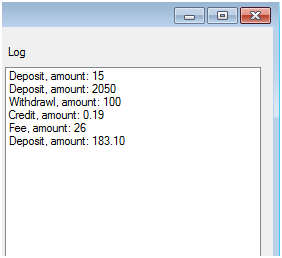
However, while the investigation is ongoing, you begin to understand that there may be other problems with the system: for example, you will find out that the user interface is not stable and the application constantly crashes. In order to find out the place of crashes, you can place try / catch in different places of the program (which can be a huge number) to understand which specific place is failing. Or you can write one class, after which the exception audit will be automatically enabled on all interface methods (yes, you can easily limit the scope of this class). In order not to be unfounded, let's see a simple example:
[Serializable]
public class ExceptionLoggerAttribute : OnExceptionAspect
{
private string _methodName;
private Type _className;
public override void CompileTimeInitialize(MethodBase method, AspectInfo aspectInfo)
{
_methodName = method.Name;
_className = method.DeclaringType;
}
public override bool CompileTimeValidate(MethodBase method)
{
if(!typeof(Form).IsAssignableFrom(method.DeclaringType))
{
Message.Write(SeverityType.Error, "003",
"ExceptionLogger can only be used on Form methods in {0}.{1}",
method.DeclaringType.BaseType, method.Name);
return false;
}
return true;
}
public override void OnException(MethodExecutionArgs args)
{
Logger.Write(_className + "." + _methodName + " - " + args.Exception);
MessageBox.Show("There was an error!");
args.FlowBehavior = FlowBehavior.Return;
}
}
* This source code was highlighted with Source Code Highlighter.And, again, I use CompileTimeInitialize only to reduce the number of calls to reflection. To apply this aspect (for a couple of functions) it is necessary to mark the corresponding methods / classes / assemblies / namespaces (in this case, the assembly is marked, the filter by the full name of the assembly member is additionally indicated) with the attribute:
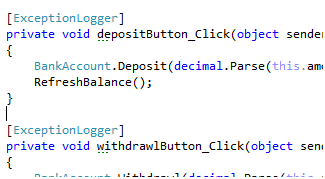
To mark the class, you can either mark the class itself or mark assembly by specifying the class name:
// in AssemblyInfo.cs
[assembly: ExceptionLogger(AttributeTargetTypes = "LoggingAuditing.BankAccountManager")]
* This source code was highlighted with Source Code Highlighter.After you turned on logging and audited the application, terrible things turned out:
- Clients can withdraw negative amounts from their accounts, and less honest clients often use this!
- When entering information into interface forms, people constantly make typos without checking the input. For example, if the cashier enters "$ 5.19", this will cause an unhandled exception and the entire application will crash!
With two very simple aspects, you can solve these glaring shortcomings of the application quickly enough, giving business users an audit of the transaction flow, and letting the developers in your team log and monitor exceptional situations during the shipment and user experience. You must recognize that a hard-broken application at the installation stage to the end user, at the user’s work stage, can create a huge number of problems. Especially with the development team. However, if you use aspects, you can diagnose and correct them very quickly.
Now, let's look under the hood and see what code is actually generated. Do not panic if you still do not understand. PostSharp is very easy to use and its results can be easily opened in any disassembler. But let's look at the resulting code anyway. We want to figure it out.
Here's the “Credit" method without using PostSharp. As you can see, it is quite simple:
public static void Credit(decimal amount)
{
Balance += amount;
}
* This source code was highlighted with Source Code Highlighter.Next, look at the same method after applying the TransactionAudit aspect. Remember that this code will only be in the resulting assembly (dll and exe files) and will not be in your sources:
public static void Credit(decimal amount)
{
Arguments CS$0$0__args = new Arguments();
CS$0$0__args.Arg0 = amount;
MethodExecutionArgs CS$0$1__aspectArgs = new MethodExecutionArgs(null, CS$0$0__args);
CS$0$1__aspectArgs.Method = <>z__Aspects.m11;
<>z__Aspects.a14.OnEntry(CS$0$1__aspectArgs);
if (CS$0$1__aspectArgs.FlowBehavior != FlowBehavior.Return)
{
try
{
Balance += amount;
<>z__Aspects.a14.OnSuccess(CS$0$1__aspectArgs);
}
catch (Exception CS$0$3__exception)
{
CS$0$1__aspectArgs.Exception = CS$0$3__exception;
<>z__Aspects.a14.OnException(CS$0$1__aspectArgs);
CS$0$1__aspectArgs.Exception = null;
switch (CS$0$1__aspectArgs.FlowBehavior)
{
case FlowBehavior.Continue:
case FlowBehavior.Return:
return;
}
throw;
}
finally
{
<>z__Aspects.a14.OnExit(CS$0$1__aspectArgs);
}
}
}
* This source code was highlighted with Source Code Highlighter.And again: do not panic! :) This code may seem messy due to the use of automatically generated variable names, but in reality it is very simple. A wrapper from try / catch is added to the original code and the code of a certain aspect is called. As you can see, only the overridden onEntry method is really used here, in which you will do your actions. However, you can override other methods (onExit, onSuccess, onException), if you would solve any problems where overriding them would be necessary.
This code, which was given above, generates a free version of postsharp. A fully functional version of the program works by optimizing the resulting code, as shown below. In our case, the program will understand that you only use the onEntry method and that in this case there is no need to generate a huge amount of code. And in this case, you will get such a short code:
public static void Credit(decimal amount)
{
Arguments CS$0$0__args = new Arguments();
CS$0$0__args.Arg0 = amount;
MethodExecutionArgs CS$0$1__aspectArgs = new MethodExecutionArgs(null, CS$0$0__args);
<>z__Aspects.a14.OnEntry(CS$0$1__aspectArgs);
Balance += amount;
}
* This source code was highlighted with Source Code Highlighter.The fully functional version intelligently generates only the code that you need. If you are writing an application that takes full advantage of postsharp aspects, using a fully functional version would be a good solution to improve application performance.
However, despite the funny names of automatically generated class members and local variables, I hope you get a good idea of what PostSharp is.
References: