Cartesian tree: Part 2. Valuable information in the tree and multiple operations with it
Table of contents (currently)
Part 1. Description, operations, applications.
Part 2. Valuable information in the tree and multiple operations with it.
Part 3. Cartesian tree by implicit key.
To be continued ...
The topic of today's lecture
Last time we met — frankly, very broadly — we met with the concept of a Cartesian tree and its basic functionality. Only so far we have used it in one unique way: as a “quasi-balanced" search tree. That is, let us be given an array of keys, add randomly generated priorities to them, and get a tree in which each key can be searched for, added and deleted in a logarithmic time and a minimum of effort. Sounds good, but not enough.
Fortunately (or unfortunately?), Real life is not limited to such trifling tasks. What will be discussed today. The first question on the agenda is the so-called K-th ordinal statistics, or an index in a tree, which will smoothly lead us to store user information at the vertices, and finally to the countless manipulations that may need to be performed with this information. Go.
We are looking for an index
In mathematics, the Kth ordinal statistic is a random variable that corresponds to the Kth largest element of a random sample from a probability space. Too smart. Let's go back to the tree: at every moment in time, we have a Cartesian tree, which could have changed significantly since its initial construction. We are required to very quickly find the Kth key in this tree in ascending order - in fact, if we present our tree as a constantly maintained sorted array, then this is simply access to the element under the index K. At first glance, it’s not very clear how to organize this: keys in our tree N, and they are scattered throughout the structure, anyhow.
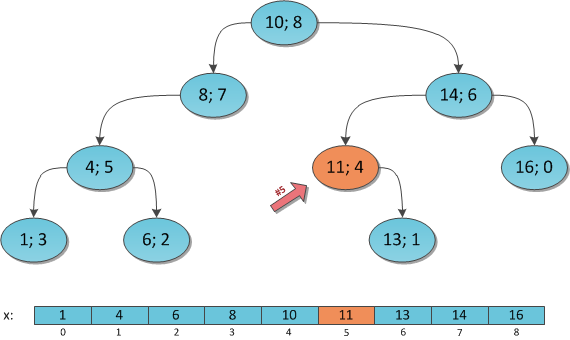
Although, frankly, not just anyhow. We know the property of the search tree - for each vertex its key is larger than all the keys of its left subtree, and less than all the keys of the right subtree. Therefore, to build the tree keys in sorted order, it is enough to carry out the so-called In-Order traversal on it, that is, go through the whole tree, fulfilling the principle of “first we will recursively bypass the left subtree, then the key of the root itself, and then recursively the right subtree”. If each key encountered in this way is recorded in a list, then in the end we will get a completely sorted list of all the vertices of the tree. Whoever does not believe can carry out the indicated procedure on the deramide from the figure a little higher - he will receive an array from the same figure.
The above arguments allow us to write an iterator for the Cartesian tree, so that by standard means of the language (foreachetc.), we will go through its elements in ascending order. In C #, you can simply write an in-order traversal function and use the operatoryield return, and in those where there is no such powerful functionality, you have to go one of two ways. Or store at each vertex a link to the "next" element in the tree, which gives an additional expense of valuable memory. Or writing a non-recursive tree traversal through its own stack, which is somewhat more difficult, but it will improve both the speed of the program and the memory costs.
Of course, such an approach is not worth considering as a complete solution to the problem, because it requires O (N) time, and this is unacceptable. But you can try to improve it, if we knew right away which parts of the tree it is not worth going into, because there are guaranteed large or smaller elements. And this is already quite possible to realize, if we remember for each vertex of the tree how many elements we will have to get around during a recursive entry into it. That is, we will store at each vertex its subtree size .
The figure shows the same tree with the sizes of subtrees affixed to each vertex.
