Transparent Page Sharing in ESX 4.1 - Following the Trail of Last Year's Article
By chance, a couple of weeks ago I stumbled upon last year’s System32 companion article about Transparent Page Sharing , which actually prompted me to disrupt my preparation schedule for VCAP-DCA and deeply immerse myself in completely unknown memory management technology in vSphere, and if to be more exact - in TPS. A System32 colleague very intelligently outlined the general principles of working with memory, the TPS operation algorithm, but at the same time made not quite correct conclusions. I was even more embarrassed by questions in the comments to which no one answered regarding high SHRD values in esxtop, despite the fact that according to the same article, when using Large Pages, TPS technology simply won’t work. In general, serious contradictions were found between beautiful theory and practice.
After 4-5 days of digging in the Vmware forums, reading Wiki, Western bloggers , I had something in my head and I was finally able to answer questions from the comments. In order to somehow streamline my fresh knowledge, I decided to write several articles on this subject in my English-language blog. I also furred Habr for new articles on this topic, but to my surprise since 2010, I have not found anything new. Therefore, I decided for the sake of constantly reading Habr and the opportunity to actively participate in the comments to translate my own article about Transparent Page Sharing and the nuances of its use on systems with processors from the Nehalem / Opteron family and with installed ESX (i) 4.1.
I don’t feel like making the article too long, so I strongly recommend that you (especially if you are a vSphere admin) read the article first, the link to which I gave at the very beginning. But still, in some little things, I repeat.
So what is TPS for?
The answer is quite banal - to save RAM, show virtual machines more memory than there is on the host itself, and therefore provide a higher level of consolidation.
How does he work?
Historically, in x86 systems, all memory is divided into 4 KB blocks, the so-called pages. When you have 20 virtual machines (VMs) running on the same ESX host with the same OS, you can easily imagine that these VMs have a lot of identical memory pages. To find the same page on the ESX host, a TPS process is launched with a periodicity of 60 minutes. It scans absolutely all pages in memory and calculates the hash of each page. All hashes are added up in one table and checked by a kernel for a match. To avoid a problem called hash collisionupon detection of the same hashes, the kernel checks the corresponding pages bit by bit. And only after making sure that they are 100% identical, the kernel leaves one single copy of the page in memory, and all calls to the deleted pages are redirected to the very first copy. If any of the VMs decides to change something on this page, then ESX will create another copy of the original page and already allow the VM to work with it, which sent the request for change. Therefore, in Vmware terminology, this type of page is called Copy-on-write (COW). The process of scanning memory on modern servers with sometimes hundreds of gigabytes of RAM can take a long time, so you should not expect immediate results.
NUMA and TPS
NUMA- This is a rather interesting technology for sharing memory access between processors. Fortunately for us, the latest versions of ESX are smart enough and know that for efficient NUMA systems TPS should work only within the NUMA node. In principle, if you adjust the value of VMkernel.Boot.sharePerNode in ESX, you can make TPS compare pages within the entire memory, rather than individual NUMA nodes. It is clear that in this case it is possible to achieve higher SHARED memory values, but you need to consider the possible serious performance drop. For example, imagine that your ESX host has 4 Xeon 5560 processors, that is, 4 NUMA nodes and each contains an identical copy of the memory page. If TPS leaves one copy in the first node and deletes the remaining 3, it means that every time, when any of the VMs working on these 3 nodes needs the desired memory page, 3 processors will have to access it not through the local and very fast memory bus, but through the general and slow. The more such pages you have, the less bandwidth remains on the shared bus, and therefore the performance of your virtual machines suffers more.
Zero Pages
One of the great new features introduced in vSphere 4.0 was the recognition of zero pages. In principle, this is a normal page, which is filled with zeros from beginning to end. Each time the Windows VM turns on, all memory is reset, this helps the OS determine the exact size of the memory available to it. ESX can instantly detect such pages in virtual machines, and instead of the useless process of allocating physical memory for zero pages, and then deleting them during TPS, ESX immediately redirects all such pages to one single zero page. If you run esxtop and check the memory values for the newly launched VM, you will find that the ZERO and SHRD values are almost identical.

However, it is important to note here that this new wonderful feature ESX 4.0 (and older) can only be used on processors with EPT (Intel) or RVI (AMD) technologies. There are a couple of excellent articles on this subject on the Kingston website ( part one , part two ). In short, it tells and shows how, on new processors, zero pages are recognized without allocating physical memory to them, but on older processors physical memory is allocated, and only when TPS fully fulfills does the reduction of used physical memory begin. For ordinary vSphere farms, this is not critical in principle, but for VDI infrastructures, where you can have hundreds of virtual machines starting at the same time, this is archip useful.
A couple of features of TPS with zero pages.
