A bit about biology and bioinformatics
Introduction
I think that all users of Habr are familiar with the successes of mankind in the field of microelectronics, the vast majority are space exploration, a considerable part is physics. But almost no one knows that a revolution is taking place in biology right now that will change our life in the next few decades no less than the spread of computers. Moreover, this revolution is directly related to success in building powerful computing systems. Of course, some "circles on the water" diverge. But not everyone is able to compare the hysteria in the media regarding GMOs, the word "recombinant" on the vial with interferon or insulin and slurred (in Russia) rumors about a certain 23andme. In fact, all these phenomena are connected by one thread. And unraveling this thread is better from the very beginning.
Mendel and genes
Perhaps it’s worth starting with research at that time (XIX century) of the unknown monk Mendel (this is only now being talked about in every school). He noticed strange patterns in the inheritance of the color of flowers by pea plants. To explain this effect, he introduced the concept of a gene as a unit of hereditary information manifested in a set of external characters (phenotype). All genes are inherited in pairs (alleles); the pair may contain genes encoding two different variations of a particular trait; what specific variation will come to life is determined by the characteristics of the gene itself. This theory very well explained the observed features of inheritance. It is so good that it was no surprise to anyone to discover a physical mechanism that determines precisely such laws of inheritance.
DNA
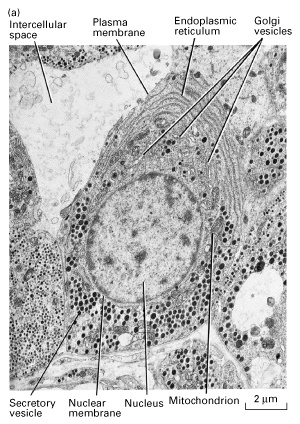
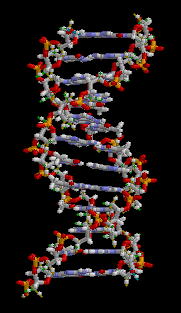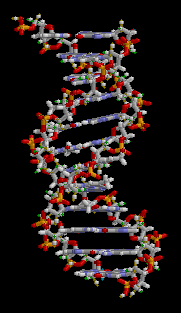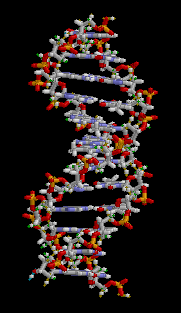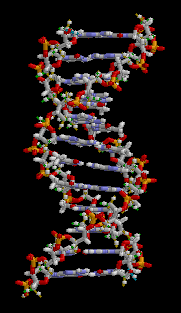
The next milestone is the discovery of the DNA structure by James Watson and Francis Crick in 1953. No, of course, and before them it was known about the presence of a certain substance concentrated in the cell nucleus and forming chromatin (tangled filaments visible in a light microscope after special staining), and chromosomes (much noticeable spindle-shaped structures are much better) during cell division. But it was Watson and Crick who showed what kind of substance it is and what its structure is. It is worth making a small digression and recall what DNA, proteins and RNA are. DNA - an organic polymer - a substance made up of a large number of fairly simple "bricks". In the case of DNA, these are the nucleotides thymine, adenine, guanine and cytosine, usually encoded by the letters T, A, G, C, respectively. DNA in the cell is a double helix (seeFigure ), consisting of two chains of complementary nucleotides: the fact is that nucleotides pairwise form bonds (TA, GC) between themselves. The complementarity property makes single DNA strands floating in solution find their “pairs” and combine with them. Such self-organization is generally extremely characteristic of biochemical processes. RNA is quite similar to DNA, but does not form a double chain, which is why it is less stable, but more mobile and chemically active. Proteins are polymers of amino acids. Usually they are built on an RNA matrix, which, in turn, is built on DNA.
{kind=link}
{kind=link}
Genetic Engineering
After the discovery of the DNA structure, further discoveries were not long in coming. A "set of a genetic engineer" was gradually formed - proteins found primarily in bacteria and viruses and allowing various DNA operations:
- restriction enzymes that cut DNA in precisely defined places;
- ligases, “gluing” DNA back;
- transcriptases that allow you to translate information from DNA to RNA and vice versa;
- and many other proteins.
- Insulin and interferon. Previously, to obtain these proteins, it was necessary to use tons of pig guts; Now bacteria produce them literally from the simplest ingredients like glucose solution.
- Glyphosate (aka roundup). Compared to other herbicides, glyphosate is practically harmless to animals (the lethal dose for an adult is measured in hundreds of grams), while lethal to all plants except artificially genetically modified ones - in other words, it completely solves the weed problem, without interfering with the growth of the cultivated crop. Actually, “genetically modified soybeans” almost always means soybeans modified to be resistant to roundup. In light of this, opponents of GMOs look especially funny, in fact, calling for the use of herbicides that are really dangerous for people - there is no alternative, you can’t feed all 6.5 billion without herbicides.