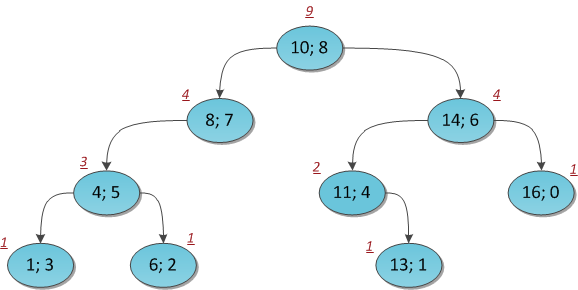
Then suppose that we honestly calculated the number of vertices in each subtree. Now we find the K -th element in the index, starting with zero (!).
The algorithm is clear: we look at the root of the tree and at the size of its left subtree S L , the size of the right one is not even needed.
If S L = K, then we found the required element, and this is the root.
If S L > K, then the desired element is somewhere in the left subtree, go down there and repeat the process.
If S L <K, then the desired element is somewhere in the right subtree. Reduce K by the number S L+1 to correctly respond to the sizes of the subtrees on the right, and repeat the process for the right subtree.
I will model this search for K = 6 on the same tree:
Vertex (10; 8), S L = 4, K = 6. We go to the right, decreasing K by 4 + 1 = 5.
The top (14; 6), S L = 2, K = 1. We go to the left without changing K.
The top (11; 4), S L = 0 (there is no left son), K = 1. We go to the right, decreasing K by 0 + 1 = 1.
The top (13; 1), S L = 0 (no left son), K = 0. The key is found.
Answer: the key under index 6 in the Cartesian tree is 13.
All of this passage, in principle, is very similar to a simple key search in the binary search tree - we just go down the tree, comparing the desired parameter with the parameter at the current vertex, and depending on the situation, turn left or right. I will say in advance - we will meet with a similar situation in different algorithms more than once, it is completely typical for various binary trees. The traversal algorithm is so typical that it is easily templated. As you can see, recursion is not even needed here, we can do with a simple cycle with a couple of variables changing with each iteration.
In a functional language, you can write a solution through recursion, and it will look and read much more beautifully, without losing a drop in performance: the recursion is tail-based, and the compiler will immediately optimize it in the same normal loop. For those who know functional programming, but doubt in my words - Haskell code:Speaking of performance. The search execution time for the Kth element is obviously O (log 2 N), because we just went down from top to bottom of the tree.dataOrd a => Treap a = Null
| Node { key::a, priority::Int, size::Int, left::(Treap a), right::(Treap a) }
sizeOf :: (Ord a) => Treap a ->Int
sizeOf Null = 0
sizeOf Node {size=s} = s
kthElement :: (Ord a) => (Treap a) ->Int->Maybe a
kthElement Null _ = Nothing
kthElement (Node key __ left right) k
| sizeLeft == k = Just key
| sizeLeft < k = kthElement left k
| sizeLeft > k = kthElement right (k - sizeLeft - 1)
where sizeLeft = sizeOf left
In order not to offend readers, in addition to the functional, I will also cite the traditional source code in C #. In it
Treap, one more integer field Size, the size of the subtree, as well as a useful function SizeOffor obtaining it , is added to the standard class blank in the first part .public static int SizeOf(Treap treap)
{
return treap == null ? 0 : treap.Size;
}
public int? KthElement(int K)
{
Treap cur = this;
while (cur != null)
{
int sizeLeft = SizeOf(cur.Left);
if (sizeLeft == K)
return cur.x;
cur = sizeLeft > K ? cur.Left : cur.Right;
if (sizeLeft < K)
K -= sizeLeft + 1;
}
return null;
}
The key issue still remains the fact that we still do not know how to maintain the correct values in the tree
size. After all, after the very first addition of a new key to the tree, all these numbers will go to dust, and to recount them every time again - O (N)! However, no. O (N) it would take after some operation that completely redispersed the tree into a structure of incomprehensible construction. And here is the addition of the key, which acts more accurately and does not touch the whole tree, but only its small part. So you can get by with less blood.Как вы помните, у нас с вами все делается, так сказать, через Split и Merge. Если приспособить эти две основные функции под поддержку дополнительной информации в дереве — в данном случае размеров поддеревьев — то все остальные операции автоматически станут выполняться корректно, ведь своих изменений в дерево они не вносят (за исключением создания элементарных деревьев из одной вершины, в которых
Size нужно не забыть установить по дефолту в 1!).Я начну с модификации операции Merge.