1. In Windows OS, there is a technology called “file system caching” (I’m sorry if in some places my translation of names and definitions has inaccuracies). Using the definition of MS, we can say that "File system caching is a memory area that stores recently used information for quick access." This cache is located in the address space of the kernel, and therefore, in 32-bit systems, its size is limited to 1 gigabyte. However, in 64bit systems, its size can reach 1 terabyte ( proof ). In principle, the technology is very useful for performance, but if we have a situation with virtual machines and zero large pages (2 megabytes), then the SHRD value in esxtop will go to zero for you.
The screenshot above showed the value of esxtop immediately after starting the Windows 2008 R2 virtual machine, but here is what esxtop showed after half an hour.

Although in the Task Manager of this virtual machine you can easily see how much more free (zero) memory we have.
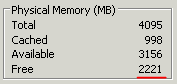
Unfortunately, I didn’t get to the bottom of why this is how things turn out, but it seems to me that file system caching does not occur as a continuous write to memory, but to its various areas.
2 . Resetting memory pages in a virtual machine occurs only when it is turned on. With a standard restart, the pages do not reset to zero.
Large pages
The size of large pages used by the kernel in ESX is 2 megabytes. The chances that two identical large pages are found in physical memory are generally almost zero, so ESX does not even try to compare them. When you use new processors with EPT / RVI, this means that the host will aggressively try to use large pages where possible. If you look at the SHRD value in such hosts, you will be unpleasantly surprised by its low value, but nevertheless it is still a significant amount. On my production host, with about 70 GB allocated, about 4 GB was SHRD. This, by the way, was one of the most interesting questions in the comments of the article, with which my interest in this topic began. Now I know that these are just zero pages, and then I was terribly tormented by ignorance and guesses.
This low rate initially sparked heated discussion on the Vmware forums for the simple reason that people decided that TPS stopped working on their ESX 4.0 hosts. Vmware was forced to post an explanation about this.
Nevertheless, even when your host is actively using large pages, TPS does not sleep at all. He also methodically scans the memory for identical 4 kB pages that he could delete if he had the will. As soon as he finds duplicate pages, he puts a bookmark (hint) there. When the value used in ESX memory reaches 94%, your host immediately breaks large pages into small pages and does not waste time scanning (TPS has already set bookmarks), it again starts to delete identical pages. If you haven’t reached this point yet, then in the same esxtop, in the COWH (Copy-on-write hints) field, you can see how much you can save after large pages are divided into small ones.

And again, I would like to draw attention to the difference in working with large pages between old and new processors. Vmware itself has included support for large pages since version 3.5. According to Vmware's “ Large Page Performance ” document , if the OS of your virtual machine uses large pages, then the ESX host will allocate large pages in physical memory specifically for this VM. However, if the same virtual machine runs on an ESX host with EPT / RVI processors, then regardless of the support of large pages of your VM, ESX will use large pages in physical memory, which, as is known from the same document, will lead to a serious increase in processor performance.
Interestingly, on a pair of hosts with old processors and ESX 4.1, which rotate 90% of Windows 2008R2, I still see a very high SHRD, which suggests that small pages are most likely used there. Unfortunately, I did not find detailed documentation on how support for large pages on older processors works: under what conditions, on which OS, etc. large pages will be used. So for me this is still a blank spot. In the near future I will try to run 10 Windows 2008 R2 pieces on the ESX 4.1 host with the old processor and check the memory values.
When I only learned all this more or less, I was puzzled - what happens if I manually turn off support for large pages on my host with a Nehalem processor? How much will I see the saved memory and how much will the performance drop? “Well, what is there to think long - you have to do it,” I thought, and turned off support for large pages on one of our production hosts. Initially, this host had 70 GB of allocated memory and 4 GB of shared memory (well, yes, we remember - these are zero pages). The average processor utilization never rose above 25%. Two hours after turning off large pages, the value of shared memory grew to 32 GB, and the processor load remained at the same level. It has been 4 weeks since then and we have not heard a single complaint about a drop in performance.
And finally, my conclusion
After I shared the information with my colleagues, they asked me, “What the hell do you do with turning off support for large pages, if the host will disable them if necessary?”. And I knew the answer right away - with the support of large pages turned on by default, I can’t fully see how much I can potentially save memory with TPS, I can’t correctly plan additional VM placement on my ESX hosts, I can’t predict the level of consolidation, in general I’m a little blind in terms of managing the resources of his vSphere farm. However, the vSphere guru, such as Duncan Epping, assured us: “don’t worry, TPS will still work when you need to, and at the same time you have a great performance boost.” After a couple more days, I found a wonderful discussion.between him and other authorities in the world of virtualization, which only confirmed the correctness of my decision to turn off large pages. Some say that you can use the COWH value to plan the use of your resources, but for some reason this value is not always true. This screenshot shows the values of one of my Windows 2003 servers, which has been running on a host with large pages disabled for 3 weeks, and as you can see the SHRD and COWH values are very different.

