Social Graph Analysis

The number of US patent applications related to social networks over the past 5 years has grown by 250% every year ( link ). So, for example, one corporation filed a patent application for a pricing method that takes into account the position of the buyer in the social graph ( discussion on Slashdot ). Another corporation recently implemented the most simplified version of this scheme, selling its new phones to influential social graph nodes for $ 0, and the rest for $ 530.
The analysis of social networks ( Social Network Analysis ) existed long before the Internet, but recently is gaining momentum.
I was interested to see how effectively the algorithm for highlighting clusters in graphs works for some groups on Twitter that are of interest to me.
January 23 in Zaporozhye will be #UKRTWEET - the first all-Ukrainian barcamp dedicated to Twitter. The graph above shows which of its participants, with whom it talks and whom it mentions.
The note below is devoted to the analysis of this graph. All the code for the scripts used here is on github . The presentation, to some extent, is inspired by the recently- written book on To Habré by Toby Segaran, “Programming the collective mind,” an example code of which is available on the author’s website .
I also talked about data mining on Twitter on January 16 at the first meeting of Coffee and Code in Donetsk this year. Therefore, here, in parallel, I will analyze a group of people from Donetsk who write on Twitter. By the way, this year the Donetsk meetings will be regular - every third Saturday of the month (next February 20). Keep track of the group .
1. Getting information
To get started, we get a list of all group members. The list of #UKRTWEET members is on the barcamp page. Download and parse it using BeautifulSoup ( code ). For people who tweet from Donetsk, I keep a list of @ dudarev / donetsk . We save its participants using the tweepy library ( code ).
For each of the participants, download the last 100 tweets and save them. Tweepy automatically parses JSON, and since this time we want to save the data as it is, we tweak the tweepy.API class ( code ) a bit .
2. What are they talking about
Now you can analyze the information. And first, a couple of observations not related to the social graph. Let's see which hashtags are most commonly used by each group. To do this, we write a utility that, taking a string, returns a list of all the hashtags it contains. To write it, TDD is very helpful ( see the code ). With the help of this utility, we parse all tweets ( code ).
The most frequently mentioned hashtags by #UKRTWEET participants (the number in brackets is the number of different people who used this hashtag):
- ukrtweet (20)
- sledui (20)
- elect_ua (16)
- ru_ff (10)
- zp_ua (9)
- nicua (9)
- google (9)
- twitter (7)
- habr (7)
People from Donetsk mentioned:
- donetsk (31)
- habr (12)
- radiot (8)
- sledui (7)
- ru_ff (7)
- google (7)
- wave (6)
- linux (6)
As you can see, in each group, the hashtag that describes the group comes first in terms of usage. There are common interests: habr, ru_ff, sledui, google.
3. When they say
Let's see what time the group is most active. To do this, we will use the same script that runs through all tweets, but this time we will create lists of the number of tweets at a given hour of the day and save them in separate files (the '-t' option when called from the command line). Let's draw diagrams using the Matplotlib library ( code ).
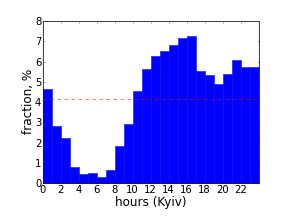
Participants #UKRTWEET are above average from 10 am to 1 am Kiev time, with a peak around 5 pm.

The Donetsk residents are active at the same time, but the peak is observed around 11 pm. Perhaps this is because people who are going to the barcamp consider Twitter as a working tool and are active in it during working hours. Although, due to recent holidays, this data may not be indicative.
4. Social graph
You can build a graph from Twitter data in various ways. Here we will follow the following construction: if person A mentioned person B at least once (it’s not important to retweet or answer), from vertex A to vertex B we build an oriented edge. The graph is not weighted, that is, we construct the edge only once.
All the same script with the option '-g' builds a dictionary representing such a graph from saved tweets and saves it in JSON format for subsequent analysis ( code ).