Recall the Merge execution routine. She first selected the root for the new tree, and then recursively merged one of its subtrees with another tree and wrote down the result in the place of the removed subtree. I will analyze the case when it was necessary to merge the right subtree, the second is symmetrical. Like last time, recursion will help us a lot.
Let us make an induction hypothesis: even after Merge is executed on subtrees, everything is already correctly calculated in them. Then we have the following state of things: in the left subtree, the dimensions are calculated correctly, because nobody touched him; in the right are also calculated correctly, because This is the result of Merge. Restore justice remains only at the very root of the new tree! Well, just recount it before completing
size = left.size + right.size + 1)The source code of Merge will change slightly: to the recalculation line before returning the answer. She is marked by a comment.
public void Recalc()
{
Size = SizeOf(Left) + SizeOf(Right) + 1;
}
public static Treap Merge(Treap L, Treap R)
{
if (L == null) return R;
if (R == null) return L;
Treap answer;
if (L.y > R.y)
{
var newR = Merge(L.Right, R);
answer = new Treap(L.x, L.y, L.Left, newR);
}
else
{
var newL = Merge(L, R.Left);
answer = new Treap(R.x, R.y, newL, R.Right);
}
answer.Recalc(); // пересчёт!
return answer;
}
Exactly the same situation awaits us with the Split operation, which is also based on a recursive call. Let me remind you: here, depending on the key value in the root of the tree, we recursively divided either the left or the right subtree of the source one by the specified key, and one of the results was suspended back, and the second was returned separately. Again, even for the sake of clarity, we recursively divide T.Right.
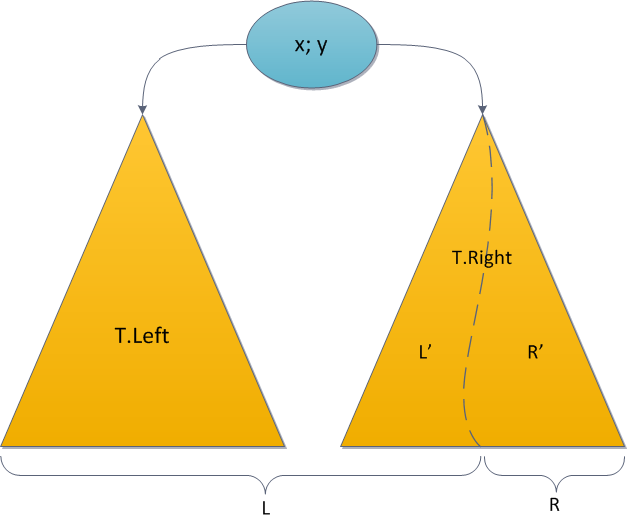
The familiar induction hypothesis — let Split recursive calls all count correctly — will help us this time too. Then the dimensions in T.Left are correct - no one touched them; dimensions in L 'are correct - this is the left result of Split; dimensions in R 'are correct - this is the right Split result. Before completing, you need to restore justice at the root
The source code of the new Split, in which two added lines recount the value
Sizein the root of L or R, depending on the variant.public void Recalc()
{
Size = SizeOf(Left) + SizeOf(Right) + 1;
}
public void Split(int x, out Treap L, out Treap R)
{
Treap newTree = null;
if (this.x <= x)
{
if (Right == null)
R = null;
else
Right.Split(x, out newTree, out R);
L = new Treap(this.x, y, Left, newTree);
L.Recalc(); // пересчёт в L!
}
else
{
if (Left == null)
L = null;
else
Left.Split(x, out L, out newTree);
R = new Treap(this.x, y, newTree, Right);
R.Recalc(); // пересчёт в R!