A week ago, we turned off large pages on 4 more hosts, another farm, and again I did not notice any performance degradation. Although, it is worth noting that this is all individual, and you must take into account the specifics of your farm, resources, virtual machines when making such a decision.
If I’m lucky and this article seems interesting, I would love to translate another article on the difference in memory management between the processors of the old and new generation.
After 4-5 days of digging in the Vmware forums, reading Wiki, Western bloggers , I had something in my head and I was finally able to answer questions from the comments. In order to somehow streamline my fresh knowledge, I decided to write several articles on this subject in my English-language blog. I also furred Habr for new articles on this topic, but to my surprise since 2010, I have not found anything new. Therefore, I decided for the sake of constantly reading Habr and the opportunity to actively participate in the comments to translate my own article about Transparent Page Sharing and the nuances of its use on systems with processors from the Nehalem / Opteron family and with installed ESX (i) 4.1.
I don’t feel like making the article too long, so I strongly recommend that you (especially if you are a vSphere admin) read the article first, the link to which I gave at the very beginning. But still, in some little things, I repeat.
So what is TPS for?
The answer is quite banal - to save RAM, show virtual machines more memory than there is on the host itself, and therefore provide a higher level of consolidation.
How does he work?
Historically, in x86 systems, all memory is divided into 4 KB blocks, the so-called pages. When you have 20 virtual machines (VMs) running on the same ESX host with the same OS, you can easily imagine that these VMs have a lot of identical memory pages. To find the same page on the ESX host, a TPS process is launched with a periodicity of 60 minutes. It scans absolutely all pages in memory and calculates the hash of each page. All hashes are added up in one table and checked by a kernel for a match. To avoid a problem called hash collisionupon detection of the same hashes, the kernel checks the corresponding pages bit by bit. And only after making sure that they are 100% identical, the kernel leaves one single copy of the page in memory, and all calls to the deleted pages are redirected to the very first copy. If any of the VMs decides to change something on this page, then ESX will create another copy of the original page and already allow the VM to work with it, which sent the request for change. Therefore, in Vmware terminology, this type of page is called Copy-on-write (COW). The process of scanning memory on modern servers with sometimes hundreds of gigabytes of RAM can take a long time, so you should not expect immediate results.
NUMA and TPS
NUMA- This is a rather interesting technology for sharing memory access between processors. Fortunately for us, the latest versions of ESX are smart enough and know that for efficient NUMA systems TPS should work only within the NUMA node. In principle, if you adjust the value of VMkernel.Boot.sharePerNode in ESX, you can make TPS compare pages within the entire memory, rather than individual NUMA nodes. It is clear that in this case it is possible to achieve higher SHARED memory values, but you need to consider the possible serious performance drop. For example, imagine that your ESX host has 4 Xeon 5560 processors, that is, 4 NUMA nodes and each contains an identical copy of the memory page. If TPS leaves one copy in the first node and deletes the remaining 3, it means that every time, when any of the VMs working on these 3 nodes needs the desired memory page, 3 processors will have to access it not through the local and very fast memory bus, but through the general and slow. The more such pages you have, the less bandwidth remains on the shared bus, and therefore the performance of your virtual machines suffers more.
Zero Pages
One of the great new features introduced in vSphere 4.0 was the recognition of zero pages. In principle, this is a normal page, which is filled with zeros from beginning to end. Each time the Windows VM turns on, all memory is reset, this helps the OS determine the exact size of the memory available to it. ESX can instantly detect such pages in virtual machines, and instead of the useless process of allocating physical memory for zero pages, and then deleting them during TPS, ESX immediately redirects all such pages to one single zero page. If you run esxtop and check the memory values for the newly launched VM, you will find that the ZERO and SHRD values are almost identical.
However, it is important to note here that this new wonderful feature ESX 4.0 (and older) can only be used on processors with EPT (Intel) or RVI (AMD) technologies. There are a couple of excellent articles on this subject on the Kingston website ( part one , part two ). In short, it tells and shows how, on new processors, zero pages are recognized without allocating physical memory to them, but on older processors physical memory is allocated, and only when TPS fully fulfills does the reduction of used physical memory begin. For ordinary vSphere farms, this is not critical in principle, but for VDI infrastructures, where you can have hundreds of virtual machines starting at the same time, this is archip useful.
A couple of features of TPS with zero pages.
1. In Windows OS, there is a technology called “file system caching” (I’m sorry if in some places my translation of names and definitions has inaccuracies). Using the definition of MS, we can say that "File system caching is a memory area that stores recently used information for quick access." This cache is located in the address space of the kernel, and therefore, in 32-bit systems, its size is limited to 1 gigabyte. However, in 64bit systems, its size can reach 1 terabyte ( proof ). In principle, the technology is very useful for performance, but if we have a situation with virtual machines and zero large pages (2 megabytes), then the SHRD value in esxtop will go to zero for you.