A few quantitative observations. In the #UKRTWEET group, 58% mention someone from the group (61/106). Altogether, 1221 people are mentioned, which is 11.5 times larger than the group itself (1221/106).
In the Donetsk group, 51.6% are involved in the group (116/225), and in total various mentions are 6 times more than the group itself (1341/225). It is clear that people who are going to visit the Twitter barcamp more actively use it as a means of communication.
5. Authority
Authority in a social graph can be analyzed in various ways. The easiest is to sort the participants by the number of incoming edges. Whoever has more is more authoritative. This method is suitable for small graphs. In an Internet search, Google uses PageRank as one of the criteria for page credibility. It is calculated by randomly wandering around the graph, where the nodes are pages, and the edge between the nodes is if one page links to another. A random walker moves around the graph and from time to time moves to a random node and starts walking again. PageRank is equal to the share of stay on some node for the entire time of wandering. The larger it is, the more authoritative the node.
Here we focus only on the two above criteria. It is worth mentioning that in the analysis of social graphs, much more attention is paid to various centralities . Their use as a criterion of authority may make more sense for more distributed social graphs.
One common Python graphing library is NetworkX . We will use it. Having created graph G, it is very convenient to consider its various parameters. So, for example, to calculate the PageRank of all nodes, it is enough to write:
pr = networkx.pagerank (G)
I want to emphasize that all the numbers below are for groups artificially isolated from the twitter sphere. Other members of these groups may be globally more influential and authoritative. The numbers below are for communications within these groups.
Let's display the dependence of PageRank for all nodes on the number of nodes that point to them ( code ). Naturally, two organizers ( @karelina and @ u02 ) have great authority . The well-known Ukrainian blogger @woofer_kyyiv has high authority measured in PageRank, although fewer people mention it, but they are mentioned evenly by group (from different communities). The authority of the official barcamp account ( @ukrtweet

) below with more mention. One interpretation: people prefer to communicate and mention people. Perhaps that is why in many official Western accounts the names of the broadcasters are clearly indicated. The undisputed leader within the Donetsk group is @quantizer . Differences in PageRank with similar numbers of mentions for the following participants can be interpreted, for example, as follows: @olchik_terl and @lancerenok communicate more with people from different parts of the group’s social graph, while @medialex , @lapidarius , @meesix , @alderko
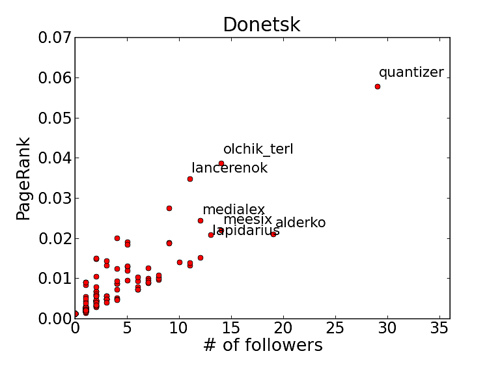
interact more with their local communities (mostly professionally selected, more on that below), so the second group has a slightly lower PageRank than the first.
6. Influencing from the outside
People outside groups also influence groups. We define the most influential ones in the same way as we did with hashtags: we sort people outside groups by the number of people who mention them in the group ( the same script that parses, but with the options '-g -o' creates the file data / friends_outside_counts.txt).
For #UKRTWEET (in parentheses - the number of different people from the group mentioned):
- podarok (16)
- taras (11)
- artemzeleny (11)
- blogoreader (10)
- yaroslavazhnyuk (9)
- wedmid (9)
- matteush (9)
For Donetsk:
- bobuk (12)
- olyapka (11)
- ekozlov (8)
- boomburum (7)
- abakala (7)
This approach can be used to find interesting people. If you are interested in a group, then probably those people whom this group mentions may also be of interest to you.