}
}
The discussed “restoration of justice” - recalculation of the value at the top - I singled out as a separate function. This is the basic line on which the functionality of the entire Cartesian tree rests. And when in the second half of the article we are going to have numerous multiple operations, each with its own “recovery”, it will be much more convenient to change it in one single place than throughout the class code. Such a function has one common property: it assumes that everything is fair in the left son, everything is fair in the right son, and based on these data it recalculates the parameter in the root. Thus, it is possible to support any additional parameters that are calculated from descendants, the sizes of subtrees are just a special example.
Welcome to the real world
Let's get back to real life. In it, data that has to be stored in a tree is not limited to just one key. And with this data constantly have to make some kind of manipulation. For example, in this article I will call such a new field of the breath
Cost. So, let us constantly receive (and sometimes delete) the keys at the entrance
x, and the corresponding price is associated with each of them Cost. And you need to maintain fast requests at the maximum price in all this mess . You can ask the maximum in the whole structure, but only in some sub-segment: say, the user may be interested in the maximum price for 2007 (if the keys are time-related, then this can be interpreted as a request for a maximum price on a set of such elements, where This does not represent any difficulty, because the maximum also fits perfectly as a candidate for the function of “restoring justice”. Just write like this:
public double Cost;
// Максимум
public double MaxTreeCost;
public static double CostOf(Treap treap)
{
return treap == null ? double.NegativeInfinity : treap.MaxTreeCost;
}
public void Recalc()
{
MaxTreeCost = Math.Max(Cost, Math.Max(CostOf(Left), CostOf(Right)));
}
The same situation is with the minimum, and with the sum, and with some Boolean characteristics of the element (the so-called "color" or "marking"). For instance:
// Сумма
public double SumTreeCost;
public static double CostOf(Treap treap)
{
return treap == null ? 0 : treap.SumTreeCost;
}
public void Recalc()
{
SumTreeCost = Cost + CostOf(Left) + CostOf(Right);
}
Or:
public bool Marked;
// Помеченность
public bool TreeHasMarked;
public static bool MarkedOf(Treap treap)
{
return treap == null ? false : treap.TreeHasMarked;
}
public void Recalc()
{
TreeHasMarked = Marked || MarkedOf(Left) || MarkedOf(Right);
}
The only thing to remember in such cases is to initialize these parameters in the constructor when creating new individual vertices.
As they would say in a functional world, you and I are doing some kind of tree folding .
Thus, we can request the value of the parameter for the whole tree - it is stored in the root. Queries on subsegments are also not difficult, if we again recall the property of a binary search tree. The key of each vertex is larger than all the keys of the left subtree and less than all the keys of the right subtree. Therefore, we can virtually assume that each vertex is associated with some interval of keys that can theoretically occur in it and in its subtree. So, at the root this is the interval
For clarity, I will show in the figure the corresponding interval for each vertex of the Cartesian tree already explored.

Now it’s clear that the parameter stored in the vertex is responsible for the value of the corresponding characteristic (maximum, sum, etc.) for the entire key on the interval of this vertex.
And we can respond to requests at intervals
Someone familiar with the tree of segments might think that it is worth applying the same recursive descent, gradually localizing the current vertex to one that fully corresponds to the desired interval or its piece. But we will do it easier and faster, reducing the task to the previous one.