The screenshot above showed the value of esxtop immediately after starting the Windows 2008 R2 virtual machine, but here is what esxtop showed after half an hour.
Although in the Task Manager of this virtual machine you can easily see how much more free (zero) memory we have.
Unfortunately, I didn’t get to the bottom of why this is how things turn out, but it seems to me that file system caching does not occur as a continuous write to memory, but to its various areas.
2 . Resetting memory pages in a virtual machine occurs only when it is turned on. With a standard restart, the pages do not reset to zero.
Large pages
The size of large pages used by the kernel in ESX is 2 megabytes. The chances that two identical large pages are found in physical memory are generally almost zero, so ESX does not even try to compare them. When you use new processors with EPT / RVI, this means that the host will aggressively try to use large pages where possible. If you look at the SHRD value in such hosts, you will be unpleasantly surprised by its low value, but nevertheless it is still a significant amount. On my production host, with about 70 GB allocated, about 4 GB was SHRD. This, by the way, was one of the most interesting questions in the comments of the article, with which my interest in this topic began. Now I know that these are just zero pages, and then I was terribly tormented by ignorance and guesses.
This low rate initially sparked heated discussion on the Vmware forums for the simple reason that people decided that TPS stopped working on their ESX 4.0 hosts. Vmware was forced to post an explanation about this.
Nevertheless, even when your host is actively using large pages, TPS does not sleep at all. He also methodically scans the memory for identical 4 kB pages that he could delete if he had the will. As soon as he finds duplicate pages, he puts a bookmark (hint) there. When the value used in ESX memory reaches 94%, your host immediately breaks large pages into small pages and does not waste time scanning (TPS has already set bookmarks), it again starts to delete identical pages. If you haven’t reached this point yet, then in the same esxtop, in the COWH (Copy-on-write hints) field, you can see how much you can save after large pages are divided into small ones.
And again, I would like to draw attention to the difference in working with large pages between old and new processors. Vmware itself has included support for large pages since version 3.5. According to Vmware's “ Large Page Performance ” document , if the OS of your virtual machine uses large pages, then the ESX host will allocate large pages in physical memory specifically for this VM. However, if the same virtual machine runs on an ESX host with EPT / RVI processors, then regardless of the support of large pages of your VM, ESX will use large pages in physical memory, which, as is known from the same document, will lead to a serious increase in processor performance.
Interestingly, on a pair of hosts with old processors and ESX 4.1, which rotate 90% of Windows 2008R2, I still see a very high SHRD, which suggests that small pages are most likely used there. Unfortunately, I did not find detailed documentation on how support for large pages on older processors works: under what conditions, on which OS, etc. large pages will be used. So for me this is still a blank spot. In the near future I will try to run 10 Windows 2008 R2 pieces on the ESX 4.1 host with the old processor and check the memory values.
When I only learned all this more or less, I was puzzled - what happens if I manually turn off support for large pages on my host with a Nehalem processor? How much will I see the saved memory and how much will the performance drop? “Well, what is there to think long - you have to do it,” I thought, and turned off support for large pages on one of our production hosts. Initially, this host had 70 GB of allocated memory and 4 GB of shared memory (well, yes, we remember - these are zero pages). The average processor utilization never rose above 25%. Two hours after turning off large pages, the value of shared memory grew to 32 GB, and the processor load remained at the same level. It has been 4 weeks since then and we have not heard a single complaint about a drop in performance.
And finally, my conclusion
After I shared the information with my colleagues, they asked me, “What the hell do you do with turning off support for large pages, if the host will disable them if necessary?”. And I knew the answer right away - with the support of large pages turned on by default, I can’t fully see how much I can potentially save memory with TPS, I can’t correctly plan additional VM placement on my ESX hosts, I can’t predict the level of consolidation, in general I’m a little blind in terms of managing the resources of his vSphere farm. However, the vSphere guru, such as Duncan Epping, assured us: “don’t worry, TPS will still work when you need to, and at the same time you have a great performance boost.” After a couple more days, I found a wonderful discussion.between him and other authorities in the world of virtualization, which only confirmed the correctness of my decision to turn off large pages. Some say that you can use the COWH value to plan the use of your resources, but for some reason this value is not always true. This screenshot shows the values of one of my Windows 2003 servers, which has been running on a host with large pages disabled for 3 weeks, and as you can see the SHRD and COWH values are very different.
A week ago, we turned off large pages on 4 more hosts, another farm, and again I did not notice any performance degradation. Although, it is worth noting that this is all individual, and you must take into account the specifics of your farm, resources, virtual machines when making such a decision.
If I’m lucky and this article seems interesting, I would love to translate another article on the difference in memory management between the processors of the old and new generation.