As an improvement, you can add not units, but PageRank mentions. So those who externally more influence the influential in the group will have more weight. We leave it for those who wish as an exercise with a code.
7. Communities
For algorithmic search for clusters in graphs, the most popular methods are those that optimize modularity. Modularity is a quantitative parameter using the number of internal connections within prospective communities and links with external communities. All the results that will be discussed below were obtained using the code posted on the website of the Belgian group , which they described in the article posted on arxiv. Other people also posted their code for such purposes. Also, the clustering algorithm is built into another popular library for working with graphs - igraph .
Graphs with labels and communities displayed using Seadragon, an interesting Microsoft web application that allows you to easily upload large graphic files in an interface similar to online maps, as well as with one file:
UkrTweet - seadragon , file .
{kind=link}
Donetsk - seadragon , file .
{kind=link}
We used a script to find communities and a script to draw a graph.
8. Community Labels
I would like to get some characteristics of the formed communities. One way is to look at which lists people from the communities were included. Download all the lists in which people from groups were included ( code ). We sort the groups by the total PageRank and print ten names of the lists that were found for the largest number of people in the group ( code ). In some communities, speaking tags cannot be distinguished, but in many participant tags they say a lot. In the table below, communities are sorted by total PageRank, the two most authoritative participants, the number of participants, several common speaking tags (in brackets the number of people from the communities that were in the corresponding lists):
UkrTweet
| Members | Total participants | Tags | Comments |
|---|---|---|---|
| u02, karelina, ... | 12 | zp-ua (10), zp (10) | Around the organizers, mainly from Zaporozhye |
| woofer_kyyiv, gasique, ... | 12 | kyiv (8), mckyiv09 (6), bloggers (6) | Kiev bloggers who met at Media Camp 2009 |
| o_saltan, netocrat, ... | thirteen | journalists (7), zp (6) | Journalists, a lot from Zaporozhye |
| b2blogger, maxzalevski, ... | 7 | seo (5), belseo (5), web-marketing (4) | Web marketers and SEO professionals |
It’s hard to say anything about the four communities from the lists. For example, I got into a community from which many retweeted about tweetingplaces , one of my project. But we have no common names for the lists, except for ukrtweet.
Donetsk
| Members | Total participants | Tags | Comments |
|---|---|---|---|
| quantizer, alderko, ... | 21 | donntu (10) | One community from DonNTU |
| decoy, andrulik, ... | 21 | cnc-donetsk (9) | Many former Coffee and Code meetings |
| medialex, iammarat, ... | thirteen | christians (13) | Believers |
| lapidarius, kolgushev, ... | eleven | seo (2), medianext-ua (2) | Related to New Media |
| meesix, bezlik, ... | 9 | donntu (2) | The second community related to DonNTU |
| alexeyosipenko, a_djo, ... | 8 | donetsk-rubyists (5), cnc-donetsk (3) | Ruby Fans Also Ex-KiK |
Interestingly, olchik_terl and lancerenok, which were mentioned earlier, and who had PageRank more than other people who are also often mentioned, fall into active communities that are poorly described by lists. They communicate more with the whole group, and not within professional communities.
Exercises
Twitter, thanks to its API, provides fertile fields for mining and analyzing information about social graphs. Here are some exercises for those who want to dig more.
- What means in the group are most often used to tweet (web, TweetDeck, Echofon, ...)?
- Mentioned centrality. Depict betweenness_centrality depending on eigenvector_centrality using NetworkX.
- Get external influences weighted through PageRank.
- Using the code of the book “Programmable Collective Intelligence”, select clusters in a group not based on a graph, but based on common lists.
Libraries used
BeautifulSoup
for HTML parsing is a
tweepy
interface for accessing the
NetworkX Twitter API .
for working with graphs
Matplotlib
allows you to draw graphs and charts
igraph
package for working with graphs, there is an interface in Python (it was not used here, but was mentioned)