Masterfully owning scissors, we will divide the tree first by key A-1. The right Split result, which stores all keys greater than or equal to A, is split again - this time by the key B. In the middle, we get a tree with all the elements for which the keys belong to the desired interval. To find out a parameter, it is enough to look at its value in the root - after all, the Split function has already done all the black work for restoring justice for each tree :)
The query’s running time is obviously O (log 2 N): two Split executions. Source code for maximum:
public double MaxCostOn(int A, int B)
{
Treap l, m, r;
this.Split(A - 1, out l, out r);
r.Split(B, out m, out r);
return CostOf(m);
}
The power of deferred computing
Aerobatics of today is the ability to change user information during the life of a tree. It is clear that after changing the value
Costat some vertex, all our previous parameters that have accumulated answers for the values in their subtrees are no longer valid. You can, of course, go through the whole tree and recount them again, but this is again O (N), and does not climb into any gates. What to do? When it comes to simple change
Costin one single peak, then this is not such a problem. First, we, moving from top to bottom, find the desired element. We change the information in it. And then, moving back from the bottom up to the root, we simply recalculate the parameter values with the standard function - after all, this change will not affect any other subtrees, except for those that we visited along the path from the root to the top. I believe that the source code doesn’t make much sense, the task is trivial: solve it with at least recursion, at least two cycles, the run time is still O (log 2 N). Life becomes much more fun if you need to support multiple operations . Let us have a Cartesian tree, each of its vertices stores user information
Cost. And we want to each valueCostin the tree (or subtree - see the discussion of intervals) add one and the same number A. This is an example of a multiple operation, in this case adding a constant on a segment. And here you can’t do with a simple passage to the root. Let's get an additional parameter at each vertex, call it
Add. Its essence is as follows: it will signal that the entire subtree growing from a given vertex is supposed to add a constant lying in Add. It turns out such a delayed addition: if necessary, change the values to A in some subtree, we change only the root in this subtreeAdd, as if giving a promise to posterity that "someday in the future you all are supposed to have an additional addition, but we will not actually carry it out until we need it." Then the request
Costfrom the root of the tree must perform another additional action, adding to the Costroot Add, and the resulting amount should be regarded as actual Cost, as if lying in the root of the tree. The same thing with requests for additional parameters, for example, the sum of prices in the tree: we have a correctly (!) Calculated value SumTreeCostin the root that stores the sum of all elements of the tree, but not taking into account the fact that we are supposed to add a certain to all these elements Add. For truly correct sum value, taking into account all pending operations is enough to add to the SumTreeCostvalue ofAddtimes the Sizenumber of elements in the subtree. It is still not very clear what to do with the standard operations of the Cartesian tree — Split and Merge — and when we still need to fulfill the promise and add to the descendants the promise that they promised
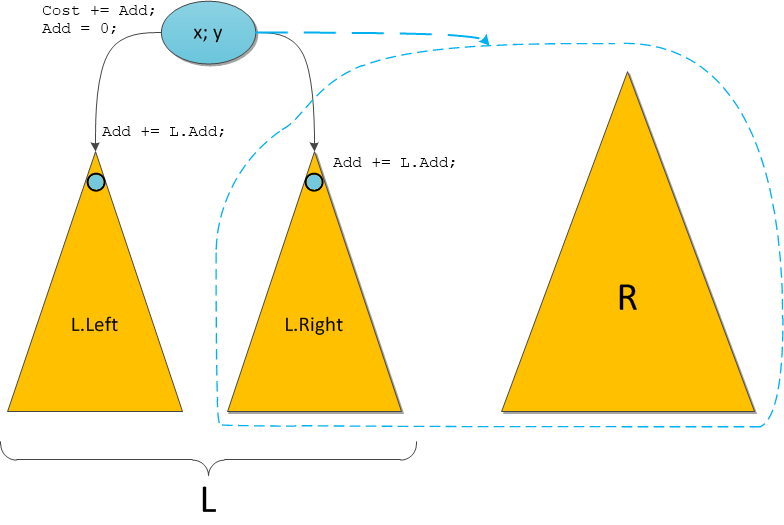
Add. Now I will consider these issues. Take up the Split operation again. Since the original tree is divided into two new ones, and we lose the original one, the delayed addition will have to be partially performed. Namely: let the recursive call Split divide at us the right subtree of T.Right. Then we will carry out such manipulations:
• We will fulfill the promise in the root, add the root
Costvalue to the root Add.T.Cost + = T.Add;• “Let’s” promise to the left: the entire left subtree also relies
Add. But since the recursion does not go to the left, we do not need to actively touch this subtree. Just make a promise.T.Left.Add + = T.Add;• “Let’s” promise to the right: the entire right subtree also relies
Add. This must be done before the recursive call, so that the Split operation manipulates the correct Cartesian tree. The recursion itself will do a further update.T.Right.Add + = T.Add;• We make the set recursive call. Split returned two correct Cartesian trees to us.
