Introducing the World's Fastest VP8 Decoder: ffvp8
- Transfer
Even at the moment when I was writing the initial review of VP8 , I noticed that the official decoder, libvpx , is very slow. There are no special reasons why it should be significantly faster than a good H.264 decoder , but it also has nothing to be so slow with! So I had a plan to write the best version for FFmpeg along with Ronald Bultje and David Conrad. This implementation of the decoder was supposed to be developed by the community and be free from the very beginning, unlike the dump of proprietary code, which was the libvpx library. A few weeks ago, the decoder was sufficiently complete to ensure binary compatibility of the video stream with libvpx, which made itthe first independent and free implementation of the VP8 decoder . Now that we have completed the first cycle of optimizations, it should have been ready for use in real conditions. I will talk about the details of the development process later, but now let's move on to the very salt of this post: the results of comparative testing of codec performance.
We tested the decoder on two 1080p clips: Parkjoy , shot live, and Sintel trailer , created on the computer. Testing was carried out as follows:
We used the latest at the time of this post assembly of FFmpeg from SVN, the last revision containing the VP8 decoder optimizations was r24471.
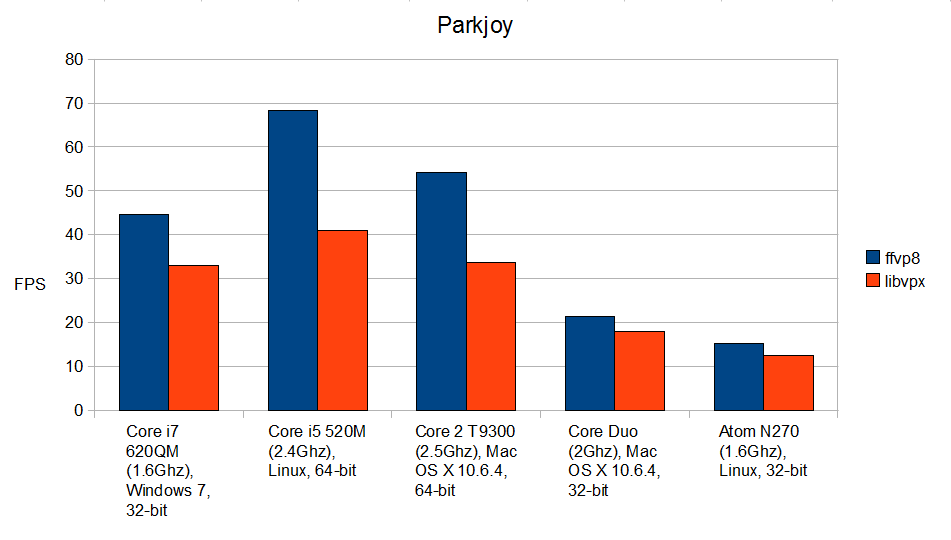

As these graphs show, ffvp8 is much faster than libvpx, especially on 64-bit platforms. Even on Atom processors, it runs significantly faster, despite the fact that we have not even optimized it specifically for Atom. In many cases, this difference in performance will determine whether the video is playing or not, especially in modern browsers, whose engines consume a significant part of the processor’s resources. Want VP8 video to play faster? New versions of players based on FFmpeg (and this is the well-known VLCand many others) will include the ffvp8 library. Want VP8 video to decode faster in your browser? Communicate with its developers, and insist that they use ffvp8 instead of libvpx. I believe that Chrome will be the first to use ffvp8, as they already use libavcodec in their video playback subsystem.
Remember that the development of ffvp8 does not end there, we will continue to improve and speed it up. We still have a queue of optimizations that have not yet been included in the main development branch.
Ffvp8 development
The first task that David and Ronald took up was to recreate the core of the decoder and bring it to binary compatibility of the stream with libvpx. This was not easy, given the incomplete official specification. Many parts of the specification were generally incorrect and contradicted libvpx code. And of course, the fact that the set of official compatibility tests does not even cover all the features that the official encoder uses does not help our work! In order to somehow work further in this state of things, we had to start adding our own tests. But I already complained about the poor quality of specifications in my previous posts, so let's move on to the nuances.
