Introducing Parallelization Levels
You can parallelize the solution of the problem at several levels. There is no clear boundary between these levels and the specific parallelization technology can be difficult to attribute to one of them. The division given here is conditional and serves to demonstrate the variety of approaches to the task of parallelization.
Task Level Parallelization

Parallelization at this level is often the simplest and most effective at the same time. Such parallelization is possible in those cases when the problem being solved naturally consists of independent subproblems, each of which can be solved separately. A good example would be audio album compression. Each record can be processed separately, since it is in no way connected with the others.
Parallelization at the task level is demonstrated to us by the operating system, running programs on different cores on a multicore machine. If the first program shows us a movie, and the second is a file-sharing client, then the operating system can calmly organize their parallel work.
Other examples of parallelization at this level of abstraction are parallel file compilation in Visual Studio 2008, data processing in batch modes.
As mentioned above, this type of parallelization is simple and in some cases very effective. But if we are dealing with a homogeneous problem, then this type of parallelization is not applicable. The operating system can not speed up a program that uses only one processor, no matter how many cores are available. A program that breaks the encoding of sound and image in a video into two tasks will not receive anything from the third or fourth core. In order to parallelize homogeneous tasks, you need to go down a level below.
Data Concurrency Level
The name of the model “data parallelism” comes from the fact that parallelism consists in applying the same operation to multiple data elements. Data parallelism is demonstrated by the archiver, which uses several processor cores for packaging. Data is divided into blocks that are processed (packaged) on different nodes in a uniform manner.

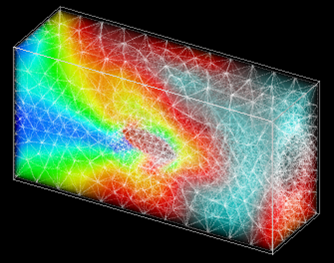
This type of parallelism is widely used in solving problems of numerical simulation. The counting area is presented in the form of cells describing the state of the medium at the corresponding points in space - pressure, density, percentage of gases, temperature, and so on. The number of such cells can be huge - millions and billions. Each of these cells must be processed in the same way. Here, the data parallelism model is extremely convenient, since it allows you to load each core by selecting a specific set of cells for it. The counting area is divided into geometric objects, such as parallelepipeds, and the cells that enter this area are given for processing to a specific core. In mathematical physics, this type of parallelism is called geometric parallelism.
Although geometric parallelism may seem similar to task-level parallelization, it is more difficult to implement. In the case of modeling problems, it is necessary to transfer data obtained at the boundaries of geometric regions to other kernels. Often, special methods are used to increase the calculation speed due to load balancing between computing nodes.

In a number of algorithms, the calculation speed, where processes are actively running, takes longer than where the environment is calm. As shown in the figure, dividing the counting area into unequal parts, you can get a more uniform loading of cores. Cores 1, 2, and 3 process small areas where the body moves, and core 4 processes a large area that has not yet been disturbed. All this requires additional analysis and the creation of a balancing algorithm.
The reward for this complication is the ability to solve the problems of long-term movement of objects for an acceptable calculation time. An example is the launch of a rocket.

Algorithm Parallelization Level
The next level is the parallelization of individual procedures and algorithms. These include parallel sorting algorithms, matrix multiplication, and solving a system of linear equations. At this level of abstraction, it is convenient to use such parallel programming technology as OpenMP.

OpenMP (Open Multi-Processing) is a set of compiler directives, library procedures, and environment variables that are designed to program multithreaded applications on multiprocessor systems. OpenMP uses a parallel branch-merge execution model. OpenMP program starts as a single threadexecution, called the initial thread. When a thread encounters a parallel construction, it creates a new group of threads, consisting of itself and a number of additional threads, and becomes the main one in the new group. All members of the new group (including the main thread) execute code inside the parallel construct. At the end of the parallel structure there is an implicit barrier. After the parallel construction, the execution of the user code continues only the main thread. Other parallel regions may be nested in a parallel region.
With the idea of “incremental parallelization,” OpenMP is ideal for developers who want to quickly parallelize their computing programs with large parallel loops. The developer does not create a new parallel program, but simply sequentially adds OpenMP directives to the text of the serial program.
The task of implementing parallel algorithms is quite complicated and therefore there is a sufficiently large number of libraries of parallel algorithms that allow you to build programs like cubes without going into the device for implementing parallel data processing.
Instruction level concurrency
The lowest level of parallelism, carried out at the level of parallel processing by the processor of several instructions. At the same level is the batch processing of several data elements with a single processor command. We are talking about technologies MMX, SSE, SSE2 and so on. This type of parallelism is sometimes distinguished into an even deeper level of parallelization - parallelism at the bit level.
A program is a stream of instructions executed by a processor. You can change the order of these instructions, distribute them among groups that will be executed in parallel, without changing the result of the entire program. This is called concurrency at the instruction level. To implement this type of parallelism in microprocessors, several instruction pipelines are used, such technologies as command prediction, register renaming.
A programmer rarely looks at this level. Yes, and that makes no sense. The compiler performs the work of arranging the commands in the most convenient sequence for the processor. This level of parallelization can be of interest only for a narrow group of specialists who are squeezing all the features from SSEx or compiler developers.
Instead of a conclusion
This text does not pretend to be a complete story about the levels of parallelism, but simply shows the versatility of the issue of using multicore systems. For those who are interested in program development, I want to offer several links to resources on parallel programming issues:
- Community of software developers. I am not an Intel employee, but highly recommend this resource as a member of this community. A lot of interesting articles, blog entries and discussions related to parallel programming.
- Reviews of articles on parallel programming using OpenMP technology.
- http://www.parallel.ru/ Everything about the world of supercomputers and parallel computing. Academic community. Technologies, conferences, discussion club (forum) on parallel computing.