• Since we honestly fulfilled the promise in the root, and honestly wrote down the promises for posterity, the root
Addshould be reset.T.Add = 0;• Further attachment of subtrees in Split is performed as usual. As a result, there are two correct Cartesian trees with relevant information on promises: somewhere fulfilled, somewhere only deferred, but relevant.
All operations are indicated on the new Split diagram.
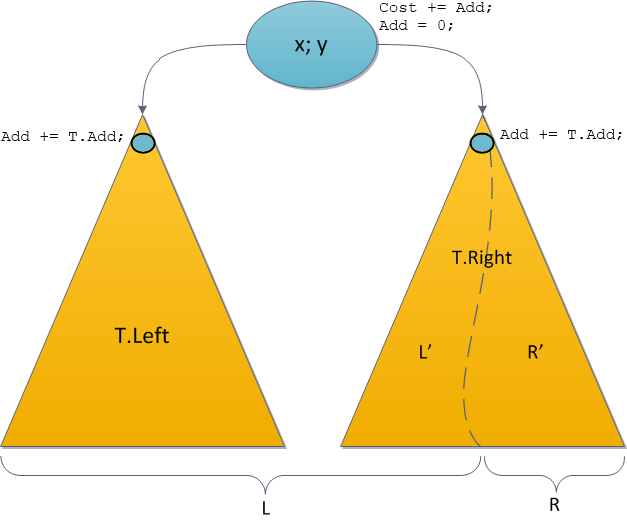
Note that actual updates are carried out only at the vertices along which the Split operation will go recursively, for the rest, at best, we will lower the promise a little lower. The same situation will be with Merge.
The new Merge basically does the same. Let it need to recursively merge the right subtree of L.Right with the right input tree R. Then we do the following:
• Keep the promise in the root L.
L. Cost + = L. Add;• “Let’s” promise to the descendants of L - for the future.
L.Left.Add + = L.Add; L.Right.Add + = L.Add;• The promise is fundamentally fulfilled - you can forget about it.
L.Add = 0;• We make the necessary recursive call
• We hang the returned tree with the right son, as before. As a result - again a Cartesian tree with relevant information on promises.
Now that we are able to make queries in the root and change on the whole tree, it is not difficult to scale this solution for subsegments, simply applying the same principle as in a few paragraphs above.
We make two calls to Split, selecting the subtree corresponding to the desired key interval in a separate tree.
Let us increase the root promise of this tree
Addfor this A. We will get the correct tree with a delayed addition.We merge again all three trees together with two calls
Mergeand write in the place of the original. Now the keys at a given interval live honestly with the promise that they should all add A. someday in the future. The source code of this manipulation can be left as an exercise to the reader :)
After all operations, do not forget to restore justice in the roots by calling a new version of the function Recalc. This new option should take into account deferred additions, as already described in the story about the queries.In conclusion, I note that multiple operations, of course, are not limited to just adding on a segment. You can also “paint” on a line — set all elements to a Boolean parameter, change — set all values
Coston the line to one value, and so on, which the programmer’s imagination can only imagine. The main condition for the operation is that it can be pushed down from the root to the descendants in Summary
We have learned to maintain various user additional information in the Cartesian tree, and to carry out a huge number of multiple manipulations with it, and each request or change, whether at a single vertex or on a segment, is performed in logarithmic time. Together with the elementary properties of the Cartesian tree described in the first part, this already represents a huge scope for using it in practice in any system where it is required to store significant amounts of data, and periodically request any statistics from these data.
But in the next part, I will make a Cartesian tree a small modification that will turn it into a tool of truly tremendous power for everyday needs. This miracle will be called "Cartesian tree by an implicit key."
Thank you all for your attention.