The next step was to add a SIMD code for all important DSP functions.. Basically, the load on the processor in the VP8 decoder is created by motion compensation and a deblocking filter ( compensation of encoding artifacts, trans. ) - the same as in H.264. But, unlike H.264, the deblocking filter relies on internal arithmetic with saturation , which costs nothing in the SIMD implementation, but is very “gluttonous” with respect to the processor in the implementation on C. Of course, neither of these presents a serious problem , since in all normal codecs these processes are implemented as SIMD code.
I helped Ronald with SIMD for x86, and also wrote most of the motion compensation, internal prediction, and part of the inverse transforms. Ronald wrote the remainder of the inverse transforms and the motion compensation part. In addition, he did the hardest part: the deblocking filter. These filters are always the hard part, as they are different in each codec. The implementation of motion compensation, by comparison, is usually not too different in different codecs: a 6-tap filter will in any case be a 6-tap filter, and the difference is usually only in the coefficients.
The biggest difficulty in the SIMD deblocking filter was to avoid “unpacking”, i.e. transition from 8 bits to 16. Many operations in such filters initially seem to require more than 8 bits of accuracy. A simple example for x86 is abs (ab), where a and b are 8-bit unsigned integers. The result “ab” requires an accuracy of 9 bits with a sign (since it can be anywhere between -255 and 255), so it cannot fit in 8 bits. But it is quite possible to solve this problem without "unpacking": (satsub (a, b) | satsub (b, a)), where "satsub" calculates the difference with saturation between the two values. If the difference is positive, the result is returned, otherwise it is zero, so performing a logical OR between the results of these functions gives us exactly what we need. This requires 4 x86 assembler instructions,
This was followed by SIMD optimization of the C code, the execution of which still took up a significant part of the decoding time. One of my biggest optimizations was the addition of smart prefetch, which reduces the number of cache misses. ffvp8 pre-queries frames referenced by the current one (“PREVIOUS”, “GOLD” and “ALTERNATIVE LINK”, they are PREVIOUS, GOLD and ALTREF), but only when they are really tangibly used in this frame. This allows us to pre-query everything that we need and not to request what we are unlikely to use. libvpx, as a rule, encodes frames that almost never (but do not understand it as “never at all”) use GOLDEN or ALTREF frames, so this optimization significantly reduces the time spent on pre-requests in many real videos. Moreover, we have done so many optimizations in different places in the code that we cannot list all of them here, as, for example, the optimization of the entropy decoder made by David. I would also like to thank Eli Friedman for his invaluable help in testing the performance of most of these improvements.
What's next? Altivec assembly code ( PPC ) is virtually absent; there are only a few features from David's motion compensation code. There is no assembly code for NEON ( ARM ) at all, and we need it to work quickly and on mobile devices. Of course, all this will happen over time, and, as usual, we are always happy with patches!
Here are the numbers corresponding to the above graphs, in frames per second and with standard errors :
Core i7 620QM (1.6Ghz), Windows 7, 32-bit:
Parkjoy ffvp8: 44.58 ± 0.44
Parkjoy libvpx: 33.06 ± 0.23
Sintel ffvp8: 74.26 ± 1.18
Sintel libvpx: 56.11 ± 0.96
Core i5 520M (2.4Ghz), Linux, 64-bit:
Parkjoy ffvp8: 68.29 ± 0.06
Parkjoy libvpx: 41.06 ± 0.04
Sintel ffvp8: 112.38 ± 0.37
Sintel libvpx: 69.64 ± 0.09
Core 2 T9300 (2.5Ghz ), Mac OS X 10.6.4, 64-bit:
Parkjoy ffvp8: 54.09 ± 0.02
Parkjoy libvpx: 33.68 ± 0.01
Sintel ffvp8: 87.54 ± 0.03
Sintel libvpx: 52.74 ± 0.04
Core Duo (2Ghz), Mac OS X 10.6.4, 32-bit:
Parkjoy ffvp8: 21.31 ± 0.02
Parkjoy libvpx: 17.96 ± 0.00
Sintel ffvp8: 41.24 ± 0.01
Sintel libvpx: 29.65 ± 0.02
Atom N270 (1.6Ghz), Linux, 32-bit:
Parkjoy ffvp8: 15.29 ± 0.01
Parkjoy libvpx: 12.46 ± 0.01
Sintel ffvp8: 26.87 ± 0.05
Sintel libvpx: 20.41 ± 0.02
Some terms have remained a mystery to me, for example, if someone can tell me the correct Russian translation of the 6-tap filter, I will be very grateful.