Bioinformatics
Improvement of biological tools has brought new problems: the transcendental complexity of the processes taking place in a living cell and the gigantic amount of information that no one is able to analyze manually became apparent. But by this time, computers were already widespread enough to become an obvious answer to the question of complexity controls. So bioinformatics was born - a science designed to cope with huge volumes of data, intertwined with internal dependencies and non-obvious patterns more than anything known to mankind before. The problems that it solves are extremely new, complex and relevant for humanity, and it is this area of knowledge that is now attracting the minds of the world's most powerful algorithmists. Almost all of them are generated by a lag of several orders of available computing power from those that are necessary for direct modeling of processes occurring in the cell. A large amount of news about building more and more powerful supercomputers may give the impression that now there are no problems with computing power and the most difficult task of modern IT is to build a fault-tolerant chat room for a couple of million people - and so, this is not so :) What does bioinformatics do ?
- Assembly of sequences. Now there is the opportunity to “parse” a protein or DNA into its constituent parts by constructing the sequence of nucleotides or amino acids from which it is built (this process is called sequencing). Unfortunately, due to technical limitations, the size of the largest section, “at a time”, is hundreds of times smaller than the whole size of the human genome, while the ends of the segments are not accurately fixed, and the segments themselves can be duplicated. This gives rise to the need to assemble the genome from small sections, trying to guess with the help of heuristics how exactly the “tails” of these sections overlap and in what order they need to be arranged. For a better understanding of the computational complexity of the task, it is necessary to clarify that the complete human genome, recorded as a string, takes about 3GB,
- Comparison and comparison of sequences. Twenty years ago, even juxtaposing two sequences could be a problem; Now, thanks to the increased power of computers and developed algorithms, this is no longer a difficult task. Nevertheless, the problem of multiple sequence comparisons has become extremely urgent; for example, metagenomics presents particularly high requirements for comparison: a method for classifying bacteria (many species are indistinguishable under a microscope), based on isolating mixtures from short sections of DNA from the mass of bacteria, sequencing them, and exclusively comparing the resulting “soup” from random DNA fragments of different bacteria with already known bacterial genomes.
- Folding. The functionality of proteins (which are the best catalysts known to mankind, capable of conducting almost any reaction) is determined by their three-dimensional structure. The three-dimensional structure is determined by the sequence of amino acids in the protein and some actions that the cell performs on the protein after its synthesis. Naturally, for the construction of proteins with desired properties, it is fundamentally important to be able to predict a three-dimensional structure from a linear sequence of amino acids. Molecular dynamics methods (direct modeling of the atoms that make up the molecule) pass on the number of atoms characteristic of proteins (tens of thousands). An example of the complexity of the structure of proteins can be, for example, the so-called protein auto splicing,
- Docking. Obviously, there are a lot of proteins and they interact with each other. Docking is the process of the interaction of proteins with each other and with simpler molecules. The calculation of this interaction includes folding as an integral part, but is not limited to it.
To which peaks does biology lead us?
As I already noted in the introduction, our life over the next couple of decades cannot but change. We have learned too much about the living for this knowledge to remain barren. So, for example, last year there was an event comparable to landing on the moon, but attracting much less attention - the creation of the first artificial organism. Hey world denominations! We humans have created life! For this, God is not needed! What's next?
- Medicines for cancer and AIDS. You need to understand that between the appearance of the medicine in the laboratories and on the market, about 5-10 years of testing and certification pass. Laboratories now have drugs that can cure certain types of cancer with a single injection ( publication ). No chemotherapy, hair loss, radiation, surgery and weight loss. The only injection. Could we at least hope so 10 years ago?
- Real biotechnology. Plants that do not require herbicides and pesticides; bananas ripening in the tundra; grass capable of competing with asphalt in strength. All this is possible and becomes reality right before our eyes.
- Real genetic diagnosis. Already, a startup (although it is possible to call the company the wife of Sergey Brin a start-up? :)) 23andme.com diagnoses dozens of hereditary diseases and predispositions (which can “shoot” 50 years ago) for $ 200. And this is just the beginning.
- Slowing down aging. Armed with new knowledge, a large number of scientists are working on research on the aging process. Given the explosive growth of biology in the last 10-20 years - many of us have a good chance not to die in the next 100 years :)
Conclusion
I hope this short excursion into modern biology was interesting. If someone is interested in something, I can try to write a continuation on topics of interest. In conclusion, I can make a small moral: don’t believe charlatans who claim that they know better how a person works and who talks about all kinds of “non-fixed energies”, “ soul ”and so on. Modern biology has almost left no completely dark places in the living, and the likelihood that some kind of matter unknown to physics will be needed to explain any effect is vanishingly small. Living is extremely difficult, but this complexity is simple in its foundations and relies on reactions that anyone can repeat in vitro without expensive reagents and equipment. I would also like to say special thanks to vyahhiand to all the people who made wonderful bioinformatics courses possible at SPbAU. You are very very cool.