Below, in the comments to the note, the author gives answers to some questions from readers, some of which I found it appropriate to give here. This is not a direct translation of questions and answers, but rather a summary of their essence.
Q: Can ffvp8 use the improvements that are made to libvpx?
A: In fact, all the optimizations that seemed interesting are already taken from there. But you need to understand that simply merging the source code is not enough here, since the architecture of the decoders is fundamentally different.
Q: Is there a danger that ffvp8 will not be able to maintain compatibility with the libvpx experimental development branch?
A: Such a task is not worth it, because at the moment the experimental branch is not intended for use in real conditions. Even the compatibility of the experimental branch with the current libvpx is not guaranteed.
Q: Who sponsors the development of FFmpeg?
A: The whole project is nobody, but some developers get money for the implementation of features needed by specific customers. As far as the author knows, the development of ffvp8 was completely non-profit.
Q: The increase in performance is due to one kind of global disadvantage of libvpx, or has there simply been a lot of optimizations here and there?
A: In general, rather the second. But the main performance gain was due to the fact that libvpx goes through the frame several times (all previous On2 codecs do the same), and ffvp8 does all the operations in one pass.
Q: Are you planning to develop your own VP8 encoder in FFmpeg?
A: This is a very big job, and to be honest, I doubt that it will ever be done. In fact, the only "native" encoder that FFmpeg has is the mpeg encoder, and there is hardly any way to make a VP8 encoder based on the existing framework, in any case, this method will not be simple. But of course, if someone wants to try ...
Q: But if for FFmpeg the only native encoder is mpeg, then how does this library support video encoding not only in mpeg, but also in WMV 7/8, H.261 / 3 and other formats without using other libraries?
A: All of these encoders actually use the internal mpeg encoder with slight variations for each format. It should be borne in mind that the encoder is a large and complex program consisting of many parts, and the only significant difference between the encoders of the listed formats is the entropy encoding algorithm and headers. Both can be easily replaced without having to change the rest of the code. This is why there are so many “encoders” in FFmpeg that are all based on the main mpeg encoder: in fact, the difference between these algorithms is not so significant (they are all similar MPEGs based on discrete cosine transform of 8x8 pixel blocks), so for all of them it can pretty much the same code be used.
This, by the way, explains the lack of a WMV9 encoder in FFmpeg - this algorithm is too different from previous versions so that it can be easily implemented based on what is.
Q: Can ffvp8 also decode VP4, 5, 6 and 7?
A: Maybe, but only VP4, 5 and 6, since no one has yet reverse-engineered VP7. But, most likely, support for VP7 will appear in the near future, given the opening of VP8, since I have a suspicion that VP7 and VP8 are mostly the same.
Q: Where can I get fresh SVN assemblies of Media Player Classic HomeCinema and FFDshow tryouts to see for yourself on a new Windows decoder?
A: xhmikosr.1f0.de
If you have any questions for the author of the note, I am ready to translate them and publish it on his blog.
We tested the decoder on two 1080p clips: Parkjoy , shot live, and Sintel trailer , created on the computer. Testing was carried out as follows:
time ffmpeg -vcodec {libvpx or vp8} -i input -vsync 0 -an -f null -We used the latest at the time of this post assembly of FFmpeg from SVN, the last revision containing the VP8 decoder optimizations was r24471.
As these graphs show, ffvp8 is much faster than libvpx, especially on 64-bit platforms. Even on Atom processors, it runs significantly faster, despite the fact that we have not even optimized it specifically for Atom. In many cases, this difference in performance will determine whether the video is playing or not, especially in modern browsers, whose engines consume a significant part of the processor’s resources. Want VP8 video to play faster? New versions of players based on FFmpeg (and this is the well-known VLCand many others) will include the ffvp8 library. Want VP8 video to decode faster in your browser? Communicate with its developers, and insist that they use ffvp8 instead of libvpx. I believe that Chrome will be the first to use ffvp8, as they already use libavcodec in their video playback subsystem.
Remember that the development of ffvp8 does not end there, we will continue to improve and speed it up. We still have a queue of optimizations that have not yet been included in the main development branch.
Ffvp8 development
The first task that David and Ronald took up was to recreate the core of the decoder and bring it to binary compatibility of the stream with libvpx. This was not easy, given the incomplete official specification. Many parts of the specification were generally incorrect and contradicted libvpx code. And of course, the fact that the set of official compatibility tests does not even cover all the features that the official encoder uses does not help our work! In order to somehow work further in this state of things, we had to start adding our own tests. But I already complained about the poor quality of specifications in my previous posts, so let's move on to the nuances.
The next step was to add a SIMD code for all important DSP functions.. Basically, the load on the processor in the VP8 decoder is created by motion compensation and a deblocking filter ( compensation of encoding artifacts, trans. ) - the same as in H.264. But, unlike H.264, the deblocking filter relies on internal arithmetic with saturation , which costs nothing in the SIMD implementation, but is very “gluttonous” with respect to the processor in the implementation on C. Of course, neither of these presents a serious problem , since in all normal codecs these processes are implemented as SIMD code.
I helped Ronald with SIMD for x86, and also wrote most of the motion compensation, internal prediction, and part of the inverse transforms. Ronald wrote the remainder of the inverse transforms and the motion compensation part. In addition, he did the hardest part: the deblocking filter. These filters are always the hard part, as they are different in each codec. The implementation of motion compensation, by comparison, is usually not too different in different codecs: a 6-tap filter will in any case be a 6-tap filter, and the difference is usually only in the coefficients.
The biggest difficulty in the SIMD deblocking filter was to avoid “unpacking”, i.e. transition from 8 bits to 16. Many operations in such filters initially seem to require more than 8 bits of accuracy. A simple example for x86 is abs (ab), where a and b are 8-bit unsigned integers. The result “ab” requires an accuracy of 9 bits with a sign (since it can be anywhere between -255 and 255), so it cannot fit in 8 bits. But it is quite possible to solve this problem without "unpacking": (satsub (a, b) | satsub (b, a)), where "satsub" calculates the difference with saturation between the two values. If the difference is positive, the result is returned, otherwise it is zero, so performing a logical OR between the results of these functions gives us exactly what we need. This requires 4 x86 assembler instructions,
This was followed by SIMD optimization of the C code, the execution of which still took up a significant part of the decoding time. One of my biggest optimizations was the addition of smart prefetch, which reduces the number of cache misses. ffvp8 pre-queries frames referenced by the current one (“PREVIOUS”, “GOLD” and “ALTERNATIVE LINK”, they are PREVIOUS, GOLD and ALTREF), but only when they are really tangibly used in this frame. This allows us to pre-query everything that we need and not to request what we are unlikely to use. libvpx, as a rule, encodes frames that almost never (but do not understand it as “never at all”) use GOLDEN or ALTREF frames, so this optimization significantly reduces the time spent on pre-requests in many real videos. Moreover, we have done so many optimizations in different places in the code that we cannot list all of them here, as, for example, the optimization of the entropy decoder made by David. I would also like to thank Eli Friedman for his invaluable help in testing the performance of most of these improvements.
What's next? Altivec assembly code ( PPC ) is virtually absent; there are only a few features from David's motion compensation code. There is no assembly code for NEON ( ARM ) at all, and we need it to work quickly and on mobile devices. Of course, all this will happen over time, and, as usual, we are always happy with patches!
Application: bare numbers
Here are the numbers corresponding to the above graphs, in frames per second and with standard errors :
Core i7 620QM (1.6Ghz), Windows 7, 32-bit:
Parkjoy ffvp8: 44.58 ± 0.44
Parkjoy libvpx: 33.06 ± 0.23
Sintel ffvp8: 74.26 ± 1.18
Sintel libvpx: 56.11 ± 0.96
Core i5 520M (2.4Ghz), Linux, 64-bit:
Parkjoy ffvp8: 68.29 ± 0.06
Parkjoy libvpx: 41.06 ± 0.04
Sintel ffvp8: 112.38 ± 0.37
Sintel libvpx: 69.64 ± 0.09
Core 2 T9300 (2.5Ghz ), Mac OS X 10.6.4, 64-bit:
Parkjoy ffvp8: 54.09 ± 0.02
Parkjoy libvpx: 33.68 ± 0.01
Sintel ffvp8: 87.54 ± 0.03
Sintel libvpx: 52.74 ± 0.04
Core Duo (2Ghz), Mac OS X 10.6.4, 32-bit:
Parkjoy ffvp8: 21.31 ± 0.02
Parkjoy libvpx: 17.96 ± 0.00
Sintel ffvp8: 41.24 ± 0.01
Sintel libvpx: 29.65 ± 0.02
Atom N270 (1.6Ghz), Linux, 32-bit:
Parkjoy ffvp8: 15.29 ± 0.01
Parkjoy libvpx: 12.46 ± 0.01
Sintel ffvp8: 26.87 ± 0.05
Sintel libvpx: 20.41 ± 0.02
Translator Notes
Some terms have remained a mystery to me, for example, if someone can tell me the correct Russian translation of the 6-tap filter, I will be very grateful.
Below, in the comments to the note, the author gives answers to some questions from readers, some of which I found it appropriate to give here. This is not a direct translation of questions and answers, but rather a summary of their essence.
Q: Can ffvp8 use the improvements that are made to libvpx?
A: In fact, all the optimizations that seemed interesting are already taken from there. But you need to understand that simply merging the source code is not enough here, since the architecture of the decoders is fundamentally different.
Q: Is there a danger that ffvp8 will not be able to maintain compatibility with the libvpx experimental development branch?
A: Such a task is not worth it, because at the moment the experimental branch is not intended for use in real conditions. Even the compatibility of the experimental branch with the current libvpx is not guaranteed.
Q: Who sponsors the development of FFmpeg?
A: The whole project is nobody, but some developers get money for the implementation of features needed by specific customers. As far as the author knows, the development of ffvp8 was completely non-profit.
Q: The increase in performance is due to one kind of global disadvantage of libvpx, or has there simply been a lot of optimizations here and there?
A: In general, rather the second. But the main performance gain was due to the fact that libvpx goes through the frame several times (all previous On2 codecs do the same), and ffvp8 does all the operations in one pass.
Q: Are you planning to develop your own VP8 encoder in FFmpeg?
A: This is a very big job, and to be honest, I doubt that it will ever be done. In fact, the only "native" encoder that FFmpeg has is the mpeg encoder, and there is hardly any way to make a VP8 encoder based on the existing framework, in any case, this method will not be simple. But of course, if someone wants to try ...
Q: But if for FFmpeg the only native encoder is mpeg, then how does this library support video encoding not only in mpeg, but also in WMV 7/8, H.261 / 3 and other formats without using other libraries?
A: All of these encoders actually use the internal mpeg encoder with slight variations for each format. It should be borne in mind that the encoder is a large and complex program consisting of many parts, and the only significant difference between the encoders of the listed formats is the entropy encoding algorithm and headers. Both can be easily replaced without having to change the rest of the code. This is why there are so many “encoders” in FFmpeg that are all based on the main mpeg encoder: in fact, the difference between these algorithms is not so significant (they are all similar MPEGs based on discrete cosine transform of 8x8 pixel blocks), so for all of them it can pretty much the same code be used.
This, by the way, explains the lack of a WMV9 encoder in FFmpeg - this algorithm is too different from previous versions so that it can be easily implemented based on what is.
Q: Can ffvp8 also decode VP4, 5, 6 and 7?
A: Maybe, but only VP4, 5 and 6, since no one has yet reverse-engineered VP7. But, most likely, support for VP7 will appear in the near future, given the opening of VP8, since I have a suspicion that VP7 and VP8 are mostly the same.
Q: Where can I get fresh SVN assemblies of Media Player Classic HomeCinema and FFDshow tryouts to see for yourself on a new Windows decoder?
A: xhmikosr.1f0.de
If you have any questions for the author of the note, I am ready to translate them and publish it on his blog.